
1. 简介
Kubernetes通过设备插件框架提供对特殊硬件资源的访问,如NVIDIA GPU、⽹卡、Infiniband适配器和其他设备。但是,配置和管理带有这些硬件资源的节点需要配置多个软件组件,例如驱动程序、容器运⾏时或其他库,这些组件组合起来⽐较困难且容易出错。GPU Operator相关架构如下:

可以从架构上看到,NVIDIA GPU Operator使⽤Kubernetes中的Operator框架⾃动管理提供GPU所需的所有NVIDIA软件组件。这些组件包括NVIDIA驱动程序(启⽤CUDA),⽤于GPU的Kubernetes设备插件,NVIDIA容器⼯具包,使⽤GFD的⾃动节点标记,基于DCGM的监控等。NVIDIA官⽅的GPU Operator可以很⽅便的安装配置组合,为容器应⽤使⽤GPU提供了很⼤的便
利性。⽬前最新的版本是23.9.0,⽀持的相关平台如下
| Deployment Options |
|---|
| Bare Metal |
| Virtual machines with GPU Passthrough |
| Virtual machines with NVIDIA vGPU based products |
| Hypervisors |
|---|
| VMware vSphere 7 and 8 |
| Red Hat Enterprise Linux KVM |
| Red Hat Virtualization (RHV) |
| Operating System | Kubernetes | Red Hat OpenShift | VMWare vSphere with Tanzu | Rancher Kubernetes Engine 2 | HPE Ezmeral Runtime Enterprise | Can Mic |
|---|---|---|---|---|---|---|
| Ubuntu20.04 LTS | 1.25—1.28 | 7.0 U3c,8.0 U2 | 1.25—1.28 | |||
| Ubuntu22.04 LTS | 1.25—1.28 | 1.26 | ||||
| CentOS 7 | 1.25—1.28 | |||||
| Red Hat Core OS | 4.9—4.14 | |||||
| Red Hat Enterprise Linux 8.4,8.6, 8.7, 8.8 | 1.25—1.28 | 1.25—1.28 | ||||
| Red Hat Enterprise Linux 8.4, 8.5 | 5.5 |
GPU Operator在如下组合上官⽅进⾏过验证:
| Operating System | Containerd 1.4 - 1.7 | CRI-O |
|---|---|---|
| Ubuntu 20.04 LTS | Yes | Yes |
| Ubuntu 22.04 LTS | Yes | Yes |
| CentOS 7 | Yes | No |
| Red Hat Core OS (RHCOS) | No | Yes |
| Red Hat Enterprise Linux 8 | Yes | Yes |
2. Kubernetes 安装
从GPU Operator⽀持列表上看,Kubernetes最低版本为1.25。对于OS的⽀持上,看起来对Ubuntu和RHEL⽀持⽐较好。另外Dockershim已经从Kubernetes 1.24版中移除。因此如果Container Runtime选择Deocker Engine,那么需要额外cri-dockerd进⾏配合使⽤。这⾥我们选择如下平台进⾏相关的安装配置。
硬件平台:
- 浪潮 NF5468M5 Intel® Xeon® Gold 6240R CPU @ 2.40GHz
- NVIDIA A30(GA100GL)GPU
软件平台:
- VMware ESXi, 8.0.1, 21495797
- Ubuntu 22.04 LTS
- Docker Engine 24.0.7
- cri-dockerd 0.3.7
本次测试总共2个Kubernetes节点,1个管理节点,1个⼯作节点。
| hostname | IP Address |
|---|---|
| k8sm | 172.16.81.103 |
| k8s01 | 172.16.81.104 |
3. OS配置
禁⽌swap,加载相关内核模块,设置相关内核参数
sudo swapoff -a
sudo sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab
sudo tee /etc/modules-load.d/containerd.conf <<EOF
overlay
br_netfilter
EOF
sudo modprobe overlay
sudo modprobe br_netfilter
sudo tee /etc/sysctl.d/kubernetes.conf <<EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
EOF
sudo sysctl --system
4. Docker Engine,cri-dockerd安装
# Add Docker's official GPG key:
sudo apt update
sudo apt install ca-certificates curl gnupg
sudo install -m 0755 -d /etc/apt/keyrings
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --
dearmor -o /etc/apt/keyrings/docker.gpg
sudo chmod a+r /etc/apt/keyrings/docker.gpg
# Add the repository to Apt sources:
echo \
"deb [arch=$(dpkg --print-architecture) signedby=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/ubuntu \
$(. /etc/os-release && echo "$VERSION_CODENAME") stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt update
sudo apt install docker-ce docker-ce-cli containerd.io docker-buildx-plugin
docker-compose-plugi
cri-dockerd可以从github上直接下载deb包进⾏安装
wget https://github.com/Mirantis/cri-dockerd/releases/download/v0.3.7/cridockerd_0.3.7.3-0.ubuntu-jammy_amd64.deb
sudo dpkg -i cri-dockerd_0.3.7.3-0.ubuntu-jammy_amd64.deb
注意:cri-dockerd默认会从google去拉取pause镜像,因此需要将cri-dockerd的默认镜像拉取url改掉,否则在初始化Kubernetes安装的时候会因为拉取不到pause镜像⽽失败。
cri-dockerd安装完成后,修改cri-docker.service⽂件,修改如下⾏
ExecStart=/usr/bin/cri-dockerd --container-runtime-endpoint fd://
改为如下:
ExecStart=/usr/bin/cri-dockerd --container-runtime-endpoint fd:// --podinfra-container-image registry.aliyuncs.com/google_containers/pause:3.9
重新加载systemd dameon
sudo systemctl daemon-reload
启动docker、cr-dockerd服务,并将其设置为⾃动启动
sudo systemctl start docker
sudo systemctl start cri-docker
sudo systemctl enable docker cri-docker
5. 安装 kubeadm
我们从国内阿⾥云软件仓库安装kubeadm,⾸先添加安装源
sudo wget https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg -O
/etc/apt/keyrings/kubernetes.gpg
echo \
"deb [arch=amd64 signed-by=/etc/apt/keyrings/kubernetes.gpg]
https://mirrors.aliyun.com/kubernetes/apt/ \
kubernetes-xenial main" | \
sudo tee /etc/apt/sources.list.d/kubernetes.list > /dev/null
sudo apt update
注意:请按照上述指令配置kubeadm安装源,不要按照阿⾥云Kubernetes软件仓库的指导进
⾏软件源的配置
安装kubeadm、kubelet、kubectl,这⾥我们没有安装最新版本的Kubernetes,安装的是1.26.9-00这个版本
sudo apt install -y kubelet=1.26.9-00 kubeadm=1.26.9-00 kubectl=1.26.9-00
初始化安装Kubernetes管理节点,由于在系统中存在2个容器引擎,因此在安装Kubernetes的时候需要指定相关的cri-socket。这⾥不要指定为Docker Engine的socket,需要使⽤cri-docker的socket。同时我们指定Kubernetes的镜像从国内阿⾥云仓库拉取。
sudo kubeadm init --image-repository registry.aliyuncs.com/google_containers --pod-network-cidr=10.244.0.0/16 --apiserver-advertise-address=172.16.81.103 --cri-socket unix:///var/run/cridockerd.sock
添加Work节点
Kubernetes管理节点安装完成后,按照相关提示将Work节点加⼊群集
sudo kubeadm join 172.16.81.103:6443 --token fh1lte.m80w04ebcmd1ryg4 --discovery-token-ca-cert-hash sha256:5757a76b34ac07a236ad01f8601d4f4f41c82e257a48ddf14620e7b950088793 --cri-socket unix:///var/run/cri-dockerd.sock
注意:要加上–cri-socket参数
安装CNI插件
这⾥我们使⽤Antrea CNI插件,下载相关yaml⽂件直接在Kubernets上应⽤即可。
kubectl apply -f https://github.com/antreaio/antrea/releases/download/1.14.1/antrea.yml
6. GPU-Operator安装
本次使⽤直通⽅式将GPU给Kubernetes的Work节点使⽤。使⽤直通模式,在ESXi上不⽤安装NVIDIA的驱动。另外在安装GPU Operator的时候对于GPU驱动也有2种选择:驱动安装在OS中,驱动直接装在容器中,这2种⽅式都可以。这⾥我们选择将驱动安装到容器中的⽅式进⾏,因此OS中也不⽤安装NVIDIA驱动。
- . 配置GPU直通
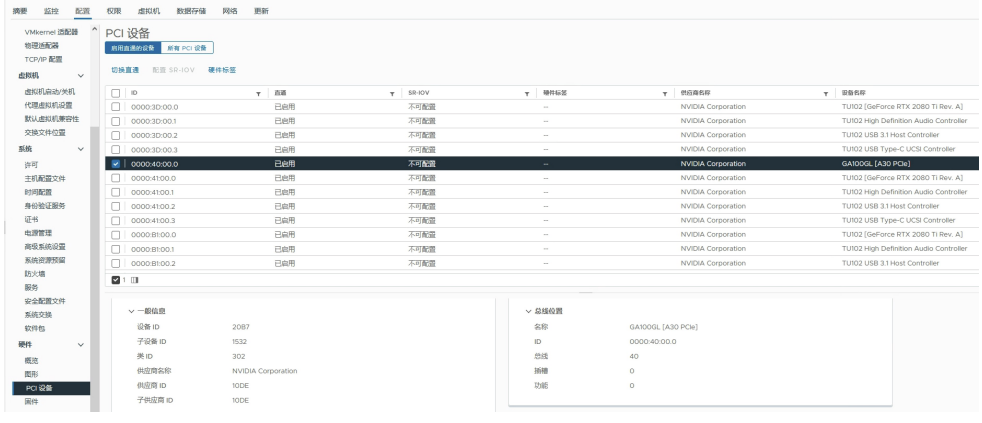
-
将直通的GPU分给相关的VM
⾸先确保VM是使⽤的EFI模式
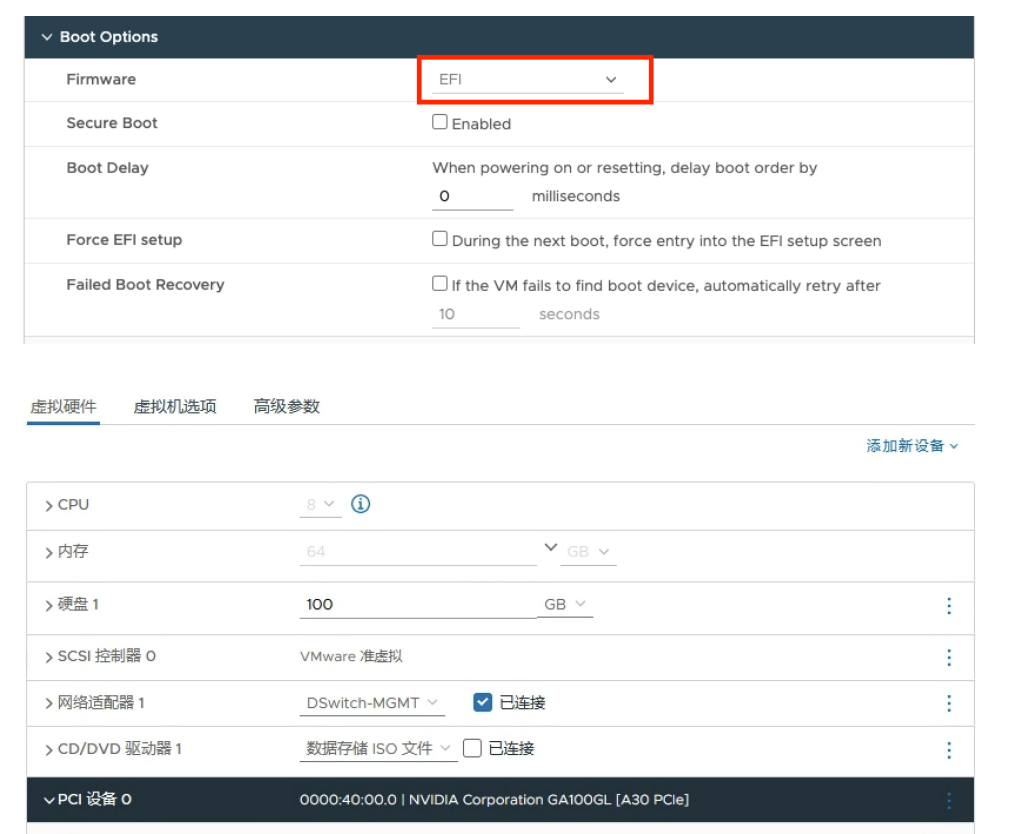
-
修改VM的⾼级参数配置
添加如下2个参数:
pciPassthru.use64bitMMIO="TRUE"
pciPassthru.64bitMMIOSizeGB = "64"

pciPassthru.64bitMMIOSizeGB参数的值可以参考nvidia的⽹站
https://docs.nvidia.com/ai-enterprise/latest/release-notes/index.html#tesla-p40-largememory-vms
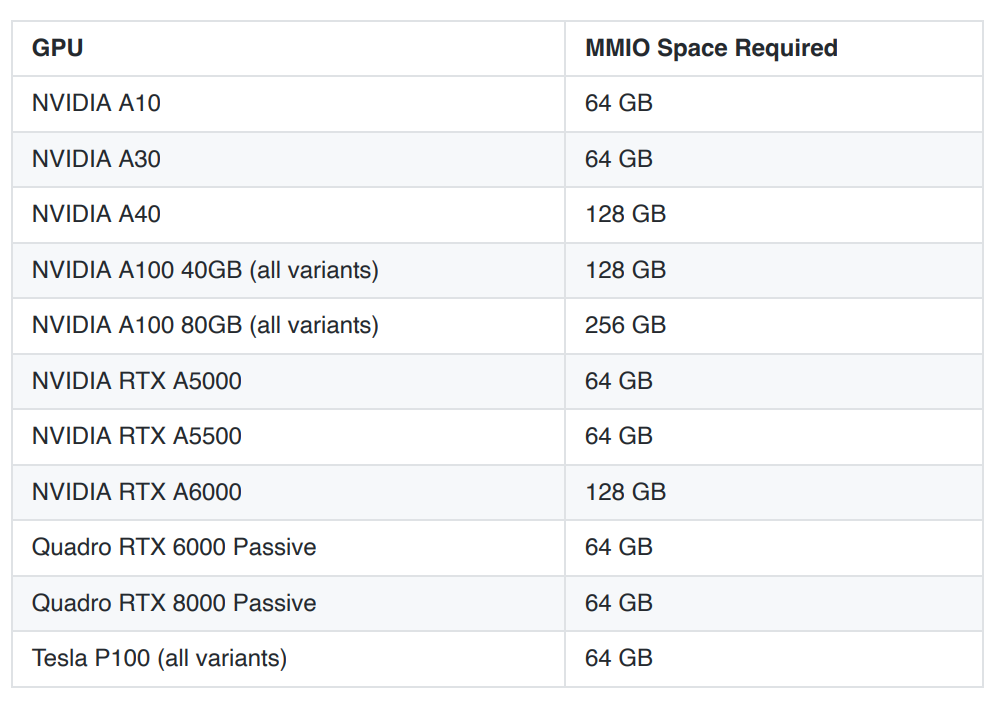
- 安装GPU Operator
GPU Operator通过helm chart安装,因此先安装⼀下helm,并将相关的helm仓库添加好
#安装helm
curl -fsSL -o get_helm.sh
https://raw.githubusercontent.com/helm/helm/master/scripts/get-helm-3 \
&& chmod 700 get_helm.sh \
&& ./get_helm.sh
#添加helm仓库
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia \
&& helm repo update
默认情况下,GPU Operator会将相关组件部署在集群中所有带有GPU的⼯作节点上。GPU⼯作节点通过标签 feature.node.kubernetes.io/pci-10de.present=true 来识别带有GPU的⼯作节点。我们先将有GPU的⼯作节点打上标签。
注意:pci-10de⾥的0x10de是NVIDIA的PCI vendor ID,这个可以在配置直通的界⾯⾥可以
看到

kubectl label nodes k8s01 feature.node.kubernetes.io/pci-10de.present=true
通过helm安装GPU Operator
helm install --wait --generate-name -n gpu-operator --create-namespace nvidia/gpu-operator
如果NVIDIA的驱动已经在OS上安装了,那么可以选择helm安装时不要将驱动安装到容器⾥,使⽤如下参数安装
helm install --wait --generate-name -n gpu-operator --create-namespace nvidia/gpu-operator --set driver.enabled=false
可以通过kubectl监控安装过程,安装完成后,如果没有问题,会有如下相关pod⽣成
$ kubectl get pods -n gpu-operator
NAME READY STATUS RESTARTS AGE
gpu-feature-discovery-crrsq 1/1 Running 0 60s
gpu-operator-7fb75556c7-x8spj 1/1 Running 0 5m13s
gpu-operator-node-feature-discovery-master-58d884d5cc-w7q7b 1/1 Running 0 5m13s
gpu-operator-node-feature-discovery-worker-6rht2 1/1 Running 0 5m13s
gpu-operator-node-feature-discovery-worker-9r8js 1/1 Running 0 5m13s
nvidia-container-toolkit-daemonset-lhgqf 1/1 Running 0 4m53s
nvidia-cuda-validator-rhvbb 0/1 Completed 0 54s
nvidia-dcgm-5jqzg 1/1 Running 0 60s
nvidia-dcgm-exporter-h964h 1/1 Running 0 60s
nvidia-device-plugin-daemonset-d9ntc 1/1 Running 0 60s
nvidia-device-plugin-validator-cm2fd 0/1 Completed 0 48s
nvidia-driver-daemonset-5xj6g 1/1 Running 0 4m53s
nvidia-mig-manager-89z9b 1/1 Running 0 4m53s
nvidia-operator-validator-bwx99 1/1 Running 0 58s
如果有什么问题可以通过kubectl logs检查pod的⽇志。
- 验证GPU Operator
创建 cuda-vectoradd.yaml ,内容如下
apiVersion: v1
kind: Pod
metadata:
name: cuda-vectoradd
spec:
restartPolicy: OnFailure
containers:
- name: cuda-vectoradd
image: "nvcr.io/nvidia/k8s/cuda-sample:vectoradd-cuda11.7.1-ubuntu20.04"
resources:
limits:
nvidia.com/gpu: 1
运⾏pod并查看相关⽇志,⽇志类似如下表示测试成功
kubectl apply -f cuda-vectoradd.yaml
kubectl logs pod/cuda-vectoradd
[Vector addition of 50000 elements]
Copy input data from the host memory to the CUDA device
CUDA kernel launch with 196 blocks of 256 threads
Copy output data from the CUDA device to the host memory
Test PASSED
Done
GPU的分配可以通过如下命令查看
$ kubectl describe node k8s01
..........
..........
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 400m (5%) 0 (0%)
memory 0 (0%) 0 (0%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-1Gi 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)
nvidia.com/gpu 1 1
Events: <none>
这⾥nvdia.com/gpu可以看到这个节点上的1个GPU已经分配出去
参考⽹站:
- 阿⾥云Kubernetes安装源
https://developer.aliyun.com/mirror/kubernetes?spm=a2c6h.13651102.0.0.1c801b115pcCkL - Docker Engine安装
https://docs.docker.com/engine/install/ubuntu/ - GPU Operator⽂档
https://docs.nvidia.com/datacenter/cloud-native/gpu-operator/latest/getting-started.html# - GPU直通配置⽂档
https://blogs.vmware.com/apps/2018/09/using-gpus-with-virtual-machines-on-vsphere-part-2-
vmdirectpath-i-o.html