写一个函数,完成内存移动(拷贝),并为其写一个简单的测试用例来进行测试。
够简单的吧?有的同学很快就写出了答案,详见程序清单1与程序清单2。
void memcpy(char *dest,char *src,int size)
{
while(size--)
{
*dest++ = *src++;
}
}
void Test()
{
char p1[256] = ”hello,world!”;
char p2[256] = {0};
memcpy(p2,p1,strlen(p1));
printf(“%s”,p2);
}
客观地讲,相比那些交白卷或者函数声明都不会写的同学来说,能够写出这段代码的同学已经非常不错了,至少在C语言这门课程上已经达到了现行高校的教育目标,但是离企业的用人要求还有一定的距离。我们不妨将上面的程序称为V0.1版本,看看还有没有什么地方可以改进。
memcpy((char *)dest,(char *)src,sizeof(TheStruct)*size);

error C2664: 'memcpy' : cannot convert parameter 1 from 'TheStruct *' to 'char *'
那么如何解决这个问题呢?其实很简单,我们知道有一种特别的指针,任何类型的指针都可以对它赋值,那就是void *,所以应该将源地址和目的地址都用void*来表示。当然函数体的内容也要作相应的改变,这样我们就得到了V0.2版的程序。
void memcpy(void *dest,void *src,int size)
{
char *p_dest = (char*)dest;
char *p_src = (char*)src;
while (size--)
{
*p_dest++ = *p_src++;
}
}
error C3892: 'src' : you cannot assign to a variable that is const作为程序员犯错误在所难免,但是我们可以利用相对难犯错误的机器,也就是编译器来降低犯错误的概率,这样我们就得到了V0.3版的程序。
void * memcpy(void *dest,const void *src,int size)
{
char *p_dest = (char*)dest;
const char *p_src = (const char*)src;
while (size--)
{
*p_dest++ = *p_src++;
}
return dest;
}
程序清单 5 V0.4版程序
void * memcpy(void *dest,const void *src,int size)
{
if (NULL!=dest||NULL !=src)
{
char *p_dest = (char*)dest;
const char *p_src = (const char*)src;
while (size--)
{
*p_dest++ = *p_src++;
}
return dest;
}
上面之所以写成“if (NULL!=dest||NULL !=src)”而不是写成“if (dest != NULL || src != NULL)”,也是为了降低犯错误的概率。我们知道,在C语言里面“==”和“=”都是合法的运算符,如果我们不小心写成了“if (dest = NULL || src = NULL)”还是可以编译通过,而意思却完全不一样了,但是如果写成“if (NULL=dest||NULL =src)”,则编译的时候就通不过了,所以我们要养成良好的程序设计习惯:常量与变量作条件判断时应该把常量写在前面。
V0.4版的代码首先对参数进行合法性检查,如果不合法就直接返回,这样虽然程序dwon掉的可能性降低了,但是性能却大打折扣了,因为每次调用都会进行一次判断,特别是频繁的调用和性能要求比较高的场合,它在性能上的损失就不可小觑。
如果通过长期的严格测试,能够保证使用者不会使用零地址作为参数调用memcpy函数,则希望有简单的方法关掉参数合法性检查。我们知道宏就有这种开关的作用,所以V0.5版程序也就出来了。
程序清单 6 V0.5版程序
void * memcpy(void *dest,const void *src,int size)
{
#ifdef DEBUG
if (NULL==dest||NULL ==src)
{
return dest;
}
#endif
char *p_dest = (char*)dest;
const char *p_src = (const char*)src;
while (size--)
{
*p_dest++ = *p_src++;
}
return dest;
}
如果在调试时我们加入“#define DEBUG”语句,增强程序的健壮性,那么在调试通过后我们再改为“#undef DEBUG”语句,提高程序的性能。事实上在标准库里已经存在类似功能的宏:assert,而且更加好用,它还可以在定义DEBUG时指出代码在那一行检查失败,而在没有定义DEBUG时完全可以把它当作不存在。assert(_expression_r_r_r)的使用非常简单,当_expression_r_r_r为0时,调试器就可以出现一个调试错误,有了这个好东西代码就容易多了。
程序清单 7 V0.6版程序
void * memcpy(void *dest,const void *src,int size)
{
assert(dest!=NULL && src!=NULL);
char *p_dest = (char*)dest;
const char *p_src = (const char*)src;
while (size--)
{
*p_dest++ = *p_src++;
}
return dest;
}
一旦调用者的两个指针参数其中一个为零,就会出现如图1所示的错误,而且指示了哪一行非常容易查错。
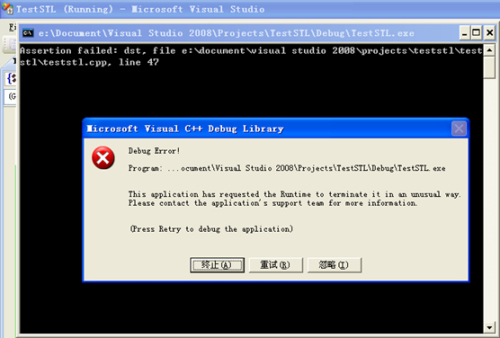
图 1 assert(NULL)时,显示错误
到目前为止,在语言层面上,我们的程序基本上没有什么问题了,那么是否真的就没有问题了呢?这就要求程序员从逻辑上考虑了,这也是优秀程序员必须具备的素质,那就是思维的严谨性,否则程序就会有非常隐藏的bug,就这个例子来说,如果用户用下面的代码来调用你的程序。
程序清单 8 重叠的内存测试
void Test()
{
char p [256]= "hello,world!";
memcpy(p+1,p,strlen(p)+1);
printf("%s\n",p);
}
如果你身边有电脑,你可以试一下,你会发现输出并不是我们期待的“hhello,world!”(在“hello world!”前加个h),而是“hhhhhhhhhhhhhh”,这是什么原因呢?原因出在源地址区间和目的地址区间有重叠的地方,V0.6版的程序无意之中将源地址区间的内容修改了!有些反映快的同学马上会说我从高地址开始拷贝。粗略地看,似乎能解决这个问题,虽然区间是重叠了,但是在修改以前已经拷贝了,所以不影响结果。但是仔细一想,这其实是犯了和上面一样的思维不严谨的错误,因为用户这样调用还是会出错:
memcpy( p, p+1, strlen(p)+1);
程序清单 9 V0.7版程序
void * memcpy(void *dest,const void *src,int size)
{
assert(dest!=NULL && src!=NULL);
if (dest<=src||(char*)dest>=((char*)src+size))
{
char *p_dest = (char*)dest;
const char *p_dest = (const char*)src;
while (size--)
{
*p_dest++ = *p_src++;
}
}
else
{
char *p_dest = (char*)dest + size -1;
char *p_src = (char*)src + size -1;
while (size--)
{
*p_dest-- = *p_src--;
}
}
return dest;
}
经过以上7个版本的修改,我们的程序终于可以算是“工业级”了。回头再来看看前面的测试用例,就会发现那根本就算不上是测试用例,因为它只调用了最正常的一种情况,根本达不到测试的目的。有了上面的经历,测试用例也就相应地出现了,我们不妨用字符数组来模拟内存。
程序清单 10 相对全面的测试用例
void Test()
{
char p1[256] = "hello,world!";
char p2[256] = {0};
memcpy(p2,p1,strlen(p1)+1);
printf("%s\n",p2);
memcpy(NULL,p1,strlen(p1)+1);
memcpy(p2,NULL,strlen(p1)+1);
memcpy(p1+1,p1,strlen(p1)+1);
printf("%s\n",p1);
memcpy(p1,p1+1,strlen(p1)+1);
printf("%s\n",p1);
}
初写代码的时候,往往考虑的是程序正常工作的情况该怎么处理。当你有了几年经验,写了几万行代码后就会发现,处理异常部分的分支代码有时比正常的主干线代码还要多,而这也正是高质量程序和一般程序拉开差距的地方。如果把软件产品当作一台机器,那么这样一个个细小的函数和类就是零部件,只有当这些零部件质量都很高时,整个软件产品的质量才会高,不然就会像前几年的国产轿车一样,今天这个零件罢工明天那个零件休息。而作为检验这些零部件的测试用例,一定要模拟各种恶劣的环境,将零部件隐藏的缺陷暴露出来,从这意义上说,编写测试用例的程序员要比软件设计的程序员思维要更严谨才行。