当今数字化时代,数据安全成为了企业和个人最为关注的重要议题之一。随着数据规模的不断增长和数据应用的广泛普及,如何保护数据的安全性和隐私性成为了迫切的需求。
今天,我将带领大家一起探索腾讯云云上实验室所推出的向量数据库,这个强大的工具不仅能够有效地存储和处理大规模的向量数据,更有着卓越的安全监控机制,为用户提供了一道坚实的数据安全之盾。本文将深入剖析腾讯云向量数据库的安全监控机制,并从多个维度进行评估。
目录
一、初识腾讯云向量数据库
腾讯云向量数据库(Tencent Cloud VectorDB):是一款全托管的自研企业级分布式数据库服务,专用于存储、检索、分析多维向量数据。该数据库能够被广泛应用于大模型的训练、推理和知识库补充等场景。是国内首个从接入层、计算层到存储层提供全生命周期AI化的向量数据库。腾讯云向量数据库最高支持10亿级向量检索规模,延迟控制在毫秒级,相比传统单机插件式数据库检索规模提升10倍,同时具备百万级每秒查询的峰值能力。跳转链接:

数据存储与处理性能:在数据存储和处理性能这一方面,官方给我们介绍了在腾讯云向量数据库中在数据存储方面单索引支持10亿级向量数据规模,在处理性能方面可支持百万 QPS 及毫秒级查询延迟,腾讯集团自研的向量检索引擎 OLAMA,近40个业务线上稳定运行,日均处理搜索请求高达千亿次,可见其服务的连续性和稳定性之高。具体的使用优势可参考官方文档给出的具体详解:

向量特征相似度查询:向量数据库可以将用户的所有数据存储在向量数据库当中,当用户输入数据进行查询时,向量数据库会根据用户输入的数据进行计算向量之间的相似度,检索最相关的问题信息并返回对应的答案信息,所以向量数据库在大模型及其问答推荐系统领域方面,应用十分广泛:
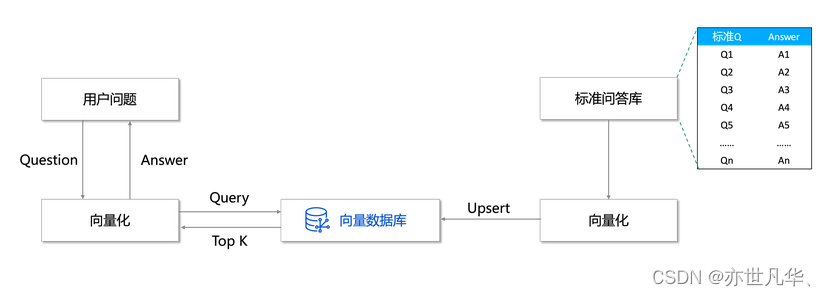
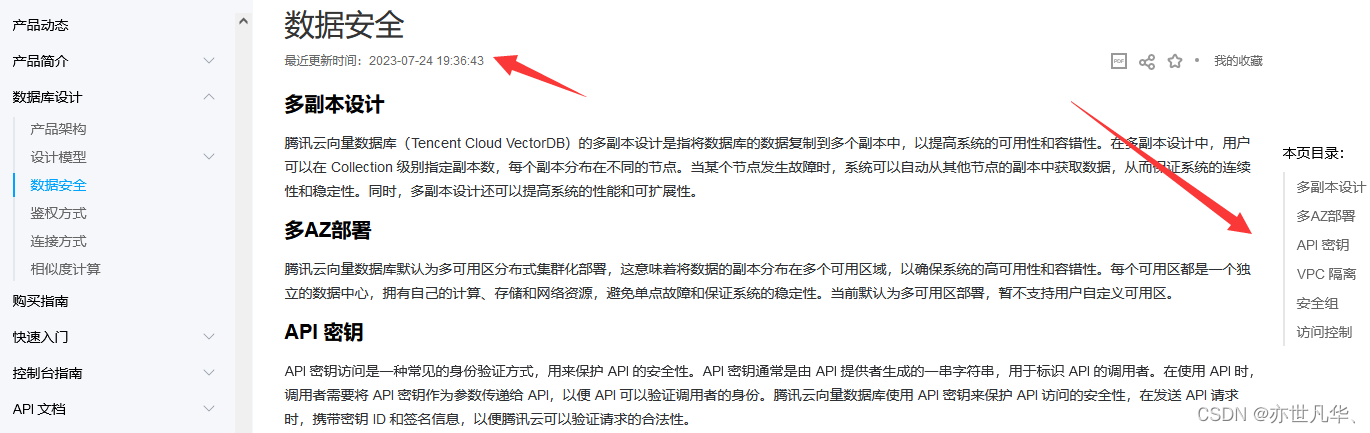
安全监控机制:在腾讯云向量数据库的对安全的处理中,腾讯云处理的方式是将向量数据库运行于私有网络环境中。该私有网络是一块在腾讯云上自定义的逻辑隔离网络空间,基于隧道技术在物理网络上构造虚拟网络,使用虚拟化技术,实现不同私有网络之间内网完全隔离。俗称VPC:
专有网络是自己完全掌控的网络,例如选择 IP 地址范围、配置路由表和网关等,可以在自己定义的专有网络中使用腾讯云或阿里云资源,专有网络支持连接到其他专有网络,或本地网络,形成一个按需定制的网络环境,实现应用的平滑迁移上云和对数据中心的扩展,而专有网络VPC是基于阿里云构建的一个隔离的网络环境,专有网络之间逻辑上彻底分离:

VPC特点:
安全隔离:使用隧道技术达到传统VLAN相同隔离的效果;实现了不同云服务器间二层网络隔离;专有网络内的ECS使用安全组防火墙进行三层网络访问控制。
访问控制:灵活的访问控制规则,满足政务金融等安全隔离规范。
软件定义网络:按需配置网络设置,软件定义网络;管理操作实时生效等。
丰富的网络连接方式:支持软件VPN;支持专线连接
安全组介绍:
安全组是一种虚拟防火墙,用于控制安全组内ECS实例的入流量和出流量,从而提高ECS实例的安全性。安全组具备状态检测和数据包过滤能力,您可以基于安全组的特性和安全组规则的配置在云端划分安全域,在下文我们将详细介绍安全组的配置过程。
其他具体的安全防护手段也可以参考 官方文档 的讲解,这里不再过多的一一介绍,详情如下:
二、体验性过程测试与评估
1】注册与登录 访问腾讯云 官方链接,初次使用腾讯云的朋友需要注册并完成实名认证才可以继续使用。然后在导航栏的搜索框当中输入向量数据库关键字回车,选择第一个文档消息进行向量数据库的体验:

2】创建实例 进入向量数据库界面选择体验,然后在进入的后台中点击 新建 创建一个新的实例:

点击新建后进入新建向量数据实例页面进行相关配置即可:
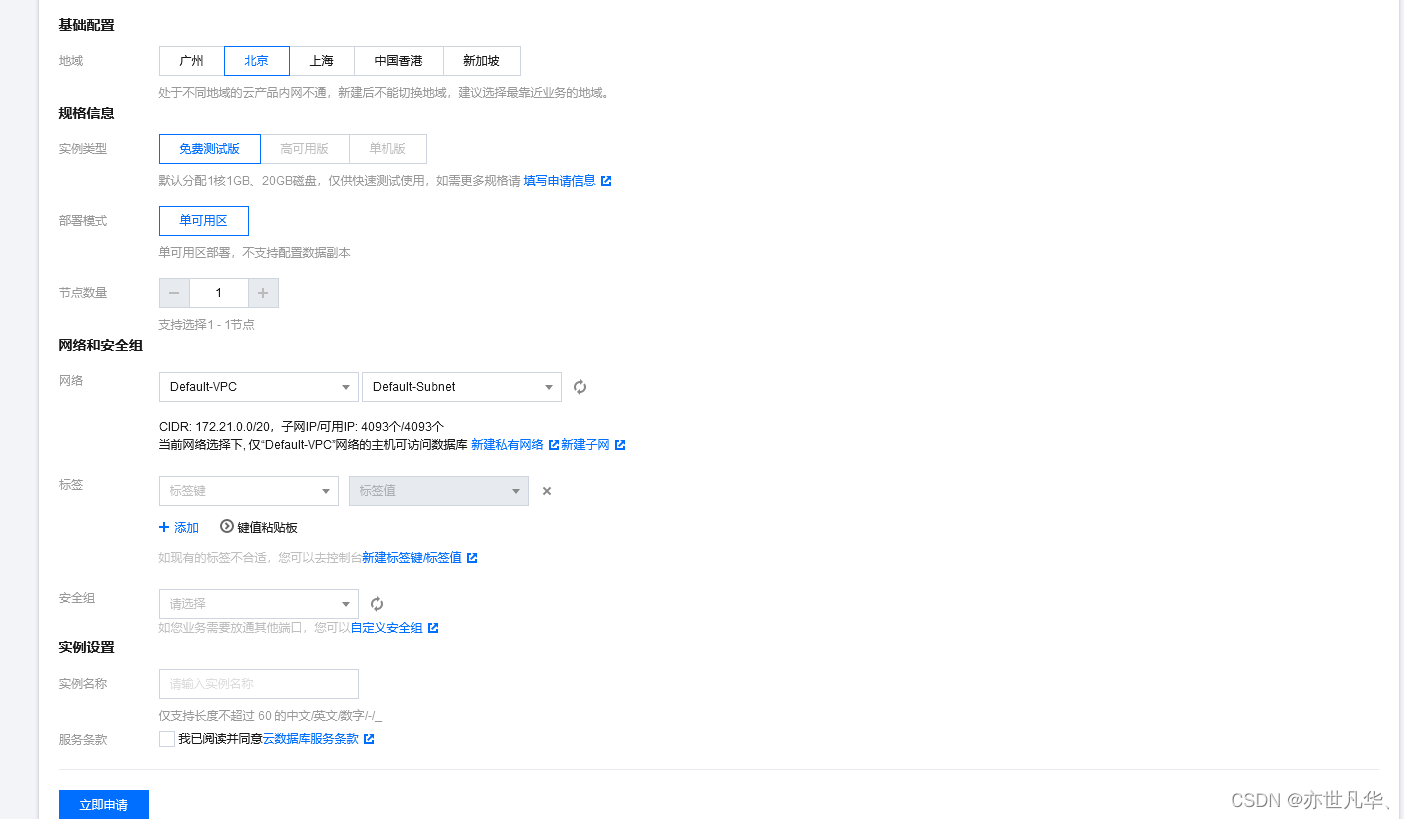
配置数据库相应选择的参数可以参考官方文档给我们的详细解释:跳转链接 :

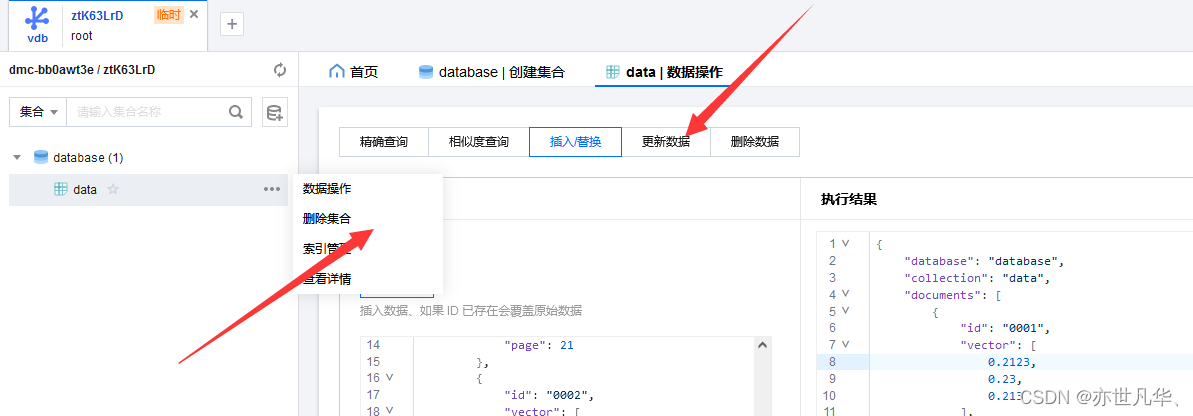
3】管理实例 创建完向量数据库实例之后,在控制台可点击管理按钮查看向量数据的具体信息:

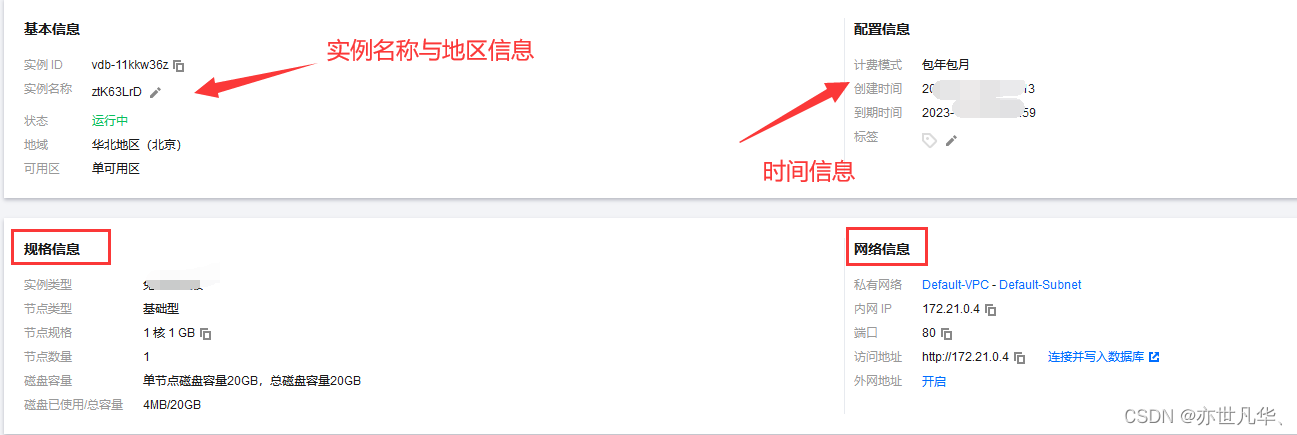
我们可以在管理实例中看到需要可视化的管理选型,可以根据自己的选择查看具体信息:

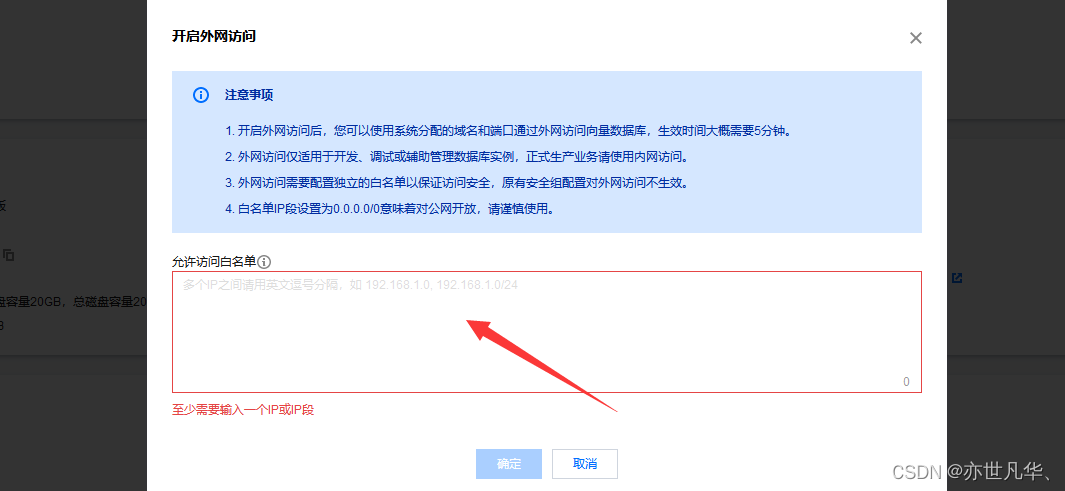
4】开启外网 单击实例 ID 进入实例详情页面,在网络信息区域,单击外网地址后面的开启。在开启外网访问的小窗口,在允许访问白名单的输入框,配置外网访问的白名单列表,如下:

5】登录数据库管理控制台 我们在上面的管理实例中找到密钥管理的选项,下面记载的名称和API密钥就是我们登录控制台的账户密码:

在控制台点击登录按钮进行到登录页面输入即可:
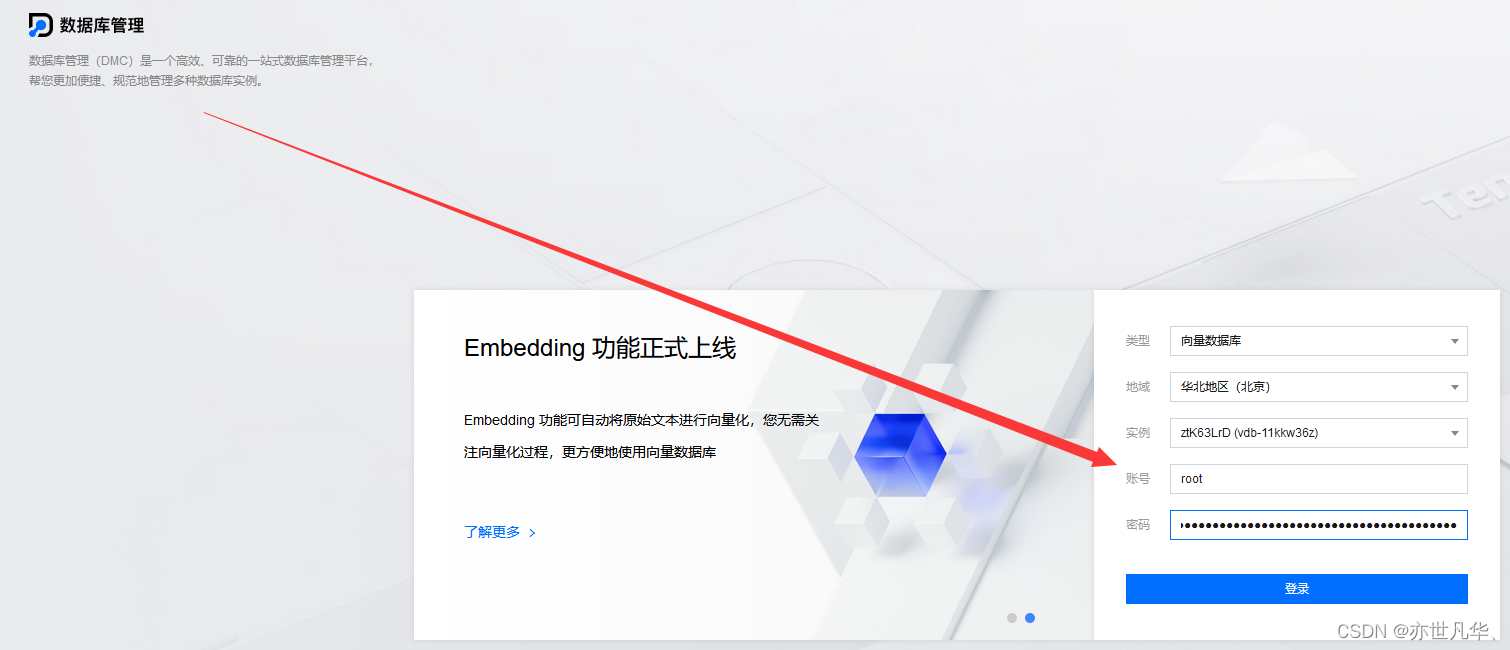
登录控制台之后,我们可以看到后台提供给我们需要的可视化选项,我们可以根据需求选择:

这里我们可以选择创建体验 Embedding,使用向量数据库提供给我们的基础数据简单的体验一下

6】删除实例 如果你想将创建的实例进行删除的话,方式很简单,只需要登录控制台点击更多在下拉框中点击销毁即可:

三、个性体验与系统兼容性
接下来简单的介绍一下关于腾讯云向量数据库是否支持用户根据需求进行配置和定制:
我们在创建向量数据库实例的时候可以根据需求定制一下基础的配置和规格信息:

在规格信息的具体实例类型方面,可以根据需要求进行更多规格的申请,而不单单只是一些基础的配置, 在填写申请表的阶段,可以详细描述一下自己所使用向量数据库的应用场景,这样的话可以腾讯云可以根据我们的需求推断出我们当前最适用的向量数据库:

在登录向量数据库后他之后,腾讯云针对向量数据库,推出数据库管理、开发工具,可帮您在线管理数据库、管理集合、快速查找更新数据等。后续腾讯云也将针对向量数据库持续推出更多的功能哦,我们期待未来它给我们更多的惊喜。
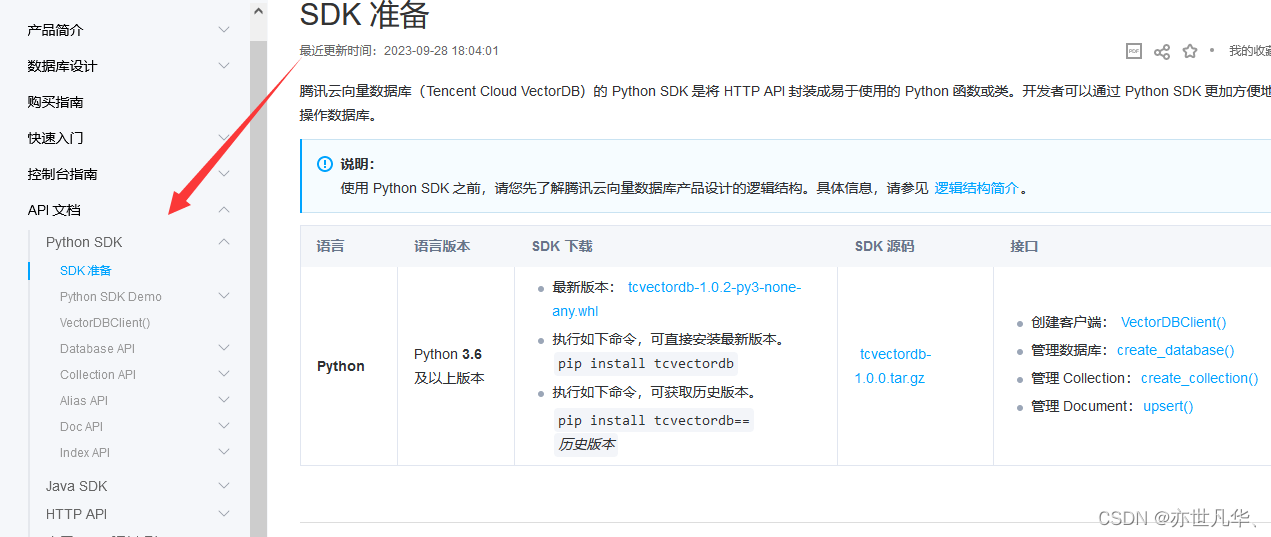
腾讯云向量数据库在主流操作系统(如Windows、Linux、MacOS等)和主流IDE(如Visual Studio Code、IntelliJ IDEA等)上都有良好的稳定性和兼容性。 它提供了多种客户端和SDK,可以方便地集成到各种开发环境和工具中。无论你使用哪种操作系统或IDE进行开发,都可以通过腾讯云向量数据库的客户端进行连接和操作。这里可以看到官方文档给我们相应的API文档:
这里使用开发工具,博主采用python语言与向量数据库进行相应的测试,首先我们需要终端执行如下命令进行安装相应的插件:
pip install tcvectordb
# pip版本过低导致安装失败,这里需要先更新一下pip版本至最新
python.exe -m pip install --upgrade pip出现如下情况说明安装成功,这里我们就可以正常的使用腾讯云向量数据库给我们提供的插件与编程语言进行相应结合了,如果报错的话可以是由于网络原因导致的中断,可以多试几次:

这里我们开始使用插件来连接我们的向量数据库,并创建一个名为 db-test-by_ye 的数据库进行一个简单的测试,这里需要用到我们上文体验过程中开始的外网访问地址和相应密钥管理当中的API密钥作为识别你身份的参数,如果没有对应的正确信息是不能连接到我们的向量数据库的,具体的代码如下,url地址和相应的key信息这里输入自己的账号信息即可:
import tcvectordb
from tcvectordb.model.enum import FieldType, IndexType, MetricType, ReadConsistency
client = tcvectordb.VectorDBClient(
url='http://lb-3f6goz65-9qzaxduhtkf........',
username='root',
key='xzxazMkko5..........Gekb02I',
read_consistency=ReadConsistency.EVENTUAL_CONSISTENCY,
timeout=30
)
db = client.create_database(database_name='db-test-by_ye')
print(db.database_name)最终我们可以看到控制台打印了我们创建的数据库的名称:

回到控制台我们可以看到我们创建的数据库名称,在向量数据库当中已经呈现:

因为向量数据库这里也是兼容java语言来连接向量数据库的,这里我们也可以采用java进行连接:
import com.tencent.tcvectordb.client.VectorDBClient;
import com.tencent.tcvectordb.model.param.database.ConnectParam;
import com.tencent.tcvectordb.model.param.enums.ReadConsistencyEnum;
public class VDBClient {
public static VectorDBClient createClient() {
ConnectParam param = getConnectParam();
return new VectorDBClient(param, ReadConsistencyEnum.EVENTUAL_CONSISTENCY);
}
private static ConnectParam getConnectParam() {
return ConnectParam.newBuilder()
.withUrl("url")
.withUsername("username")
.withKey("key")
.withTimeout(30)
.build();
}
}文档的后面也提供了一个比较详细的问答系统结合向量数据库的实现过程:

这么详细的文档和示例代码,可以帮助开发者快速上手并集成到他们的项目中。同时,腾讯云的技术支持团队也会为开发者提供及时的帮助和支持,确保在不同的开发环境下能够顺利使用腾讯云向量数据库。
四、数据可视化和数据安全
官方文档给我们讲解了关于腾讯云向量数据的具体操作,我们通过腾讯云提供的可视化界面,用户可以轻松地创建新的数据库,
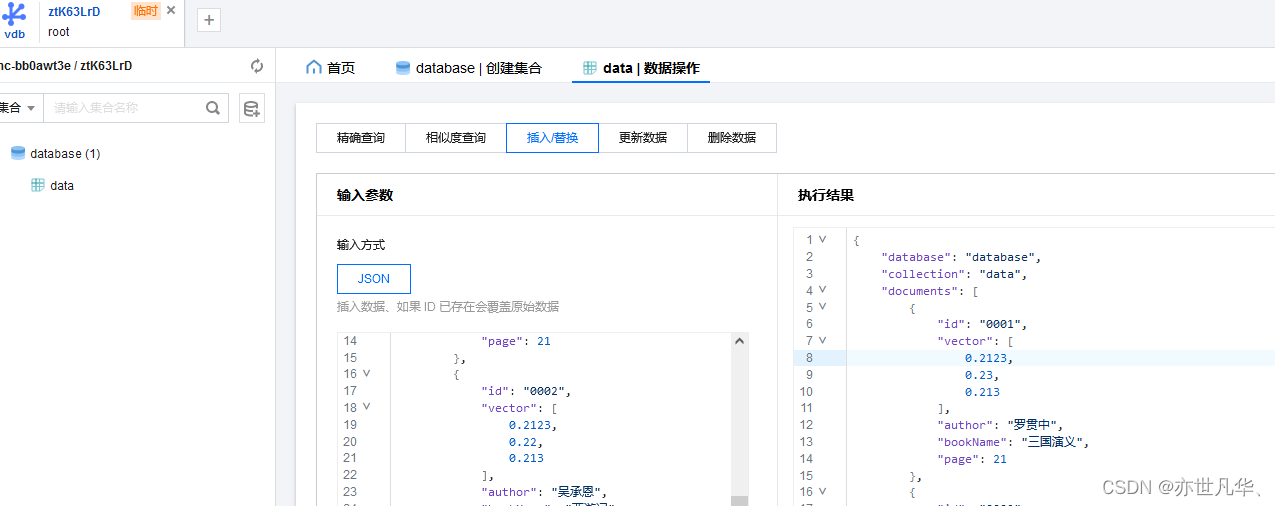
进行数据操作以及数据查询分析等各种操作:
当然我们也可以借助代码将相应本地的文件上传到向量数据库当中进行检索,这里我们使用py进行相应的操作,这里我们先创建一个集合,并将一个相应的数据进行插入到向量数据库当中:
# 指定数据库
db = client.database('db-test-by_ye')
# 第一步,设计索引(不是设计 Collection 的结构)
index = Index(
FilterIndex(name='id', field_type=FieldType.String, index_type=IndexType.PRIMARY_KEY),
FilterIndex(name='question', field_type=FieldType.String, index_type=IndexType.FILTER),
FilterIndex(name='answer', field_type=FieldType.String, index_type=IndexType.FILTER),
VectorIndex(name='vector', dimension=3, index_type=IndexType.HNSW,
metric_type=MetricType.COSINE, params=HNSWParams(m=16, efconstruction=200))
)
# 第二步,创建 Collection
coll = db.create_collection(
name='intelligent',
shard=1,
replicas=0,
description='this is a collection of test embedding',
index=index
)
# 写入数据
res = coll.upsert(
documents=[
Document(id='0001', vector=[
0.2123, 0.23, 0.213],
question='请问车险理赔时,全责一方和无责任一方收到待遇的区别',
answer='这位朋友提问的有些过于笼统了不是很详细,理论上来讲,从商业险的角度分析,有责任,保险公司才会...', page=21),
Document(id='0002', vector=[
0.2123, 0.22, 0.213],
question='买保险,一定要找代理人吗,直接去保险公司买不可以吗?',
answer='可以的。可以自行去保险公司进行投保,也可以选择在网上投保。不过有代理人的好处在于可以为被保险...', page=22),
Document(id='0003', vector=[
0.2123, 0.21, 0.213],
question='机动车撞伤人至骨折保险公司该怎么赔偿',
answer='交通事故赔偿是有标准的,因交通事故造成损失,肇事者向受害者、保险公司对承保车辆造成的损失进行...', page=23)
],
build_index=True
)这里我们在向量数据库的控制台处进行相应的数据查询,可以看到我们的数据已经写入到我们的向量数据库当中:

当然我们也可以进行相应的相似度进行查询,代码如下:
import tcvectordb
from tcvectordb.model.enum import FieldType, IndexType, MetricType, ReadConsistency
from tcvectordb.model.index import Index, VectorIndex, FilterIndex, HNSWParams
from tcvectordb.model.collection import UpdateQuery
from tcvectordb.model.document import Document, SearchParams, Filter
client = tcvectordb.VectorDBClient(
url='http://lb-3f6goz65-9q.......om:20000',
username='root',
key='xzxazMkko50V.......cpUYGekb02I',
read_consistency=ReadConsistency.EVENTUAL_CONSISTENCY,
timeout=30
)
# 指定数据库
db = client.database('db-test-by_ye')
# 指定集合
coll = db.collection('intelligent')
doc_lists = coll.searchById(
document_ids=['0001','0002'],
filter=Filter(Filter.In("question",["请问车险理赔时,全责一方和无责任一方收到待遇的区别", "买保险,一定要找代理人吗,直接去保险公司买不可以吗?"])),
params=SearchParams(ef=200),
limit=3,
retrieve_vector=True,
output_fields=['question','answer']
)
for i, docs in enumerate(doc_lists):
print(i)
for doc in docs:
print(doc)查询的相似度的数据如下:

当然我们也可以在网上找些问答系统的数据集进行测试,那法律问题的回答我们可以采用Elasticsearch进行搜索:
def create_mapping(self):
# 定义索引的映射关系
node_mappings = {
"mappings": {
self.doc_type: { # 索引中的类型
"properties": {
"question": { # 问题字段
"type": "text", # 字段类型为text(文本)
"analyzer": "ik_max_word", # 分词器为ik_max_word(中文分词器)
"search_analyzer": "ik_smart", # 搜索时使用的分词器为ik_smart(中文分词器)
"index": "true" # 控制该字段的值是否被索引
},
"answers": { # 答案字段
"type": "text", # 字段类型为text(文本)
"analyzer": "ik_max_word", # 分词器为ik_max_word(中文分词器)
"search_analyzer": "ik_smart", # 搜索时使用的分词器为ik_smart(中文分词器)
"index": "true" # 控制该字段的值是否被索引
},
}
}
}
}
# 如果索引不存在,则创建索引
if not self.es.indices.exists(index=self._index):
self.es.indices.create(index=self._index, body=node_mappings)
print("Create {} mapping successfully.".format(self._index))
else:
print("index({}) already exists.".format(self._index))得到的结果如下:
question:昨天把人家车刮了,要赔多少
answers: ['您好,建议协商处理,如果对方告了你们,就只能积极应诉了。', '您好,建议尽量协商处理,协商不成可起诉']
*******************************************************
question:最近丈夫经常家暴,我受不了了
answers: ['报警要求追究刑事责任。', '您好,建议起诉离婚并请求补偿。', '你好!可以起诉离婚,并主张精神损害赔偿。']
*******************************************************
question:毕业生拿了户口就跑路可以吗
answers: 您好,对于此类问题,您可以咨询公安部门
*******************************************************
question:孩子离家出走,怎么找回来
answers: ['孩子父母没有结婚,孩子母亲把孩子带走了?这样的话可以起诉要求抚养权的。毕竟母亲也是孩子的合法监护人,报警警察一般不受理。']
*******************************************************在数据安全方面腾讯云采用的是API 密钥访问作为身份验证的方式,API 密钥通常是由 API 提供者生成的一串字符串,用于标识 API 的调用者。在使用 API 时,调用者需要将 API 密钥作为参数传递给 API,以便 API 可以验证调用者的身份。腾讯云向量数据库使用 API 密钥来保护 API 访问的安全性,在发送 API 请求时,携带密钥 ID 和签名信息,以便腾讯云可以验证请求的合法性。

当恶意用户在不知道我们的API密钥情况下,访问我们的向量数据库就会产生与向量数据库通信发生故障,产生中断。

然后在外面的实例列表中找到相应的密钥管理来作为对于username和key的参数,密钥作为能够识别我们身份的令牌,腾讯云将密钥进行了加密处理,如下:

这里我们可以看到腾讯云设置的API密钥的长度,可以说是杜绝了黑客进行暴力破解的可能:

五、安全监控机制实操过程
腾讯云向量数据库如何进行网络流量、日志数据等表示为向量的安全监控,我们在探讨其在异常检测、模式识别和发现潜在安全威胁时应该采取什么措施,或者说未雨绸缪应该搭配腾讯云向量数据库设置怎样的防护手段呢?如下:
配置告警:腾讯云向量数据库在实例实时监控方面下了很大的功夫,当我们打开控制台的管理面板时,可以看到相当多的资源监控画面:
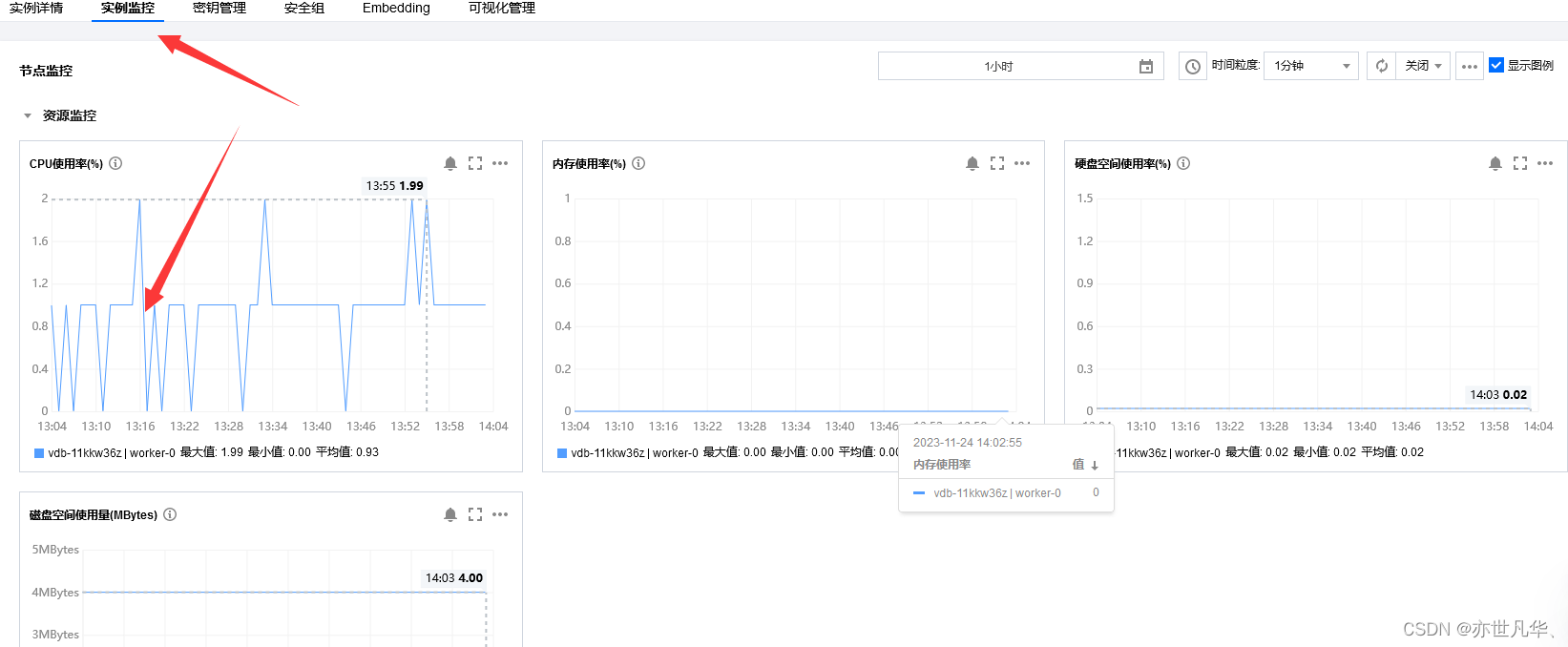
很人性化的一点就是,当我们的网站数据被恶意请求时,当前的面板能够实时的监听出来,而且给我们还设置了一些报警的阈值,比如说当用户恶意请求网站大量的流量时,控制台将会根据我们设置的阈值进行相应的报警处理,我们可以在想要监听用户访问资源的面板处进行报警设置:

配置相应的告警规则后,当用户恶意攻击我们的时候,就会触发告警规则,及时通知我们目前我数据正在被攻击,这样就给我们一个处理被攻击的一个机会,而不是等到已经被攻击完毕之后,我们才后知后觉的发现网站数据被攻击:

我们可以下载相应的开源工具 ann-benchmark-dev 进行向量数据库的性能测试,具体方式可以参考官网的性能白皮书,我们根据官网的提示配置相应的探索参数:

然后在终端执行如下命令:
python3 run.py --dataset sift-128-euclidean --local --force --parallelism 1 --algorithm vector_db --definitions=mytest.yml --runs 1首先要cd到当前的工具目录下执行命令进行测试:

我们在资源监控的位置就可以看到外面的资源正在被请求当中,这里设置阈值来进行安全告警完全是可以的:
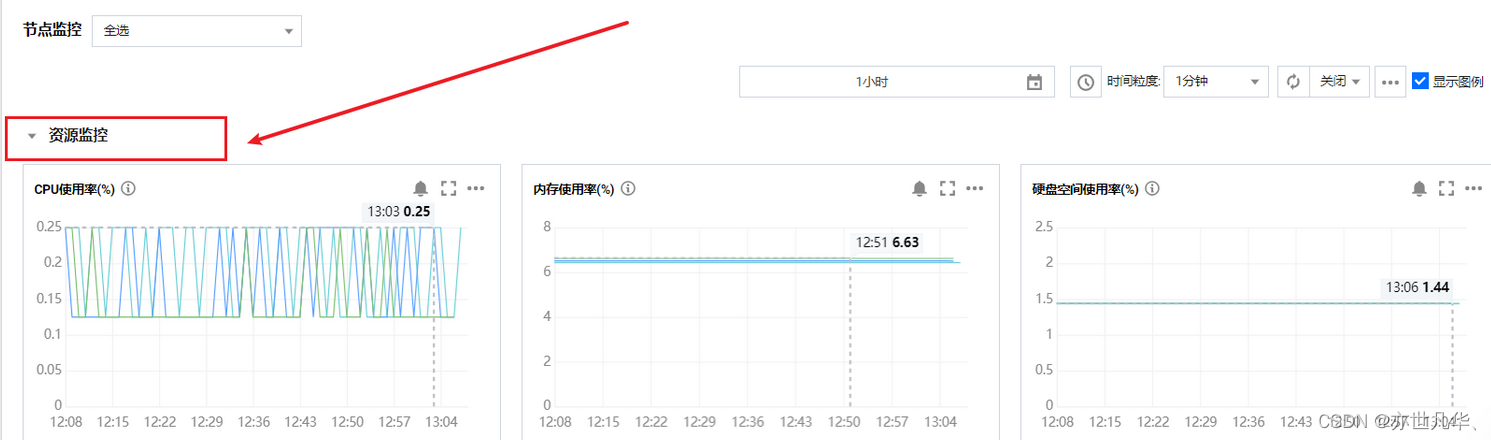
安全组:简单介绍如何防止网站被黑客攻击的有效方式,提升自己网站的安全级别,防止被黑的有效的方式可以备份!定时备份就算被攻击了也不慌!配置安全组,也是最有效的防护方式!
借助安全组我们可以限制某个ip段只能访问我们的服务器或者数据库,拿服务器举例来说,如果一个服务器不做任何限制的话是最容易被黑客攻击的,也就是说如果我们的所有端口都是开放的话就很容易被黑客入侵,如下:

在向量数据库当中也是可以进行配置相应的安全组的,我们在腾讯云向量数据库后台点击安全组,默认其给我们的是一个摩恩的安全组规则,其默认开放的也是80端口,这里如果我们可以根据需求进行一个规则的修改:

进行安全组规则的设置界面之后,我们进行添加规则的设置,可以根据需求添加相应的协议端口,如果我们本来已经存在的端口删掉的话,再次进行连接的话是已经连接不上了。

比如我们百度搜索ip,然后就会出现你当前所处地区的ip地址,我们可以将该ip地址添加到安全组规则当中:

然后给其编辑其入站规则即可:
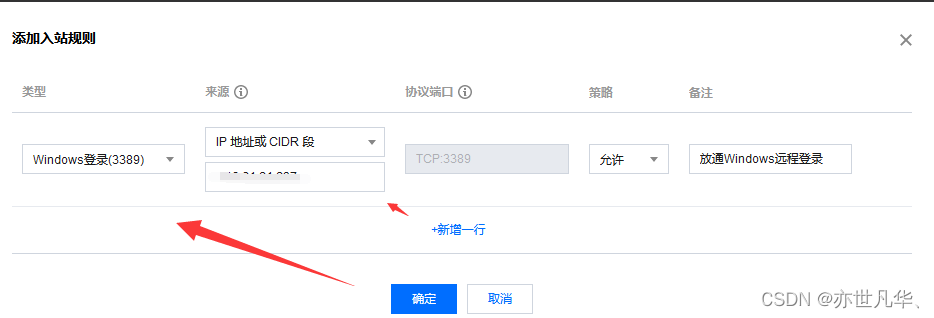
重置API密钥:API密钥涉及的范围很大,一旦有人掌握了我们的密钥,我们的向量数据库中的数据就会完完全全的暴露给别人,因为我们需要定期更新我们的密钥防止因为用户的操作失误从而导致API密钥泄露:

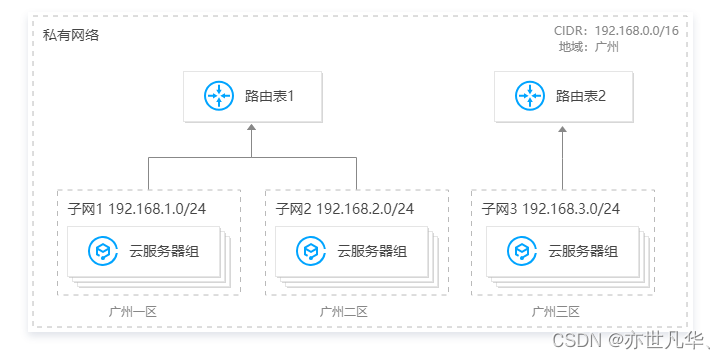
私有网络: 我们在上文初识腾讯云向量数据库的时候,已经简单介绍了一下关于安全监控机制涉及的网络层面上的事,在腾讯云数据库当中也是采用相应的私有网络进行安全防范,私有网络为云上逻辑隔离的网络空间,不同私有网络间相互隔离,保障业务安全:
目前腾讯云提供了数据库安全防护的可视化工具,不单单只是向量数据库,当我们使用其他数据库的时候也可以采用这个便利的可视化工具,可以大大加强我们的项目的防护:

六、个人总结及其未来展望
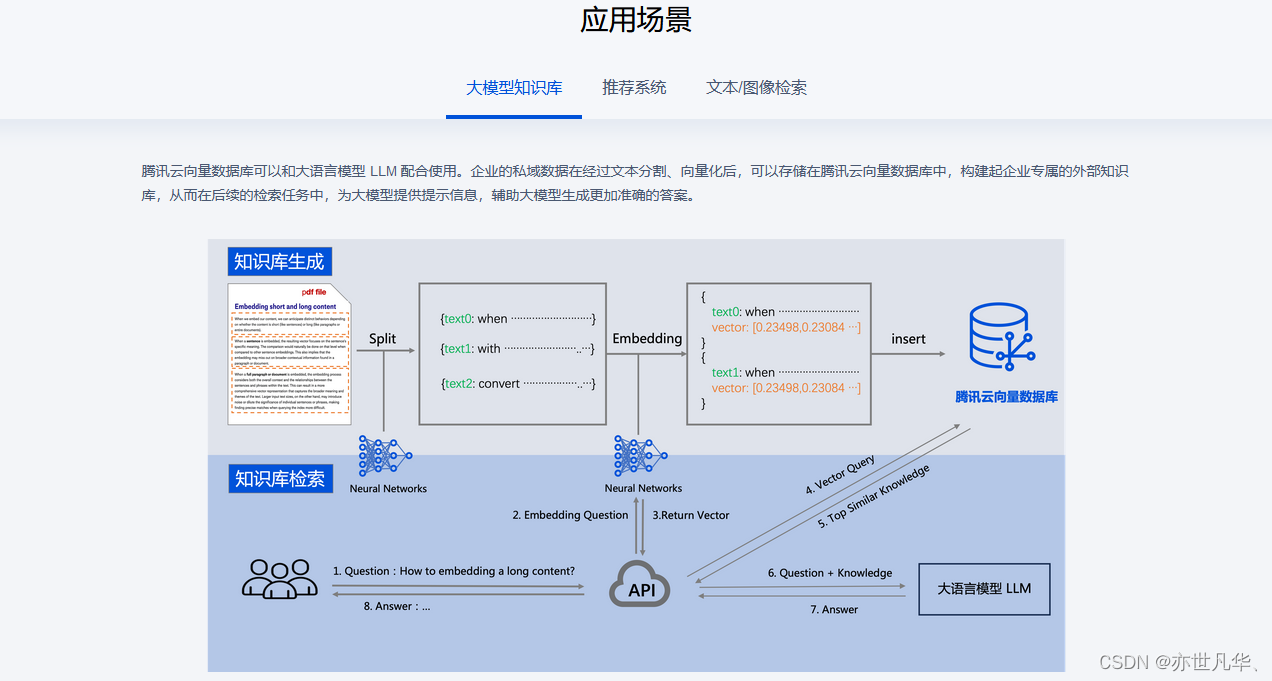
通过上文学习我们了解到了腾讯云向量数据库的安全监控机制在保护数据安全和隐私方面发挥着重要作用。其在实时监控、异常检测、审计日志、访问控制等方面都有很简便的操作性。当然除了安全方面,其应用场景也十分广泛,包括构建大型知识库、推荐系统、智能问答系统以及文本/图像检索等。
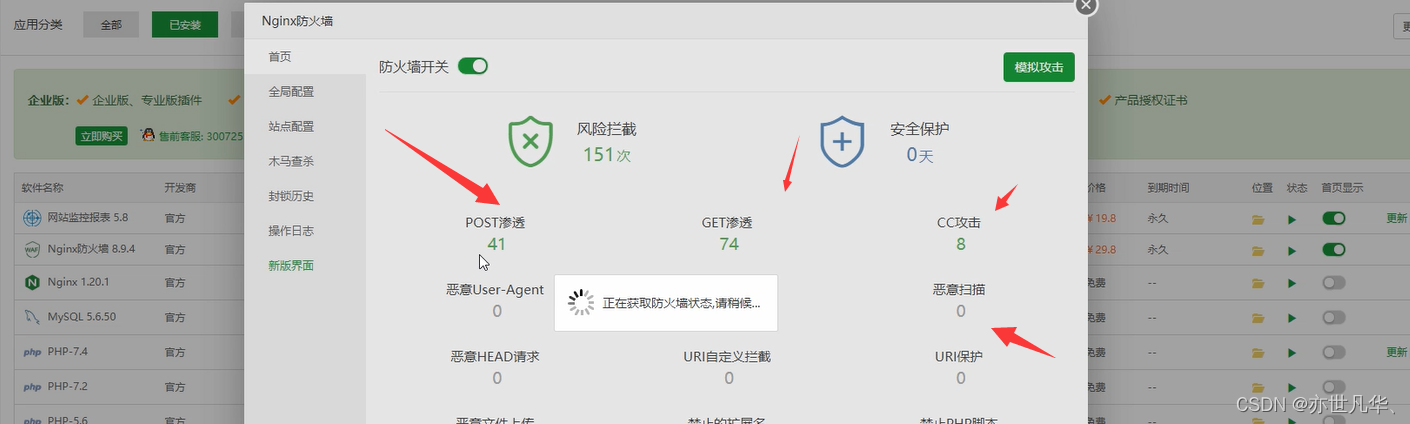
但是关于腾讯云向量数据库安全防范方面功能也不是很齐全,要知道数据库被黑客攻击的方式有很多,像SQL注入、跨站脚本攻击、未经授权的访问、拒绝服务攻击、密码破解等。我们不仅仅要实施严格的访问控制策略、启用审计日志并监控异常活动等操作还要定期备份数据库,并将备份文件存储在安全的位置、对用户输入数据进行验证和过滤,确保输入的数据符合预期的格式和范围等常规操作。宝塔面板就考虑多方面的因素
智者千虑,必有一失。再安全的防范如果连操作的员工都不知道基本的安全意识的话,也是无用的,所以建立安全意识培训计划,教育员工有关数据库安全的最佳实践和常见的安全威胁,这也是非常重要的一环。
总之,腾讯云向量数据库在保护数据安全和隐私方面已经做得很好,未来也可以不断优化和完善安全监控机制,以满足用户在安全性和合规性方面的不断提升的需求。具体的信息大家也可以查看一下官方对腾讯云数据库的见解:
