【藏经阁一起读(71)】读《阿里云 ClickHouse 企业版技术白皮书》

作者: Tom Schreiber 凤豪 卫寻 魏庄
本书由 ClickHouse 资深技术专家和产品联合撰写,全面介绍了ClickHouse企业版的云原生存算分离整体架构,详细介绍 SharedMergeTree表引擎的实现机制原理及基准测试结果,并介绍 Lightweight update 增强数据更新的实时性的实现原理,是学习 ClickHouse 云原生技术的宝贵资源。
《阿里云 ClickHouse 企业版技术白皮书》不属于初级技术书籍,Clickhouse是什么,文中没有相关介绍,我自己先补习了一些相关知识:
一、什么是clickhouse
ClickHouse是一种OLAP类型的列式数据库管理系统,是一个全球流行的开源高性能、可扩展列式数据库技术,核心应用于在线分析处理(OLAP)业务,
ClickHouse完美的实现了OLAP和列式数据库的优势,因此在大数据量的分析处理应用中Clickhouse表现很优秀。
ClickHouse是一个用于联机分析(OLAP)的列式数据库管理系统(DBMS)。
1.1、OLAP联机分析处理
OLAP(OnLine Analysis Processing ,联机分析处理 ) 是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。在实际的商业分析中,OLAP联机分析更多的是指对数据分析的一种解决方案。
OLAP联机分析首先是把数据预处理成数据立方(Cube),并把有可能的汇总都预先算出来(即预聚合处理),然后在用户选择多维度汇总时,在预先的计算出来的数据基础上很快地计算出用户想要的结果,从而可以更好更快地支持极大数据量的及时分析。
OLAP联机分析最基本的工作就是对数据方(Cube)的操作
OLAP联机分析是从多维信息、多层次信息的角度,针对特定问题进行数据的汇总分析。
OLAP场景的关键特征
- 绝大多数是读请求
- 数据以相当大的批次(> 1000行)更新,而不是单行更新;或者根本没有更新。
- 已添加到数据库的数据不能修改。
- 对于读取,从数据库中提取相当多的行,但只提取列的一小部分。
- 宽表,即每个表包含着大量的列
- 查询相对较少(通常每台服务器每秒查询数百次或更少)
- 对于简单查询,允许延迟大约50毫秒
- 列中的数据相对较小:数字和短字符串(例如,每个URL 60个字节)
- 处理单个查询时需要高吞吐量(每台服务器每秒可达数十亿行)
- 事务不是必须的
- 对数据一致性要求低
- 每个查询有一个大表。除了他以外,其他的都很小。
- 查询结果明显小于源数据。换句话说,数据经过过滤或聚合,因此结果适合于单个服务器的RAM中
OLAP场景与其他通常业务场景有很大的不同, 因此想要使用OLTP或Key-Value数据库去高效的处理分析查询场景,并不是非常完美的适用方案。例如,使用OLAP数据库去处理分析请求通常要优于使用MongoDB或Redis去处理分析请求。
1.2、行式数据库系统
在传统的行式数据库系统中,数据按如下顺序存储:


处于同一行中的数据总是被物理的存储在一起。
常见的行式数据库系统有:MySQL、Postgres和MS SQL Server。
1.3、列式数据库系统
在列式数据库系统中,数据按如下的顺序存储:

这些示例只显示了数据的排列顺序。来自不同列的值被单独存储,来自同一列的数据被存储在一起。
常见的列式数据库有: Vertica、 Paraccel (Actian Matrix,Amazon Redshift)、 Sybase IQ、 Exasol、 Infobright、 InfiniDB、 MonetDB (VectorWise, Actian Vector)、 LucidDB、 SAP HANA、 Google Dremel、 Google PowerDrill、 Druid、 kdb+。
列式数据库更适合于OLAP场景

1.4、方式选择
不同的数据存储方式适用不同的业务场景,数据访问的场景包括:进行了何种查询、多久查询一次以及各类查询的比例;每种类型的查询(行、列和字节)读取多少数据;读取数据和更新之间的关系;使用的数据集大小以及如何使用本地的数据集;是否使用事务,以及它们是如何进行隔离的;数据的复制机制与数据的完整性要求;每种类型的查询要求的延迟与吞吐量等等。
系统负载越高,依据使用场景进行定制化就越重要,并且定制将会变的越精细。没有一个系统能够同时适用所有不同的业务场景。如果系统适用于广泛的场景,在负载高的情况下,要兼顾所有的场景,那么将不得不做出选择。是要平衡还是要效率?
ClickHouse在DB—Engine 全球数据库流行度排榜排名前列,逐年关注度增长迅猛。ClickHouse 分析性能优异,典型分析场景下,支持数十亿级数据行规模,90%查询在1秒内完成。这使得 ClickHouse 成为企业处理大规模数据,构建实时数仓的理想选择。国内外大厂中,微软,腾讯、ebay,淘宝、Uber,京东、快手、小红书,携程都使用 ClickHouse 构建数据分析平台。
1.5、MergeTree表引擎
MergeTree(合并树)系列表引擎是ClickHouse提供的最具特色的存储引擎。MergeTree 引擎系列的基本理念如下。当你有巨量数据要插入到表中,你要高效地一批批写入数据片段,并希望这些数据片段在后台按照一定规则合并。相比在插入时不断修改(重写)数据进存储,这种策略会高效很多。MergeTree引擎支持数据按主键、数据分区、数据副本以及数据采样等特性。官方提供了包括MergeTree、ReplacingMergeTree、SummingMergeTree、AggregatingMergeTree、CollapsingMergeTree、VersionedCollapsingMergeTree、GraphiteMergeTree等7种不同类型的MergeTree引擎的实现,以及与其相对应的支持数据副本的MergeTree引擎(Replicated*)。
MergeTree是该系列引擎中最核心的引擎,其他引擎均以MergeTree为基础,并在数据合并过程中实现了不同的特性,从而构成了MergeTree表引擎家族。
二、ClickHouse 企业版云原生架构
ClickHouse 企业版采用完全不同与开源社区版本的云原生新架构,针对云环境做了全面适配。新架构基于存储和计算分离的架构基础,采用对象存储数据实现 Share Storage 共享存储,所有ClickHouse Server 节点都可以访问相同的全局物理数据,单个Server 节点实际上是单个没有限制分片的Replica 节点,节点之间访问同一份数据副本。
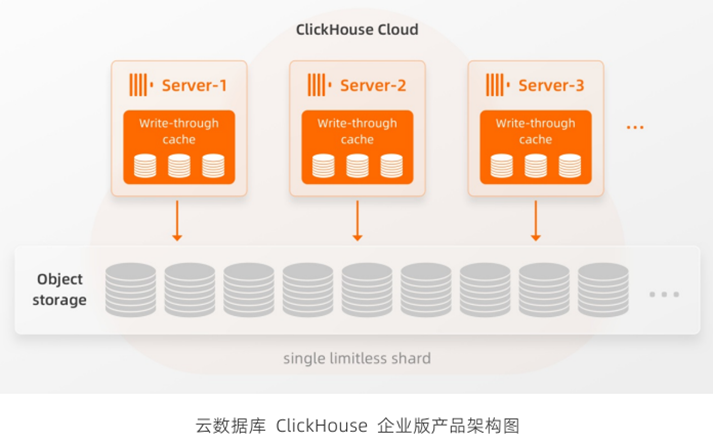
三、ClickHouse企业版引擎升级
MergeTree系列的表引擎是ClickHouse中的主要表引擎。它们负责存储插入的数据,在后台进行数据合并,根据特定的引擎进行数据转换等操作。企业版新推出SharedMergeTree引擎加入到MergeTree引擎大家庭,而企业版能够支持云原生架构箩也核心依赖sharedMergeTree引擎。sharedMergeTree引擎是商业化引擎,仅在企业版提供,在开源社区版不支持。
3.1、开源ReplicatedMergeTree引擎
大多数MergeTree家族中的表都支持自动的数据复制,并通过表引擎的复制机制实现
3.2、云原生SharedMergeTree引擎ReplicatedMergeTree
SharedMergeTree表引擎是ClickHouse内核ReplicatedMergeTree表引擎的更高效的替代品,专为云原生数据处理而设计和优化。
深入了解这个表引擎,解释其优势,并通过基准测试展现其效率。
3.3、对象存储上的数据可用性
3.4、自动集群扩展
四、ReplicatedMergeTree的挑战
ReplicatedMergeTree表引擎并不适用于ClickHouse企业版的预期架构,因为其复制机制旨在在少量的节点上创建数据的物理副本。而ClickHouse企业版需要一个支持在对象存储之上运行本量计算服务节点的表引擎。
-
显式的数据复制
ReplicatedMergeTree表引擎的复制机制:使用ClickHouse Keeper(也称为“Keeper”)作为协调系统,通过复制日志方式进行数据复制。Keeper充当复制过程特定元数据和表结构的集中式存储,以及分布式操作的一致性协调系统。Keeper确保为Part顺序地分配连续的块编号,将merge和mutation操作分配给特定的replica。
下图概述了一个具有3个replica节点的shared-nothing架构的 ClickHouse集群,并显示了ReplicatedMergeTree表引擎的数据复制机制:
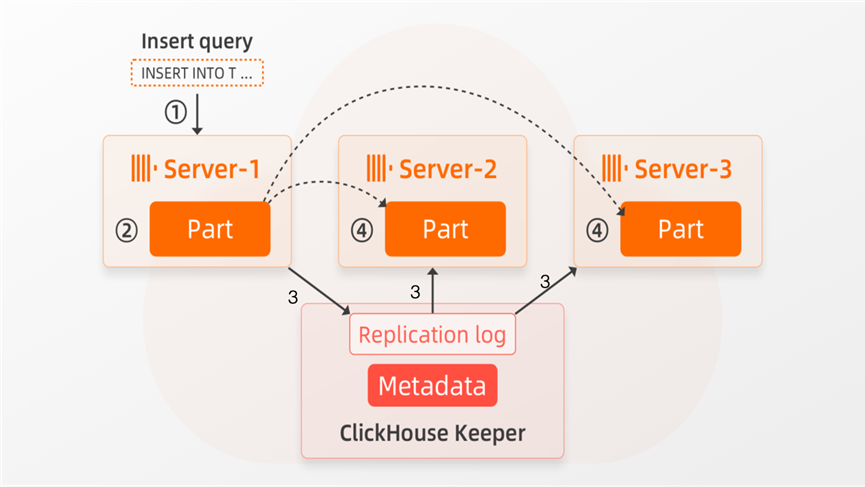
当 ① Server-1 接收到插入查询时,② Server-1 在其本地磁盘上创建一个包含插入数据的新Part。③通过复制日志,其他节点(Server-2、Server-3)被告知Server-1上存在一个新Part。在 ④ 处,其他server独立地从 server-1下载(“获取”)该Part到自己的本地文件系统。创建或接收Part后,三个节点还会在Keeper中更新元数据,元数据用以描述 Part 文件信息。
请注意,我们仅展示了如何复制新创建的Part。Part合并(和mutation)也以类似的方式复制。如果一个节点决定合并一组Parts,那么其他节点将在其本地Parts副本上自动执行相同的合并操作。
在本地存储完全丢失或添加新副本时,ReplicatedMergeTree从已有的副本克隆数据。
ClickHouse企业版使用持久性更好的对象存储来实现数据可用性,所以不需要ReplicatedMergeTree的显式数据复制功能。 -
依赖 sharding进行集群扩展
五、SharedMergeTree 升级
5.1、独立 SharedMergeTree 优点
ClickHouse企业版实现了一个名为 SharedMergeTree的表引擎 - 专为在共享存储上工作而设计。SharedMergeTree 是云原生方式,具有如下优点
(1) MergeTree 代码更加简单易维护,
(2)支持垂直和水平自动扩展,
(3)为我们的云用户提供未来的功能和改进,如更高的一致性保证,更好的耐用性,基于时间点数据恢复等。
5.2、SharedMergeTree 引擎下的集群扩展原理
在这里,我们简要介绍 SharedMergeTree 如何支持ClickHouse企业版自动进行集群扩展。提醒一下:ClickHouse企业版计算节点是具有访问共享存储的计算单元,其规格和数量可以更改。基于此机制,SharedMergeTree 完全将业务数据和元数据的存储与计算节点分离,并使用Keeper的接口去读取、写入和修改共享元数据。每个计算节点都有一个存储元数据的本地缓存,并通过订阅机制自动获取数据更改的通知。下图描述了如何使用 SharedMergeTree 将新服务器添加到集群中:
当Server-3 添加到集群时,这个新Server ① 订阅 Keeper 中的元数据更改信息并将当前Parts的元数据获取到其本地缓存中。这不需要任何锁机制;
②新Server基本上只需说:“我在这里。请随时通知我所有数据更改”。
③新添加的Server-3 几乎可以立即参与数据处理,因为它通过从 Keeper 中只获取必要的元数据信息,找到有哪些数据以及在共享存储中的什么位置。
5.3、SharedMergeTree 引擎下的数据一致性原理
下图描述所有Server 节点如何知道新插入的数据,来保证查询数据一致性:
① Server-1 接收到插入查询
② Server-1将写入的数据以Part的形式写入共享存储。
③ Server-1 还将关于该部分的信息存储在其本地缓存和 Keeper 中(例如,哪些文件属于该Part,以及与文件对应的块位于共享存储中的位置)。
④ ClickHouse 向查询的发送者确认插入成功。其他节点(Server-2、Server-3)通过 Keeper 的订阅机制 ⑤ 自动得到存储层中存在新数据的通知,并将更新的元数据提取到其本地缓存中。
请注意,在步骤 ④ 之后,插入的数据是持久的。即使Server-1或其他任何节点崩溃,Part都存储在高可用的存储中,元数据存储在 Keeper 中(Keeper 具有至少 3 个 Keeper节点的高可用设置)。
从集群中移除节点也是一个简单且快速的操作。为了优雅地移除,相关节点只需从 Keeper 中注销,以便处理进行中的分布式查询时不会出现缺少服务器的警告。
六、CIickHouse企业版收益
- 无缝集群扩展
ClickHouse企业版中,SharedMergeTree表引擎是RepIicatedMergeTree表引擎的更高效的替代品,为ClickHouse企业版用户带来以下好处。 - 插入操作的效率收益
- 更轻量级的强一致性Select查询
- 集群吞吐和查询效率的线性提升
七、SharedMergeTree引擎的兼容性
SharedMergeTree 表引擎现在已经作为 ClickHouse企业版中默认的表引擎。ClickHouse企业版支持的 MergeTree 家族中的所有特殊表引擎,并都会自动基于 SharedMergeTree 进行更新。
八、SharedMergeTree的实际应用对比
SharedMergeTree 支持无缝的集群扩展。测试中,后台合并的吞吐量与节点数量呈线性关系。当我们将节点数量从 3 增至 10 时,吞吐量也将增加三倍左右。当我们将节点数量再次增加 2 倍至 20,然后增加 4 倍至 80 时,吞吐量也分别增加了约两倍和四倍。正如预期的那样,使用ReplicatedMergeTree 在随着副本节点数量的增加时无法很好地扩展(甚至在较大的集群大小下会减少写入性能),而SharedMergeTree 则随着副本节点数量的增加而获得更好的扩展。因为它的复制机制不适用于处理大量副本的情况。
九、总结
通过阅读《阿里云ClickHouse企业版技术白皮书 》,我了解了企业版的技术架构和实现原理,了解了ClickHouse 企业版 SharedMergeTree 表引擎的机制,丰富了云原生知识。
十、附录
阿里云
网络
ClickHouse官方
https://zhuanlan.zhihu.com/p/621480049
https://zhuanlan.zhihu.com/p/361622782