项目优化(异步化)
1. 认识异步化
1.1 同步与异步
- 同步:一件事情做完,再做另外一件事情,不能同时进行其他的任务。
- 异步:不用等一件事故完,就可以做另外一件事情。等第一件事完成时,可以收到一个通知,通知你这件事做好了,你可以再进行后续处理。
1.2 标准异步化的业务流程 ⭐
-
当用户要进行耗时很长的操作时,如点击提交后,不需要在界面长时间的等待,而是应该把这个任务保存到数据库中记录下来
-
用户要执行新任务时:
-
任务提交成功:
-
程序还有多余的空闲线程时,可以立刻去执行这个任务。
-
程序的线程都在繁忙时,无法继续处理,那就放到等待队列里。
-
-
任务提交失败:比如程序所有线程都在忙,任务队列满了。
-
拒绝掉这个任务,再也不去执行。
-
通过保存到数据库中的记录来看到提交失败的任务,并且在程序空闲的时候,可以把任务从数据库中回调到程序里,再次去执行此任务。3
-
-
-
程序(线程)从任务队列中取出任务依次执行,每完成一件事情要修改一下的任务的状态。
-
用户可以查询任务的执行状态,或者在任务执行成功或失败时能得到通知(发邮件、系统消息提示、短信),从而优化体验。
-
如果我们要执行的任务非常复杂,包含很多环节,在每一个小任务完成时,要在程序(数据库中)记录一下任务的执行状态(进度)。
2. 线程池
-
线程池是什么:线程池是一种并发编程技术,用于优化多线程应用程序的性能和稳定性。它可以在应用程序启动时创建一组可重用的线程,并将工作任务分配给这些线程,以避免重复地创建和销毁线程,从而提高应用程序的吞吐量、响应时间和资源利用率。
-
线程池优点:
-
减少了线程的创建和销毁开销,提高了性能和效率。
-
避免了线程数量过多而导致的系统资源耗尽和线程调度开销增大的问题。
-
允许调整线程池大小,以满足不同应用程序的需求。
-
可以提高代码的可维护性和可重用性,避免了线程相关的错误,使得代码更加健壮和可靠。
-
-
线程池的作用 :帮助你轻松管理线程、协调任务的执行过程
-
线程池的实现:(不用自己写)
-
如果是在Spring中,可以用
ThreadPoolTaskExecutor配合@Async注解来实现。(不太建议:进行了封装) -
JUC线程池的实现方式(JUC并发编程包,中的
ThreadPoolExecutor来实现非常灵活地自定义线程池。)-
创建配置线程池类
/** * 配置线程池类 * 可以在yml文件中写配置,实现自动注入 */ @Configuration public class ThreadPoolExecutorConfig { /** * 线程池的实现类 * @return */ @Bean public ThreadPoolExecutor threadPoolExecutor(){ ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(); return threadPoolExecutor; } } -
参数解释
参数根据实际场景,测试调整,不断优化
根据BI系统来说,线程数量要配置AI的能力(AI能力是瓶颈),ai支持4个线程,允许20个任务排队(参数根据条件调整)
资源隔离策略:不同的程度的任务,分为不同的队列,比如VIP一个队列,普通用户一个队列。
public ThreadPoolExecutor(int corePoolSize,//核心线程数:正常情况下,系统能同时工作的数量,处于随时就绪的状态 int maximumPoolSize,//最大线程数,极限情况下,线程池有多少个线程 long keepAliveTime,//空闲线程存活时间,非核心线程在没有任务的情况下多久删除,从而释放线程资源 TimeUnit unit,//空闲线程存活时间单位 BlockingQueue<Runnable> workQueue, //工作队列,用于存放给线程执行的任务,存在队列最大长度(一定要设置不可以为无限) ThreadFactory threadFactory,//线程工厂,控制每个线程的生产 RejectedExecutionHandler handler//(拒绝策略)线程池拒绝策略,==任务队列满的时候,我们采取什么措施,比如抛异常、不抛异常、自定义策略==。 ) { }-
线程池的工作机制
- 开始时:没有任务的线程,也没有任何的任务。
- 刚开始的核心线程数、最大线程数、任务队列中分别存在的数量为:
corePoolSize = 0 ;maximumPoolSize = 0 ,workQueue.size = 0
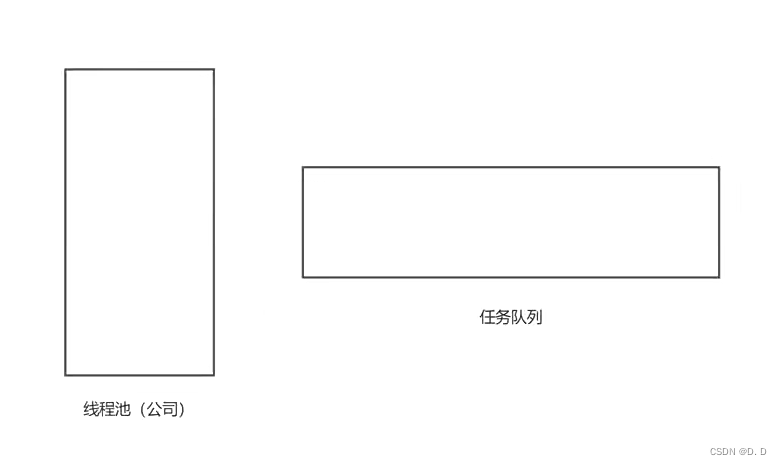
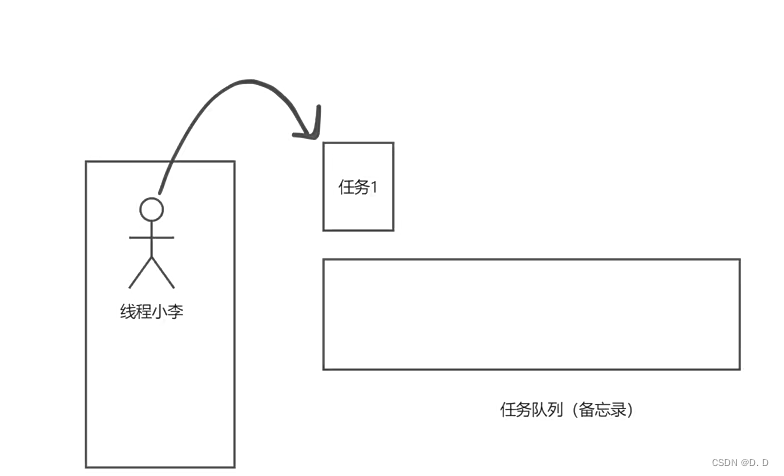
- 来了第一个任务,发现我们的员工没有到达正式的员工人数,来了一个员工直接处理这个任务。
- 第一个任务到来时的核心线程数、最大线程数、任务队列中分别存在的数量为:
corePoolSize = 1 ;maximumPoolSize = 1 ,workQueue.size = 0
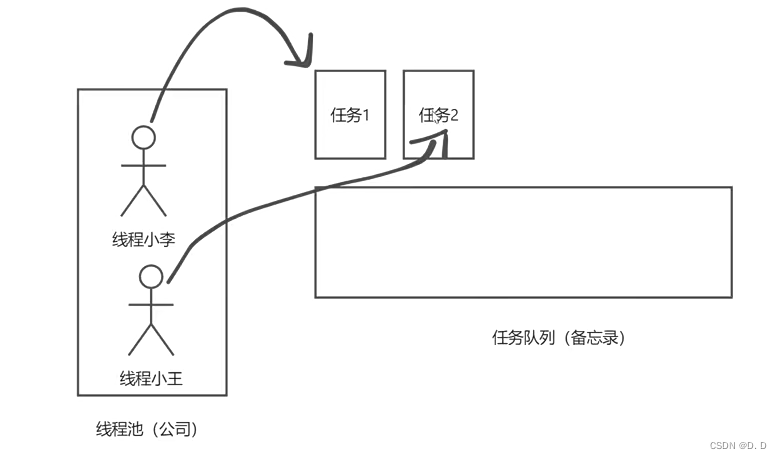
- 又来了一个任务,发现我们的员工还没有达到正式员工数,再来一个员工直接处理这个任务。
3、第二个任务到来时的核心线程数、最大线程数、任务队列中分别存在的数量为:
corePoolSize = 2 ;maximumPoolSize = 2 ,workQueue.size = 0
(一个人处理一个任务,一线程一任务)
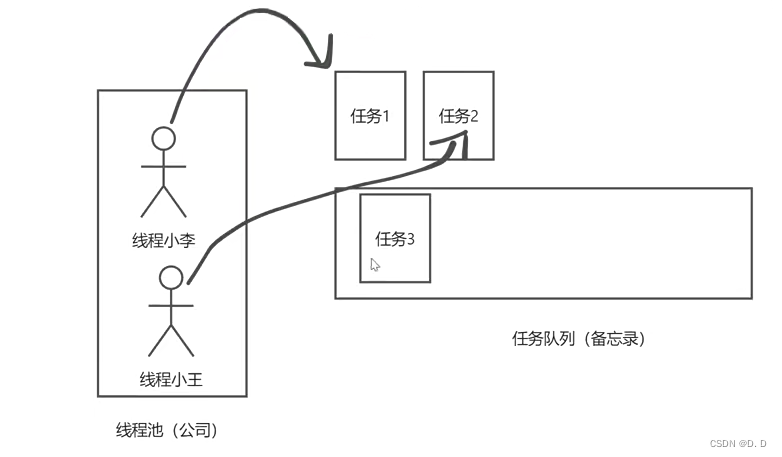
- 又来了一个任务,但是我们正式员工数已经满了(当前线程数 = corePoolSize = 2),将最新来的任务放到任务队列(最大长度
workQueue.size是 2) 里等待,而不是再加新员工。
4、第三、四个任务到来时的核心线程数、最大线程数、任务队列中分别存在的数量为:
corePoolSize = 2 ;maximumPoolSize = 2 ,workQueue.size = 2
(一个人处理一个任务,一线程一任务)
- 又来了一个任务,但是我们的任务队列已经满了(当前线程数 大于了 corePoolSize=2,己有任务数 = 最大长度
workQueue.size= 2),新增线程(maximumPoolSize= 4)来处理任务,而不是丢弃任务。
- 第五个任务到来时的核心线程数、最大线程数、任务队列中分别存在的数量为:
corePoolSize = 2 ;maximumPoolSize = 3 ,workQueue.size = 2
(找了一个临时工处理这个队新来的这个任务)
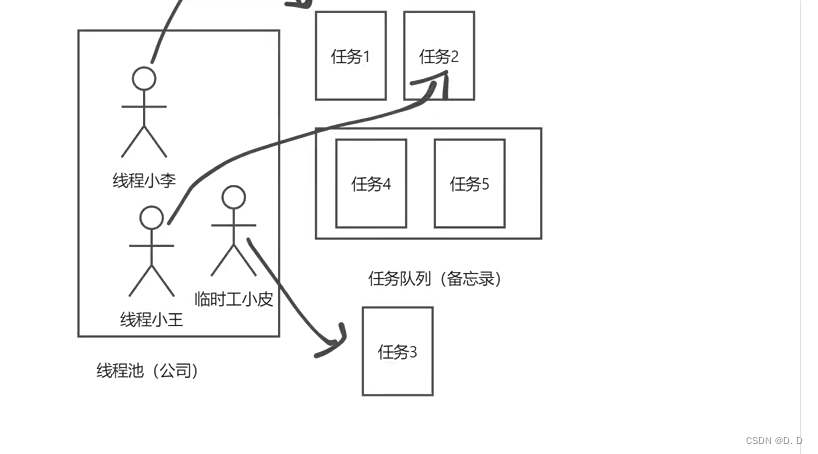
- 当到了任务7,但是我们的任务队列已经满了、临时工也招满了(当前线程数 =
maximumPoolSize= 4,已有任务数 = 最大长度workQueue.size= 2) 调用RejectedExecutionHandler拒绝策略来处理多余的任务。
- 等到第六个任务到来时的核心线程数、最大线程数、任务队列中分别存在的数量为:
corePoolSize = 2 ;maximumPoolSize = 4 ,workQueue.size = 2
(再找了一个临时工处理这个队列任务中最前面的任务4,然后这个第六个新来的线程就进入到任务队列中等待)
- 等到第七个任务到来时的核心线程数、最大线程数、任务队列中分别存在的数量为:
corePoolSize = 2 ;maximumPoolSize = 4 ,workQueue.size = 2
(此时在核心线程数、最大线程数以及任务队列中都占满了,以及无法接收新的任务了,所以说只能拒绝任务7)
7、最后,如果当前线程数超过 corePoolSize (正式员工数),又没有新的任务给他,那么等 keepAliveTime 时间达到后,就可以把这个线程释放。
-
确定线程池的参数
corePoolSize(核心线程数=>正式员工数):正常情况下,可以设置为 2 - 4maximumPoolSize(最大线程数):设置为极限情况,设置为 <= 4keepAliveTime(空闲线程存活时间):一般设置为秒级或者分钟级TimeUnit unit(空闲线程存活时间的单位):分钟、秒workQueue(工作队列):结合实际请况去设置,可以设置为20 (2n+1)threadFactory(线程工厂):控制每个线程的生成、线程的属性(比如线程名)RejectedExecutionHandler(拒绝策略):抛异常,标记数据库的任务状态为 “任务满了已拒绝”
-
线程设置种类
- IO密集型:耗费带宽/内存/硬盘的读写资源,corePoolSize可以设置大一点,一般经验值是 2n 左右,但是建议以 IO 的能力为主。
- 计算密集型:耗费cpu资源,比如音视频资源,图像处理、数学计算等一般是设置corePoolSize为cpu的核数+1(空余线程池)
考虑导入百万数据到数据库,属于IO密集型任务、还是计算密集型任务?
答:考虑导入百万数据到数据库是一个IO密集型任务。导入数据需要从外部读取大量数据,然后将其写入数据库,这个过程中计算的工作量不是很高,相对来说需要更多的磁盘IO和网络IO。因此,这个任务的性能瓶颈通常是在IO操作上,而非计算上。
-
自定义线程池
/** * 配置线程池类 * 可以在yml文件中写配置,实现自动注入 */ @Configuration public class ThreadPoolExecutorConfig { @Bean public ThreadPoolExecutor threadPoolExecutor() { ThreadFactory threadFactory = new ThreadFactory() { private int count = 1; @Override public Thread newThread(@NotNull Runnable r) { // 一定要将这个 r 放入到线程当中 Thread thread = new Thread(r); thread.setName("线程:" + count); // 任务++ count++; return thread; } }; ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(2, 4, 100, TimeUnit.SECONDS, new ArrayBlockingQueue<>(100), threadFactory); return threadPoolExecutor; } } -
提交任务到自定义线程池
@RestController @RequestMapping("/queue") @Slf4j @Profile({ "dev", "local" }) @Api(tags = "QueueController") @CrossOrigin(origins = "http://localhost:8000", allowCredentials = "true") public class QueueController { @Resource private ThreadPoolExecutor threadPoolExecutor; @GetMapping("/add") public void add(String name) { CompletableFuture.runAsync(() -> { log.info("任务执行中:" + name + ",执行人:" + Thread.currentThread().getName()); try { Thread.sleep(60000); } catch (InterruptedException e) { throw new RuntimeException(e); } },threadPoolExecutor); } @GetMapping("/get") public String get() { Map<String, Object> map = new HashMap<>(); int size = threadPoolExecutor.getQueue().size(); map.put("队列长度:", size); long taskCount = threadPoolExecutor.getTaskCount(); map.put("任务总数:", taskCount); long completedTaskCount = threadPoolExecutor.getCompletedTaskCount(); map.put("已完成任务数:", completedTaskCount); int activeCount = threadPoolExecutor.getActiveCount(); map.put("正在工作的线程数:", activeCount); return JSONUtil.toJsonStr(map); } }
-
-
-
3. 实操项目使用异步化优化
-
系统问题分析:
- 用户等待时间较长
- 业务服务器可能会有很多请求在处理,导致系统资源紧张,严重时导致服务器宕机或者无法处理新的请求(很多用户在系统中进行同一个请求导致系统使用体验降低。)
- 调用的第三方服务(如AI能力)的处理能力是有限的,比如每3秒只处理1个请求,当多个请求时会导致 AI 处理不过来,严重时AI可能会对后台系统拒绝服务。
-
解决方法=>异步化
- 异步化使用场景:调用的服务处理能力有限,或者接口的处理(返回)时间较长,考虑异步化
-
异步化优化前后对比
-
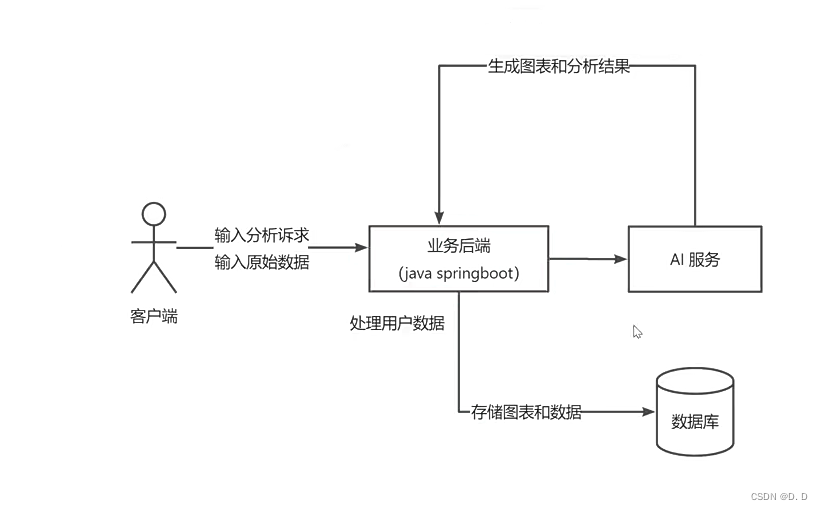
优化前架构图
-
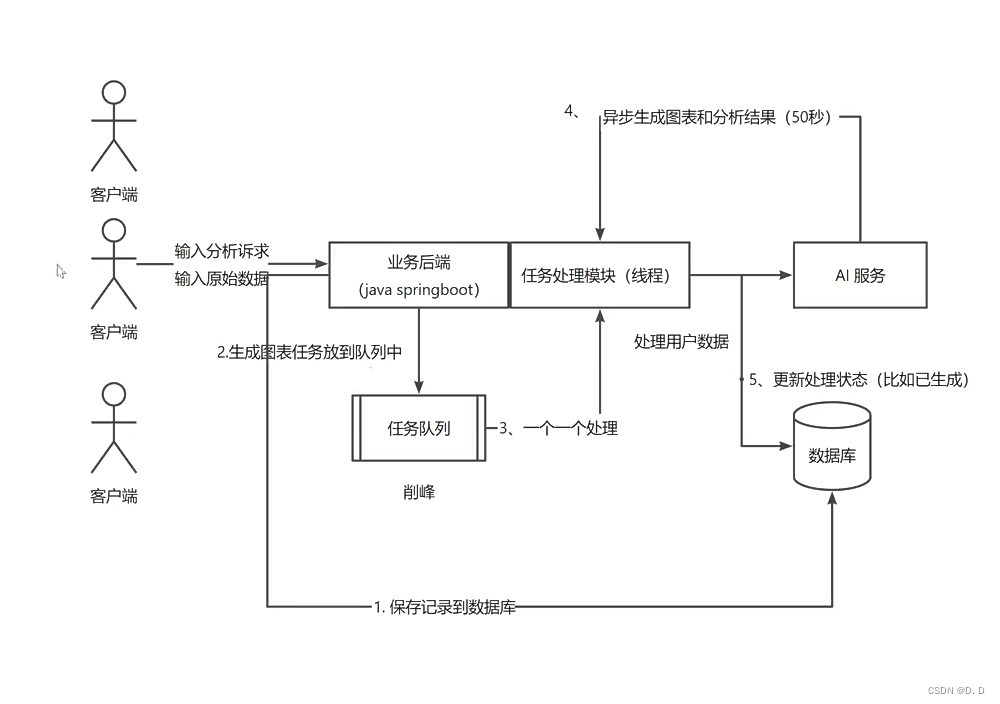
优化后架构图
-
-
异步化(new Rhread)实现
- 任务队列的最大容量应该设置多少合适?
- 程序怎么从任务队列中取出任务去执行,这个任务队列的流程怎么实现的,怎么保证程序最多同时执行多少个任务?
- 阻塞队列
- 线程池
- 增加更多的人手?
-
流程梳理:
-
给chart表新增任务状态字段(比如排队中、执行中、已完成、失败),任务执行信息字段(用于记录任务执行中、或者失败的一些信息)
-- 图表信息表 create table if not exists chart ( id bigint auto_increment comment 'id' primary key, goal text null comment '分析目标', chartName varchar(256) null comment '图表名称', chartData text null comment '图表数据', chartType varchar(256) null comment '图表类型', genChart text null comment '生成的图表信息', genResult text nul l comment '生成的分析结论', chartStatus varchar(128) default 'wait' not null comment 'wait-等待,running-生成中,succeed-成功生成,failed-生成失败', execMessage text null comment '执行信息', userId bigint null comment '创建图标用户 id', createTime datetime default CURRENT_TIMESTAMP not null comment '创建时间', updateTime datetime default CURRENT_TIMESTAMP not null on update CURRENT_TIMESTAMP comment '更新时间', isDelete tinyint default 0 not null comment '是否删除' ) comment '图表信息表' collate = utf8mb4_unicode_ci; -
用户点击智能分析页面的提交按钮时,先把图表立刻保存到数据库中(作为一个任务)
-
任务:先修改图表任务状态为"执行中"。等执行成功后,修改为"已完成"、保存执行结果;执行失败后,状态修改为"失败",记录任务失败信息。
-
用户可以在图表管理界面插查看所有的图表的信息和状态
- 已生成的
- 生成中的
- 生成失败的
-
用户可以修改生成失败的图表信息,点击重新生成图表
-