提升数据分析效率:Amazon S3 Express One Zone数据湖实战教程
(声明:本篇文章授权活动官方亚马逊云科技文章转发、改写权,包括不限于在 亚马逊云科技开发者社区、知乎、自媒体平台、第三方开发者媒体等亚马逊云科技官方渠道)
前言
Hello,我是 Maynor。
近日受邀写一篇关于亚马逊云科技 re:Invent 大会新品发布的产品测评,于是有了这篇文章,以下是我对 S3 Express One Zone 的测评:
什么是 Amazon S3?
Amazon Simple Storage Service (Amazon S3) 是一种对象存储服务,提供业界领先的可扩展性、数据可用性、安全性和性能。各种规模和行业的客户都可以使用 Amazon S3 来存储和保护各种用例的任意数量的数据,例如数据湖、网站、移动应用程序、备份和恢复、存档、企业应用程序、物联网设备和大数据分析。Amazon S3 提供管理功能,以便可以优化、组织和配置对数据的访问,以满足的特定业务、组织和合规性要求。
什么是 S3 Express One Zone?

简单说: S3 Express One Zone 就是能够存储任何文件的服务器,无论是音频视频文件,还是结构化或非结构化数据统统都能存下,存储读取的速度还贼快~
实现概述
在这个数字化时代,数据湖已成为企业收集、存储和分析大规模数据集的关键资源。Amazon Web Services 提供了一系列强大的工具,使构建和管理数据湖变得既简单又高效。接下来,我将深入探索如何利用 S3 Express One Zone、Amazon Athena和Amazon Glue 来打造一个高性能且成本效益显著的数据湖。 
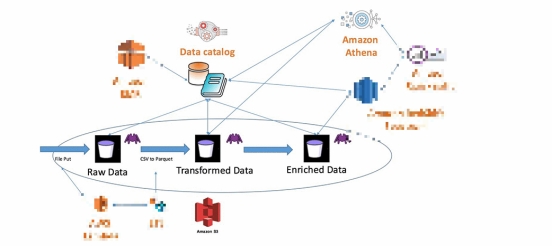
技术架构组件
• S3 Express One Zone:作为数据湖的底层存储,提供低成本的存储选项。
• Amazon Athena:用于查询存储在 S3 Express One Zone 中的数据。
• Amazon Glue:数据目录和 ETL 作业。
技术架构如图所示:
实现步骤概览
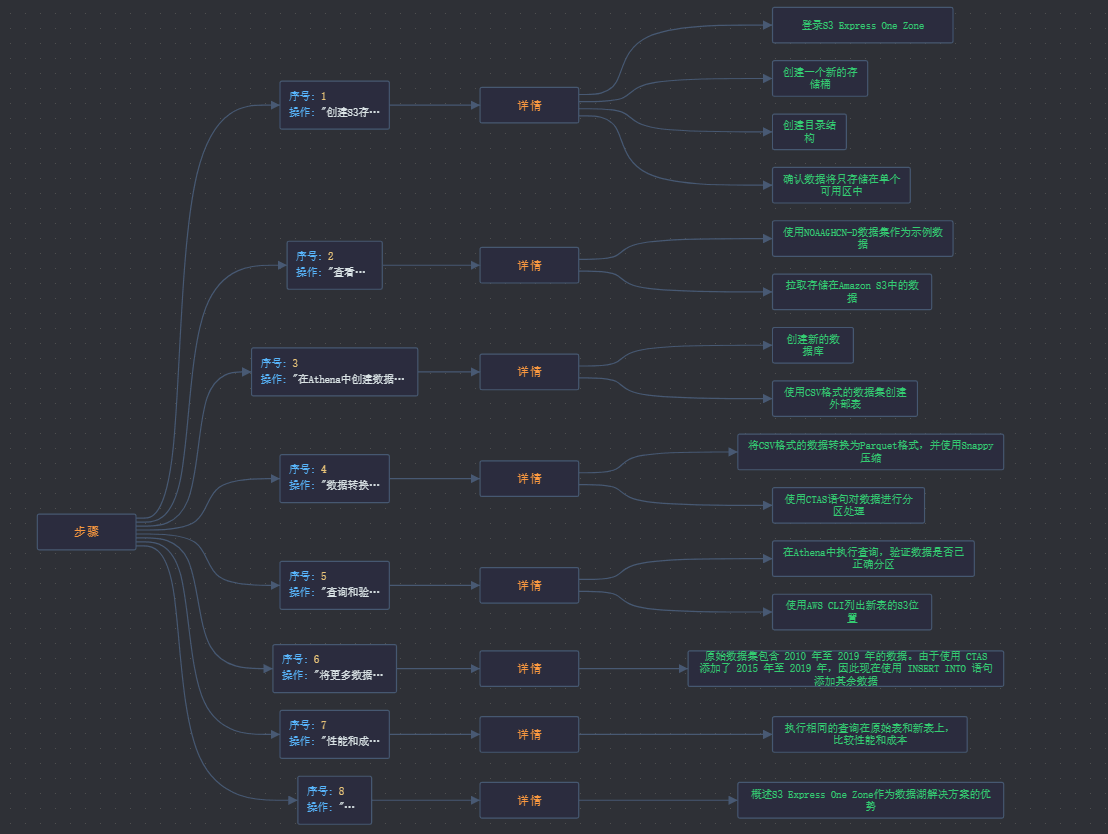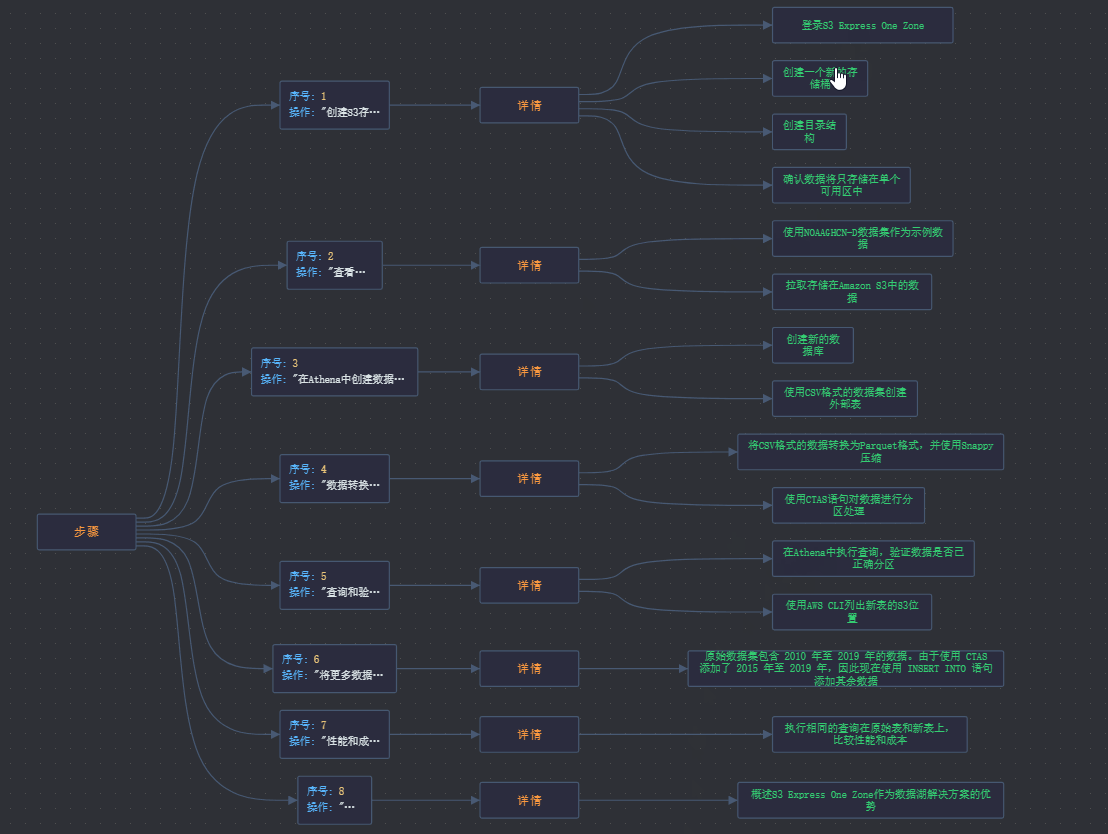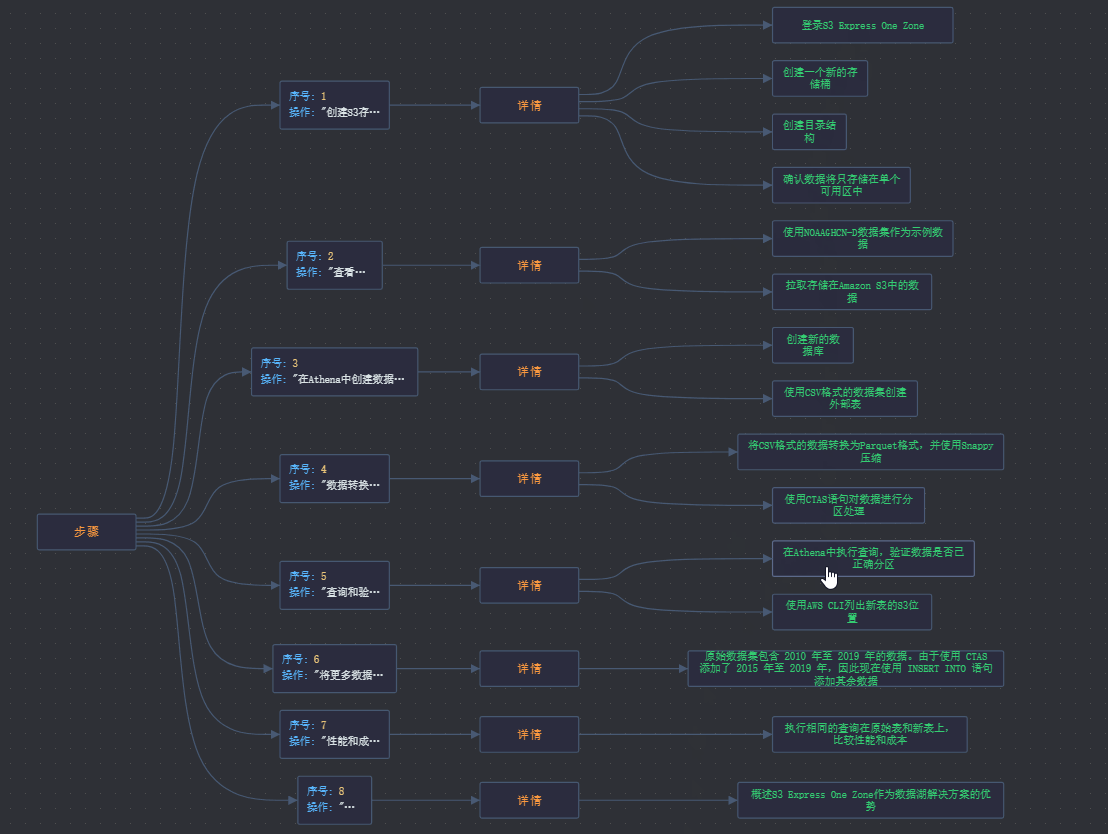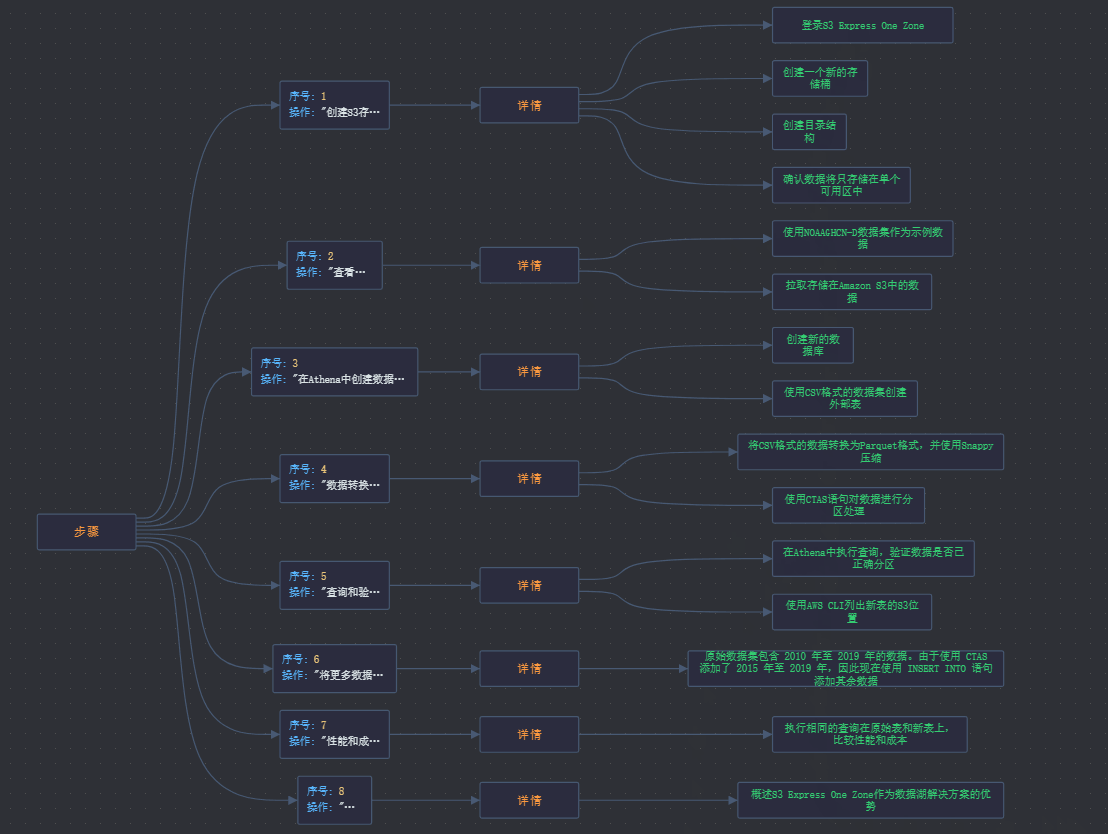
第一步:构建数据湖的基础
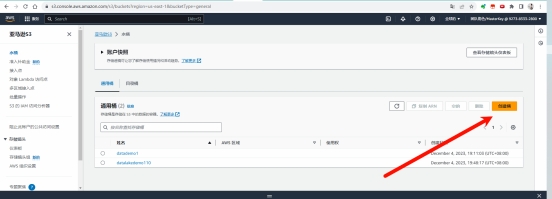
S3 Express One Zone 登录链接: https://s3.console.aws.amazon.com/s3/buckets
点击创建桶:
点击第二个选项,创建目录 -新
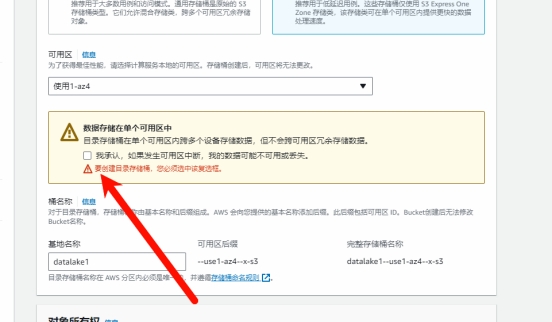
确定数据存储只存储在单个可用区中
第二步:选择并查看数据集
本示例使用 NOAA 全球历史气候网络日报 (GHCN-D)数据,数据存储在 amazon s3 对象存储中,我们只需要拉取即可:
aws s3 ls s3://aws-bigdata-blog/artifacts/athena-ctas-insert-into-blog/ 
第三步:在 Athena 中搭建架构
在 Athena 控制台中执行查询。首先,为此创建一个数据库:
CREATE DATABASE blogdb
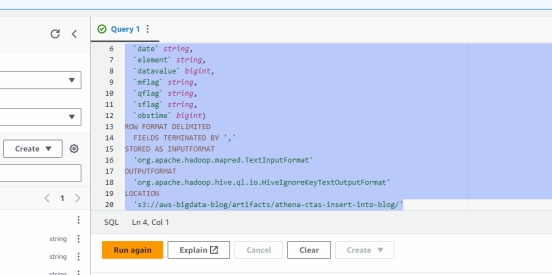
现在,根据上面的数据创建原始 CSV 格式的外部表。
CREATE EXTERNAL TABLE blogdb.original_csv (
id string,
date string,
element string,
datavalue bigint,
mflag string,
qflag string,
sflag string,
obstime bigint)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
's3://aws-bigdata-blog/artifacts/athena-ctas-insert-into-blog/'
第四步:数据转换与优化
现在,使用 Snappy 压缩将数据转换为 Parquet 格式,并每年对数据进行分区。所有这些操作都是使用 CTAS 语句执行的。就本博客而言,初始表仅包含 2015 年至 2019 年的数据。可以使用 INSERT INTO 命令向该表添加新数据。
刚才创建的表有一个日期字段,日期格式为 YYYYMMDD(例如 20100104),新表按年份分区,使用 Presto 函数 substr(“date”,1,4) 从日期字段中提取年份值。
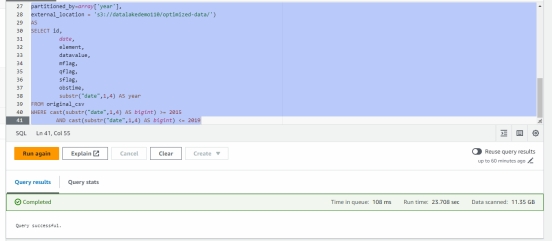
CREATE table new_parquet
WITH (format='PARQUET',
parquet_compression='SNAPPY',
partitioned_by=array['year'],
external_location = 's3://datalakedemo110/optimized-data/')
AS
SELECT id,
date,
element,
datavalue,
mflag,
qflag,
sflag,
obstime,
substr("date",1,4) AS year
FROM original_csv
WHERE cast(substr("date",1,4) AS bigint) >= 2015
AND cast(substr("date",1,4) AS bigint) <= 2019
耗时 23 秒,加载数据 11.35GB,可以说相当的快! 
第五步:查询和验证数据
点击控制台,查看是否有数据:
输入命令,查询分区(文件夹):
aws s3 ls s3://datalakedemo110/optimized-data/
成功查询到 15 年至 19 年的分区:

输入命令,查询文件:
aws s3 ls s3://datalakedemo110/optimized-data/ --recursive --human-readable | head -5
成功查询到 15 年至 19 年的分区里的文件:

第六步:将更多数据添加到表
现在,将更多数据和分区添加到上面创建的新表中。原始数据集包含 2010 年至 2019 年的数据。由于使用 CTAS 添加了 2015 年至 2019 年,因此现在使用 INSERT INTO 语句添加其余数据:
INSERT INTO new_parquet
SELECT id,
date,
element,
datavalue,
mflag,
qflag,
sflag,
obstime,
substr("date",1,4) AS year
FROM original_csv
WHERE cast(substr("date",1,4) AS bigint) < 2015
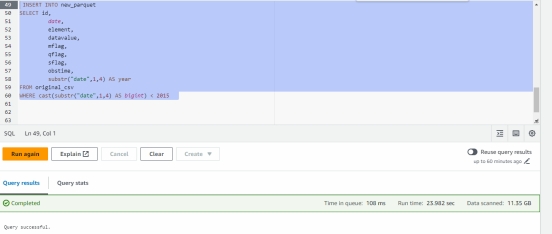
列出新表的 Amazon S3 位置
aws s3 ls s3://datalakedemo110/optimized-data/ 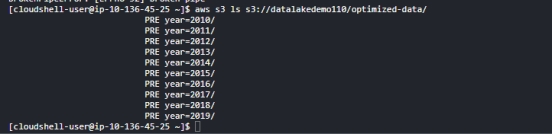
第七步:性能和成本效益分析
运行一些查询来查看在性能和成本优化方面获得的收益:
首先,找出年份中每个值的不同 ID 的数量:
查询原表:
SELECT substr("date",1,4) as year,
COUNT(DISTINCT id)
FROM original_csv
GROUP BY 1 ORDER BY 1 DESC
查询新表:
SELECT year,
COUNT(DISTINCT id)
FROM new_parquet
GROUP BY 1 ORDER BY 1 DESC
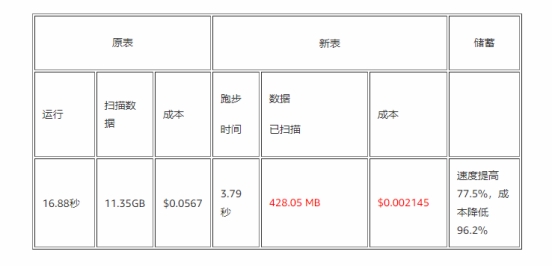
性能对比:

速度提升 77.5%,成本降低 96.2%
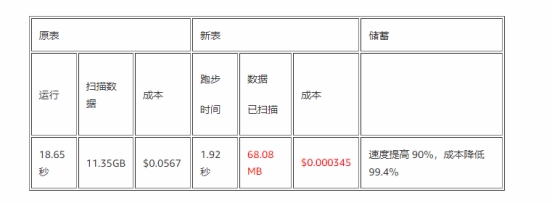
接下来,计算 2018 年地球的平均最高气温(摄氏度)、平均最低气温(摄氏度)和平均降雨量(毫米):
查询原表:
SELECT element, round(avg(CAST(datavalue AS real)/10),2) AS value
FROM original_csv
WHERE element IN ('TMIN', 'TMAX', 'PRCP') AND substr("date",1,4) = '2018'
GROUP BY 1
查询新表:
SELECT element, round(avg(CAST(datavalue AS real)/10),2) AS value
FROM new_parquet
WHERE element IN ('TMIN', 'TMAX', 'PRCP') and year = '2018'
GROUP BY 1
总体查询速度提升 90%,成本降低 99.4%
体会
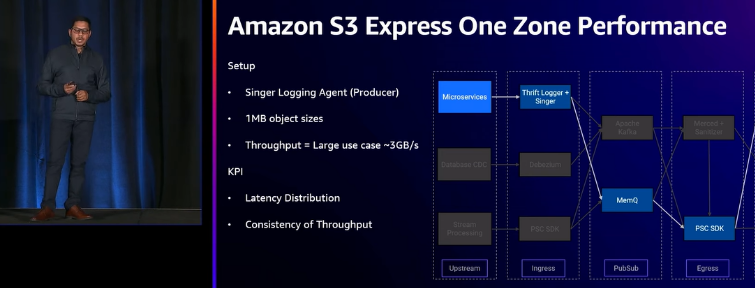
Amazon S3 Express One Zone在速度和成本这块可谓遥遥领先于同行! 相较于传统构建方式,Amazon S3 Express One Zone在性能上表现出色,其数据访问速度比Amazon S3快10倍,尤其适用于作机器学习、大数据分析,正如本次的数据湖构建实战。此外,通过将数据与计算资源置于同一亚马逊云科技可用区,客户不仅可以更灵活地扩展或缩减存储,而且能够以更低的计算成本运行工作负载,降低了总体成本。
结语
以上内容展示了 S3 Express One Zone 在存储和快速访问大规模数据集方面的强大能力,还通过一个实际案例演示了如何有效地利用这些技术构建一个高性能、成本有效的数据湖。这对于那些需要处理大量数据并迅速获取洞察的企业来说是一个非常有价值的资源。

以上便是 S3 Express One Zone 作数据湖的构建过程,S3 Express One Zone 作为一个非常方便且可靠的数据湖解决方案。它提供了低成本的存储选项,并且具有高可用性和持久性。
同时,它还支持多种数据湖工具和分析服务,能够满足各种数据湖的需求,如果需要进一步扩展,可以考虑结合其他 AWS 的数据湖相关服务,比如使用 Amazon Redshift 来构建更加完善的数据湖架构、连接 BI 工具如 Amazon QuickSight 以进行数据可视化、使用 AWS CloudWatch 监控数据湖的使用情况和性能,这里有待读者去自行探索~
附录
本文涉及产品官网入口:
亚马逊云科技控制台:
Amazon S3 Express One Zone官网: