你好!这里是风筝的博客,
欢迎和我一起交流。
科大讯飞用到我司的一款芯片做识别笔,叫啥阿尔法蛋,一看就不是啥好蛋。。。。。。。
这客户反馈每次用识别笔去识别文字的时候,启动的时候概率性会卡住大概一秒钟的时间才会有语音响起,很影响用户体验。
时间比较紧急,快要量产了,客户希望我在三天内解决,好家伙,我直接好家伙。
(问题是小半年前解的问题了)然后刚刚某宝看下了,这个词典笔居然卖六百九十九人民币,哇,抢钱啊。
拿到机器,我先使用tinyplay工具进行测试,发现现象正常,没有复现到有这场景,怀疑是不是他们应用这块调用流程有问题(tinyplay的流程可以参考我这篇文章:Tinyplay流程分析),因为客户的应用层代码(算法)是保密的,没有给到我,就现场吭哧吭哧给我大概讲了他们的应用流程。
作为一名合格的驱动工程师,只好发挥我的主观能动性了,先从底层查起吧。因为没有客户环境,客户的固件我也动不了,只好在我们的sdk上编译出内核镜像,只烧写到他们机器的kernel分区替换内核镜像作实验了。
经测试,发现仅每次播音第一段音频开始时有此现象,第二次write数据时就不会。因为每次仅第一段音频会卡住等待一小会,加上具体log抓耗时分析,发现耗时主要在pcm_perpare函数,猜测:
(1)错误关中断造成的
(2)资源互斥,锁互斥造成的
一开始觉得是不是哪里长时间关了中断导致响应不及时造成的延时,所以用trace抓了一下数据,关于trace使用可以参考我这篇文章:使用trace查看函数调用关系|分析Linux性能
mount -t debugfs none /sys/kernel/debug/
cd /sys/kernel/debug/tracing/
echo 0 > tracing_on
echo irqsoff > current_tracer
echo 1 > tracing_on
执行客户程序
echo 0 > tracing_on
查看结果:
# tracer: irqsoff
#
# irqsoff latency trace v1.1.5 on 4.9.191
# --------------------------------------------------------------------
# latency: 628 us, #286/286, CPU#0 | (M:preempt VP:0, KP:0, SP:0 HP:0)
# -----------------
# | task: swapper-0 (uid:0 nice:0 policy:0 rt_prio:0)
# -----------------
# => started at: __irq_svc
# => ended at: __do_softirq
#
#
# _------=> CPU#
# / _-----=> irqs-off
# | / _----=> need-resched
# || / _---=> hardirq/softirq
# ||| / _--=> preempt-depth
# |||| / delay
# cmd pid ||||| time | caller
# \ / ||||| \ | /
<idle>-0 0d..1 1us : __irq_svc
<idle>-0 0d..2 2us : gic_handle_irq <-__irq_svc
<idle>-0 0d..2 5us : __handle_domain_irq <-gic_handle_irq
<idle>-0 0d..2 7us : irq_enter <-__handle_domain_irq
<idle>-0 0d..2 8us : rcu_irq_enter <-irq_enter
<idle>-0 0d..2 11us : __local_bh_disable_ip <-irq_enter
<idle>-0 0d..2 13us : tick_irq_enter <-irq_enter
<idle>-0 0d..2 15us : ktime_get <-tick_irq_enter
<idle>-0 0d..2 17us : arch_counter_read <-ktime_get
<idle>-0 0d..2 19us : arch_counter_read_cc <-arch_counter_read
<idle>-0 0d..2 21us : update_ts_time_stats.constprop.10 <-tick_irq_enter
<idle>-0 0d..2 23us : nr_iowait_cpu <-update_ts_time_stats.constprop.10
<idle>-0 0d..2 25us : tick_do_update_jiffies64 <-tick_irq_enter
<idle>-0 0d..2 27us : preempt_count_add <-tick_do_update_jiffies64
<idle>-0 0d..3 30us : do_timer <-tick_do_update_jiffies64
<idle>-0 0d..3 34us : calc_global_load <-do_timer
//后面无关省略
我一看,最大中断延时才628us,那明显和这个没关系啊。
那么,会不会是之前猜测到第二点原因呢?
trace工具不能很好到抓取锁和资源到竞争关系,这里需要用到perf工具,关于perf之后我再开一篇文章来阐述使用方法吧,这里使用perf工具分析,发现没有发现锁竞争出现忙等待到情况啊~~~
那么问题是出现在哪里呢?只好用老办法了,查看具体是在哪个函数最耗时!!
既然如此到话,prepare下到流程何其多,我们难道要在每个函数下加打印跟踪耗时吗???
如果这样做到话,效率也太低了吧,所幸,trace能用到这一点,在asoc代码里,关键到函数本身已经具备了trace_point了,我们只需开启trace就能用了!!
mount -t debugfs none /sys/kernel/debug/
cd /sys/kernel/debug/tracing/
echo 0 > tracing_on
echo asoc > set_event
echo 1 > tracing_on
执行客户程序
echo 0 > tracing_on
cat trace
查看结果,有重大发现!
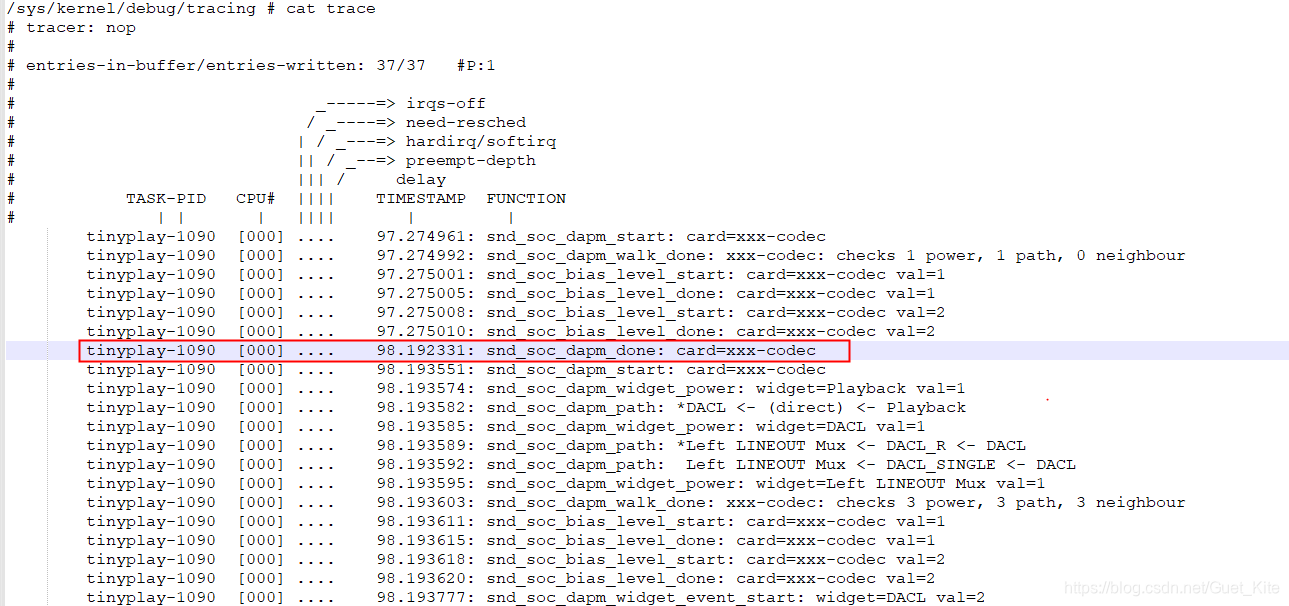
发现snd_soc_dapm_done这里居然耗时了900多ms,很可疑,非常可疑。
PS:trace还是比较好用的,还能看到DAPM里各个widget的连接情况。
查找代码,发现是在sound/soc/soc-dapm.c文件里的dapm_power_widgets函数里,这个函数比较重要,主要是扫描dapm链路上widget的path完整性,以便及时给widget上下电。
进一步加打印抓取时间,发现耗时主要在这个函数片段:
/*
* Scan each dapm widget for complete audio path.
* A complete path is a route that has valid endpoints i.e.:-
*
* o DAC to output pin.
* o Input pin to ADC.
* o Input pin to Output pin (bypass, sidetone)
* o DAC to ADC (loopback).
*/
static int dapm_power_widgets(struct snd_soc_card *card, int event)
{
//......
/* Run other bias changes in parallel */
list_for_each_entry(d, &card->dapm_list, list) {
if (d != &card->dapm)
async_schedule_domain(dapm_pre_sequence_async, d,
&async_domain);
}
async_synchronize_full_domain(&async_domain);
//......
trace_snd_soc_dapm_done(card);
return 0;
}
从注释就可以看出,这里会遍历audio 路由patch里的dapm widget,设置bias_level。耗时主要在async_synchronize_full_domain函数,这里就是等待async_schedule_domain函数里的回调执行完毕。
猜测是在系统负载比较重的时候,任务不能及时调度,造成了延时,所以async_synchronize_full_domain函数才会阻塞等待好几百ms。
通过top命令也证实,在跑这个客户的应用时,CPU负载一度达到了70+%。
通过git log命令查看历史提交记录,发现这段代码在2011年由Mark Brown修改,啊,是大佬,不好意思,打扰了。。。。。。
大佬的补丁修改如下:
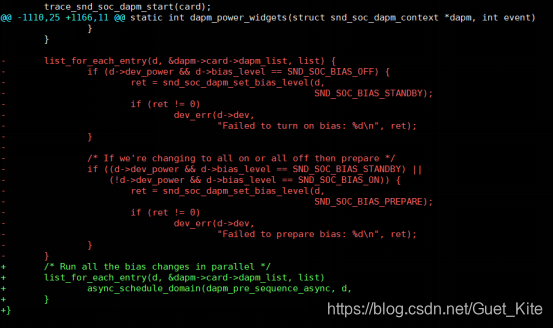
将之前的一些bias_level操作放到线程里面调度执行。
唉,但是我们现在这芯片是单核的啊,系统负载重时,work线程优先级低可不就卡在这里了嘛,没办法,只要做下小兼容了,在单核系统上就不要放到线程里了吧~
最后问题顺利解决。
最后补丁如下:
diff --git a/sound/soc/soc-dapm.c b/sound/soc/soc-dapm.c
index 0b5d132..ab57e90 100644
--- a/sound/soc/soc-dapm.c
+++ b/sound/soc/soc-dapm.c
@@ -1902,11 +1902,15 @@ static int dapm_power_widgets(struct snd_soc_card *card, int event)
/* Run other bias changes in parallel */
list_for_each_entry(d, &card->dapm_list, list) {
if (d != &card->dapm)
+#ifdef CONFIG_SMP
async_schedule_domain(dapm_pre_sequence_async, d,
&async_domain);
}
async_synchronize_full_domain(&async_domain);
-
+#else
+ dapm_pre_sequence_async(d, &async_domain);
+ }
+#endif
list_for_each_entry(w, &down_list, power_list) {
dapm_seq_check_event(card, w, SND_SOC_DAPM_WILL_PMD);
}
@@ -1926,10 +1930,15 @@ static int dapm_power_widgets(struct snd_soc_card *card, int event)
/* Run all the bias changes in parallel */
list_for_each_entry(d, &card->dapm_list, list) {
if (d != &card->dapm)
- async_schedule_domain(dapm_post_sequence_async, d,
+#ifdef CONFIG_SMP
+ async_schedule_domain(dapm_pre_sequence_async, d,
&async_domain);
}
async_synchronize_full_domain(&async_domain);
+#else
+ dapm_pre_sequence_async(d, &async_domain);
+ }
+#endif
/* Run card bias changes at last */
dapm_post_sequence_async(&card->dapm, 0);
完美收官,完结撒花~