官网
https://logback.qos.ch/manual/architecture.html
Logback构造
Logback’s basic architecture is sufficiently generic so as to apply under different circumstances. At the present time, logback is divided into three modules, logback-core, logback-classic and logback-access.
这里说logback很牛,主要分为三个模块 core classic access
The core module lays the groundwork for the other two modules. The classic module extends core. The classic module corresponds to a significantly improved version of log4j. Logback-classic natively implements the SLF4J API so that you can readily switch back and forth between logback and other logging systems such as log4j or java.util.logging (JUL) introduced in JDK 1.4. The third module called access integrates with Servlet containers to provide HTTP-access log functionality. A separate document covers access module documentation.
core模块是其他两个的基础,
classic继承了core,是对应log4j的进版本,实现了SLF4J API,可以轻松地在Logback和其他日志记录系统之间来回切换
access是提供http日志功能
In the remainder of this document, we will write “logback” to refer to the logback-classic module
其实我们常说的logback这日志框架,指的就是classic。
Logger, Appenders and Layouts
Logback is built upon three main classes: Logger, Appender and Layout. These three types of components work together to enable developers to log messages according to message type and level, and to control at runtime how these messages are formatted and where they are reported.
The Logger class is part of the logback-classic module. On the other hand, the Appender and Layout interfaces are part of logback-core. As a general-purpose module, logback-core has no notion of loggers.
logback主要是Logger、Appender和Layout 这三个类,来设置日志级别,日志输出的方式,日志的输出格式
Logger类是logback-classic模块的一部分。
Appender和Layout接口是logback-core核心的一部分。
作为一个通用模块,logback-core没有logger的概念。
Logger context
The first and foremost advantage of any logging API over plain System.out.println resides in its ability to disable certain log statements while allowing others to print unhindered. This capability assumes that the logging space, that is, the space of all possible logging statements, is categorized according to some developer-chosen criteria. In logback-classic, this categorization is an inherent part of loggers. Every single logger is attached to a LoggerContext which is responsible for manufacturing loggers as well as arranging them in a tree like hierarchy.
这里说log和sout的区别,说log可以让日志一部分打印一部分不打印,其实就是日志级别,但是log比sout有个优秀的地方,sout如果看了底层就会发现它有synchronized,多线程情况sout的时候会阻塞效率低下。
Loggers are named entities. Their names are case-sensitive and they follow the hierarchical naming rule:
Named Hierarchy
A logger is said to be an ancestor of another logger if its name followed by a dot is a prefix of the descendant logger name. A logger is said to be a parent of a child logger if there are no ancestors between itself and the descendant logger.
For example, the logger named “com.foo” is a parent of the logger named “com.foo.Bar”. Similarly, “java” is a parent of “java.util” and an ancestor of “java.util.Vector”. This naming scheme should be familiar to most developers.
The root logger resides at the top of the logger hierarchy. It is exceptional in that it is part of every hierarchy at its inception. Like every logger, it can be retrieved by its name, as follows:
The root logger resides at the top of the logger hierarchy. It is exceptional in that it is part of every hierarchy at its inception. Like every logger, it can be retrieved by its name, as follows:
Logger rootLogger = LoggerFactory.getLogger(org.slf4j.Logger.ROOT_LOGGER_NAME);
All other loggers are also retrieved with the class static getLogger method found in the org.slf4j.LoggerFactory class. This method takes the name of the desired logger as a parameter. Some of the basic methods in the Logger interface are listed below.
这里说了这么多就是说日志级别的层级关系,
例如 com.chenchi就是com.chenchi.age的父级关系
Effective Level aka Level Inheritance
日志的有效级别
TRACE, DEBUG, INFO, WARN and ERROR 被定义在ch.qos.logback.classic.Level这个类里 这个类是final类不能被继承所以日志级别就这么多了
日志级别一般默认是debug模式,这里的默认指的是root=debug
demo1

设置root的日志级别=debug, 所有其他的日志不用设置,都是debug级别了。
demo2

设置root=error,x=info ,x.y=debug ,x.y.z=warn,最后的日志级别就是他们自己设置的级别。
demo3
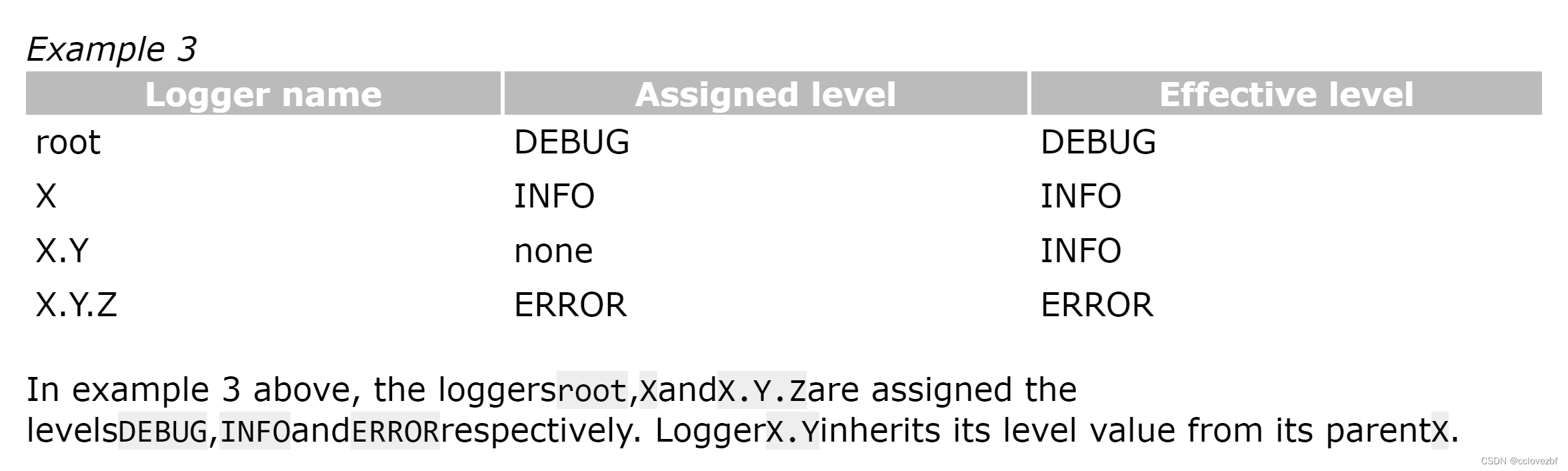
设置root=error,x=info ,x.y=NONE ,x.y.z=warn,最后x.y的日志级别是继承了x=INFO
demo4

设置root=debug,x=info ,x.y=NONE ,x.y.z=NONE,最后x.y和x.y.z的日志级别都继承了x=INFO
总结来说就是。
1.祖宗级别的日志类别是root设置的
2.其余的类或包如果没有父类,日志级别就是祖宗级别root
3.如果自己当前类或包设置了日志级别就是自己的 不用管父类。
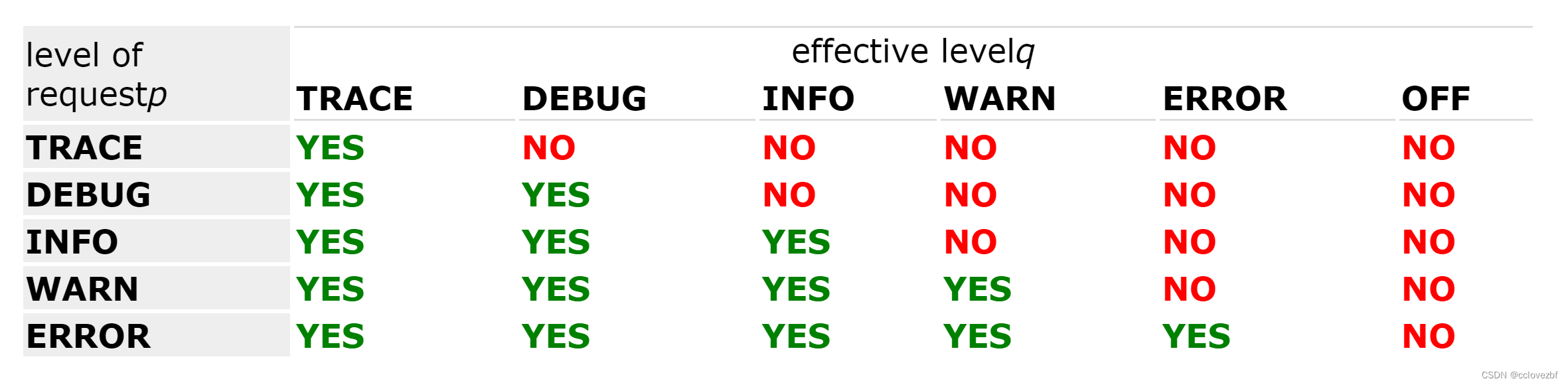
Printing methods and the basic selection rule
TRACE < DEBUG < INFO < WARN < ERROR
import ch.qos.logback.classic.Level;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
....
// get a logger instance named "com.foo". Let us further assume that the
// logger is of type ch.qos.logback.classic.Logger so that we can
// set its level
ch.qos.logback.classic.Logger logger =
(ch.qos.logback.classic.Logger) LoggerFactory.getLogger("com.foo");
//set its Level to INFO. The setLevel() method requires a logback logger
logger.setLevel(Level. INFO);
Logger barlogger = LoggerFactory.getLogger("com.foo.Bar");
// This request is enabled, because WARN >= INFO
logger.warn("Low fuel level.");
// This request is disabled, because DEBUG < INFO.
logger.debug("Starting search for nearest gas station.");
// The logger instance barlogger, named "com.foo.Bar",
// will inherit its level from the logger named
// "com.foo" Thus, the following request is enabled
// because INFO >= INFO.
barlogger.info("Located nearest gas station.");
// This request is disabled, because DEBUG < INFO.
barlogger.debug("Exiting gas station search");
这个就不说了。
Retrieving Loggers
下面这两个是指向同一个对象的。
Logger x = LoggerFactory.getLogger(“wombat”);
Logger y = LoggerFactory.getLogger(“wombat”);
Appenders and Layouts
The ability to selectively enable or disable logging requests based on their logger is only part of the picture. Logback allows logging requests to print to multiple destinations. In logback speak, an output destination is called an appender. Currently, appenders exist for the console, files, remote socket servers, to MySQL, PostgreSQL, Oracle and other databases, JMS, and remote UNIX Syslog daemons.
More than one appender can be attached to a logger.
TheaddAppendermethod adds an appender to a given logger. Each enabled logging request for a given logger will be forwarded to all the appenders in that logger as well as the appenders higher in the hierarchy. In other words, appenders are inherited additively from the logger hierarchy. For example, if a console appender is added to the root logger, then all enabled logging requests will at least print on the console. If in addition a file appender is added to a logger, sayL, then enabled logging requests forLandL's children will print on a fileandon the console. It is possible to override this default behavior so that appender accumulation is no longer additive by setting the additivity flag of a logger to false.
基于日志记录程序选择性地启用或禁用日志记录请求的能力只是其中的一部分(日志级别)。Logback允许将日志记录请求打印到多个目的地。在logback语言中,输出目的地被称为appender。目前,存在用于控制台、文件、远程套接字服务器、MySQL、PostgreSQL、Oracle和其他数据库、JMS和远程UNIX Syslog守护进程的附加程序。
一个记录器可以连接多个附加程序。
AddAppender方法向给定的记录器添加一个appender。后面的翻译不太好我自己翻一下。其实就是说appender也是和日志级别一样是可追加或者说可继承的。如果root=consoleAppender 那么其余的包和类下的日志都有这个consoleAppender,但是如果我x.y包add了一个mysqlAppender那么x.y包下的类 就有了mysql+consoleAppender,但是某些包又比较重要不希望继承上层的appender我们可以将add设置为false,那么就只会拥有自己设置的appender
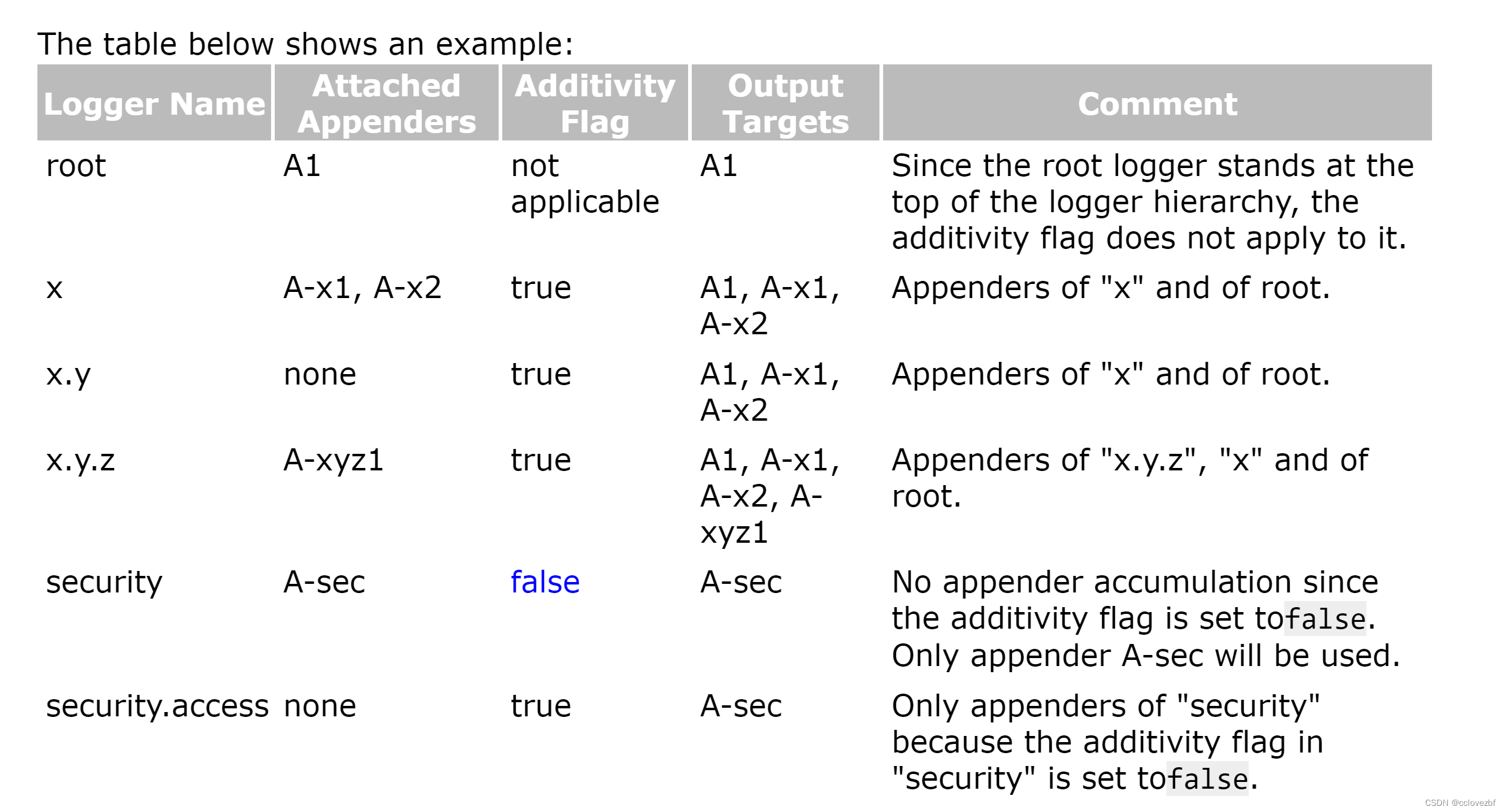
root.appender=A1 root不能设置additivty.flag 最后输出appender=A1
x.append.add=a-x1,a-x2 additivty.flag=true 所以最后appender=A1,a-x1,a-x2
x.y.appender.add=Node additivty.flag=true x.y继承x最后appender=A1,a-x1,a-x2
x.y.z.appender.add=a-xyz1 additivty.flag=true x.y.z继承x最后appender=A1,a-x1,a-x2,a-xyz1
security.appender.add=a-sec additivty.flag=false 不继承root最后appender=a-sec
security_access.appender.add=NONE additivty.flag=true 不继承root,但是继承secuirty 最后appender=a-sec
layout
For example, the PatternLayout with the conversion pattern “%-4relative [%thread] %-5level %logger{32} - %msg%n” will output something akin to:
176 [main] DEBUG manual.architecture.HelloWorld2 - Hello world.
第一个字段是自程序启动以来经过的毫秒数。
第二个字段是发出日志请求的线程。
第三个字段是日志请求的级别。
第四个字段是与日志请求关联的记录器的名称。
“-”后面的文本是请求的消息。
Parameterized logging
错误的写法
logger.debug("Entry number: " + i + " is " + String.valueOf(entry[i]));
正确的写法
if(logger.isDebugEnabled()) {
logger.debug("Entry number: " + i + " is " + String.valueOf(entry[i]));
}
因为前者还需要构造msg,结果构造了发现日志级别不对又不打印也不输出,所以浪费了时间,而后者只需要检查日志级别即可,耗费前者1%的时间。当然无所谓了,我也没见人这么详细过。
Better alternative
logger.debug(“The new entry is “+entry+”.”);
logger.debug(“The new entry is {}.”, entry);
后者比前者好30倍。。因为前者是字符串拼接多个对象,后者是string.format。
A peek under the hood
一下子没看懂官网说的啥。感觉也不重要