
目录
前言
腾讯云高性能应用服务 HAI 是为开发者量身打造的澎湃算力平台。无需复杂配置,便可享受即开即用的GPU云服务体验。在 HAI 中,根据应用智能匹配并推选出最适合的GPU算力资源,以确保您在数据科学、LLM、AI作画等高性能应用中获得最佳性价比。
本文主要是通过 HAI 部署了StableDiffusionWebUI,StableDiffusionWebUI是基于StableDiffusion开源模型进行AI绘画,AI绘画是一种利用深度学习算法进行创作的绘图方式,广泛应用于数字媒体、游戏、动画、电影、广告等领域。
一、选择 HAI部署的优势
使用传统方式GPU服务器会遇到各种问题,比如:GPU卡型多样,算力、显存差异大,选型困难;环境配置复杂、模型安装和调试门槛高;各类插件迭代频繁,难以在进行环境管理。然而 HAI 部署的StableDiffusionWebUI具有很大优势:
- 智能匹配算力,多种算力套餐满足不同需求的绘图性能。
- 预置主流AI作画模型及常用插件,无需手动部署,支持即开即用。
- 动态更新模型版本,确保模型版本与时俱进,无需频繁操作。
二、HAI 搭建AI绘图服务实现思路
本次我们使用腾讯云高性能应用服务 HAI 体验快速搭建并使用AI模型 StableDiffusion ,实现思路如下:
1、体验 高性能应用服务 HAI 一键部署 StableDiffusion AIGC
2、启动 StableDiffusionWebUI 进行文生图模型推理
3、开发者体验 JupyterLab 进行 StableDiffusion API 的部署
4、开发者使用 Cloud Studio 快速开发调用 StableDiffusion API 的前端Web页面
三、生成设计图操作流程
使用StableDiffusionWebUI需要注册腾讯云账号,注册地址:https://cloud.tencent.com/register,注册之后进行登录。然后进入到HAI应用服务页面,申请资格,地址:https://cloud.tencent.com/act/pro/hai?from=21361。申请成功之后就可以体验HAI应用服务。
1、新建HAI应用
在算力管理页面新建HAI应用

因为我们要使用AI绘画功能,所以选择AI模型Stable Diffusion,然后点击购买。
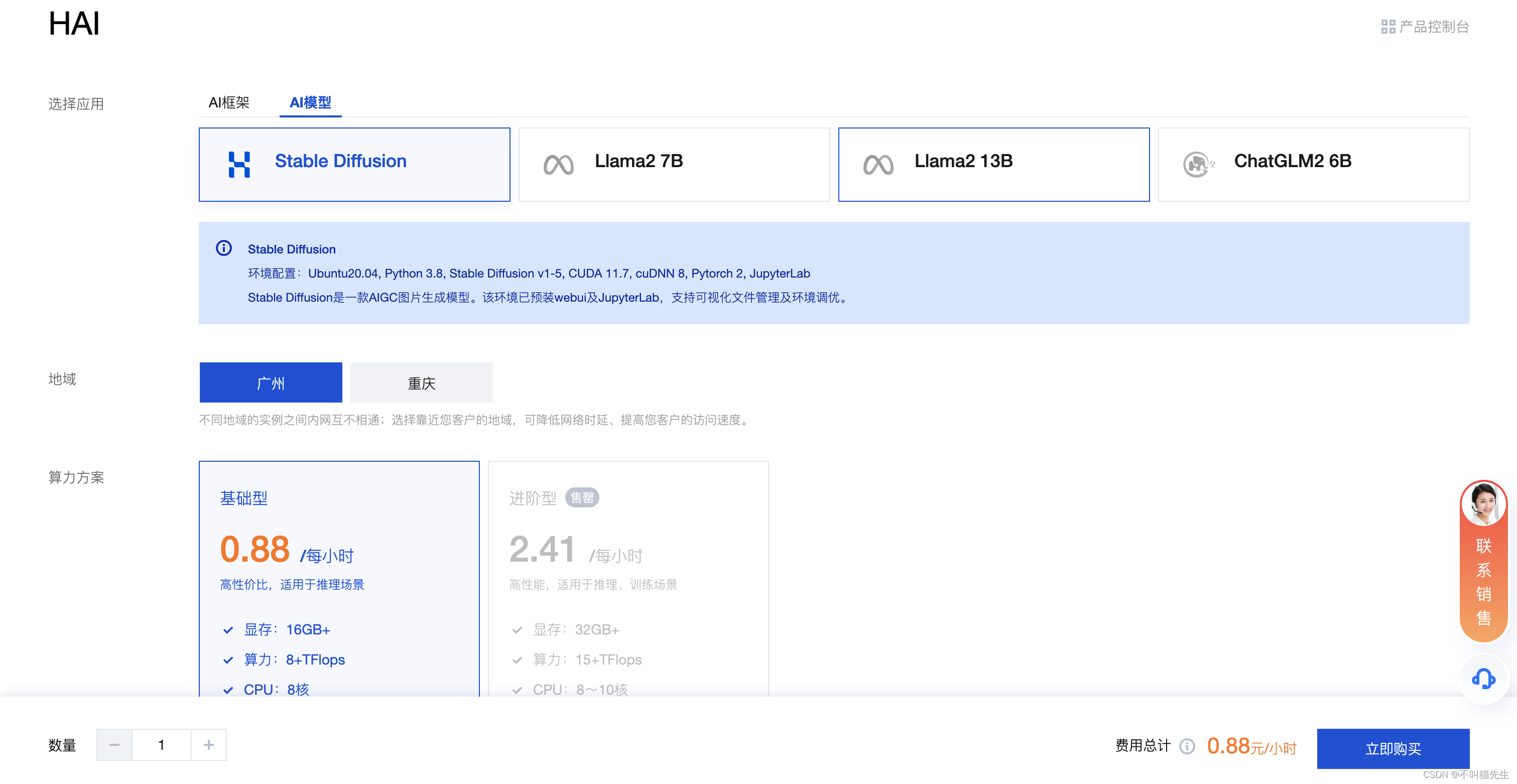
购买完成后应用会自动创建,大概需要3-8分钟。
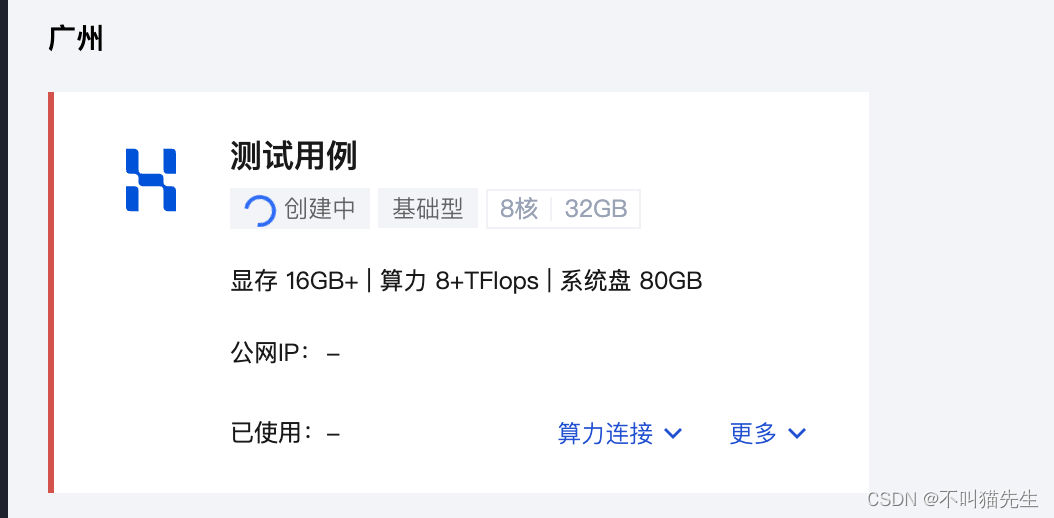
之后选择StableDiffusionWebUI
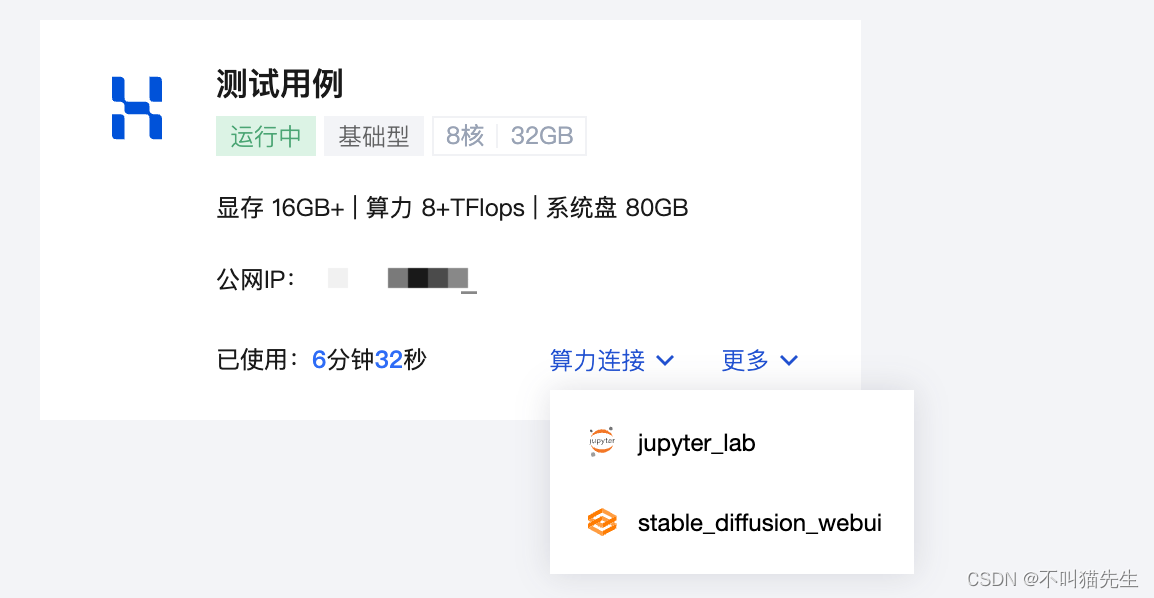
2、StableDiffusionWebUI
StableDiffusionWebUI 主页面如下图所示。
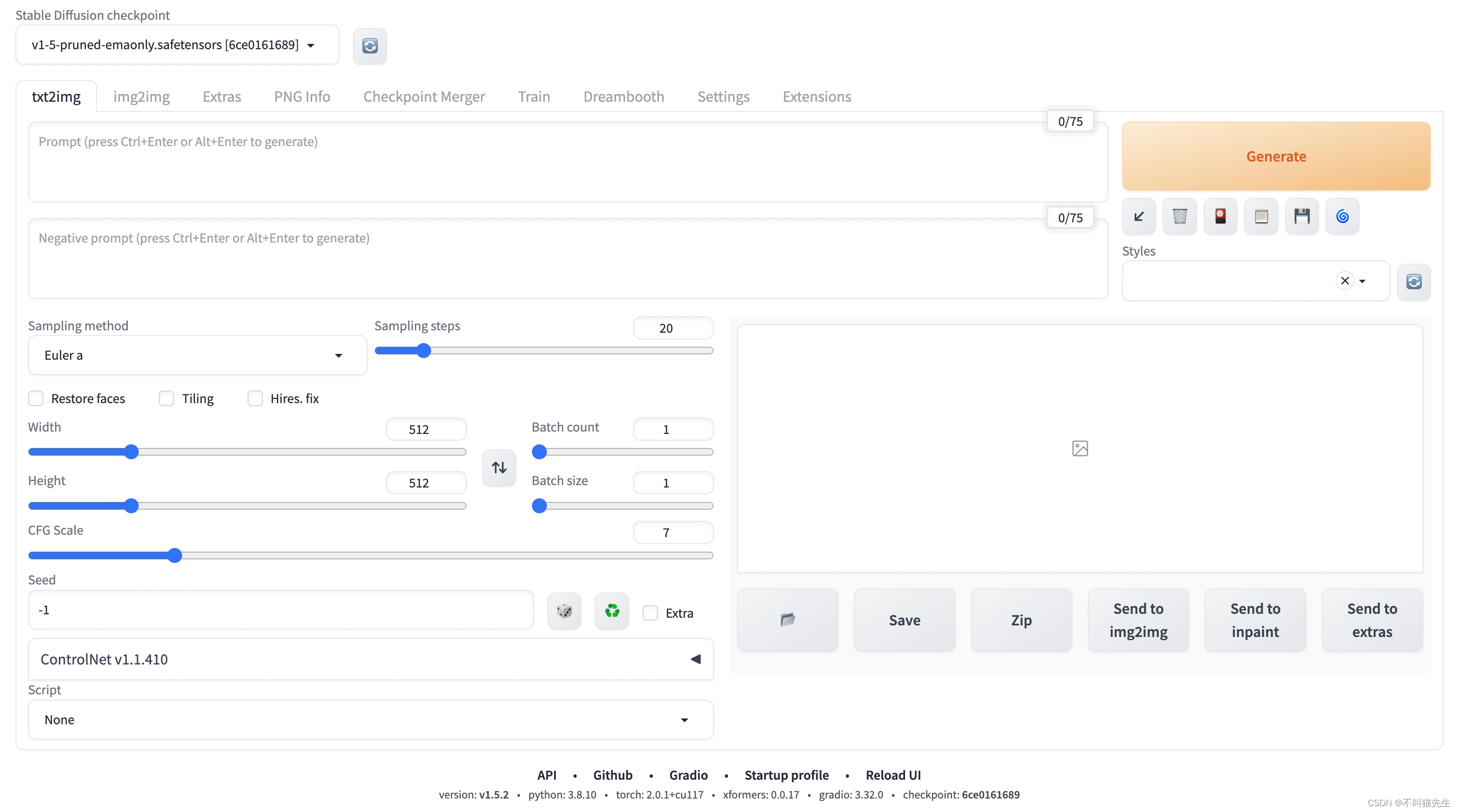
其中相关配置属性解释如下:
- 提示词:主要描述图像,包括内容风格等信息,原始的webui会对这个地方有字数的限制,可以安装一些插件突破字数的限制
- 反向提示词:为了提供给模型,我们不需要的风格
- 提示词相关性(CFG scale):分类器自由引导尺度——图像与提示符的一致程度——越低的值产生的结果越有创意,数值越大成图越贴近描述文本。一般设置为7
- 采样方法(Sampling method):采样模式,即扩散算法的去噪声采样模式会影响其效果,不同的采样模式的结果会有很大差异,一般是默认选择euler,具体效果我也在逐步尝试中。
- 采样迭代步数(Sampling steps):在使用扩散模型生成图片时所进行的迭代步骤。每经过一次迭代,AI就有更多的机会去比对prompt和当前结果,并作出相应的调整。需要注意的是,更高的迭代步数会消耗更多的计算时间和成本,但并不意味着一定会得到更好的结果。然而,如果迭代步数过少,一般不少于50,则图像质量肯定会下降
- 随机种子(Seed):随机数种子,生成每张图片时的随机种子,这个种子是用来作为确定扩散初始状态的基础。不懂的话,用随机的即可
(1)功能介绍
StableDiffusionWebUI是基于StableDiffusion开源模型开发的,具有以下功能:
-
文生图
根据描述生成任何图像 -
智能识别:
Stable Diffusion可以智能识别用户上传的图片,并自动调整图片质量和色彩,让图片更加清晰、饱满。 -
风格转换:
Stable Diffusion可以将用户上传的图片转换成不同的艺术风格,如印象派、后印象派、立体派等等,让图片更加艺术化。 -
人像修复:
Stable Diffusion可以自动识别人像并进行修复,去除皱纹、瑕疵等不良痕迹,让人像更加美观自然。 -
图像融合:
Stable Diffusion可以将多张图片进行融合,生成全新的图像,让用户可以尝试不同的创意和设计。 -
图像去噪:
Stable Diffusion可以自动去除图片中的噪点,让图片更加干净、清晰。
(2)页面转中文
首先我们先把页面换成中文。
选择Extensions菜单中的Available菜单,然后取消localization勾选,勾选script,之后点击 Load from
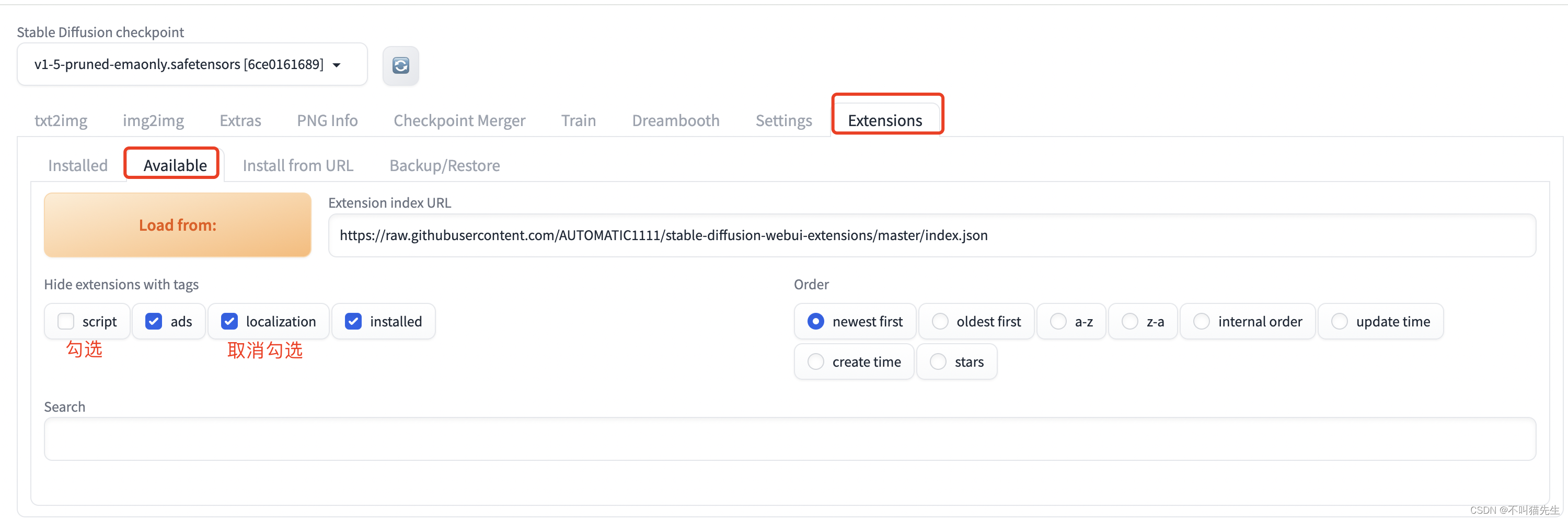
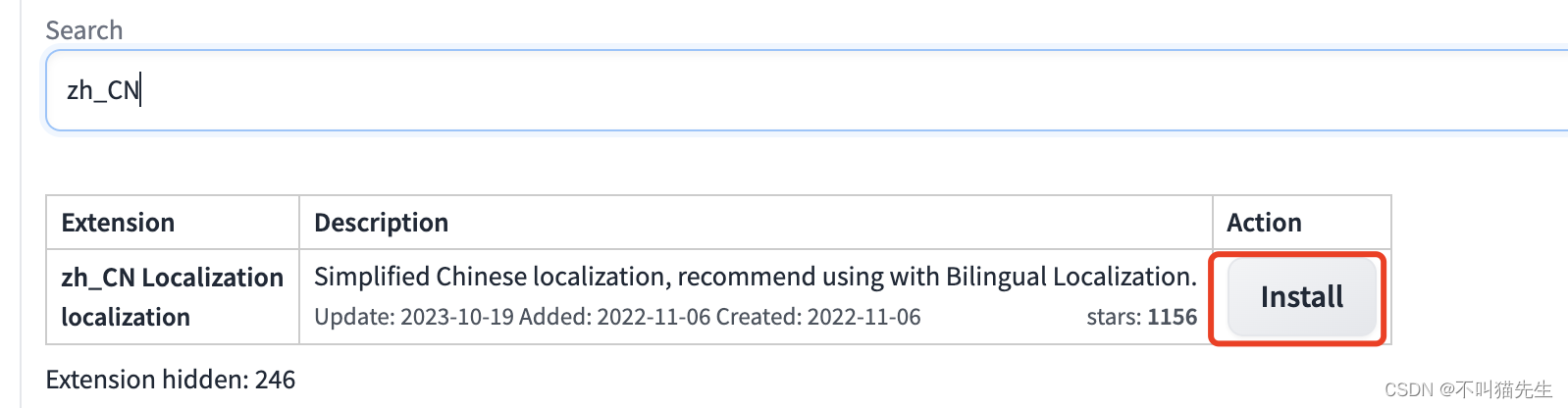
然后在搜索框中搜索:zh_CN,

点击Install进行安装。
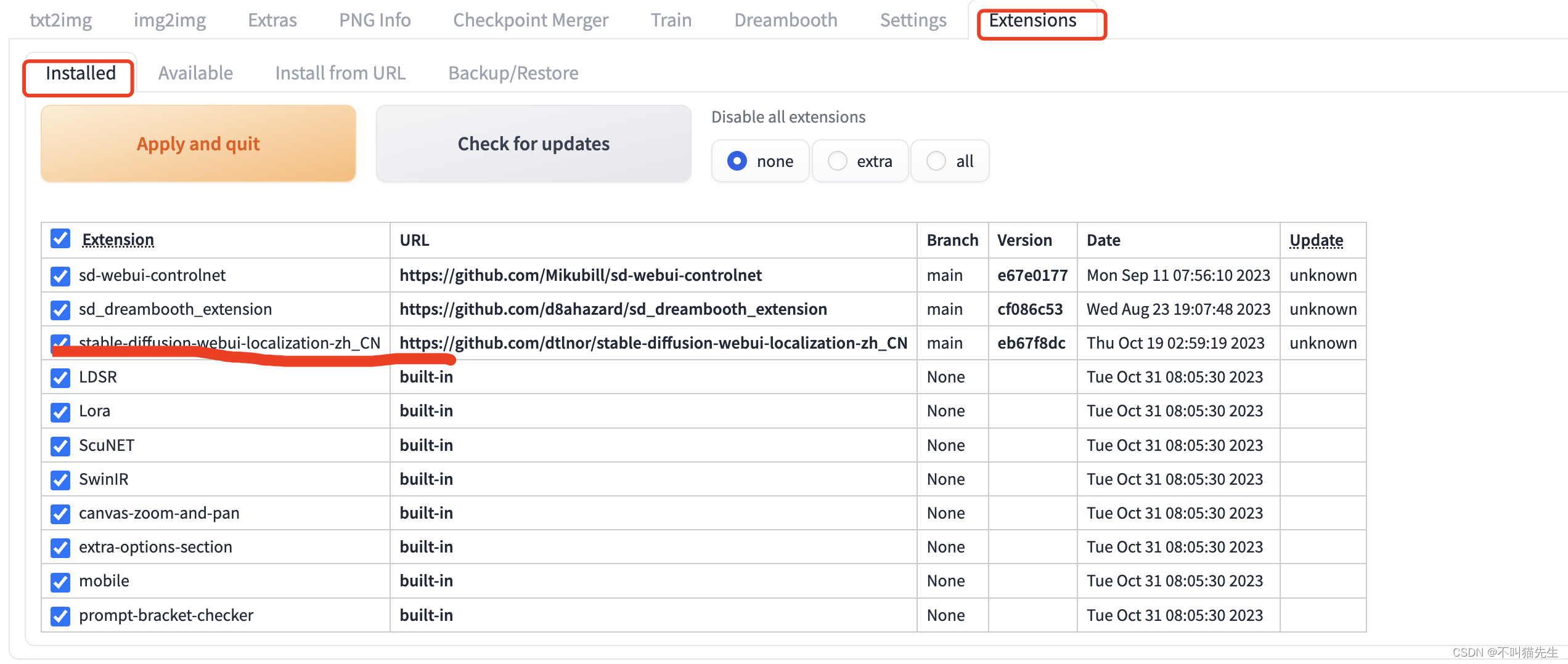
安装成功后,我们可以在Extensions菜单中的Installed菜单看到安装的stable-diffusion-webui-localization-zh_CN
最后在Setting菜单中选择User interface,在Localization (requires restart) 下拉菜单中选择zh_CN
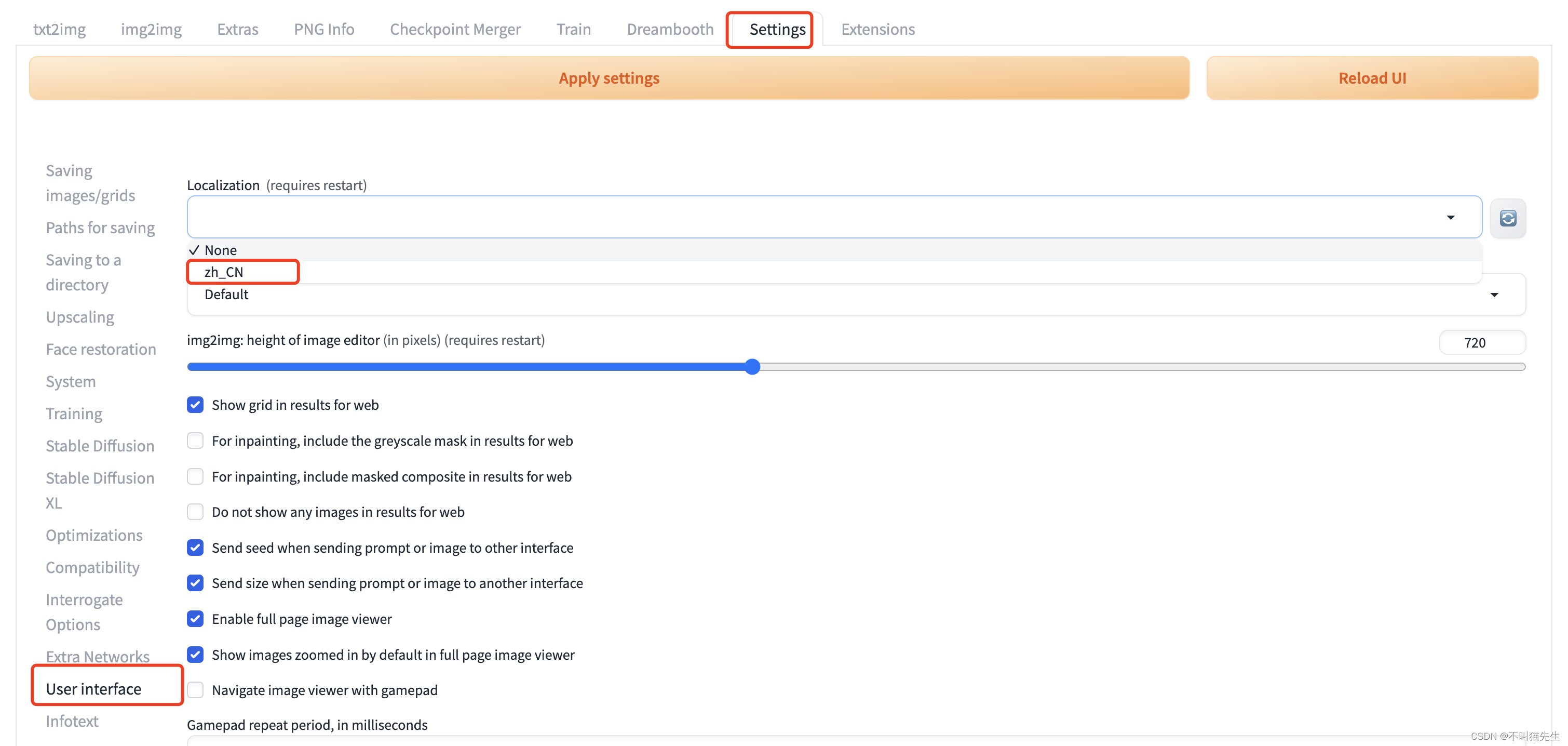
最后先点击Apply setting,然后再点击Reload UI,页面就变成中文了。
(3)线稿生成图
首先进行关键词设置。
正向关键词:
CBD 办公场景,宽敞明亮,有格调,高清摄影,广告级修图,8K 高清,CBD office scene,Bright and spacious,There is style,HD photography,Ad-level retouching,8K HD,
反向关键词:
NSFW,nude,naked,porn,(worst quality, low quality:1.4),deformed
iris,deformed pupils,(deformed,distorteddisfigured:1.3)cropped,out of
frame,poorlydrawn,badanatomy,wronganatomy,extralimb,missinglimb,floatinglimbs,cdonedface(mutatedhandsandfingers:1.4),
disconnectedlimbs,extralegs,fusedfingers,toomanyfingers,longneck,mutation,mutated,ugly,
disgusting.amputation,blurry,jpegartifacts,watermark,watermarked,text,Signature,sketch,
基础设置:
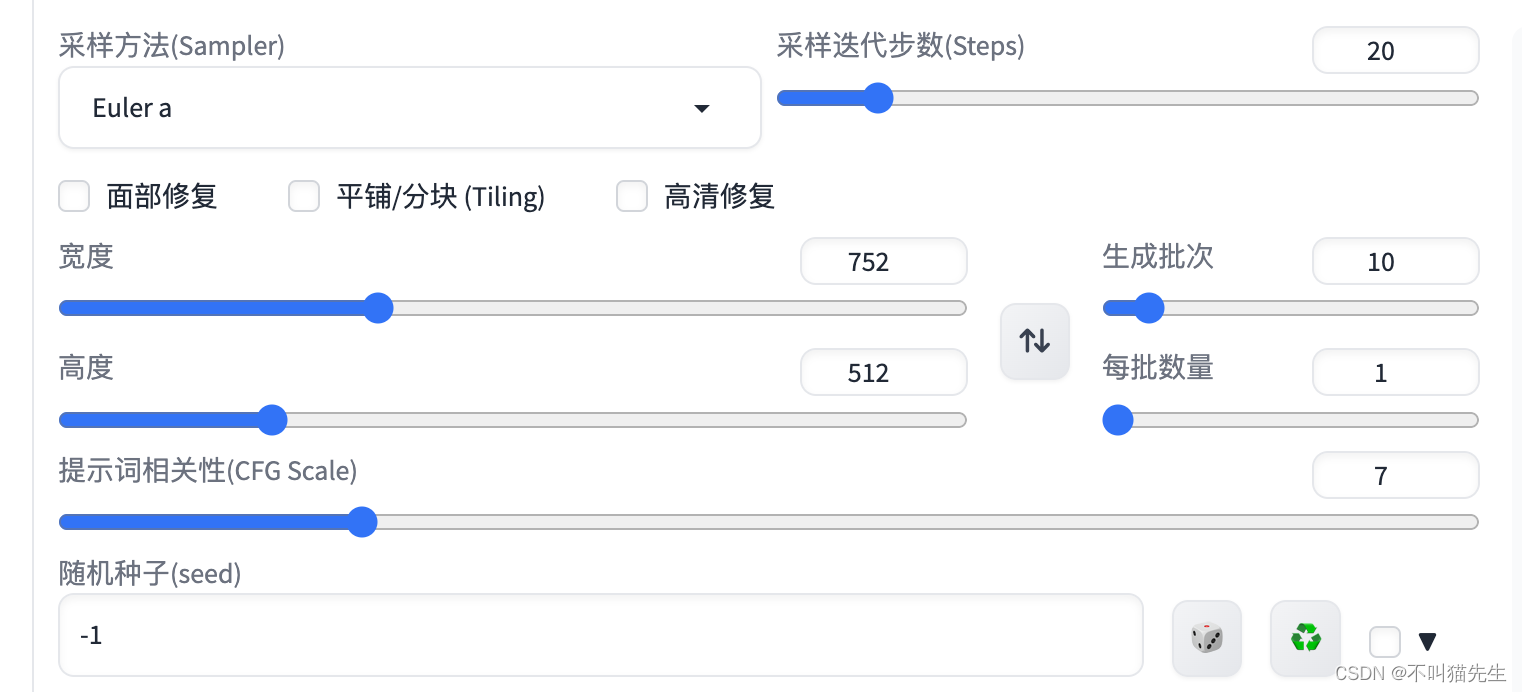
ControlNet设置:
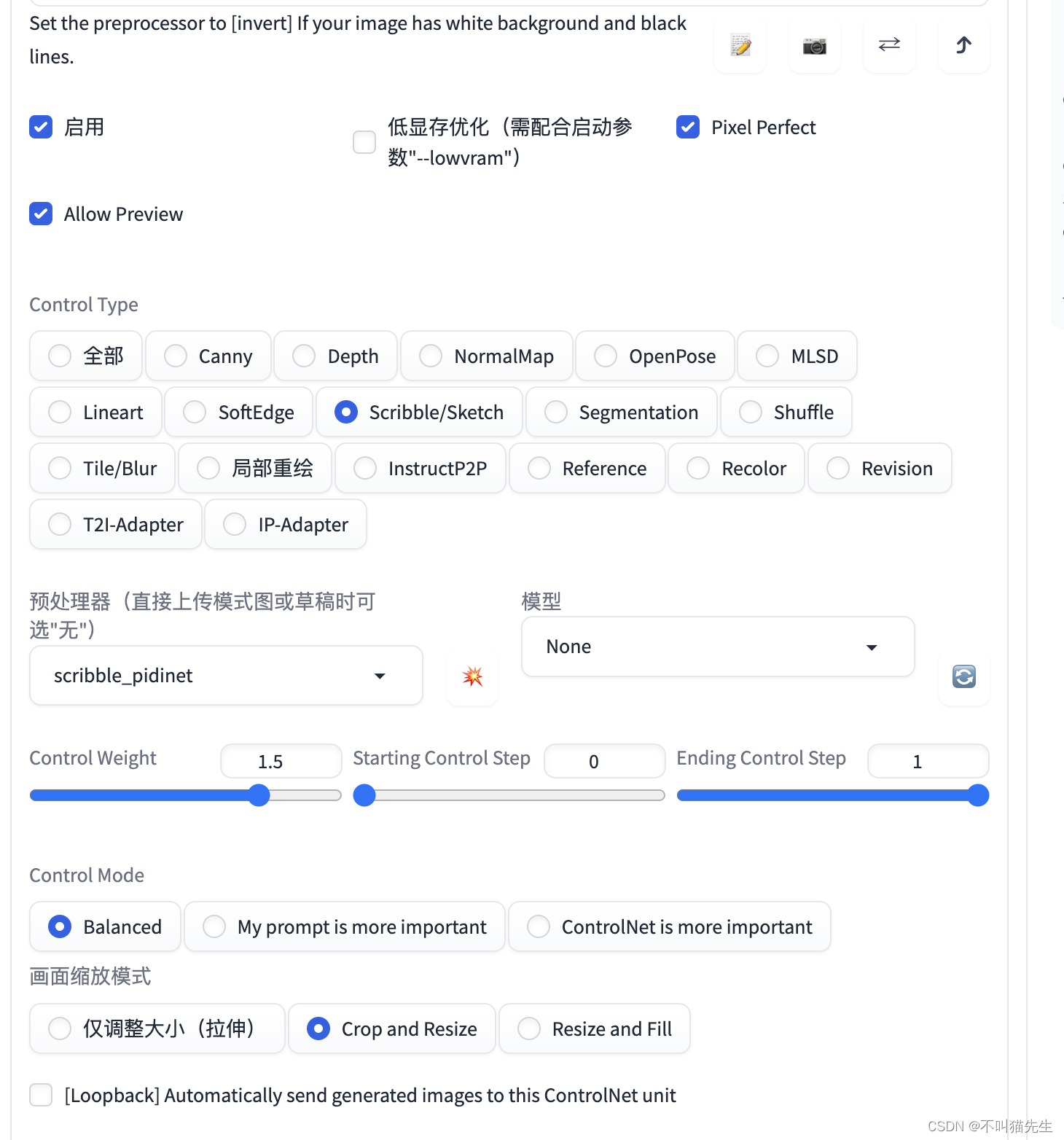
ControlNet 的作用是通过添加额外控制条件,来引导 Stable Diffusion 按照创作者的创作思路生成图像,从而提升 AI 图像生成的可控性和精度。在使用 ControlNet 前,需要确保已经正确安装 Stable Diffusion 和 ControlNet 插件。
输入关键词的同时将脑子里的想法通过绘图软件绘制成线稿图(这个线稿的布局及外形决定了出图的结构及布局),将绘制好的草图上传至ControlNet 插件里选择 scribble 模型(实际操作界面如下)。
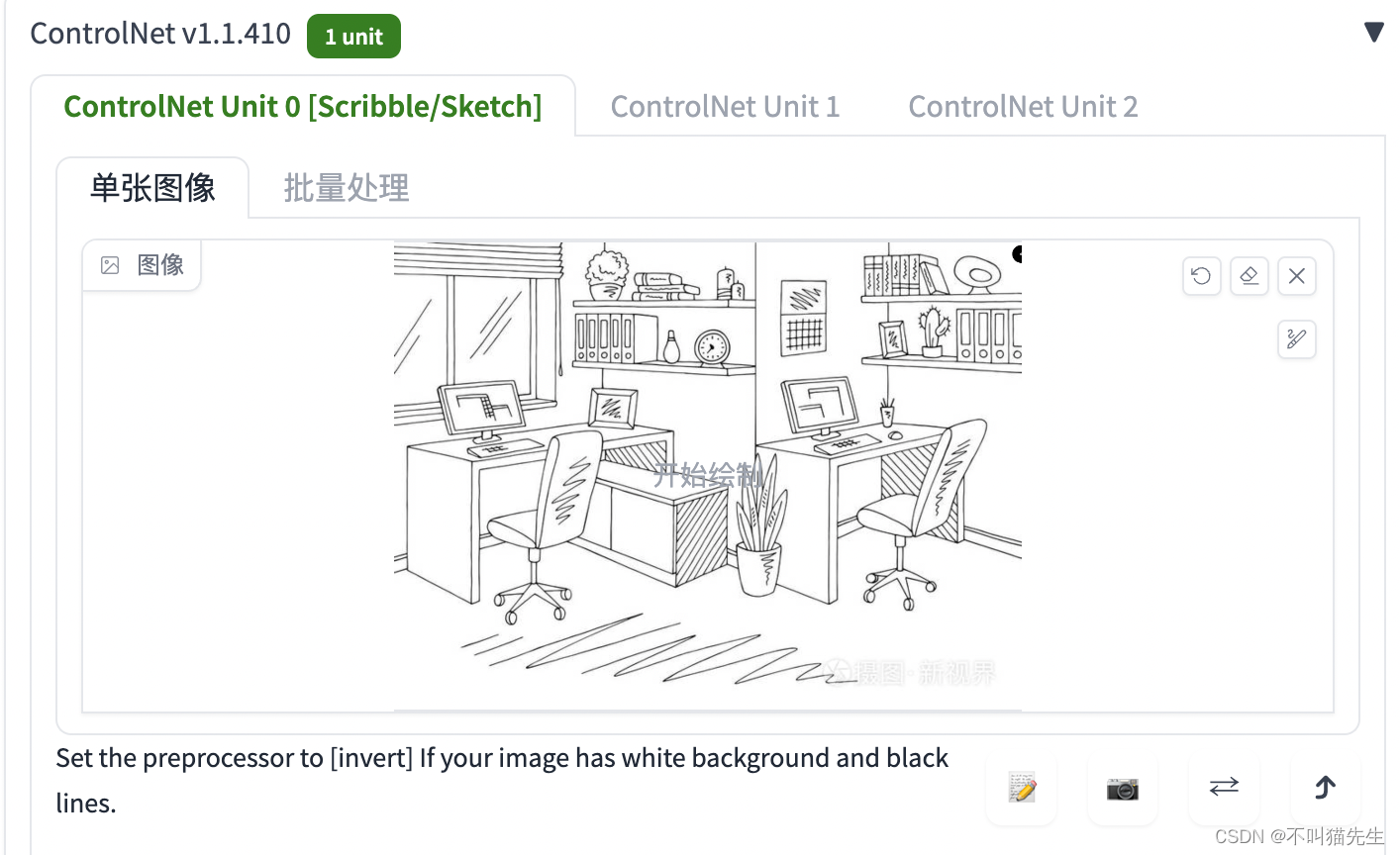
线稿图如下所示:

然后对其他选项进行设置
根据上面的定制化设置,然后点击生成按钮,最终生成的结果如下:
















四、部署StableDiffusionWebUI服务
1、开启API服务
在算力管理界面选择jupyter_lab,
选择终端。

命令参数描述:
- –nowebui:以 API 模式启动
- –xformers:使用xformers库。极大地改善了内存消耗和速度。
- –opt-split-attention:Cross attention layer optimization 优化显着减少了内存使用,几乎没有成本(一些报告改进了性能)。黑魔法。默认情况下torch.cuda,包括 NVidia 和 AMD 卡。
- –listen:默认启动绑定的 ip 是 127.0.0.1,只能是你自己电脑可以访问 webui,如果你想让同个局域网的人都可以访问的话,可以配置该参数(会自动绑定 0.0.0.0 ip)。
- –port:默认端口是 7860,如果想换个端口,可以配置该参数,例如:–port 7862
- –gradio-auth username:password:如果你希望给 webui 设置登录密码,可以配置该参数,例如:–gradio-auth GitLqr:123456。
输入下面代码。
cd /root/stable-diffusion-webui
python launch.py --nowebui --xformers --opt-split-attention --listen --port 7862
执行成功如下图所示:
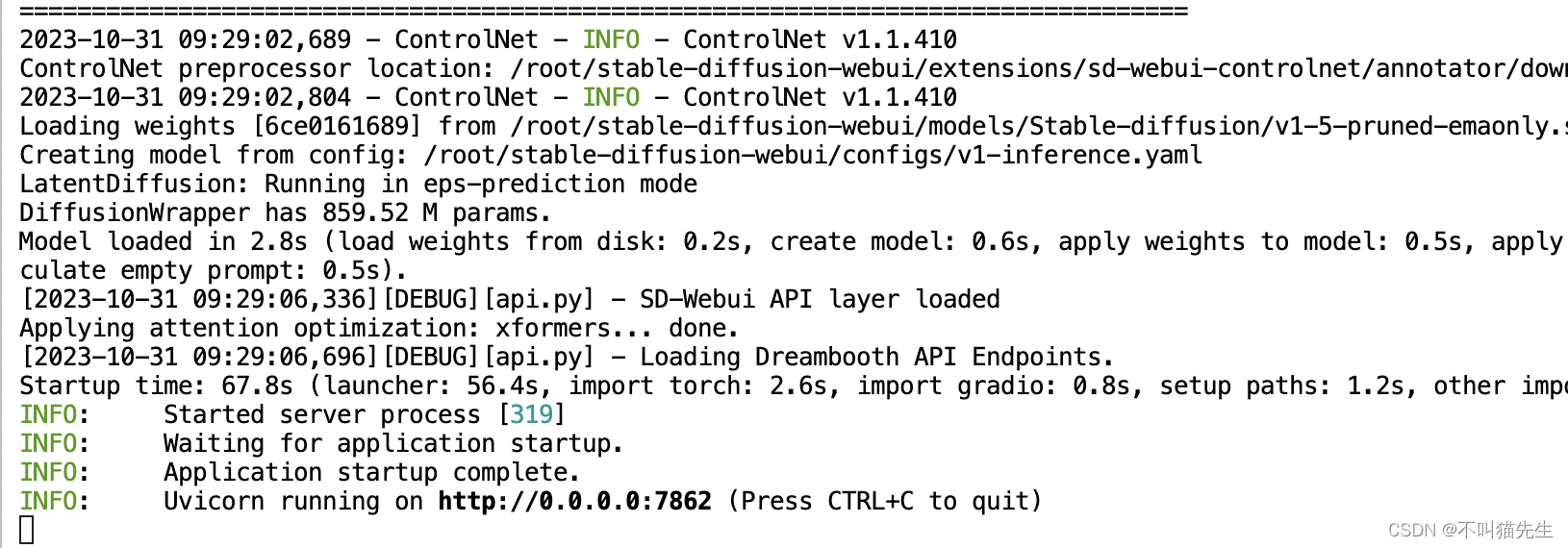
2、配置端口
点击创建的实例到详情页面,在端口配置卡片中点击编辑规则按钮配置端口。
选择添加规则
填写下面信息,API服务的端口就设置好啦
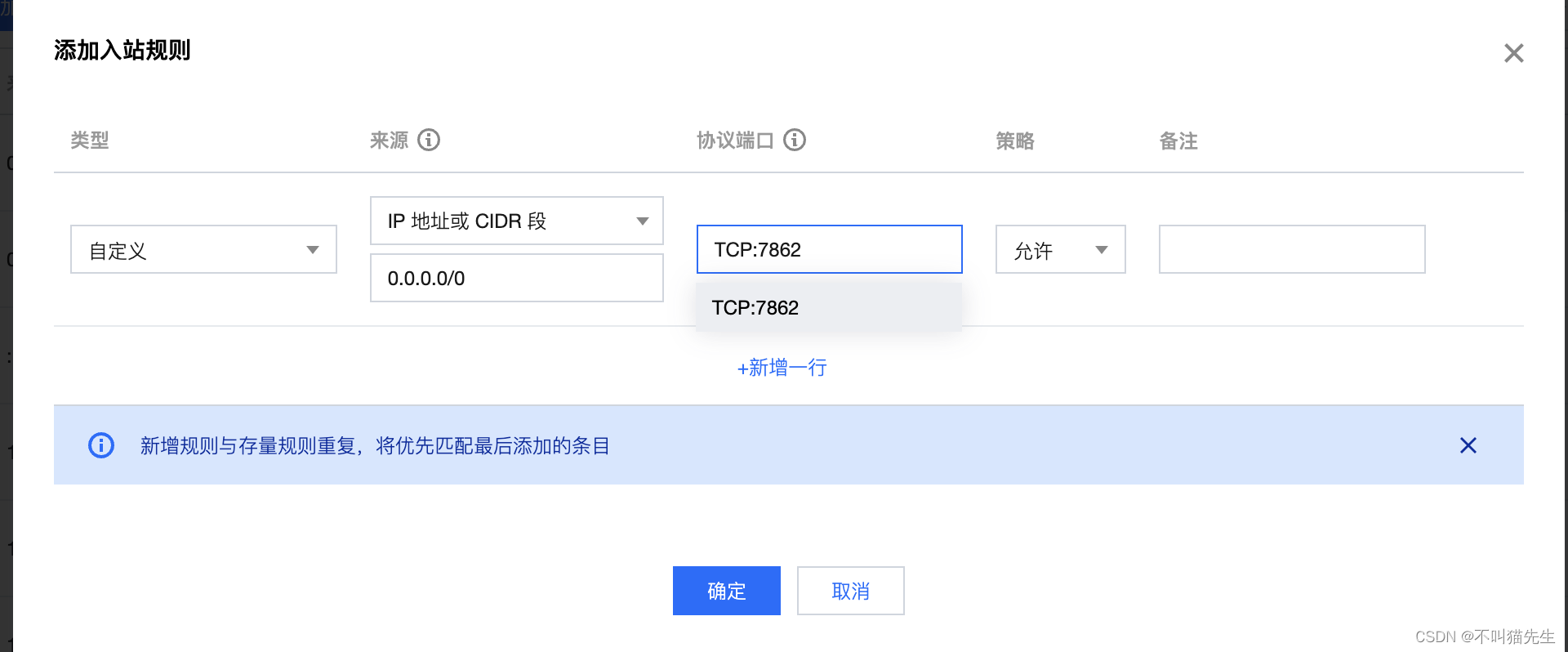
然后输入ip+端口+/docs,就可以看到API文档啦。
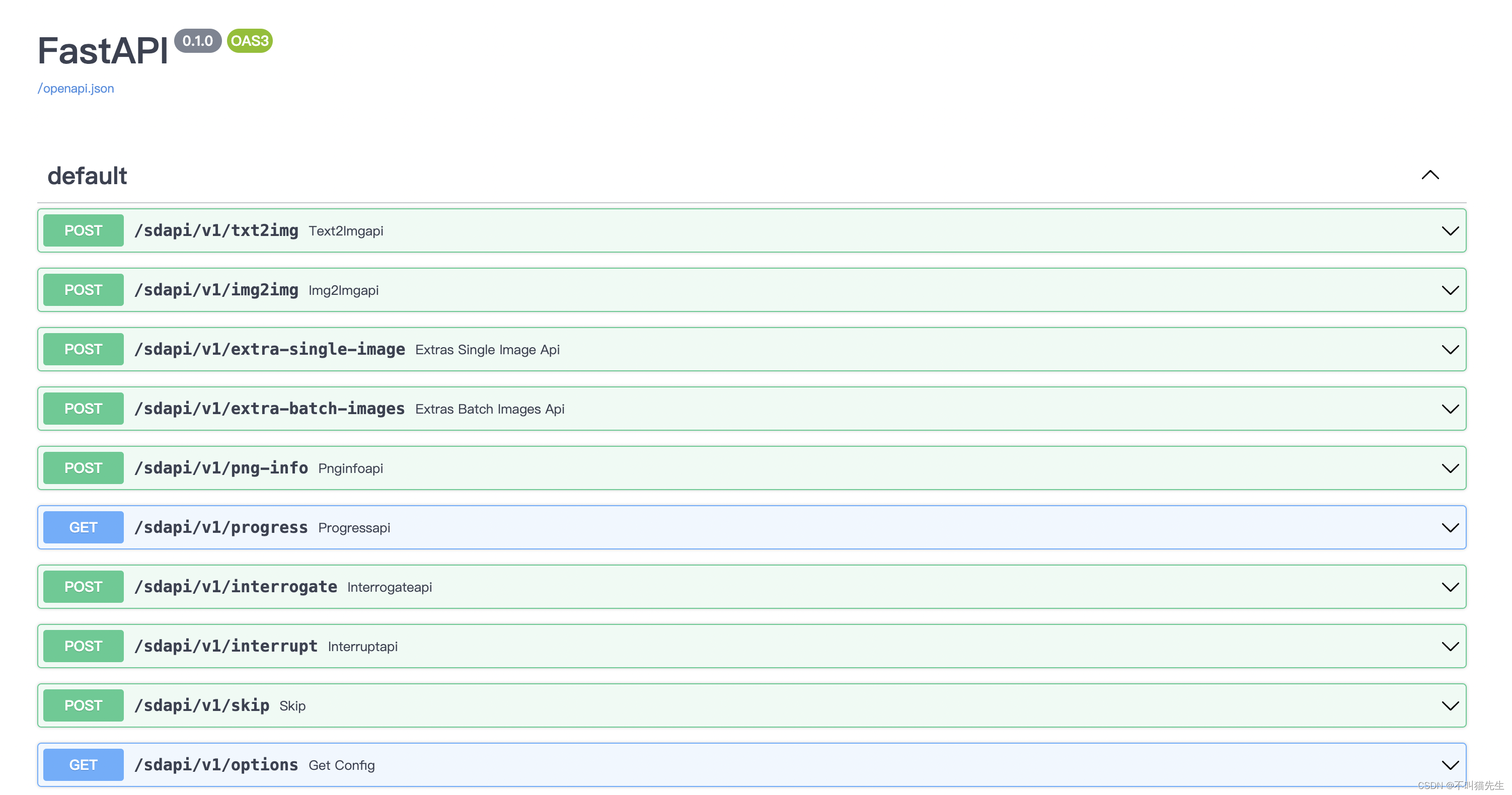
代码部署
前往gitee下载代码:链接直达
修改vite.config.js配置文件:
import {
defineConfig } from 'vite'
import vue from '@vitejs/plugin-vue'
// https://vitejs.dev/config/
export default defineConfig({
plugins: [vue()],
// 服务端代理
server: {
// 监听主机 127.0.0.1,如果是 0.0.0.0 则代表所有ip都可以访问该前端项目
host: "127.0.0.1", //这里可不用管
// 将 /sdapi、 /controlnet 开头的请求都代理到服务端地址 http://127.0.0.1:7862
proxy: {
'/sdapi': {
target: 'http://xxxxx', //这里配置为您的服务端地址+端口
changeOrigin: true
},
'/controlnet': {
target: 'http://xxxxx', //这里配置为您的服务端地址+端口
changeOrigin: true
}
}
}
})
之后启动程序,输入:
npm run dev
会看到下面的界面,说明已经成功部署啦
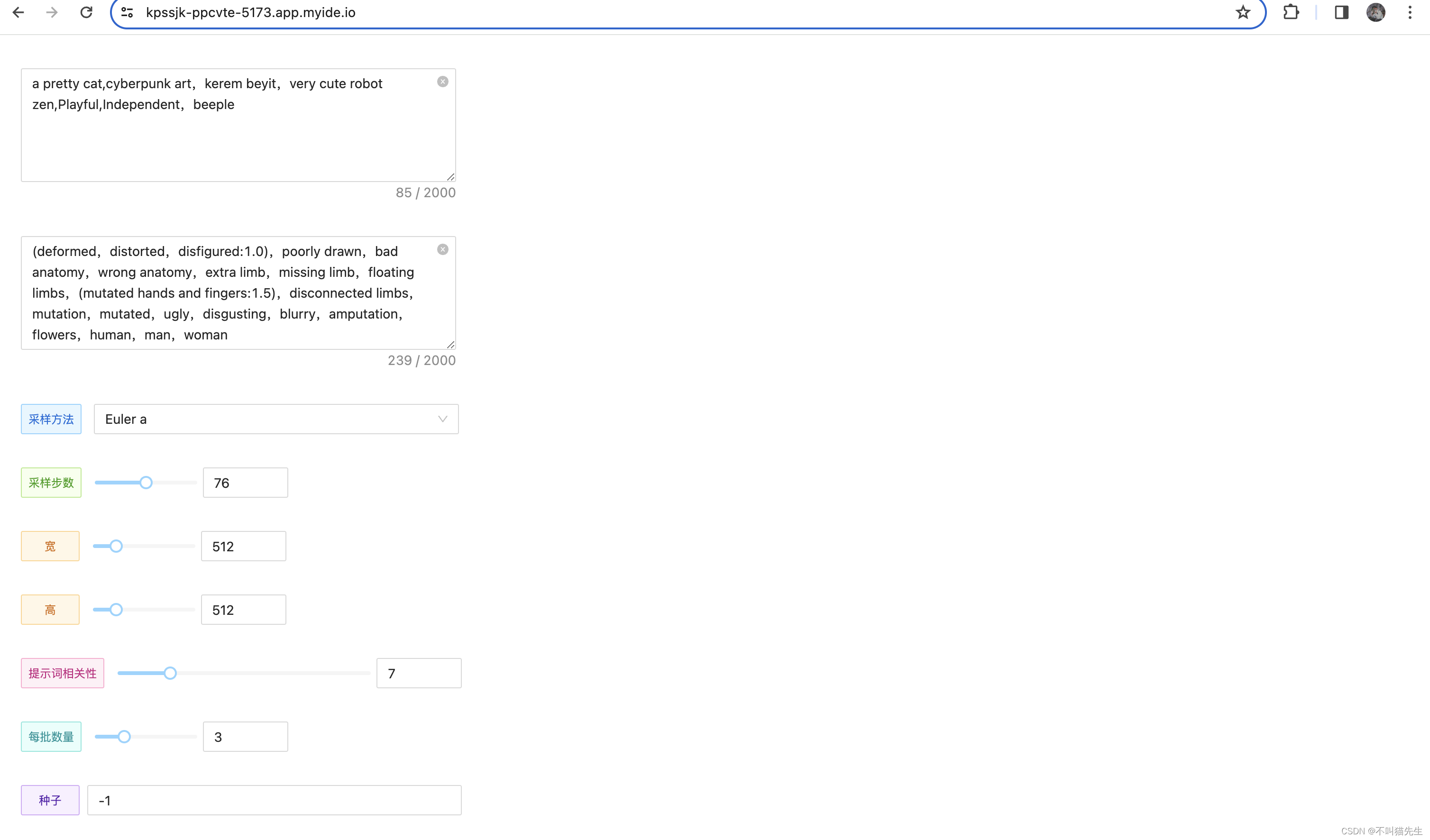
然后进行基础设置。
| 参数名 | 值 |
|---|---|
| 正向关键词 | CBD 办公场景,宽敞明亮,有格调,高清摄影,广告级修图,8K 高清,CBD office scene,Bright and spacious,There is style,HD photography,Ad-level retouching,8K HD, |
| 反向关键词 | poorlydrawn,badanatomy,wronganatomy,extralimb,missinglimb,floatinglimbs,cdonedface(mutatedhandsandfingers:1.4),disconnectedlimbs,extralegs,fusedfingers,toomanyfingers,longneck,mutation,mutated,ugly,disgusting.amputation,blurry,jpegartifacts,watermark,watermarked,text,Signature,sketch, |
| 提示词相关性(CFG scale) | 7 |
| 采样方法(Sampling method) | 20 |
| 采样步数(Sampling steps) | |
| 随机种子(Seed) | -1 |
| 每批次数量 | 1 |
然后点击文生图按钮就可以啦!
总结
本次实验实现了高性能应用服务 HAI 部署 StableDiffusion 运行环境轻松拿捏AI作画,开箱即用,可以快速上手。StableDiffusionWebUI能够通过我们设置最终输出我们需要的图片,可以感受到人工智能的真的非常强大。AI绘画学习成本其实并不高,并且对我们的绘画技能要求还降低了许多。
最后期待大家一起探索 高性能应用服务 HAI 更多的功能,为工作中赋能增效降本!
官方地址:https://cloud.tencent.com/act/pro/hai