
本文整理自阿里云智能开源表存储负责人,Founder of Paimon,Flink PMC 成员李劲松在云栖大会开源大数据专场的分享。本篇内容主要分为四部分:
- 数据分析架构演进
- 介绍 Apache Paimon
- Flink + Paimon 流式湖仓
- 流式湖仓Demo演示
数据分析架构演进
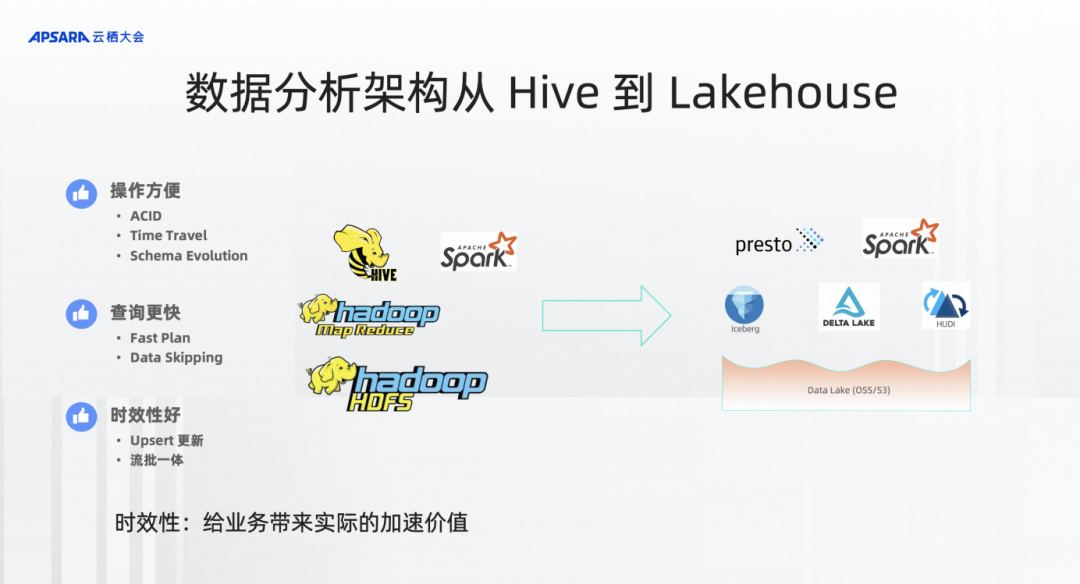
目前,数据分析架构正在从Hive到Lakehouse的演变。传统数仓包括Hive、Hadoop正在往湖、Lakehouse 架构上演进,Lakehouse 架构包括Presto、Spark、OSS,湖格式 (Delta、Hudi、Iceberg) 等等架构,这是现在比较大的趋势。Lakehouse 架构包含了诸多新能力。
首先OSS比起传统的HDFS有了更加弹性、更加计算存储分离的能力。而且OSS还有热冷存储分离能力,数据可以归档到冷存,你会发现它的冷存储非常便宜,给了你存储的灵活性。
再往上会发现这些湖格式有着一些好处。具体是哪些好处呢?
第一点操作方便,湖格式有ACID、Time Travel、Schema Evolution,这些可以让你有更好的管控能力。
第二个可能查询更快,比如说plan阶段会耗时更短,Hive在超大数据量、超多文件的时候会有一些查询的问题。所以湖格式在这方面也会解决得更好。
上面的两个好处不一定能打动公司的决策人,其实也不是每家公司都在升级或者都已经升级,其中一个大的原因就是大家虽然说Hive老了,但它还是能再战一战的,因为前面这两个好处不一定对于每家公司都是刚需。大量的公司都还是继续用Hive,也许底下的存储换成OSS (或者OSS-HDFS) ,但还是老的Hive那套。
举例来说,现在已经有了运行稳定的火车,现在可以把它升级一下,增加餐车,装潢一遍,切分成更多节更灵活,但是需要升级为新的一套架构,你愿意冒着风险升级吗?但是如果能升级成高铁动车呢?
所以我要介绍左边第三个好处。Lakehouse可以做到时效性更好。
时效性更好不一定是所有业务都需要更好的时效性,都要从天到达分钟级,而是你可以选择其中某些数据进行实时化升级,还可以选择某些时间进行实时化,主流数据仍然是离线状态。
时效性更好可能会给你的一些业务带来真正的改变,甚至说对于你的架构能带来大幅的简化,让整个数仓更稳定。

时效性在计算领域的领头羊是Apache Flink。刚才说提升时效性是Lakehouse下一步的发展重点,现在要做的就是把Streaming计算标准技术也就是Apache Flink带到Lakehouse架构当中。
所以前几年我们也做有很多相关的探索,包括在Iceberg和Hudi上的投入,都成功地把Flink和Iceberg的对接、和Hudi的对接打磨出来。但是可能打磨得效果也没有那么好,如果大家用过Flink + Iceberg或者Flink + Hudi可能也有一些吐槽。关键问题在于,Iceberg 和 Hudi 都是面向 Spark、面向离线而生的数据湖技术,与实时和 Flink 有着不太好的匹配。
所以我们研发了新型数据湖格式 Apache Paimon,它是一个流式数据湖格式。我们分析一下数据湖四剑客有什么样的历史和初衷。

Apache Iceberg 和 Delta Lake,他们其实是对传统Hive格式的一种升级。本质上还是面向Append数据的处理,在离线数仓T+1的分析上比起Hive更有优势和更方便的使用,更多还是面向传统的离线处理。
Apache Hudi其实是在Hive的基础上提供增量更新的能力,这是它的初衷。它的基础架构还是面向全增量合并的方式,Flink 的集成不如 Spark,一些功能只在Spark有,Flink没有。
Apache Paimon是从Flink社区中孵化出来的,面向流设计的数据湖,目的就是支持大规模更新和真正的流读。
流和湖的结合难点其实在更新。如果大家对Flink比较熟悉,Flink SQL 成功的原因之一是它真正对Changelog做出了原生的处理,这个changelog本身就是一种更新。
Iceberg、Hudi、Delta是因为他们都是面向批处理、Spark的增量 + 全量的方式。一旦需要涉及到合并就是增量数据和全量数据的一次超大合并。相当有全量10 TB,增量哪怕1 GB也可能会涉及到所有文件的合并,这10个TB的数据要全部重写一次,然后合并才算完成,合并的代价非常大。
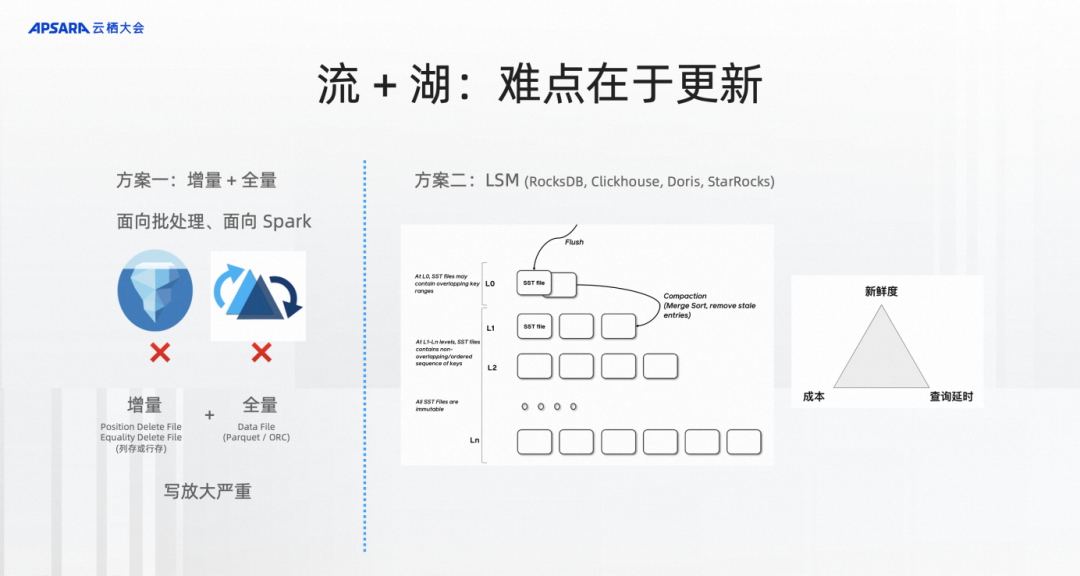 右边是面向更新的技术,LSM,全名是Log Structured Merge-Tree,这种格式在实时领域已经被大量的各种数据库应用起来,包括 RocksDB、Clickhouse、Doris、StarRocks 等等。
右边是面向更新的技术,LSM,全名是Log Structured Merge-Tree,这种格式在实时领域已经被大量的各种数据库应用起来,包括 RocksDB、Clickhouse、Doris、StarRocks 等等。
LSM带来的变化是每次合并都可能是局部的。每次合并只用按照一定的策略来merge数据即可,这种格式能真正在成本、新鲜度和查询延时的三角trade-off中可以做到更强,而且在三角当中可以根据不同的参数做不一样的trade-off的选择。
介绍 Apache Paimon
我们刚刚介绍了演进的过程,需要Flink + 湖存储来做Flink Lakehouse,也介绍了难点。第二部分就介绍一下Apache Paimon。

Apache Paimon是什么样的东西?你可以简单认为基础的架构就是湖存储+ LSM的结合,对于湖存储来说基本的能力是写和读。Apache Paimon在这个基础上和Flink做了更深度的集成,各种 CDC 数据可以通过Flink CDC做到 Schema Evolution 和整库同步地把数据同步到Paimon中。
也可以通过Flink、Spark、Hive、宽表合并的方式或者通过批写覆盖的方式写到Paimon中,这是基本的 Lakehouse能力。也可以在后面批读,通过Flink、Spark、StrarRocks、Trino做一些分析,也可以这里通过Flink来流读Paimon里面的数据,流读生成的 Changelog,流读方面的特性,后面我也会介绍。

这是Paimon的架构图,这主要是Paimon流式一体实时数据湖大致的发展历程。最开始在2022年初发现了开源社区技术上的一块缺失,所以在Flink社区提出了Flink Table Store。直到2023年1月发布了第一个稳定的版本0.3,3月份进入Apache孵化器。今年9月份发布了Paimon 0.5版本,这是Paimon全面成熟的版本,包括CDC入湖和Append数据处理。
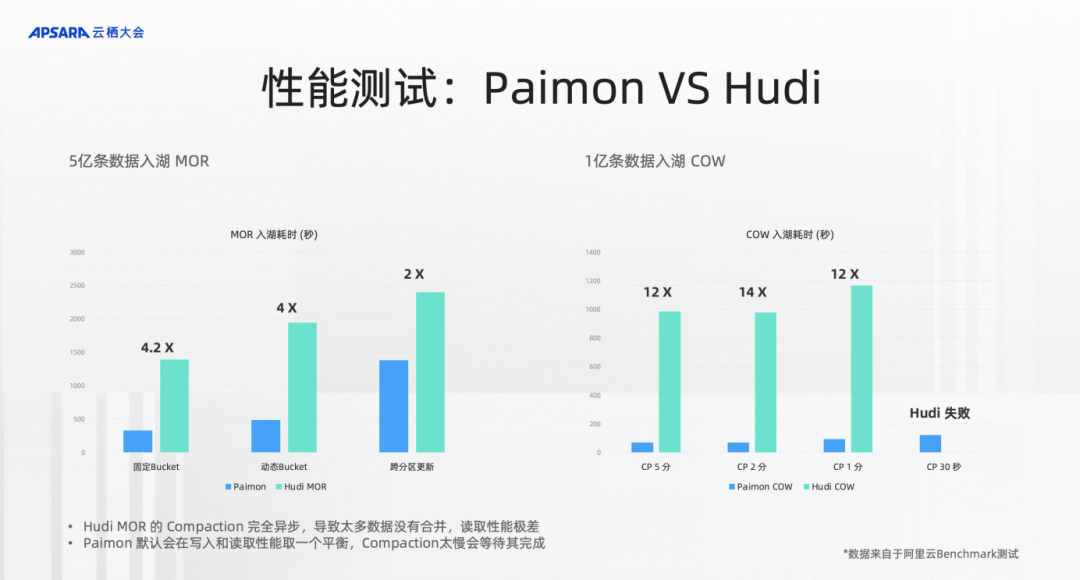
我们也在阿里云上测试Apache Paimon和Hudi的性能,测试湖存储的 MergeOnRead 的更新性能,可以看到左边是大致是5亿条数据入湖,按照类似的配置、相同的索引来入湖,我们来评估5亿条入湖需要多少时间。经过测试发现Paimon入湖的过程中,吞吐或者耗时能达到Hudi的4倍,但是查询相同的数据,发现Paimon的查询性能是Hudi的10倍甚至20倍,Hudi 还会碰到因内存变小而无法读取的情况。
为什么呢?我们分析到,Hudi MOR是纯Append,虽然后台有compaction,但是完全不等Compaction。所以在测试中Hudi的Compaction只做了一点点,读取的时候性能特别差。
基于这点,我们也做了右边的benchmark,就是1亿条数据的CopyOnWrite,来测试合并性能,测试CopyOnWrite情况下的 compaction 性能。测试的结果是发现不管是2分钟、1分钟还是30秒,Paimon性能都是大幅领先的,是12倍的性能差距。在30秒的时候,Hudi跑不出来,Paimon还是能比较正常地跑出来。

所以回过头来,我希望通过这三句话的关键词来描述Paimon能做到什么。
第一,低延时、低成本的流式数据湖。如果你有用过Hudi,我们希望你替换到Paimon之后以1/3的资源来运行它。
第二,使用简单、入湖简单、开发效率高。可以轻松地把数据库的数据以CDC的方式同步到数据湖Paimon中。
与Flink集成强大,数据流起来。
Flink + Paimon 流式湖仓
第一部分讲了数据架构演进,就是我们为什么要做Paimon,第二部分介绍Paimon能干什么,有哪些集成、优势,性能上表现如何。接下来第三部分就是Flink + Paimon怎么构建流式湖仓。
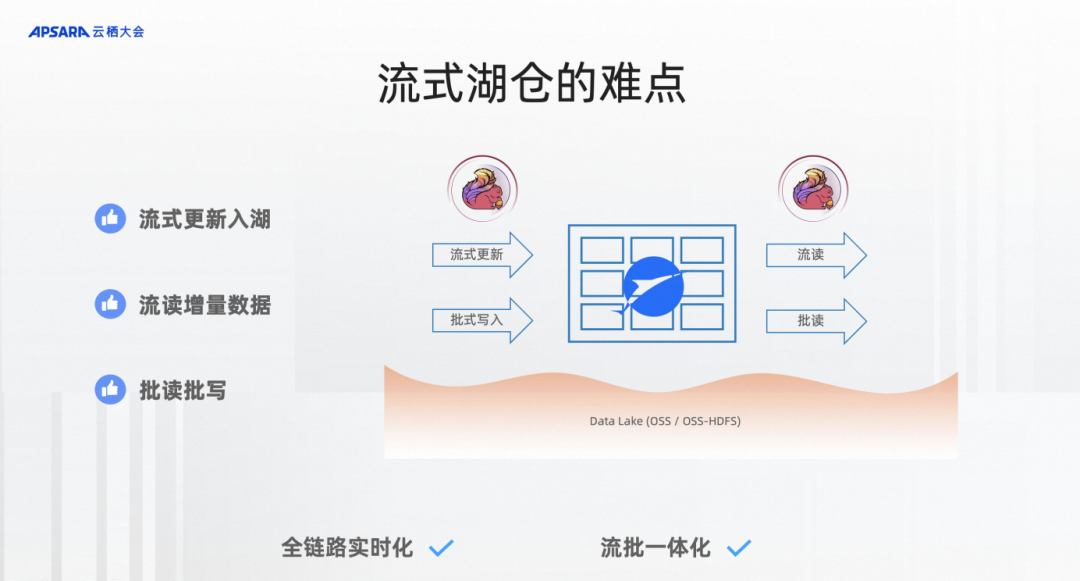
首先我们看一个大致的图,其实流式湖仓本质还是一个湖仓,湖仓能干什么?最基本的就是批写、批读,能比起传统的Hive数仓有更好的优势。在这个基础上要提供一个强大的流式数据更新入湖以及流式数据增量数据的流读,达到全链路的实时化、流批一体化,难点就是流式更新和流读。

一个最典型的流式湖仓能解决的场景,Hive上CDC数据,也就是从MySQL、传统数据库的数据、CDC数据能流到仓或者湖中的链路。这是一个比较陈旧,但是也是大量在企业中被应用的架构图。
你可能在第一次运行的时候或者按需通过全量同步的方式同步到Hive全量分区表中,成为一个分区。接下来每天要通过增量同步的方式同步到kafka中,通过定时回流的方式把增量的CDC数据同步成Hive中的一个增量表。每天晚上同步完后,大概0点10分的时候就可以做一个增量表和全量表的合并,合并之后形成新的分区就是MySQL新一天的全量。
通过这样的技术可以看到它的产出时延是非常高的,至少需要T+1,并且还要等增量数据和全量数据合并。而且全量增量是割裂的,存储也非常浪费。你可以看到Hive全量表每个分区就是一个全量的数据,你要存100天的数据就至少是100倍的存储。
第三也是链路非常长,非常复杂,涉及到各种各样好几个技术,在真实的业务场景中非常容易遇到的就是这个产出,哪个组件有问题,数据产出不了,导致后面一系列的离线作业跑不了。所以这里描述的就是三高,时延高、成本高、链路复杂度高。
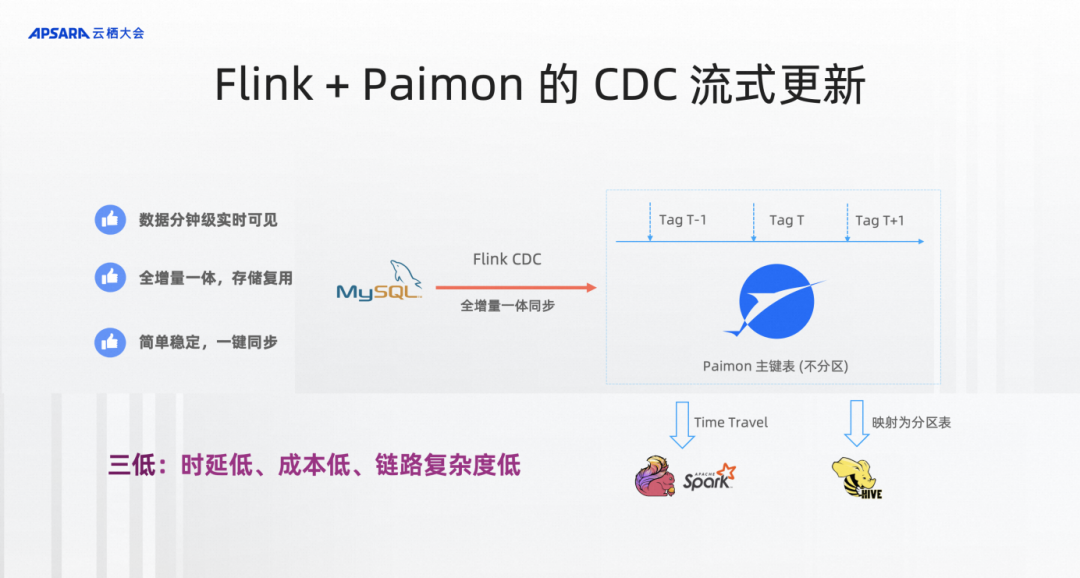
切到Flink+Paimon的流式CDC更新,我们希望把架构做得非常简单,不用Hive的分区表,只要定义Paimon的主键表,不分区。它的定义就非常像MySQL表的定义。
通过Flink CDC、Flink作业把CDC数据全增量一体到Paimon中就够了,就可以实时看到这张表的状态,并且实时地查到这张表。数据被实时的同步,但是离线数仓是需要每天的view,Paimon要提供Tag技术。今天打了一个Tag就记住了今天的状态,每次读到这个Tag都是相同的数据,这个状态是不可变的。所以通过Tag技术能等同取代Hive全量表分区的作用,Flink、Spark可以通过Time Travel的语法访问到Tag的数据。
传统的Hive表那是分区表,Hive SQL也没有Time Travel的语义,怎么办?在Paimon中也提供了Tag映射成Hive分区表的能力,还是可以在Hive SQL中通过分区查询,查询多天的数据。Hive SQL是完全兼容一行不改的状态来查询到Paimon的组件表,所以经过这样的架构改造之后,你可以看到整个数据分钟级实时可见,各整个全增量一体化,存储是复用,比较简单稳定而且一键同步,这里不管是存储成本还是计算成本都可以大幅降低。
存储成本通过Paimon的文件复用机制,你会发现打十天的Tag其实存储成本只有一两天的全量成本,所以保留100天的分区,最后存储成本可以达到50倍的节省。
在计算成本上虽然需要维护24小时都在跑的流作业,但是你可以通过Paimon的异步compaction的方式,尽可能地缩小同步的资源消耗,甚至Paimon也提供整库同步的类似功能给到你,可以通过一个作业同步上百张或者几百张表。所以整个链路能做到三低:时延低、成本低和链路复杂度低。
接下来介绍两个流读。大家可能觉得Paimon是为实时而生的,更好地流读,其实没有什么实感。包括Hudi、Iceberg也能流读,我在这里通过两个机制来说明Paimon在数据流读上做了大量的工作。
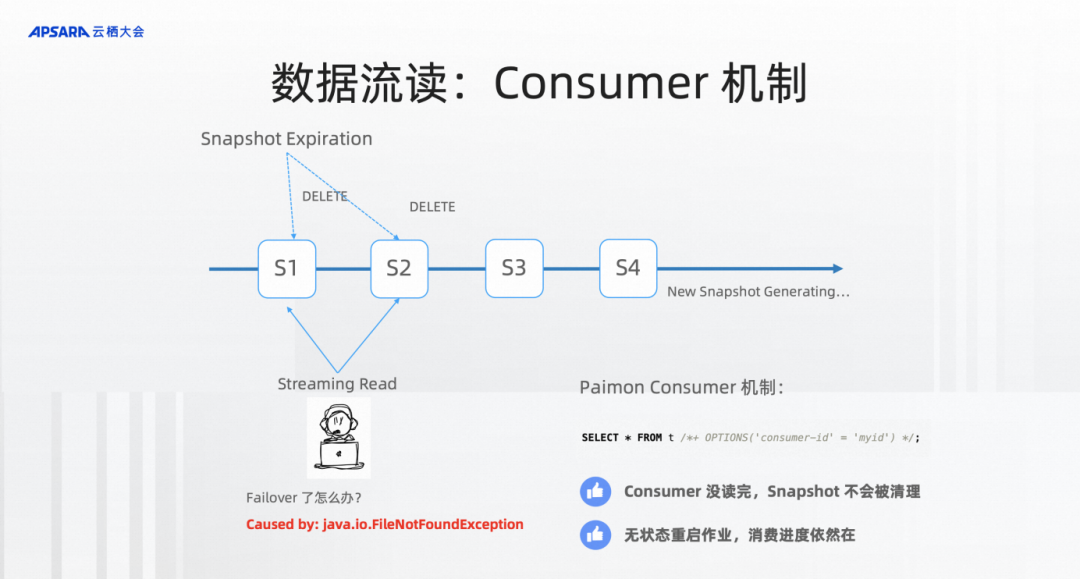
Consumer机制。如果没有这个能力,经常流读的时候碰到非常头疼的东西就是FileNotFoundException,这个机制是什么样的呢?因为我们在数据产出过程当中,需要不断地产生Snapshot。太多的Snapshot会导致大量的文件、导致数据存储非常地冗余,所以需要有Snapshot的清理机制。但是另外流读的作业可不知道这些,万一我正在流读的Snapshot被Snapshot Expiration给删了,那不就会出现FileNotFoundException,怎么办?而且更为严重的是,流读作业可能会failover,万一它挂了2个小时,重新恢复后,它正在流读的 snapshot 已经被删除了,再也恢复不了。
所以Paimon在这里提出了consumer机制。consumer机制就是在Paimon里用了这个机制之后,会在文件系统中记一个进度,当我再读这个Snapshot,Expiration就不会删这个Snapshot,它能保证这个流读的安全,也能做到像类似 kafka group id 流读进度的保存。重启一个作业无状态恢复还是这个进度。所以consumer机制可以说是流读的基本机制。
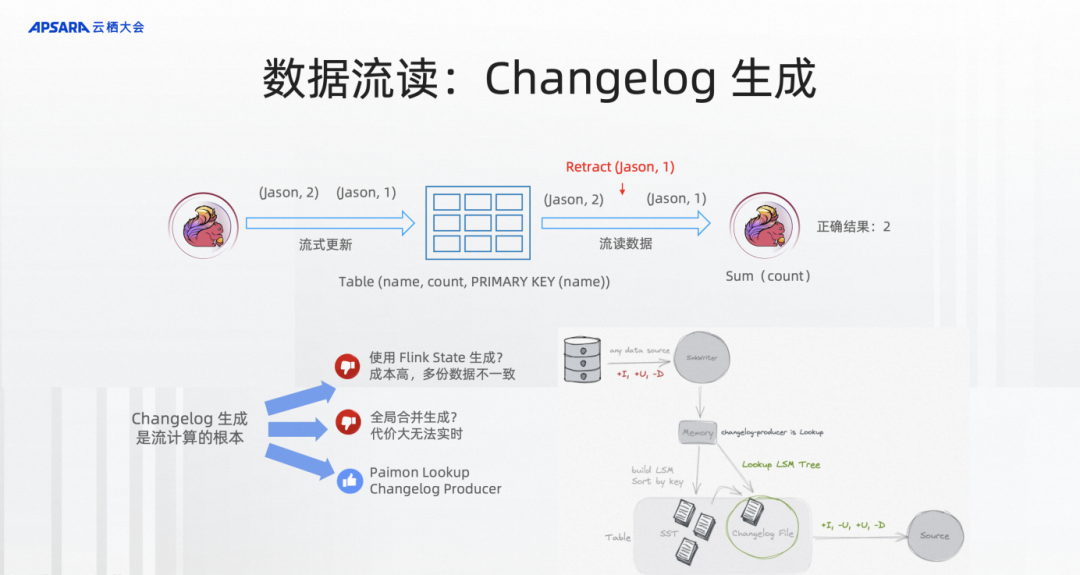
第二,Changelog生成。假设有这样一张Paimon的PK表,key是名字,Value是count,上游在不断地流写,下游在不断地流读。流写可能会同一个组件写相同的数据,比如说先前写的jason是1,后面又写一个jason是2。你会发现流读的作业在做一个正确流处理的时候,比如说做一个sum,sum结果应该是2还是3,如果没有这个changelog的生成就不知道这是同一个主键,我要先把jason -> 1给retract掉,再写jason -> 2。所以这里也对我们湖存储本身要表现得像一个数据库生成binlog的方式,下游的流读计算才能更好、更准确。
changelog生成有哪些技术呢?在Flink实时流计算中,大家如果写过作业的话,也可能写过大量用State的方式来去重。但是这样的方式state的成本比较高,而且数据会存储多份,一致性也很难保障。或者你可以通过全量合并的方式,比如说Delta、Hudi、Paimon都提供了这样的方式,可以在全量合并的时候生成对应的changelog,这个可以,但是每次生成changelog都需要全量合并,这个代价也会非常大。
第三,Paimon这边独有的方式,它有chagelog-producer=lookup,因为它是LSM。LSM是有点查的能力,所以你可以配置这样一个点查的方式在写入的时候能通过批量高效率的点查生成对应的chanelog让下游的流处理能够正确地流处理。
上面两个部分就是Paimon的更新和流读。流式湖仓面向流批一体的Flink的流批一体。之前是流批一体的计算,现在有了存储以后是流批一体的计算 + 流批一体的存储。
但是,有同学在用阿里云 Serverless Flink发现没有批的基本能力:调度和工作流?
流式湖仓不仅要解决流的能力,还需要解决批的离线处理能力,批是湖仓的基础,流只是在这个流式湖仓中真正的流可能只有10%、20%,并不是整个湖仓的全部。所以Flink的流批一体离不开Flink的真正批处理。
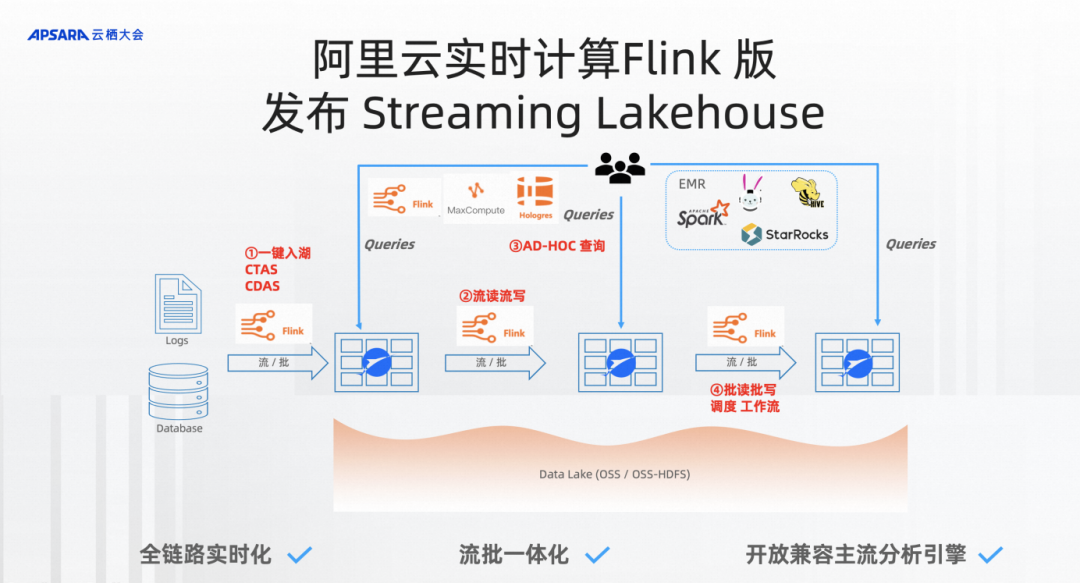
大家也可以看到流式湖仓的图里,可能需要4个步骤来处理数据。
第一步是一键入湖,通过Flink CTAS/CDAS一键入湖。
第二步里面Pipeline全链路实时化是流起来的,所以需要我对存储有流读流写的能力。
第三步就是这些数据全都是可以通过开放分析引擎来分析到数据。
第四步就是湖仓本质的东西批读批写,在产品上需要的东西基本上就是调度、工作流。
大家期待已久,阿里云 Serverless Flink也正式迎来了产品上的调度和工作流的能力,能让你在Serverless Flink达到真正的完整批处理链路的能力。
接下来我就想通过一个准实时流式湖仓的案例,是电商的数据分析。通过Flink实时入湖入到ODS层Paimon表,通过流式流起来流到DWD,再流到DWM,再到DWS,这样一整套完整的流式湖仓。

流式湖仓Demo演示
Demo演示观看地址:
https://yunqi.aliyun.com/2023/subforum/YQ-Club-0044
开源大数据专场回放视频 01:52:42 - 01:59:00 时间段
Serverless Flink不只有流ETL的能力,现在也有一个比较完善的批处理方式,以前可能是流在一个开发平台,批在一个开发平台,非常地割裂,现在能做到的是整个开发平台都可以在Serverless Flink上,整个计算引擎可以是 Flink Unified的,而且底下的存储都是Unified的一套Paimon存储,完成离线处理以及实时处理或者准实时处理的能力,能达到从开发到计算和存储的完整Unified方案。批处理的版本即将发布,大家有需要可以联系我们提前试用。
OpenAI 面向所有用户免费开放 ChatGPT Voice Vite 5 正式发布 运营商神操作:后台断网、停用宽带账号,强迫用户更换光猫 微软开源 Terminal Chat 程序员篡改 ETC 余额,一年私吞 260 余万元 Redis 之父用纯 C 语言代码实现 Telegram Bot 框架 假如你是开源项目维护者,遇到这种回复能忍到哪步? 微软 Copilot Web AI 将于12月1日正式上线,支持中文 OpenAI 前 CEO 和总裁 Sam Altman & Greg Brockman 加入微软 博通宣布成功收购 VMware