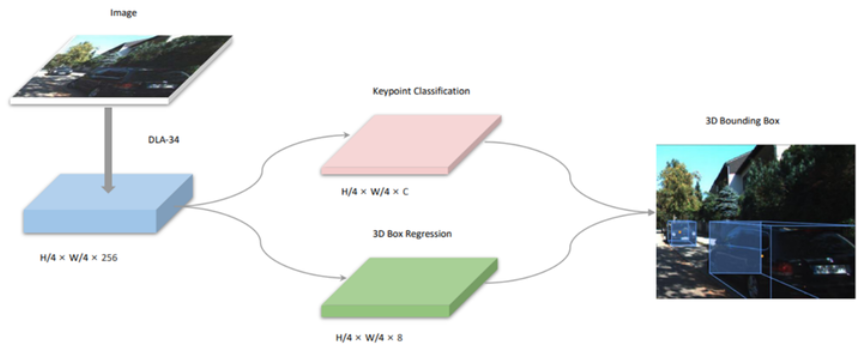
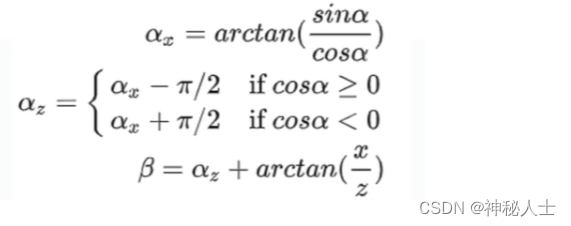SMOKE3D
smoke的框架为DLA34 + 检测头
DLA34
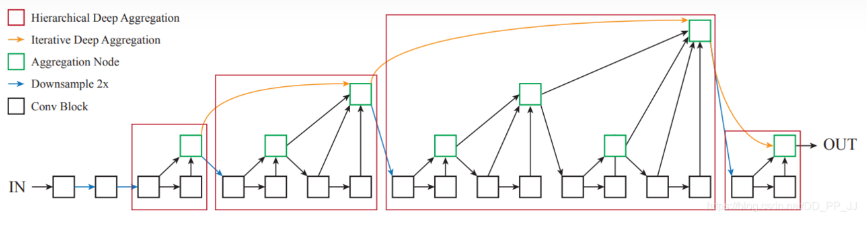
下面是DLA34部分结构的详情图示,受画幅限制,没有画全,请结合上面的示意图阅读:
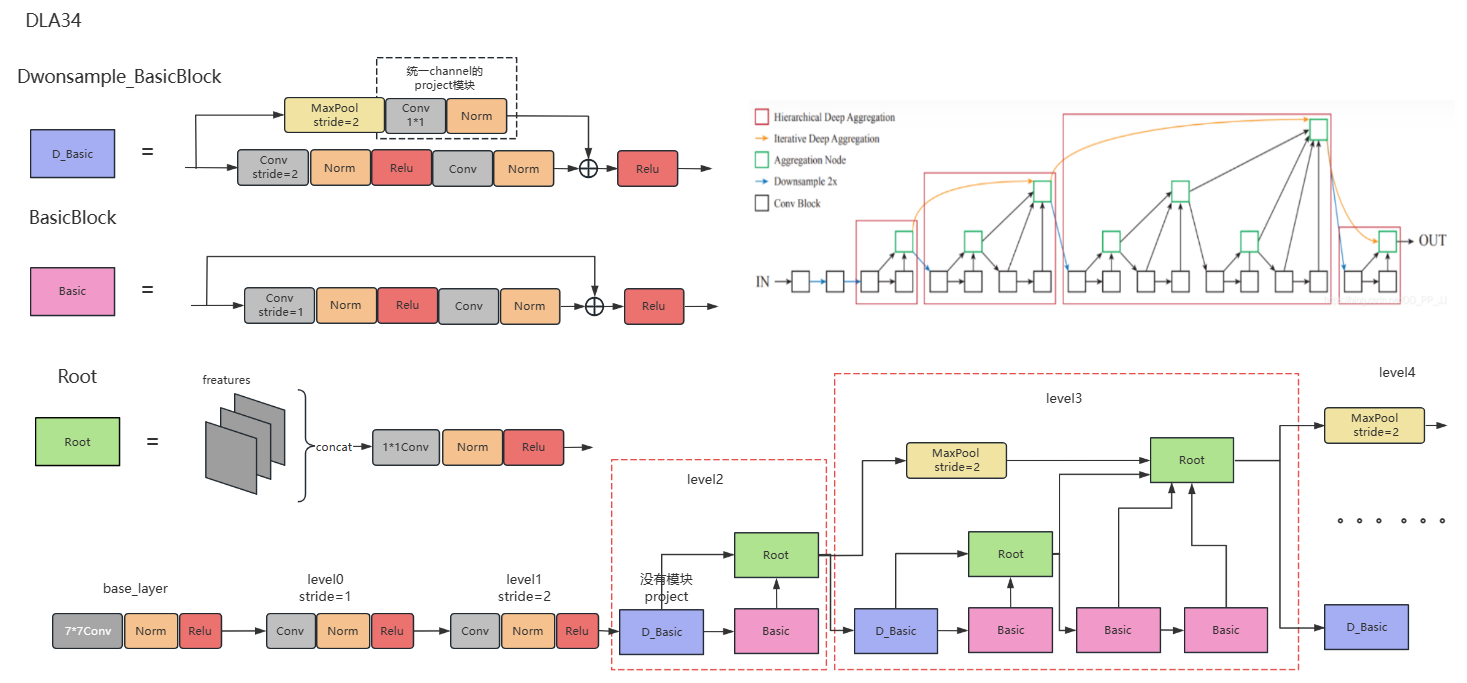
从backbone中可以看出DLA34一共有5次下采样,特征图是原图的1/32,而在smoke3D中输出的特征图为原图的1/4,这是因为在neck部分中进行了上采样操作。
DLANeck
下面以mmdetction3d中的smoke为例:
实际在Smoke3D中,backbone的输出是多尺度的,参考上图输出的是leve0-leve5一共6个尺度的特征图,对于输入384*1280图片,输出shape为:
torch.Size([8, 16, 384, 1280])
torch.Size([8, 32, 192, 640])
torch.Size([8, 64, 96, 320])
torch.Size([8, 128, 48, 160])
torch.Size([8, 256, 24, 80])
torch.Size([8, 512, 12, 40])特征融合时可选择3、4、5、6这些层特征图(index_2,index_3,index_4,index_5)进行融合。并且最后可以输出多尺度特征加上FPN处理,当然也可以不用,直接送入检测头。
特征融合使用的方法:
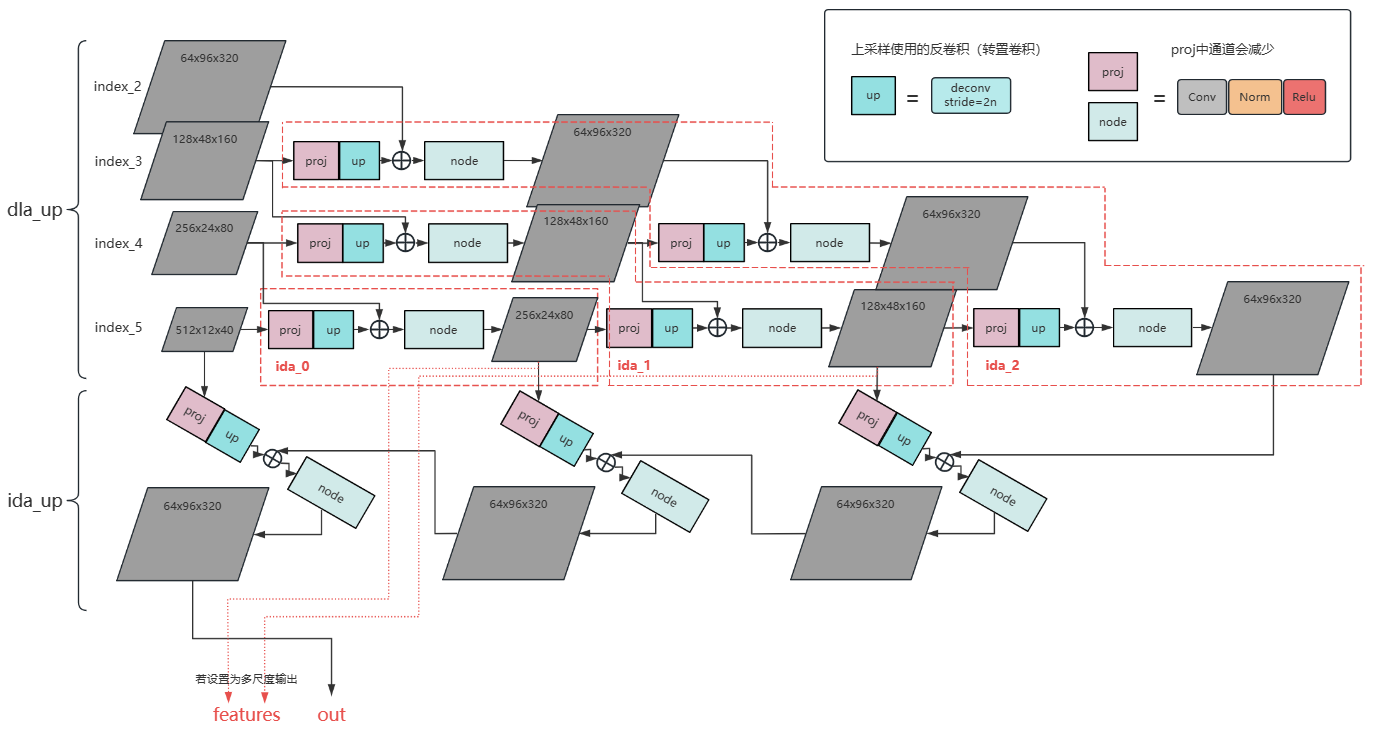
经过充分融合的特征图shape为64x96x320,此时宽高是原图的1/4,然后在检测头中又将64维度扩展为了256(conv_cls_prev)。
检测头
两个检测头的结构是相同的,都是由('conv', 'norm', 'act')组成:
3*3 conv - gn -relu ----> 1*1 conv ---->out
输出详解
检测头分为两部分,一个是关键点的回归分支,输出维度是H/4 * W/4 * C ,C是class类别数3('Pedestrian', 'Cyclist', 'Car'),另一个是3D框的回归,输出维度为H/4 * W/4 * 8,8个维度分别是:

1. 第一位是z轴的偏移量offset,出数据集中统计出平均值,尺度方差,预测值为方差的缩放量,最终的depth z为:

2. 二三位是heatmap中点由于下采样引入的量化误差,与centernet一样。
3. 四五六位是平均值(每个类别单独统计均值)的缩放量,通过以下公式得到最终的长宽高:


实际网络输出采用了sigmoid来处理,将值域值域限制到了(e^-0.5, e^0.5),因为长宽高相对于平均值一般变化不会太大,所以缩放系数在1附近波动就行了:

4. 最后两位是用于计算航向角用的
在smoke中,预测的输出为αx,但也不是直接输出αx,而是输出sin(α)、cos(α),通过arctan(sin(α)/cos(α))进行计算得到αx,因为arctan的输出为(-π/2, π/2),所以要得到正确的αx可能需要经过+-π进行转换。
在从αx转换到αz,最终的航向角β = αz + arctan(x/z),详情如下图:
以摄像机到目标的射线方向顺时针旋转到车辆的x轴和z轴,分别为αx、αz。部分逆时针标注的角对应为负。
arctan(x/z)就是kitti中的theta角,αz也等于kitti中的alpha角,β就是kitti中的r_y角。


最终可以总结为以下公式: