目录
博客主页:専心_前端,javascript,mysql-CSDN博客
系列专栏:vue3+nodejs 实战--文件上传
前端代码仓库:jiangjunjie666/my-upload: vue3+nodejs 上传文件的项目,用于学习 (github.com)
后端代码仓库:jiangjunjie666/my-upload-server: nodejs上传文件的后端 (github.com)
欢迎关注
在上一篇中我们实现了文件的拖拽上传,Vue3 + Nodejs 实战 ,文件上传项目--实现拖拽上传-CSDN博客
该篇就讲讲大文件上传的需求场景
1.大文件上传的场景
如果遇到需要上传电影或者视频之类的需求,那么上传的文件是非常大的,这个时候我们不能说用一个请求就直接将所有的文件传输过去,因为这个大文件上传时间相比较来说是比较长的,存在很多的弊端,假如用户刷新了页面之类的情况,这时候上传又需要重头开始上传,这对用户以及服务器都是不妥的。
需要解决的基本问题(其他的扩展根据需求来定)
- 对大文件进行分片上传
- 上传的实时进度显示
- 上传中断后再次上传跳过已经上传的部分
2.前端实现
2.1 对文件进行分片
对文件进行分片我们用到的是 file.slice(i,j) 这个方法
其中的参数代表的意思就是切割的大小,以size单位的,i-j 就是切这一段的数据
<template>
<input type="file" @change="fileChange" />
</template>
<scritp>
import { ref } from 'vue'
const fileList = ref([])
const file = ref([])
const fileChange = (e) => {
console.log(e.target.files[0])
//分片
file.value = e.target.files[0]
for (let i = 0; i < file.value.size; i += 1024 * 1024) {
fileList.value.push(file.value.slice(i, i + 1024 * 1024))
}
}
</script>这样就将文件切成了每个大小为 1024 * 1024 的大小的文件,也就是1mb
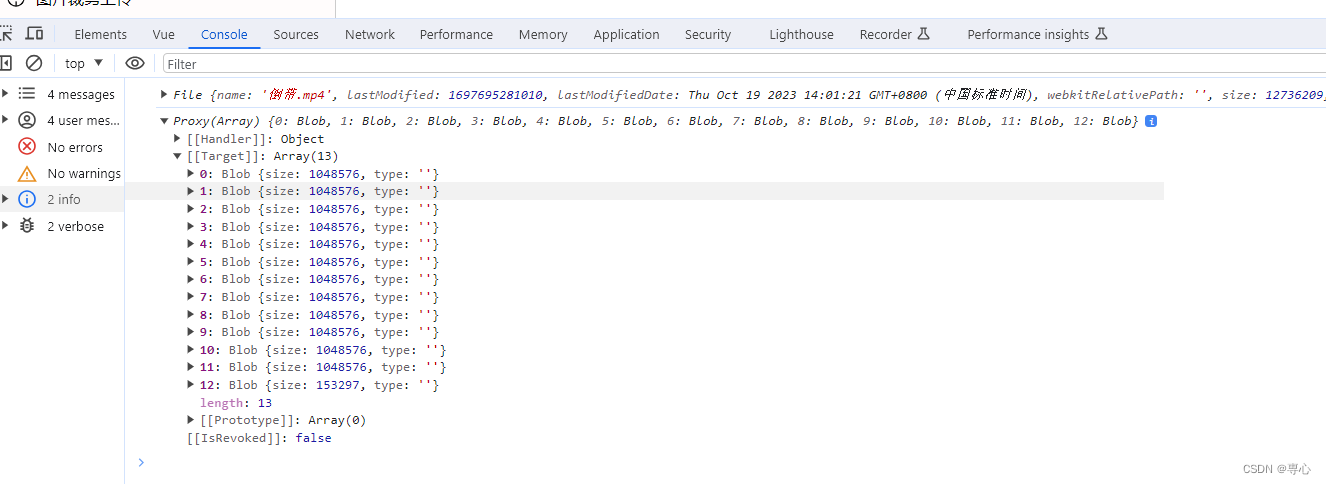
2.2 生成hash值(唯一标识)
因为我们进行分片后的文件数据并不能单独成为一个原本的文件,一般都是二进制数据,我们在分片上传的时候需要临时存储已经上传的文件,这时候为了能对应到每个文件,需要对每个文件生成对应的文件hash值,这里需要用到hash算法,项目中大家可以直接使用spark-md5这个库生成文件hash。
总之文件hash的作用就是生成唯一的标识,该算法生成的hash值永远不会出现重复 ,但是同一文件多次生成的都是一样的。
安装 spark-md5
npm i spark-md5引入生成hash
import SparkMD5 from 'spark-md5'
const fileMd5 = ref('')
const hash = new SparkMD5.ArrayBuffer() // 构建hash值对象
const fileReader = new FileReader()
fileReader.onload = () => {
hash.append(fileReader.result)
fileMd5.value = hash.end()
}
fileReader.readAsArrayBuffer(file.value)2.3 发送上传文件请求
大文件分片上传一般都是二个请求,一个是分片上传的请求,一个是分片上传完之后的合并请求。
分片上传:
const upload = async (index) => {
if (index == fileList.value.length) {
mergeUpload()
return
}
const formData = new FormData()
formData.append('chunk', fileList.value[index])
formData.append('index', index)
formData.append('name', fileMd5.value + '@' + index) // 临时的二进制文件分片
formData.append('filename', fileMd5.value) // 文件名,采用hash
let res = await http.post('/api/upload_chunk1', formData)
if(res.code == 200){
upload(index+1)
}else{
upload(index) // 失败重新上传
}
}合并分片:
const mergeUpload = async () => {
//合并请求
let res = await http.post('/api/merge_chunk', {
filename: fileMd5.value, //最后合并的文件名
extname: file.value.type.split('/').pop() //文件后缀
})
if ((res.code = 200)) {
file.value = null
fileList.value = []
fileMd5.value = ''
ElMessage({
type: 'success',
message: '上传成功'
})
}
}3.后端实现
我这边使用的是 multiparty 中间件完成的该需求,可以安装一下
npm i multiparty如果没有看过建的项目,可以看看第一期喔:Vue3 + Nodejs 实战 ,文件上传项目--实现图片上传-CSDN博客
3.1 接收分片数据临时存储
首先要做的就是利用请求中携带的数据进行创建一个临时保存分片数据的目录,目录名可以使用hash值,这样可以做到唯一性,并且后面实现断点续传也能更方便。
分片上传的数据会被临时保存在 Temp 文件夹中,如果windows电脑的话,可以 win + R ,输入 %temp% 就能进入该目录,里面保存的都是临时文件。我的做法就是将这个的文件copy一份到对应的目录下,然后删除临时文件。
const multiparty = require('multiparty')
const path = require('path')
const fs = require('fs')
exports.upload_chunk1 = (req, res, next) => {
// 二进制数据上传
const form = new multiparty.Form()
form.parse(req, (err, fields, files) => {
if (err) {
next(err)
return
}
//将每一次上传的数据进行统一的存储
const oldName = files.chunk[0].path
const newName = path.join(__dirname, '../../public/upload/chunk/' + fields['filename'][0] + '/' + fields['name'][0])
//创建临时存储目录
fs.mkdirSync('./public/upload/chunk/' + fields['filename'][0], {
recursive: true
})
console.log(fields)
console.log(files)
fs.copyFile(oldName, newName, (err) => {
if (err) {
console.error(err)
} else {
// 删除源文件
fs.unlink(oldName, (err) => {
if (err) {
console.error(err)
} else {
console.log('文件复制和删除成功')
}
})
}
})
res.send({
code: 200,
msg: '分片上传成功'
})
})
}
这是刚刚上传的一批二进制文件

3.2 合并分片
合并接口:
exports.merge_chunk = (req, res, next) => {
const fields = req.body
console.log(fields)
thunkStreamMerge('../../public/upload/chunk/' + fields.filename, '../../public/upload/' + fields.filename + '.' + fields.extname)
res.send({
code: 200,
data: '/public/upload/' + fields.filename + '.' + fields.extname
})
}
编写一个thunkStreamMerge 函数用来合并分块文件。它接收两参数:源文件目录 sourceFiles 和目标文件路径 targetFile。利用 fs.readdirSync 读取源文件目录下的文件列表,并根据文件名中的序号排序,以确保按正确的顺序合并文件。接着创建一个可写流 (fileWriteStream),用于将所有分块文件的内容写入到目标文件中。这个目标文件路径是由 targetFile 指定的。
// 文件合并
function thunkStreamMerge(sourceFiles, targetFile) {
const chunkFilesDir = path.join(__dirname, sourceFiles)
const chunkTargetDir = path.join(__dirname, targetFile)
const list = fs.readdirSync(chunkFilesDir) //读取目录中的文件
const fileList = list
.sort((a, b) => a.split('@')[1] * 1 - b.split('@')[1] * 1)
.map((name) => ({
name,
filePath: path.resolve(chunkFilesDir, name)
}))
const fileWriteStream = fs.createWriteStream(chunkTargetDir)
thunkStreamMergeProgress(fileList, fileWriteStream, chunkFilesDir)
}thunkStreamMergeProgress 函数是用来处理每个分块文件的函数。它接收三个参数:fileList,包含了分块文件信息的数组;fileWriteStream,目标文件的可写流;以及可选的 sourceFiles,用于删除临时文件目录。
首先,函数检查 fileList 是否为空,如果为空,表示所有分块文件已经合并完成。此时,它向目标文件写入一个标识('完成了'),并根据需要删除源文件目录 sourceFiles。
如果 fileList 不为空,函数会从中取出第一个文件信息,并获取其文件路径。然后,它创建一个可读流 (currentReadStream) 来读取该分块文件的内容。
接下来,函数使用 .pipe 方法将当前可读流的内容传输到目标文件的可写流中,这将逐步将分块文件的内容写入目标文件。
当当前可读流读取完毕(end 事件触发)后,它递归调用 thunkStreamMergeProgress 函数,处理下一个分块文件,直到所有分块文件都合并到了目标文件中。
//合并每一个分片
function thunkStreamMergeProgress(fileList, fileWriteStream, sourceFiles) {
if (!fileList.length) {
// thunkStreamMergeProgress(fileList)
fileWriteStream.end('完成了')
// 删除临时目录
if (sourceFiles) fs.rmdirSync(sourceFiles, { recursive: true, force: true })
return
}
const data = fileList.shift() // 取第一个数据
const { filePath: chunkFilePath } = data
const currentReadStream = fs.createReadStream(chunkFilePath) // 读取文件
// 把结果往最终的生成文件上进行拼接
currentReadStream.pipe(fileWriteStream, { end: false })
currentReadStream.on('end', () => {
// console.log(chunkFilePath);
// 拼接完之后进入下一次循环
thunkStreamMergeProgress(fileList, fileWriteStream, sourceFiles)
})
}
这样做完后就能实现基本的文件分片上传以及合并分片了
这是上传的一个视频
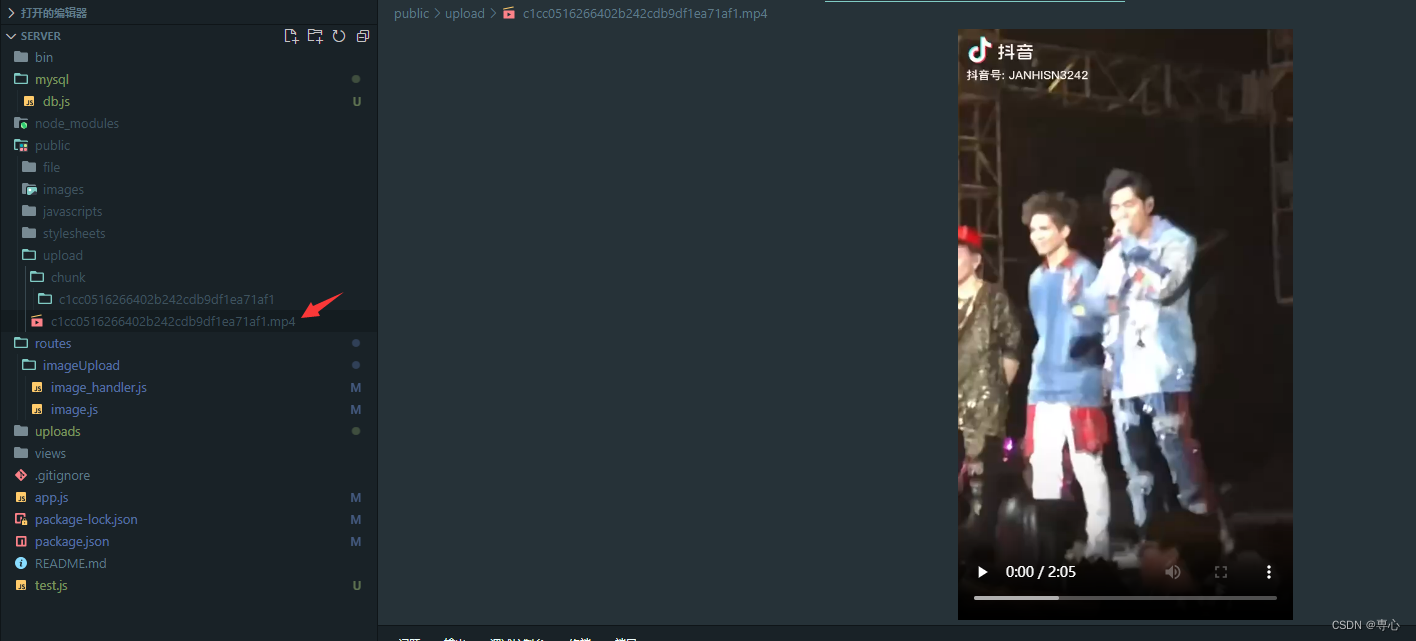
4.完成段点续传
4.1修改后端
断点续传的情况就是文件上传至一半时突然做了其他的交互让上传停止了,那么下次再上传时就需要重新开始从头上传,这样非常消耗时间,对用户的体验与服务器的维护都不友好,这时候就要判断是否有对应的文件数据,直接将对应的索引传给客户端,客户端直接从该分片开始传输即可,因为我们之前给每个临时文件都加了 hash+@+index,我们可以读取文件夹目录查找最后的index传输给客户端即可。
当然这种解决方法是因为我没有采用数据库的情况,如果采用数据库或者其他的需求,基本的实现思路都差不多,利用唯一值 hash 进行传输。
后端接口加上一个判断,是否为段点传输
exports.upload_chunk1 = (req, res, next) => {
// 二进制数据上传
const form = new multiparty.Form()
form.parse(req, (err, fields, files) => {
if (err) {
next(err)
return
}
let pa = path.join(__dirname, '../../public/upload/chunk/' + fields['filename'][0])
console.log(pa)
//判断是否为断点续传
if (fs.existsSync(pa) && parseInt(fields.index[0]) === 0) {
//存在该目录
//返回最大的索引
let maxIndex = 0
let arr = fs.readdirSync(pa)
for (let i = 0; i < arr.length; i++) {
let str = parseInt(arr[i].split('@')[1])
console.log(str)
if (str > maxIndex) {
maxIndex = str
}
}
res.send({
code: 300,
msg: '存在该目录,请继续上传',
index: maxIndex
})
} else {
//将每一次上传的数据进行统一的存储
const oldName = files.chunk[0].path
const newName = path.join(__dirname, '../../public/upload/chunk/' + fields['filename'][0] + '/' + fields['name'][0])
//创建临时存储目录
fs.mkdirSync('./public/upload/chunk/' + fields['filename'][0], {
recursive: true
})
console.log(fields)
console.log(files)
fs.copyFile(oldName, newName, (err) => {
if (err) {
console.error(err)
} else {
// 删除源文件
fs.unlink(oldName, (err) => {
if (err) {
console.error(err)
} else {
console.log('文件复制和删除成功')
}
})
}
})
res.send({
code: 200,
msg: '分片上传成功'
})
}
})
}4.2 修改前端
前端加上进度条,发送请求时对相应的数据进行判断即可完成此需求了
分片请求,合并请求不变
const upload = async (index) => {
if (index == fileList.value.length) {
mergeUpload()
return
}
const formData = new FormData()
formData.append('chunk', fileList.value[index])
formData.append('index', index)
formData.append('name', fileMd5.value + '@' + index) // 名字
formData.append('filename', fileMd5.value) // 文件名
let res = await http.post('/api/upload_chunk1', formData)
console.log(res)
if (res.code == 300) {
//证明已经存在部分文件
percentage.value = ((res.index / fileList.value.length) * 100).toFixed(2)
upload(res.index + 1)
} else if (res.code == 200) {
percentage.value = (((index + 1) / fileList.value.length) * 100).toFixed(2)
upload(index + 1)
} else {
upload(index)
}
}加上进度条
<template>
<div>
<input type="file" @change="fileChange" />
<div class="progress">
<el-progress :text-inside="true" :stroke-width="24" :percentage="percentage" status="success" />
</div>
</div>
</template>
<script>
let percentage = ref(0)
</script>5.测试
我这里选择一个 624Mb的视频
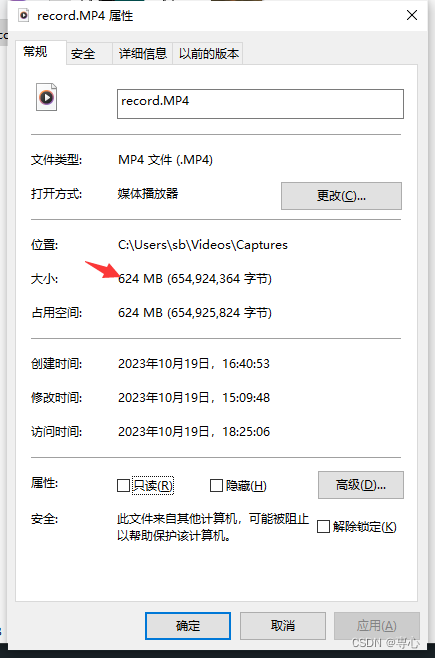
我在上传进度到一半时刷新了页面

分片文件也只有450个

这时候重新选择该视频重新上传
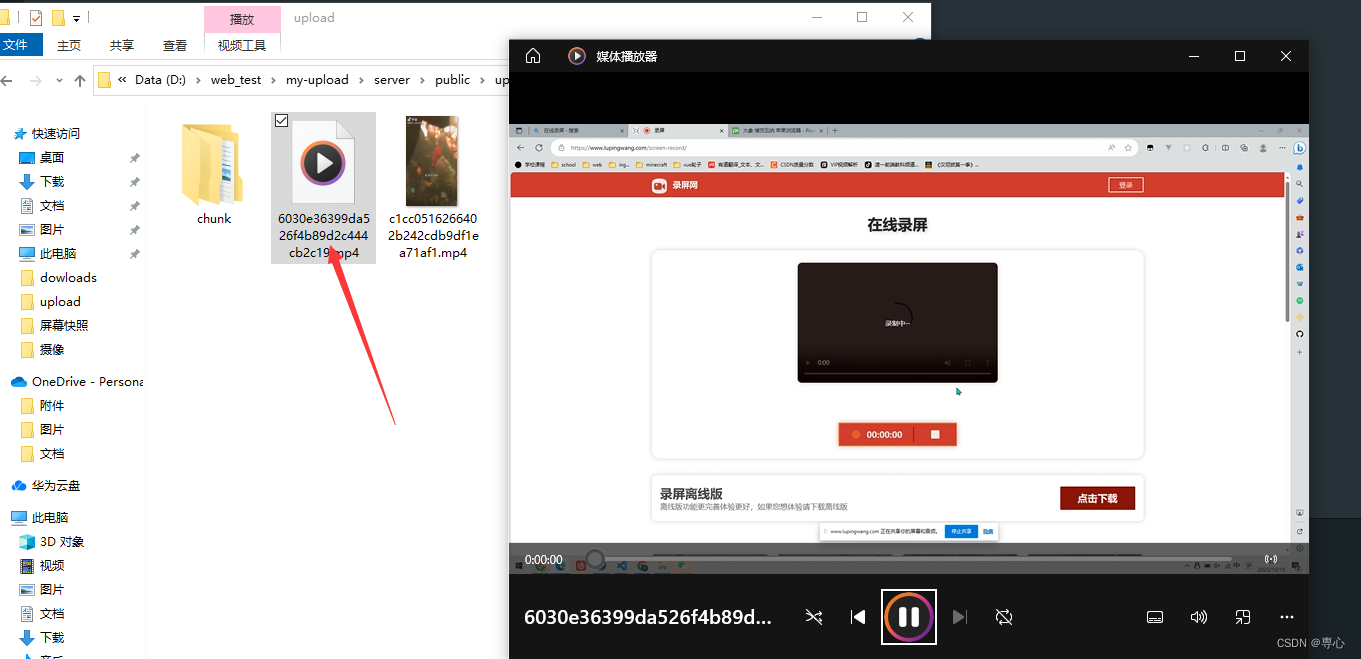
这时候进度条很快就能到对应的进度

后端也没有上传多余的文件,直接接着传输,速度很快就传输完并且合并成了视频
到这基本的分片传输 + 断点续传就实现了,可能还存在者一些小问题,这个大家再项目中根据需求来做相应的改变。
具体的详细代码请大家到仓库下载,或者可以去我的主页资源中下载源码。