
熟悉unordered_set及其模拟实现
unordered_set的定义
unordered_set 是 C++ 标准库中的一个容器,用于存储唯一的元素,而且不按照任何特定的顺序来组织这些元素。它是基于哈希表实现的,因此可以在平均情况下提供常数时间的插入、删除和查找操作。
以下是使用 unordered_set 定义的基本示例:
#include <iostream>
#include <unordered_set>
int main() {
// 创建一个unordered_set
std::unordered_set<int> mySet;
// 向unordered_set中插入元素
mySet.insert(5);
mySet.insert(2);
mySet.insert(8);
// 查找元素
if (mySet.find(2) != mySet.end()) {
std::cout << "元素 2 存在于unordered_set中" << std::endl;
}
// 遍历unordered_set中的元素
for (const int& value : mySet) {
std::cout << value << " ";
}
std::cout << std::endl;
return 0;
}
unordered_set 提供了一种高效的方法来存储和检索不重复的值,但不保留它们的顺序。因此,如果你需要按顺序存储元素,可以考虑使用 std::set 或其他有序容器。
1. unordered_set的模板定义
template < class Key, // unordered_set::key_type/value_type
class Hash = hash<Key>, // unordered_set::hasher
class Pred = equal_to<Key>, // unordered_set::key_equal
class Alloc = allocator<Key> // unordered_set::allocator_type
> class unordered_set;
Key(键/值类型):这是在unordered_set中存储的元素类型。例如,如果您想要创建一个存储整数的unordered_set,则将Key设置为int。Hash(哈希函数类型):这是用于计算元素哈希值的函数对象类型。默认情况下,它是std::hash<Key>,它提供了针对大多数内置类型的哈希函数。您也可以提供自定义的哈希函数。Pred(键比较函数类型):这是用于比较元素的函数对象类型。默认情况下,它是std::equal_to<Key>,它执行标准的等于比较操作。您可以提供自定义的比较函数,以根据自己的需求确定元素是否相等。Alloc(分配器类型):这是用于分配和释放内存的分配器类型。默认情况下,它是std::allocator<Key>,用于标准内存管理。您通常只需要在特殊情况下自定义分配器。
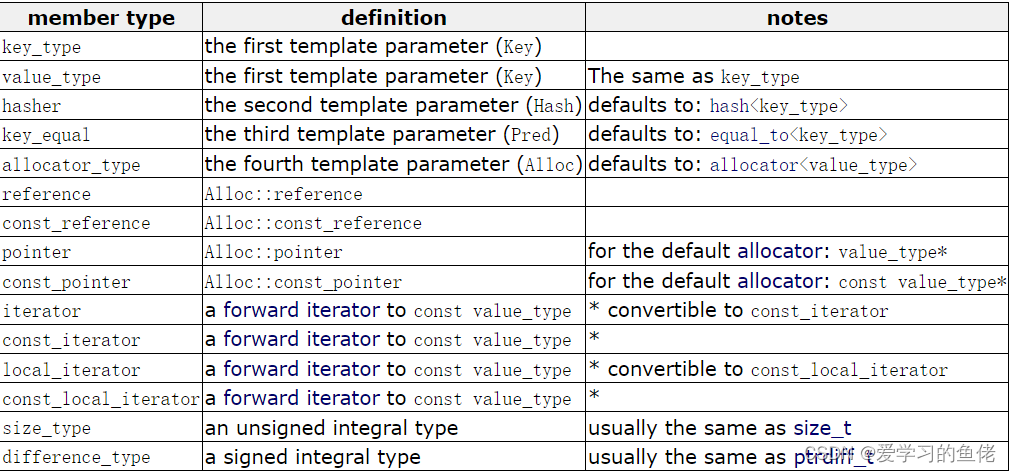
2. unordered_set的成员类型
以下别名是unordered_set的成员类型。它们被成员函数广泛用作参数和返回类型
unordered_set构造函数
empty (1)
explicit unordered_set ( size_type n = /* see below */,
const hasher& hf = hasher(),
const key_equal& eql = key_equal(),
const allocator_type& alloc = allocator_type() );
explicit unordered_set ( const allocator_type& alloc );
range (2)
template <class InputIterator>
unordered_set ( InputIterator first, InputIterator last,
size_type n = /* see below */,
const hasher& hf = hasher(),
const key_equal& eql = key_equal(),
const allocator_type& alloc = allocator_type() );
copy (3)
unordered_set ( const unordered_set& ust );
unordered_set ( const unordered_set& ust, const allocator_type& alloc );
move (4)
unordered_set ( unordered_set&& ust );
unordered_set ( unordered_set&& ust, const allocator_type& alloc );
initializer list (5)
unordered_set ( initializer_list<value_type> il,
size_type n = /* see below */,
const hasher& hf = hasher(),
const key_equal& eql = key_equal(),
const allocator_type& alloc = allocator_type() );
explicit unordered_set(size_type n = /* see below */, const hasher& hf = hasher(), const key_equal& eql = key_equal(), const allocator_type& alloc = allocator_type());- 创建一个空的
unordered_set。 n:哈希表的初始桶数。hf:哈希函数。eql:键的比较函数。alloc:分配器。
- 创建一个空的
template <class InputIterator> unordered_set(InputIterator first, InputIterator last, size_type n = /* see below */, const hasher& hf = hasher(), const key_equal& eql = key_equal(), const allocator_type& alloc = allocator_type());- 用迭代器范围
[first, last)中的元素创建unordered_set。 n:哈希表的初始桶数。hf:哈希函数。eql:键的比较函数。alloc:分配器。
- 用迭代器范围
unordered_set(const unordered_set& ust);- 用另一个
unordered_set的副本创建一个新的unordered_set。
- 用另一个
unordered_set(unordered_set&& ust);- 移动构造函数,使用另一个
unordered_set的内容创建一个新的unordered_set,并且源unordered_set不再包含这些元素。
- 移动构造函数,使用另一个
unordered_set(initializer_list<value_type> il, size_type n = /* see below */, const hasher& hf = hasher(), const key_equal& eql = key_equal(), const allocator_type& alloc = allocator_type());- 使用初始化列表
il创建unordered_set。 n:哈希表的初始桶数。hf:哈希函数。eql:键的比较函数。alloc:分配器。
- 使用初始化列表
以下是一些使用不同构造函数创建和初始化 std::unordered_set 的示例:
#include <iostream>
#include <unordered_set>
int main() {
// 示例 1: 使用默认构造函数创建一个空的 unordered_set
std::unordered_set<int> mySet1;
// 示例 2: 使用迭代器范围初始化 unordered_set
std::unordered_set<int> mySet2({
1, 2, 3, 4, 5}); // 初始化列表
std::unordered_set<int> mySet3(mySet2.begin(), mySet2.end()); // 从另一个集合复制
// 示例 3: 使用复制构造函数创建一个新的 unordered_set
std::unordered_set<int> mySet4(mySet3);
// 示例 4: 使用移动构造函数创建一个新的 unordered_set
std::unordered_set<int> mySet5(std::move(mySet4));
// 示例 5: 使用初始化列表和自定义哈希函数
std::unordered_set<std::string> mySet6({
"apple", "banana", "cherry"}, 10, std::hash<std::string>(), std::equal_to<std::string>());
// 遍历并打印 unordered_set 中的元素
for (const int& value : mySet3) {
std::cout << value << " ";
}
std::cout << std::endl;
for (const std::string& fruit : mySet6) {
std::cout << fruit << " ";
}
std::cout << std::endl;
return 0;
}
这个示例演示了如何使用不同的构造函数来创建和初始化 std::unordered_set,包括使用默认构造函数、迭代器范围、复制构造函数、移动构造函数和初始化列表。还演示了如何自定义哈希函数和比较函数。
unordered_set赋值运算符重载
copy (1)
unordered_set& operator= ( const unordered_set& ust );
move (2)
unordered_set& operator= ( unordered_set&& ust );
initializer list (3)
unordered_set& operator= ( intitializer_list<value_type> il );
这是关于 std::unordered_set 的不同赋值运算符重载:
unordered_set& operator= ( const unordered_set& ust );- 复制赋值运算符。用另一个
unordered_set的内容替换当前的unordered_set内容。
- 复制赋值运算符。用另一个
unordered_set& operator= ( unordered_set&& ust );- 移动赋值运算符。使用另一个
unordered_set的内容来替换当前的unordered_set内容,并且源unordered_set不再包含这些元素。
- 移动赋值运算符。使用另一个
unordered_set& operator= ( initializer_list<value_type> il );- 初始化列表赋值运算符。用初始化列表中的元素来替换当前
unordered_set的内容。
- 初始化列表赋值运算符。用初始化列表中的元素来替换当前
这些赋值运算符允许您以不同的方式将元素从一个 std::unordered_set 赋值给另一个,包括复制、移动和使用初始化列表。这有助于管理和更新 unordered_set 的内容。
以下是使用不同类型的赋值运算符重载的示例:
#include <iostream>
#include <unordered_set>
int main() {
// 示例 1: 复制赋值运算符
std::unordered_set<int> set1 = {
1, 2, 3};
std::unordered_set<int> set2;
set2 = set1; // 复制 set1 到 set2
std::cout << "set2 after copy assignment: ";
for (const int& value : set2) {
std::cout << value << " ";
}
std::cout << std::endl;
// 示例 2: 移动赋值运算符
std::unordered_set<std::string> set3 = {
"apple", "banana", "cherry"};
std::unordered_set<std::string> set4;
set4 = std::move(set3); // 移动 set3 到 set4
std::cout << "set3 after move assignment: ";
for (const std::string& fruit : set3) {
std::cout << fruit << " "; // set3 不再包含元素
}
std::cout << std::endl;
std::cout << "set4 after move assignment: ";
for (const std::string& fruit : set4) {
std::cout << fruit << " "; // set4 包含被移动的元素
}
std::cout << std::endl;
// 示例 3: 初始化列表赋值运算符
std::unordered_set<char> set5;
set5 = {
'a', 'b', 'c'}; // 使用初始化列表赋值
std::cout << "set5 after initializer list assignment: ";
for (const char& letter : set5) {
std::cout << letter << " ";
}
std::cout << std::endl;
return 0;
}
这个示例演示了不同类型的赋值运算符重载的用法,包括复制、移动和使用初始化列表赋值。注意,移动赋值后源 unordered_set 不再包含元素。
unordered_set容量函数(Capacity)
bool empty() const noexcept;- 这个函数返回一个布尔值,指示集合是否为空。如果集合为空,它将返回
true;否则,返回false。 const noexcept表示这是一个不会抛出异常的常量成员函数。
- 这个函数返回一个布尔值,指示集合是否为空。如果集合为空,它将返回
size_type size() const noexcept;- 这个函数返回集合中元素的数量,也就是集合的大小。
const noexcept表示这是一个不会抛出异常的常量成员函数。- 返回的类型
size_type是一个无符号整数类型,通常是std::size_t。
size_type max_size() const noexcept;- 这个函数返回集合可能包含的最大元素数量。
const noexcept表示这是一个不会抛出异常的常量成员函数。- 返回的类型
size_type是一个无符号整数类型,通常是std::size_t。
这些函数允许您在使用 std::unordered_set 时查询集合的状态,例如检查是否为空、获取集合的大小以及了解集合可能包含的最大元素数量。由于它们都是常量成员函数并且不会抛出异常,因此可以在安全的情况下调用它们。
以下是使用 std::unordered_set 的成员函数 empty(), size(), 和 max_size() 的示例:
#include <iostream>
#include <unordered_set>
int main() {
std::unordered_set<int> mySet;
// 检查集合是否为空
if (mySet.empty()) {
std::cout << "集合为空" << std::endl;
} else {
std::cout << "集合不为空" << std::endl;
}
// 添加元素到集合
mySet.insert(1);
mySet.insert(2);
mySet.insert(3);
// 获取集合的大小
std::cout << "集合的大小为: " << mySet.size() << std::endl;
// 获取集合可能包含的最大元素数量
std::cout << "集合可能包含的最大元素数量为: " << mySet.max_size() << std::endl;
return 0;
}
这个示例演示了如何使用 empty() 函数来检查集合是否为空,使用 size() 函数来获取集合的大小,以及使用 max_size() 函数来获取集合可能包含的最大元素数量。根据示例中的操作,程序将输出相应的信息。
unordered_set迭代器(Iterators)
1. begin()
container iterator (1)
iterator begin() noexcept;
const_iterator begin() const noexcept;
bucket iterator (2)
local_iterator begin ( size_type n );
const_local_iterator begin ( size_type n ) const;
iterator begin() noexcept;- 非常量版本的
begin()函数返回指向集合中第一个元素的迭代器。您可以使用这个迭代器来遍历集合的元素。 const noexcept表示这是一个不会抛出异常的非常量成员函数。
- 非常量版本的
const_iterator begin() const noexcept;- 常量版本的
begin()函数返回指向集合中第一个元素的常量迭代器。这个常量迭代器只允许读取元素,不能修改它们。 const noexcept表示这是一个不会抛出异常的常量成员函数。
- 常量版本的
local_iterator begin(size_type n);- 这个函数用于获取指向桶
n中第一个局部元素的迭代器。在哈希表中,元素被分布到不同的桶中,local_iterator允许您在特定桶中遍历元素。 size_type n参数指定桶的索引。
- 这个函数用于获取指向桶
const_local_iterator begin(size_type n) const;- 这是常量版本的
begin(size_type n)函数,返回指向桶n中第一个局部元素的常量迭代器。
- 这是常量版本的
2. end()
container iterator (1)
iterator end() noexcept;
const_iterator end() const noexcept;
bucket iterator (2)
local_iterator end (size_type n);
const_local_iterator end (size_type n) const;
iterator end() noexcept;- 非常量版本的
end()函数返回指向集合末尾的迭代器。它通常用于与begin()配合来遍历整个集合的元素。 const noexcept表示这是一个不会抛出异常的非常量成员函数。
- 非常量版本的
const_iterator end() const noexcept;- 常量版本的
end()函数返回指向集合末尾的常量迭代器。这个常量迭代器只允许读取元素,不能修改它们。 const noexcept表示这是一个不会抛出异常的常量成员函数。
- 常量版本的
local_iterator end(size_type n);- 这个函数用于获取指向桶
n的结束局部元素的迭代器。在哈希表中,元素被分布到不同的桶中,local_iterator允许您在特定桶中遍历元素。 size_type n参数指定桶的索引。
- 这个函数用于获取指向桶
const_local_iterator end(size_type n) const;- 这是常量版本的
end(size_type n)函数,返回指向桶n的结束局部元素的常量迭代器。
- 这是常量版本的
3. cbegin()
container iterator (1)
const_iterator cbegin() const noexcept;
bucket iterator (2)
const_local_iterator cbegin ( size_type n ) const;
const_iterator cbegin() const noexcept;- 这个函数返回指向集合中第一个元素的常量迭代器。与
begin()类似,但这是一个常量成员函数,只允许读取元素而不能修改它们。 const noexcept表示这是一个不会抛出异常的常量成员函数。
- 这个函数返回指向集合中第一个元素的常量迭代器。与
const_local_iterator cbegin(size_type n) const;- 这个函数用于获取指向桶
n中第一个局部元素的常量迭代器。在哈希表中,元素被分布到不同的桶中,const_local_iterator允许您在特定桶中遍历元素。 size_type n参数指定桶的索引
- 这个函数用于获取指向桶
4. cend()
container iterator (1)
const_iterator cend() const noexcept;
bucket iterator (2)
const_local_iterator cend ( size_type n ) const;
const_iterator cend() const noexcept;- 这个函数返回指向集合末尾的常量迭代器。与
end()类似,但这是一个常量成员函数,只允许读取元素而不能修改它们。 const noexcept表示这是一个不会抛出异常的常量成员函数。
- 这个函数返回指向集合末尾的常量迭代器。与
const_local_iterator cend(size_type n) const;- 这个函数用于获取指向桶
n的常量局部结束元素的迭代器。在哈希表中,元素被分布到不同的桶中,const_local_iterator允许您在特定桶中遍历元素。 size_type n参数指定桶的索引。
- 这个函数用于获取指向桶
unordered_set元素查找函数
1. find
iterator find ( const key_type& k );
const_iterator find ( const key_type& k ) const;
std::unordered_set 提供了 find() 成员函数,用于查找指定键值是否存在于集合中,并返回一个迭代器,指向包含该键值的元素(如果存在)或指向 end()(如果不存在)。
以下是 std::unordered_set 中 find() 函数的两个重载形式:
iterator find(const key_type& k);- 这个版本的
find()函数返回一个迭代器,指向包含键值k的元素(如果存在),否则返回指向end()的迭代器。 - 如果要对找到的元素进行修改,可以使用此迭代器。
- 这个版本的
const_iterator find(const key_type& k) const;- 这是常量版本的
find()函数,返回一个常量迭代器,用于查找包含键值k的元素(如果存在),否则返回指向end()的常量迭代器。 - 如果您只需要查找元素而不打算修改它,可以使用此常量迭代器。
- 这是常量版本的
这些 find() 函数是在 std::unordered_set 中查找特定键值的常见方式,它们允许你快速确定某个键是否存在于集合中,并让你访问该元素(如果存在)。
以下是使用 std::unordered_set 的 find() 函数的示例:
#include <iostream>
#include <unordered_set>
int main() {
std::unordered_set<int> mySet = {
1, 2, 3, 4, 5};
// 查找特定键值
int keyToFind = 3;
auto it = mySet.find(keyToFind);
// 检查元素是否存在
if (it != mySet.end()) {
std::cout << "键值 " << keyToFind << " 存在于集合中,对应的元素是 " << *it << std::endl;
} else {
std::cout << "键值 " << keyToFind << " 不存在于集合中" << std::endl;
}
// 尝试查找一个不存在的键值
int nonExistentKey = 6;
auto nonExistentIt = mySet.find(nonExistentKey);
if (nonExistentIt != mySet.end()) {
std::cout << "键值 " << nonExistentKey << " 存在于集合中,对应的元素是 " << *nonExistentIt << std::endl;
} else {
std::cout << "键值 " << nonExistentKey << " 不存在于集合中" << std::endl;
}
return 0;
}
在这个示例中,我们使用 find() 函数查找特定的键值(3 和 6),并根据查找结果输出相应的信息。如果键值存在于集合中,find() 返回指向该元素的迭代器,否则返回指向 end() 的迭代器。
2. count
size_type count ( const key_type& k ) const;
std::unordered_set 提供了 count() 成员函数,用于计算指定键值在集合中的出现次数。这个函数接受一个键值作为参数,并返回一个表示键值在集合中出现的次数的整数。
以下是 std::unordered_set 中 count() 函数的示例用法:
#include <iostream>
#include <unordered_set>
int main() {
std::unordered_set<int> mySet = {
1, 2, 2, 3, 4, 5, 5, 5};
// 计算指定键值的出现次数
int keyToCount = 2;
std::unordered_set<int>::size_type occurrences = mySet.count(keyToCount);
std::cout << "键值 " << keyToCount << " 在集合中出现了 " << occurrences << " 次" << std::endl;
// 计算一个不存在的键值的出现次数
int nonExistentKey = 6;
std::unordered_set<int>::size_type nonExistentOccurrences = mySet.count(nonExistentKey);
std::cout << "键值 " << nonExistentKey << " 在集合中出现了 " << nonExistentOccurrences << " 次" << std::endl;
return 0;
}
在这个示例中,我们使用 count() 函数来计算指定键值在集合中的出现次数。对于存在的键值(例如2),count() 将返回键值在集合中的实际出现次数,而对于不存在的键值(例如6),count() 将返回0。这个函数对于统计元素出现的次数非常有用。
3. equal_range
pair<iterator,iterator>
equal_range ( const key_type& k );
pair<const_iterator,const_iterator>
equal_range ( const key_type& k ) const;
std::unordered_set 提供了 equal_range() 成员函数,用于查找与指定键值相等的元素范围。这个函数返回一个 std::pair,包含两个迭代器,分别指向范围的开始和结束。
以下是 std::unordered_set 中 equal_range() 函数的两个不同重载的示例用法:
#include <iostream>
#include <unordered_set>
int main() {
std::unordered_set<int> mySet = {
1, 2, 2, 3, 4, 5, 5, 5};
// 查找与指定键值相等的元素范围
int keyToFind = 2;
auto range = mySet.equal_range(keyToFind);
std::cout << "元素范围,键值 " << keyToFind << ": ";
for (auto it = range.first; it != range.second; ++it) {
std::cout << *it << " ";
}
std::cout << std::endl;
// 尝试查找一个不存在的键值的元素范围
int nonExistentKey = 6;
auto nonExistentRange = mySet.equal_range(nonExistentKey);
std::cout << "元素范围,键值 " << nonExistentKey << ": ";
for (auto it = nonExistentRange.first; it != nonExistentRange.second; ++it) {
std::cout << *it << " ";
}
std::cout << std::endl;
return 0;
}
在这个示例中,我们使用 equal_range() 函数来查找与指定键值相等的元素范围。对于存在的键值(例如2),equal_range() 返回一个包含范围的 std::pair,并使用迭代器遍历该范围。对于不存在的键值(例如6),equal_range() 返回一个范围,但这个范围为空,因此迭代器范围为相等的 begin() 和 end(),不会有元素遍历。这个函数对于查找集合中具有相同键值的元素非常有用。
unordered_set修饰符函数
1. emplace
template <class... Args>
pair <iterator,bool> emplace ( Args&&... args );
emplace() 成员函数,用于通过构造元素并插入集合中来有效地添加新元素。这个函数返回一个 std::pair,其中包含一个迭代器和一个布尔值。
以下是 std::unordered_set 中 emplace() 函数的示例用法:
#include <iostream>
#include <unordered_set>
#include <string>
int main() {
std::unordered_set<std::string> mySet;
// 使用 emplace() 插入新元素
auto result1 = mySet.emplace("apple");
auto result2 = mySet.emplace("banana");
// 检查插入结果
if (result1.second) {
std::cout << "插入成功: " << *result1.first << std::endl;
} else {
std::cout << "插入失败: " << *result1.first << " 已存在" << std::endl;
}
if (result2.second) {
std::cout << "插入成功: " << *result2.first << std::endl;
} else {
std::cout << "插入失败: " << *result2.first << " 已存在" << std::endl;
}
return 0;
}
在这个示例中,我们使用 emplace() 函数向 std::unordered_set 中插入新元素。该函数允许您通过传递构造元素所需的参数来创建元素,而不需要显式地创建对象然后插入。emplace() 返回一个 std::pair,其中的 first 成员是一个迭代器,指向插入的元素(或已存在的元素),而 second 成员是一个布尔值,指示插入是否成功。如果元素已存在,则 emplace() 返回已存在的元素的迭代器和 false,否则返回新插入的元素的迭代器和 true。
2. emplace_hint
template <class... Args>
iterator emplace_hint ( const_iterator position, Args&&... args );
emplace_hint() 成员函数,用于在指定位置的提示下(hint)插入新元素。这个函数接受一个常量迭代器 position 作为提示,以及用于构造新元素的参数。
以下是 std::unordered_set 中 emplace_hint() 函数的示例用法:
#include <iostream>
#include <unordered_set>
#include <string>
int main() {
std::unordered_set<std::string> mySet = {
"apple", "banana"};
// 使用 emplace_hint() 在提示位置插入新元素
std::string hint = "cherry";
auto hintIterator = mySet.find(hint); // 获取提示位置的迭代器
if (hintIterator != mySet.end()) {
mySet.emplace_hint(hintIterator, "grape");
} else {
std::cout << "提示位置不存在" << std::endl;
}
// 输出集合中的元素
for (const std::string& fruit : mySet) {
std::cout << fruit << " ";
}
std::cout << std::endl;
return 0;
}
在这个示例中,我们首先获取了一个提示位置的迭代器,然后使用 emplace_hint() 函数在提示位置插入新元素。emplace_hint() 接受一个迭代器 position 作为提示位置,并在此位置之前插入新元素。如果提示位置不存在,可以采取相应的处理措施,如示例中所示。
3. insert
(1) pair<iterator,bool> insert ( const value_type& val );
(2) pair<iterator,bool> insert ( value_type&& val );
(3) iterator insert ( const_iterator hint, const value_type& val );
(4) iterator insert ( const_iterator hint, value_type&& val );
(5) template <class InputIterator>
void insert ( InputIterator first, InputIterator last );
(6) void insert ( initializer_list<value_type> il );
insert() 成员函数,用于将元素插入集合中。以下是这些 insert() 函数的不同形式:
(1)pair<iterator, bool> insert(const value_type& val);- 这个函数将一个值
val插入到集合中。 - 如果成功插入了元素,它返回一个包含插入的元素的迭代器和
true的std::pair。 - 如果元素已存在于集合中,它返回一个指向现有元素的迭代器和
false。
- 这个函数将一个值
(2)pair<iterator, bool> insert(value_type&& val);- 这个函数用于将一个右值引用
val插入到集合中。 - 类似于
(1),如果成功插入了元素,它返回一个包含插入的元素的迭代器和true。 - 如果元素已存在于集合中,它返回一个指向现有元素的迭代器和
false。
- 这个函数用于将一个右值引用
(3)iterator insert(const_iterator hint, const value_type& val);- 这个函数将一个值
val插入到集合中,并使用提示位置hint来优化插入操作。 - 返回一个迭代器,指向插入的元素或现有元素(如果元素已存在)。
- 这个函数将一个值
(4)iterator insert(const_iterator hint, value_type&& val);- 这是
(3)的右值引用版本,类似于(3),它使用提示位置hint来优化插入操作。
- 这是
(5)template <class InputIterator> void insert(InputIterator first, InputIterator last);- 这个函数接受一个迭代器范围
[first, last),并将范围内的元素插入到集合中。
- 这个函数接受一个迭代器范围
(6)void insert(initializer_list<value_type> il);- 这个函数接受一个初始化列表,并将其中的元素插入到集合中。
这些不同形式的 insert() 函数允许您以多种方式将元素插入到 std::unordered_set 中,包括单个元素的插入、使用提示位置的插入、范围插入和初始化列表插入。插入时会检查元素是否已经存在,如果存在,则不会重复插入相同的元素。
以下是一些使用不同形式的 insert() 函数来将元素插入 std::unordered_set 中的示例:
#include <iostream>
#include <unordered_set>
int main() {
std::unordered_set<int> mySet;
// (1) 插入单个元素
auto result1 = mySet.insert(1);
auto result2 = mySet.insert(2);
if (result1.second) {
std::cout << "成功插入元素 " << *result1.first << std::endl;
} else {
std::cout << "元素 " << *result1.first << " 已存在" << std::endl;
}
if (result2.second) {
std::cout << "成功插入元素 " << *result2.first << std::endl;
} else {
std::cout << "元素 " << *result2.first << " 已存在" << std::endl;
}
// (3) 使用提示位置插入元素
std::unordered_set<int>::iterator hint = mySet.find(3);
if (hint != mySet.end()) {
mySet.insert(hint, 4);
} else {
std::cout << "提示位置不存在" << std::endl;
}
// (5) 范围插入元素
std::unordered_set<int> anotherSet = {
5, 6, 7};
mySet.insert(anotherSet.begin(), anotherSet.end());
// (6) 使用初始化列表插入元素
mySet.insert({
8, 9, 10});
// 输出集合中的元素
for (const int& element : mySet) {
std::cout << element << " ";
}
std::cout << std::endl;
return 0;
}
在这个示例中,我们使用不同形式的 insert() 函数将元素插入到 std::unordered_set 中。程序输出了每次插入的结果,如果元素已存在,则显示相应的消息。最后,我们遍历集合以查看插入的元素。这演示了如何使用不同的 insert() 函数来操作 std::unordered_set。
4. erase
by position (1)
iterator erase ( const_iterator position );
by key (2)
size_type erase ( const key_type& k );
range (3)
iterator erase ( const_iterator first, const_iterator last );
以下是使用不同形式的 erase() 函数从 std::unordered_set 中删除元素的示例:
#include <iostream>
#include <unordered_set>
int main() {
std::unordered_set<int> mySet = {
1, 2, 3, 4, 5};
// (1) 通过位置删除元素
std::unordered_set<int>::const_iterator position = mySet.find(3);
if (position != mySet.end()) {
mySet.erase(position);
}
// (2) 通过键值删除元素
int keyToRemove = 5;
size_t elementsRemoved = mySet.erase(keyToRemove);
std::cout << "删除了 " << elementsRemoved << " 个键值为 " << keyToRemove << " 的元素" << std::endl;
// (3) 通过范围删除元素
std::unordered_set<int>::const_iterator first = mySet.begin();
std::unordered_set<int>::const_iterator last = mySet.end();
mySet.erase(first, last);
// 输出剩余的元素
for (const int& element : mySet) {
std::cout << element << " ";
}
std::cout << std::endl;
return 0;
}
在这个示例中,我们使用不同形式的 erase() 函数删除 std::unordered_set 中的元素。首先,我们通过位置、键值和范围删除了元素,然后输出了删除操作之后的集合内容。这演示了如何使用 erase() 函数来删除元素。
5. clear
void clear() noexcept;
clear() 成员函数,用于清空集合,即删除集合中的所有元素,使其变为空集合。这个函数没有参数,不会抛出异常,并且具有 noexcept 保证,表示它不会引发异常。
以下是使用 clear() 函数的示例:
#include <iostream>
#include <unordered_set>
int main() {
std::unordered_set<int> mySet = {
1, 2, 3, 4, 5};
// 输出原始集合内容
std::cout << "原始集合内容:";
for (const int& element : mySet) {
std::cout << " " << element;
}
std::cout << std::endl;
// 清空集合
mySet.clear();
// 输出清空后的集合内容
std::cout << "清空后的集合内容:";
for (const int& element : mySet) {
std::cout << " " << element;
}
std::cout << std::endl;
return 0;
}
在这个示例中,我们首先输出原始集合的内容,然后使用 clear() 函数清空集合。最后,我们再次输出集合的内容,可以看到清空操作使集合变为空集合。这是一种快速清空集合的方法。
6. swap
void swap ( unordered_set& ust );
swap() 成员函数,用于交换两个集合的内容,即将一个集合的元素和另一个集合的元素互换。
以下是使用 swap() 函数的示例:
#include <iostream>
#include <unordered_set>
int main() {
std::unordered_set<int> set1 = {
1, 2, 3};
std::unordered_set<int> set2 = {
4, 5, 6};
// 输出交换前的集合内容
std::cout << "交换前 set1:";
for (const int& element : set1) {
std::cout << " " << element;
}
std::cout << std::endl;
std::cout << "交换前 set2:";
for (const int& element : set2) {
std::cout << " " << element;
}
std::cout << std::endl;
// 使用 swap() 函数交换两个集合的内容
set1.swap(set2);
// 输出交换后的集合内容
std::cout << "交换后 set1:";
for (const int& element : set1) {
std::cout << " " << element;
}
std::cout << std::endl;
std::cout << "交换后 set2:";
for (const int& element : set2) {
std::cout << " " << element;
}
std::cout << std::endl;
return 0;
}
在这个示例中,我们首先输出了交换前两个集合的内容,然后使用 swap() 函数交换了它们的内容,最后输出了交换后两个集合的内容。可以看到,集合的内容已经互换。这个函数非常有用,可以用于高效地交换两个集合的内容,而无需复制元素。
unordered_set桶函数
1. bucket_count
size_type bucket_count() const noexcept;
bucket_count() 成员函数,用于获取哈希表中的桶的数量。哈希表是用来实现 std::unordered_set 的底层数据结构,它将元素分布到不同的桶中,以提高查找性能。
以下是使用 bucket_count() 函数的示例:
#include <iostream>
#include <unordered_set>
int main() {
std::unordered_set<int> mySet = {
1, 2, 3, 4, 5};
// 获取桶的数量
std::unordered_set<int>::size_type bucketCount = mySet.bucket_count();
std::cout << "哈希表中的桶的数量为: " << bucketCount << std::endl;
return 0;
}
在这个示例中,我们使用 bucket_count() 函数来获取哈希表中的桶的数量,并将其输出到控制台。这个值可以帮助你了解哈希表的大小和性能。请注意,桶的数量可以随着哈希表的调整而变化,以保持性能。
2. max_bucket_count
size_type max_bucket_count() const noexcept;
max_bucket_count() 成员函数,用于获取哈希表支持的最大桶的数量。这个值通常受到实现限制,取决于计算机的硬件和操作系统。
以下是使用 max_bucket_count() 函数的示例:
#include <iostream>
#include <unordered_set>
int main() {
std::unordered_set<int> mySet = {
1, 2, 3, 4, 5};
// 获取支持的最大桶的数量
std::unordered_set<int>::size_type maxBucketCount = mySet.max_bucket_count();
std::cout << "哈希表支持的最大桶的数量为: " << maxBucketCount << std::endl;
return 0;
}
在这个示例中,我们使用 max_bucket_count() 函数来获取哈希表支持的最大桶的数量,并将其输出到控制台。这个值是由标准库实现定义的,通常是一个大整数,代表了哈希表可以容纳的最大桶数。这有助于你了解哈希表的容量限制。
3. bucket_size
size_type bucket_size ( size_type n ) const;
bucket_size(size_type n) 成员函数,用于获取指定桶中的元素数量。您需要传递一个桶的索引 n,然后这个函数将返回该桶中元素的数量。
以下是使用 bucket_size() 函数的示例:
#include <iostream>
#include <unordered_set>
int main() {
std::unordered_set<int> mySet = {
1, 2, 3, 4, 5};
// 获取第一个桶中的元素数量
std::unordered_set<int>::size_type bucketSize = mySet.bucket_size(0);
std::cout << "第一个桶中的元素数量为: " << bucketSize << std::endl;
return 0;
}
在这个示例中,我们使用 bucket_size() 函数来获取第一个桶中的元素数量,并将其输出到控制台。这可以帮助您了解特定桶中的元素数量,有助于调试和了解哈希表的分布情况。请注意,不同桶中的元素数量可能不同。
4. bucket
size_type bucket ( const key_type& k ) const;
bucket(const key_type& k) 成员函数,用于获取与特定键值 k 相关联的桶的索引。这个函数返回一个 size_type 值,表示键值 k 对应的桶的索引。
以下是使用 bucket() 函数的示例:
#include <iostream>
#include <unordered_set>
int main() {
std::unordered_set<int> mySet = {
1, 2, 3, 4, 5};
int keyToFind = 3;
// 获取键值 3 对应的桶的索引
std::unordered_set<int>::size_type bucketIndex = mySet.bucket(keyToFind);
std::cout << "键值 " << keyToFind << " 对应的桶的索引为: " << bucketIndex << std::endl;
return 0;
}
在这个示例中,我们使用 bucket() 函数来获取键值 3 对应的桶的索引,并将其输出到控制台。这个函数可以帮助您了解特定键值在哈希表中的分布情况,以及它位于哪个桶中。不同键值可能位于不同的桶中。
unordered_set哈希策略函数
1. load_factor
float load_factor() const noexcept;
load_factor() 成员函数,用于获取当前哈希表的负载因子。负载因子是哈希表中元素数量与桶数量的比率。它可以用来衡量哈希表的填充程度,通常用于判断何时需要重新调整哈希表的大小以保持性能。
load_factor() 返回一个 float 值,表示当前的负载因子。
以下是使用 load_factor() 函数的示例:
#include <iostream>
#include <unordered_set>
int main() {
std::unordered_set<int> mySet = {
1, 2, 3, 4, 5};
// 获取当前哈希表的负载因子
float currentLoadFactor = mySet.load_factor();
std::cout << "当前哈希表的负载因子为: " << currentLoadFactor << std::endl;
return 0;
}
在这个示例中,我们使用 load_factor() 函数来获取当前哈希表的负载因子,并将其输出到控制台。负载因子可以帮助你监测哈希表的填充程度,根据需要调整哈希表的大小以保持性能。通常,负载因子小于某个阈值时,会触发哈希表的重新调整大小操作。
2. max_load_factor
(1)float max_load_factor() const noexcept;- 这个函数用于获取当前哈希表的最大负载因子。最大负载因子是哈希表可以容忍的最大填充程度。默认情况下,它通常是一个较小的浮点数(例如0.75)。
- 这个函数返回一个
float值,表示当前哈希表的最大负载因子。
(2)void max_load_factor(float z);- 这个函数用于设置哈希表的最大负载因子为指定的值
z。 - 你可以使用这个函数来调整哈希表的最大负载因子,以控制在何时触发哈希表的重新调整大小操作。
- 这个函数用于设置哈希表的最大负载因子为指定的值
以下是使用这两个函数的示例:
#include <iostream>
#include <unordered_set>
int main() {
std::unordered_set<int> mySet = {
1, 2, 3, 4, 5};
// 获取当前哈希表的最大负载因子
float currentMaxLoadFactor = mySet.max_load_factor();
std::cout << "当前哈希表的最大负载因子为: " << currentMaxLoadFactor << std::endl;
// 设置新的最大负载因子
float newMaxLoadFactor = 0.6;
mySet.max_load_factor(newMaxLoadFactor);
// 再次获取最大负载因子,检查是否已更新
float updatedMaxLoadFactor = mySet.max_load_factor();
std::cout << "更新后的最大负载因子为: " << updatedMaxLoadFactor << std::endl;
return 0;
}
在这个示例中,我们首先使用 max_load_factor() 函数获取当前的最大负载因子,然后使用 max_load_factor() 函数来设置新的最大负载因子。这允许你根据需要调整哈希表的填充程度,以控制何时触发哈希表的重新调整大小操作。
3. rehash
rehash(size_type n) 成员函数,用于重新调整哈希表的桶数量,以容纳指定数量的桶。这可以用于手动调整哈希表的大小以提高性能或满足特定需求。
以下是使用 rehash() 函数的示例:
#include <iostream>
#include <unordered_set>
int main() {
std::unordered_set<int> mySet = {
1, 2, 3, 4, 5};
// 获取当前哈希表的桶数量
std::unordered_set<int>::size_type currentBucketCount = mySet.bucket_count();
std::cout << "当前哈希表的桶数量为: " << currentBucketCount << std::endl;
// 手动调整哈希表的桶数量
std::unordered_set<int>::size_type newBucketCount = 10;
mySet.rehash(newBucketCount);
// 再次获取桶数量,检查是否已更新
std::unordered_set<int>::size_type updatedBucketCount = mySet.bucket_count();
std::cout << "更新后的哈希表的桶数量为: " << updatedBucketCount << std::endl;
return 0;
}
在这个示例中,我们首先使用 bucket_count() 函数获取当前的桶数量,然后使用 rehash() 函数来手动调整哈希表的桶数量。这允许你根据需要控制哈希表的大小,以满足性能或内存需求。调整哈希表的桶数量可能需要重新分布元素,因此可能会影响性能
4. reserve
reserve(size_type n) 成员函数,用于预留足够的桶空间以容纳至少 n 个元素,以提高性能。这个函数的参数 n 表示预留的元素数量,但不是桶的数量。
以下是使用 reserve() 函数的示例:
#include <iostream>
#include <unordered_set>
int main() {
std::unordered_set<int> mySet = {
1, 2, 3, 4, 5};
// 获取当前哈希表的桶数量
std::unordered_set<int>::size_type currentBucketCount = mySet.bucket_count();
std::cout << "当前哈希表的桶数量为: " << currentBucketCount << std::endl;
// 预留足够的桶空间以容纳至少 10 个元素
std::unordered_set<int>::size_type reserveCount = 10;
mySet.reserve(reserveCount);
// 再次获取桶数量,检查是否已更新
std::unordered_set<int>::size_type updatedBucketCount = mySet.bucket_count();
std::cout << "更新后的哈希表的桶数量为: " << updatedBucketCount << std::endl;
return 0;
}
在这个示例中,我们首先使用 bucket_count() 函数获取当前的桶数量,然后使用 reserve() 函数来预留足够的桶空间,以容纳至少 10 个元素。这有助于提高插入和查找操作的性能,因为哈希表不需要频繁地重新调整大小。请注意,桶的数量可能大于指定的元素数量,以确保性能。
unordered_set开散列形式模拟实现
和我上一篇unordered_map博客是用的同一段源代码,模拟实现也类似
HashTable.h全部代码
#pragma once
#include<iostream>
#include<utility>
#include<vector>
#include<string>
using namespace std;
template<class K>
struct HashFunc
{
size_t operator()(const K& key)
{
return (size_t)key;
}
};
template<>
struct HashFunc<string>
{
size_t operator()(const string& key)
{
size_t val = 0;
for (auto ch : key)
{
val *= 131;
val += ch;
}
return val;
}
};
namespace Bucket
{
template<class T>
struct HashNode
{
T _data;
HashNode<T>* _next;
HashNode(const T& data)
:_data(data)
, _next(nullptr)
{
}
};
// 前置声明
template<class K, class T, class Hash, class KeyOfT>
class HashTable;
template<class K, class T, class Hash, class KeyOfT>
struct __HashIterator
{
typedef HashNode<T> Node;
typedef HashTable<K, T, Hash, KeyOfT> HT;
typedef __HashIterator<K, T, Hash, KeyOfT> Self;
Node* _node;
HT* _pht;
__HashIterator(Node* node, HT* pht)
:_node(node)
, _pht(pht)
{
}
T& operator*()
{
return _node->_data;
}
T* operator->()
{
return &_node->_data;
}
Self& operator++()
{
if (_node->_next)
{
// 当前桶中迭代
_node = _node->_next;
}
else
{
// 找下一个桶
Hash hash;
KeyOfT kot;
size_t i = hash(kot(_node->_data)) % _pht->_tables.size();
++i;
for (; i < _pht->_tables.size(); ++i)
{
if (_pht->_tables[i])
{
_node = _pht->_tables[i];
break;
}
}
// 说明后面没有有数据的桶了
if (i == _pht->_tables.size())
{
_node = nullptr;
}
}
return *this;
}
bool operator!=(const Self& s) const
{
return _node != s._node;
}
bool operator==(const Self& s) const
{
return _node == s._node;
}
};
template<class K, class T, class Hash, class KeyOfT>
class HashTable
{
typedef HashNode<T> Node;
template<class K, class T, class Hash, class KeyOfT>
friend struct __HashIterator;
public:
typedef __HashIterator<K, T, Hash, KeyOfT> iterator;
iterator begin()
{
for (size_t i = 0; i < _tables.size(); ++i)
{
if (_tables[i])
{
return iterator(_tables[i], this);
}
}
return end();
}
iterator end()
{
return iterator(nullptr, this);
}
~HashTable()
{
for (size_t i = 0; i < _tables.size(); ++i)
{
Node* cur = _tables[i];
while (cur)
{
Node* next = cur->_next;
delete cur;
cur = next;
}
_tables[i] = nullptr;
}
}
inline size_t __stl_next_prime(size_t n)
{
static const size_t __stl_num_primes = 28;
static const size_t __stl_prime_list[__stl_num_primes] =
{
53, 97, 193, 389, 769,
1543, 3079, 6151, 12289, 24593,
49157, 98317, 196613, 393241, 786433,
1572869, 3145739, 6291469, 12582917, 25165843,
50331653, 100663319, 201326611, 402653189, 805306457,
1610612741, 3221225473, 4294967291
};
for (size_t i = 0; i < __stl_num_primes; ++i)
{
if (__stl_prime_list[i] > n)
{
return __stl_prime_list[i];
}
}
return -1;
}
pair<iterator, bool> Insert(const T& data)
{
Hash hash;
KeyOfT kot;
// 去重
iterator ret = Find(kot(data));
if (ret != end())
{
return make_pair(ret, false);
}
// 负载因子到1就扩容
if (_size == _tables.size())
{
vector<Node*> newTables;
newTables.resize(__stl_next_prime(_tables.size()), nullptr);
// 旧表中节点移动映射新表
for (size_t i = 0; i < _tables.size(); ++i)
{
Node* cur = _tables[i];
while (cur)
{
Node* next = cur->_next;
size_t hashi = hash(kot(cur->_data)) % newTables.size();
cur->_next = newTables[hashi];
newTables[hashi] = cur;
cur = next;
}
_tables[i] = nullptr;
}
_tables.swap(newTables);
}
size_t hashi = hash(kot(data)) % _tables.size();
// 头插
Node* newnode = new Node(data);
newnode->_next = _tables[hashi];
_tables[hashi] = newnode;
++_size;
return make_pair(iterator(newnode, this), true);
}
iterator Find(const K& key)
{
if (_tables.size() == 0)
{
return end();
}
Hash hash;
KeyOfT kot;
size_t hashi = hash(key) % _tables.size();
Node* cur = _tables[hashi];
while (cur)
{
if (kot(cur->_data) == key)
{
return iterator(cur, this);
}
cur = cur->_next;
}
return end();
}
bool Erase(const K& key)
{
if (_tables.size() == 0)
{
return false;
}
Hash hash;
KeyOfT kot;
size_t hashi = hash(key) % _tables.size();
Node* prev = nullptr;
Node* cur = _tables[hashi];
while (cur)
{
if (kot(cur->_data) == key)
{
// 1、头删
// 2、中间删
if (prev == nullptr)
{
_tables[hashi] = cur->_next;
}
else
{
prev->_next = cur->_next;
}
delete cur;
--_size;
return true;
}
prev = cur;
cur = cur->_next;
}
return false;
}
size_t Size()
{
return _size;
}
// 表的长度
size_t TablesSize()
{
return _tables.size();
}
// 桶的个数
size_t BucketNum()
{
size_t num = 0;
for (size_t i = 0; i < _tables.size(); ++i)
{
if (_tables[i])
{
++num;
}
}
return num;
}
size_t MaxBucketLenth()
{
size_t maxLen = 0;
for (size_t i = 0; i < _tables.size(); ++i)
{
size_t len = 0;
Node* cur = _tables[i];
while (cur)
{
++len;
cur = cur->_next;
}
if (len > maxLen)
{
maxLen = len;
}
}
return maxLen;
}
private:
vector<Node*> _tables;
size_t _size = 0; // 存储有效数据个数
};
};
利用哈希表封装实现unordered_set
#pragma once
#include "HashTable.h"
namespace yulao
{
template<class K, class Hash = HashFunc<K>>
class unordered_set
{
struct SetKeyOfT
{
const K& operator()(const K& key)
{
return key;
}
};
public:
typedef typename Bucket::HashTable<K, K, Hash, SetKeyOfT>::iterator iterator;
iterator begin()
{
return _ht.begin();
}
iterator end()
{
return _ht.end();
}
pair<iterator, bool> insert(const K& key)
{
return _ht.Insert(key);
}
private:
Bucket::HashTable<K, K, Hash, SetKeyOfT> _ht;
};
}