
一、问题是怎么发现的
部署chatglm2和llama2到一个4*V100的GPU机器上遇到问题
config.pbtxt
中设置模型分别在指定gpu上部署实例配置不生效
如以下配置为在gpu0上部署本模型,部署count=1个实例,在gpu1上部署本模型,部署count=2个实例
instance_group [ { count: 1 kind: KIND_GPU gpus: [ 0 ] },
{ count: 2
kind: KIND_GPU
gpus: [ 1 ] } ]
部署时发现,所有模型实例都会被部署到gpu0上面, 由于gpu只有16g显存,在部署第一个模型实例成功后,第二个模型实例也会往gpu0上进行加载,最终导致cuda out of memery.
网上搜索发现有人遇到同样的问题,链接: https://github.com/triton-inference-server/server/issues/6124
二、排查问题的详细过程
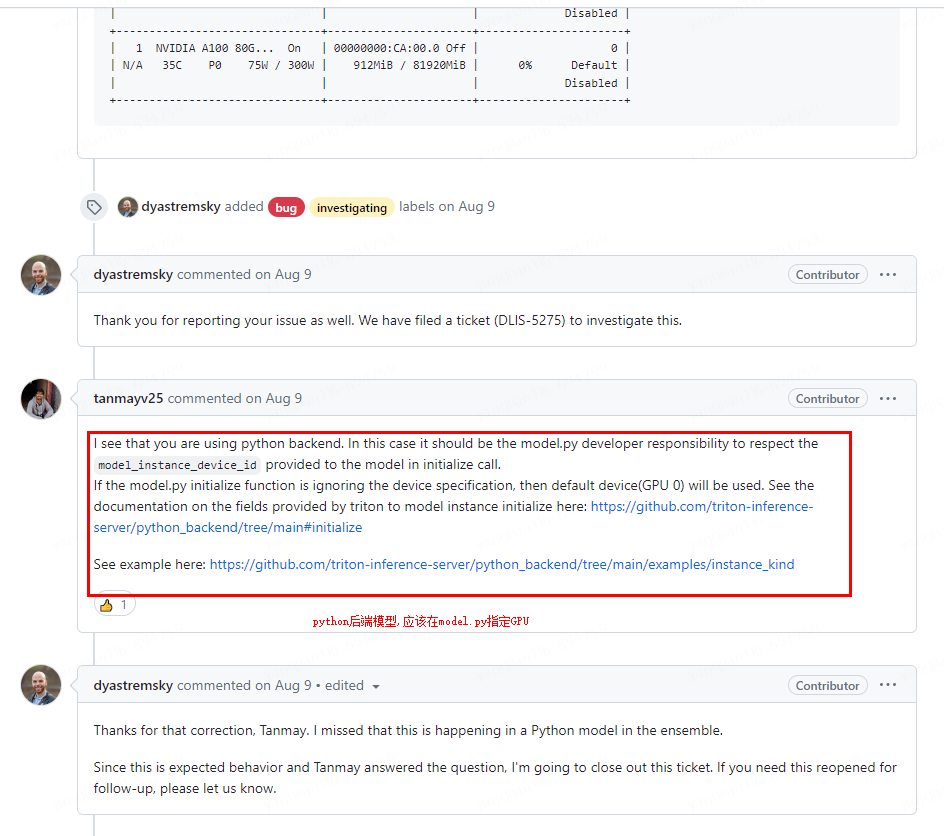
大佬回答解决方案:
三、如何解决问题
1.在model.py手动获取config.pbtxt配置的gpu编号gpus:[0]
instance_group [
{
count: 1
kind: KIND_GPU
gpus: [ 0 ]
}
]
2.设置可用的GPU编号
os.environ["CUDA_VISIBLE_DEVICES"] = str(device_id)
3.启动成功

四、总结反思:是否可以更快发现问题?如何再次避免等。
triton启动的使用使用 nvidia-smi -l 2 监控显卡想显存, 可以发现所有模型都在往第一个gpu,gpu[0]内加载,发现配置config.pbtxt不生效
雷军:小米全新操作系统澎湃 OS 正式版已完成封包 国美 App 抽奖页面弹窗辱骂其创始人 Ubuntu 23.10 正式发布,不妨趁周五升级一波! Ubuntu 23.10 发版插曲:因包含仇恨言论,ISO 镜像被紧急“召回” 23 岁博士生修复 Firefox 中的 22 年“幽灵老 Bug” RustDesk 远程桌面 1.2.3 发布,增强 Wayland 支持 TiDB 7.4 发版:正式兼容 MySQL 8.0 拔出罗技 USB 接收器后,Linux 内核竟然崩溃了 大神用 Scratch 手搓 RISC-V 模拟器,成功运行 Linux 内核 JetBrains 推出 Writerside,创建技术文档的工具作者:京东科技 杨建
来源:京东云开发者社区 转载请注明来源
{{o.name}}
{{m.name}}