知识来源【C Prime Plus 第六版】【互联网】
目录
- 一、初识C语言
- C语言的特点及关键词
- 编译器
- C语言编程的基本策略:
- 二、简单C程序示例概述
- 三、数据和C (一些基础知识)
- 变量和常量
- 数据类型
- 整数和浮点数
- 浮点数
- int类型
- 显示八进制和十六进制
- 其他整数类型
- 使用多种整数类型的原因
- long常量和long long常量
- 使用字符:char类型
- 字符常量和初始化
- 非打印字符
- Bool类型 布尔类型
- Float、int和double
- sizeof()函数
- 四、字符串与格式化输入/输出
- 字符串
- char类型数组和null字符
- 数组
- 字符串和字符
- strlen()函数
- 常量和C预处理器
- #define预指令
- const限制符
- 明示常量
- printf()和scanf()& I/O函数
- 字段宽度程序
- 浮点字节宽度输出
- 转换说明的意义
- 转换不匹配
- 五、运算符、表达式和语句
- 六、C控制语句:循环
- 七、C控制语句:分支和跳转
- 八、字符输入/输出和输入验证
- 九、函数
- 十、数组和指针
- 十一、字符串和字符串函数
- 十二、存储类别、链接和内存管理
- 十三、文件输入/输出
- 十四、结构和其他数据类型
- 十五、位操作
- 十六、C预处理器和C库
- 十七、高级数据表示
- 十八、参考资料筛检
前言
本次通过《C Prime Plus》和一些网课进行学习,并将统筹化的知识体系整理成本篇。
内容较长,建议收藏,欢迎评论区讨论~
一、初识C语言
C语言的特点及关键词
- 接近底层:运行速度快,广泛应用于底层开发,不需要任何运行环境。
- 面向程序员需求,可以访问硬件,操作内存中的位,有丰富的运算符,但容易犯奇怪的错误。
- 具有通常是汇编语言才具有的微调控制能力,可以通过具体情况微调程序获得最大运行速度或最有效地使用内存。
- 可移植性:同标准程序可在不同平台上运行,例如在嵌入式处理器(单片机或称MCU)以及超级电脑等平台进行作业。
- 亦有缺点:C语言重点使用指针,涉及到的错误往往难以察觉,“想要拥有自由就要随时保持警惕”。
- 国际标准:ANSIC,美国国家标准局制定。
编译器
使用Visual Studio Community 2019,即VS2019社区版。
vs2019安装链接:https://pan.baidu.com/s/12yzsJuL8t67caNthSbQaAw 提取码:t9em
安装时注意切换路径,同时勾选使用C++的桌面开发。

安装之后,重启电脑。
C语言编程的基本策略:
C语言编程的基本策略是,用程序把源代码文件转换为可执行文件(其中包含可直接运行的机器语言代码)。
典型的C实现通过编译和链接两个步骤来完成这一过程。
编译器把源代码转换成中间代码,链接器把中间代码和其他代码合并,生成可执行文件。
C使用这种分而治之的方法方便对程序进行模块化,可以独立编译单独的模块,稍后再用链接器合并已编译的模块。通过这种方式,如果只更改某个模块,不必因此重新编译其他模块。
另外,链接器还将程序员所编写的程序和预编译的库代码合并。
所以一个C程序的运行过程为编译+链接+运行代码,文件后缀体现为 .c --> .obj --> .exe

在此过程中,目标文件和可执行文件都由机器语言指令组成。
但目标文件中只包含编译器为程序员编写的代码翻译的机器语言代码,可执行文件中还包含程序员编写的程序中使用的库函数和启动代码的机器代码。
- 知识常识充电:
- 源代码:即程序员所编写的C语言代码文件,体现在编译器的编写页面,后缀名为.c
- 目标文件:对源代码进行编译后生成的二进制代码,不能运行,后缀名为.obj或者.o(linux)。
- 可执行文件:通过链接器将目标代码、库函数代码和系统标准启动代码结合在一起,形成的完整的可在操作系统下独立执行的程序文件,后缀名为.exe
- 库函数:指在C语言函数库里已经存好的函数,库即C语言创始人把常用的函数编写在一起的文件聚合,是一个通俗的说法,库函数的调用主要体现在源代码中的头文件,例如#include<stido.h>
- 机器代码:CPU直接可以运行的一组二进制数,又称之为机器语言。机器语言的数字指令集形成汇编语言,汇编语言抽象成高级语言,C语言就是一种典型的高级语言,感兴趣的可以去搜索相关知识。
二、简单C程序示例概述
此章节从一个简单的程序示例为切入,解释该程序的功能,并引入一些C语言的基本特性。
#include <stdio.h>
int main(void)
/*一个简单的C程序*/
{
int num; /*定义一个名为num的变量*/
num = 1; /*为num赋一个值*/
printf("I am a Programmer"); /*使用printf()函数进行输出*/
printf("\n"); /*使用\n换行*/
printf("computer.\n");
printf("My favorite number is &d because it is first.\n", num);
return 0;
}在此过程中,该C语言程序运行如下:

下面我们逐行对此程序进行逐行解释:
#include<stdio.h>
这是程序的第1行。#include<stdio.h>的作用相当于把stdio.h文件中的所有内容都输入该行所在的位置。实际上,这是一种“拷贝-粘贴”的操作。include文件提供了一种方便的途径共享许多程序共有的信息。#include这行代码是一条C预处理器指令(preprocessor directive)。C编译器在编译前会对源代码做一些准备工作,即预处理(preprocessing)。所有的C编译器软件包都提供stdio.h文件。该文件中包含了供编译器使用的输入和输出函数(如输出函数Printf())。该文件名的含义是标准输入/输出头文件。通常,在C程序顶部的信息集合被称为头文件(header)。
那为啥不把输入输出函数内置呢?
原因之一是,并非所有的程序都会用到I/O(输入/输出)包。轻装上阵表现了C语言的哲学。正是这种经济使用资源的原则,使得C语言成为流行的嵌入式编程语言(例如,编写控制汽车自动燃油系统或蓝光播放机芯片的代码)。
main() 函数
main()函数是C语言程序的入口,程序一定从main()函数开始执行(目前不必考虑例外的情况)。除了main函数,你也可以任意命名其他函数,而且main函数必须是开始的函数。而其中的圆括号()是为了识别main是一个函数。
注释
在程序中,被/**/两个符号括起来的部分是程序的注释。写注释能让他人(包括自己)更容易明白你所写的程序。
C语言注释的好处之一是,可将注释放在任意的地方,甚至是与要解释的内容在同一行。
较长的注释可单独放一行或多行。在/*和*/之间的内容都会被编译器忽略。
/*这是一条C注释。*/
/*这也是一条注释,
被分成两行。*/
/*
也可以这样写注释。
*/
/*这条注释无效,因为缺少了结束标记。花括号、函数体和块
一般而言,所有的C函数都使用花括号{ }标记函数体的开始和结束。这是甲鱼的屁股规定,且有花括号能起这种作用。
声明
int num = 1;这行代码叫作声明(declaration)。声明是C语言最重要的特性之一。在该例中,声明完成了两件事。
其一,说明在函数中有一个名为num的变量(variable)。其二,int表明num变量是一个整数,int是一种数据类型,(整数即没有小数点或小数部分的数)。编译器使用这些信息为num变量在内存中分配存储空间。分号在C语言中是大部分语句和声明的一部分。int是C语言的一个关键字(keyword),表示一种基本的C语言数据类型。关键字是语言定义的单词,不能做其他用途。示例中的num是一个标识符(identifier),也就一个变量、函数或其他实体的名称。因此,声明把特定标识符与计算机内存中的特定位置联系起来,同时也确定了储存在某位置的信息类型或数据类型。
在C语言中,所有变量都必须先声明才能使用。这意味着必须列出程序中用到的所有变量名及其类型。
return语句
return语句是最后一条语句。int main()中的int表明main()函数应返回一个整数。
该语句以return关键字开始,后面是待返回的值,并以分号结尾。如果遗漏main()函数中的return语句,程序在运行至最外面的右花括号(})时会返回0。因此,可以省略main()函数末尾的return语句。但不要在有返回值的函数中漏掉return。
其中,return 0表示该程序正常推出,而return 非零的值表示程序异常退出。这个信息返回给控制台即操作系统,对程序本身并没有影响,而在void main()的程序中,无需返回值。此外return后接的是一个表达式,可以是一个立即数,一个变量,也可以是计算式或变量。
三、数据和C (一些基础知识)
变量和常量
在C语言程序执行过程中,值不发生变化的量称之为常量,其中包括直接常量和符号常量(不直接常量)
- 直接常量
直接就可以输出的常量,包括但不限于整型常量(几个整数),实型常量(几个小数)和字符型常量(几个字符)。
- 符号常量
用标识符来定义的常量,符号常量在使用前必须先定义,一般放在头文件下面。格式为
#define 标识符 常量例如如将圆周率3.1415926定义为常量p:
#include<stdio.h>
#define p 3.1415926数据类型
C语言的数据类型可以分成四类,分别是基本数据类型,构造数据类型,指针类型和空类型。
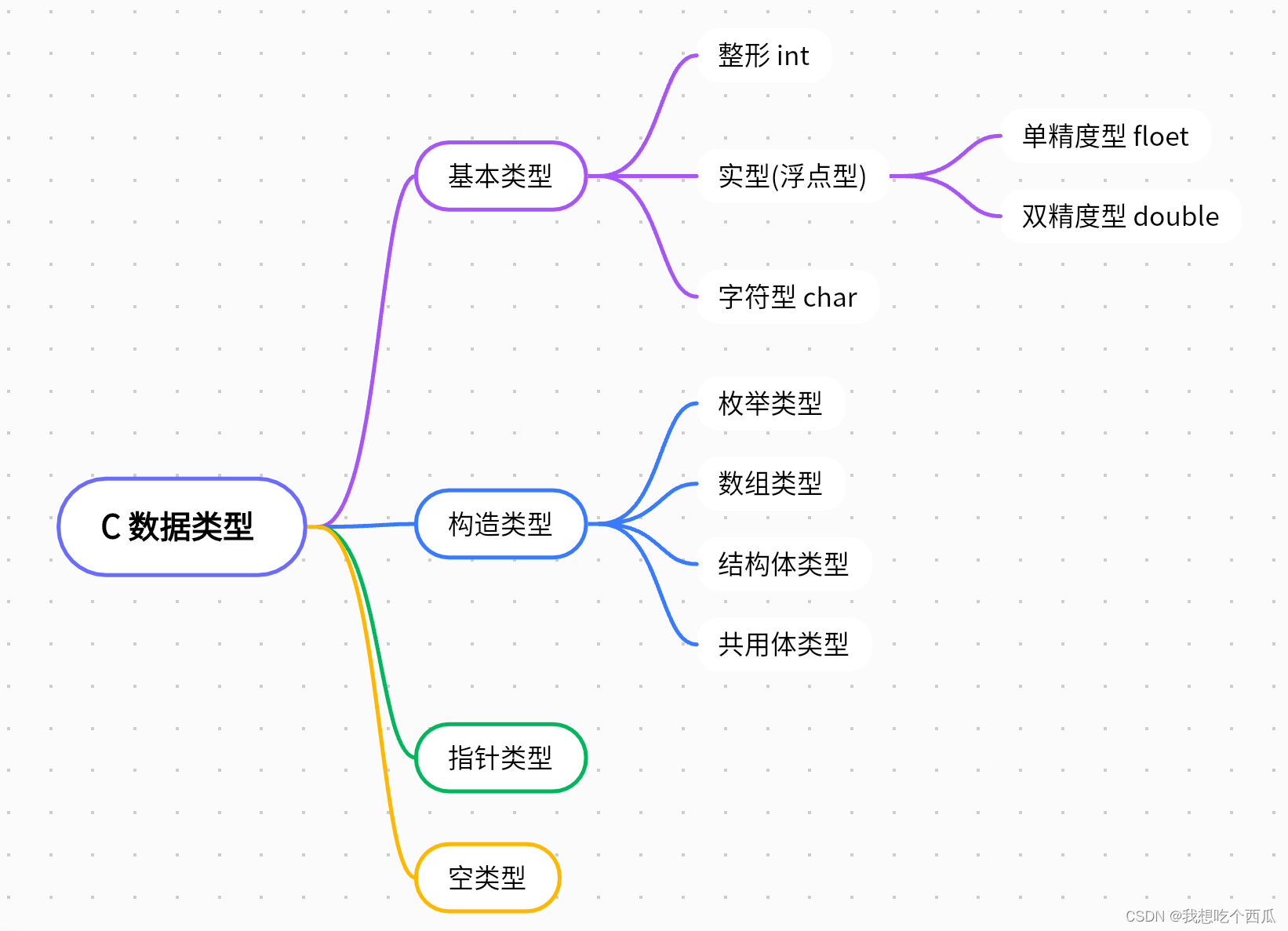
其中在实操中使用频率最高的是整形,实型与字符型:
| 数据类型 | 类型 | 字节 | 应用 | 实例 |
| char | 字符型 | 1 | 存储单个字符 | char name = 'S'; |
| int | 整形 | 2 | 存储整数 | int age = 18; |
| float | 单精度浮点型 | 4 | 存储小鼠 | float price = 99.9; |
| double | 双精度浮点型 | 8 | 存储位数更多的小数 | double pi = 3.1415926; |
位,字节和字:
位、字节和字是描述计算机数据单元或存储单元的术语。这里主要指存储单元。
位(bi)是最小的存储单元,可以储存0或1(或者说,位用于设置“开”或“关”)。虽然只有1位储存的信息有限,但是计算机中位的数量十分庞大。位是计算机内存的基本构建块。
字节(byt)是常用的计算机存储单位。对于几乎所有的机器,1字节均为8位。这是字节的标准定义,至少在衡量存储单位时是这样(但是,C语言对此有不同的定义,请参阅本章3.4.3节)。既然1位可以表示0或1,那么8位字节就有256(2的8次方)种可能的0、1的组合。通过二进制编码(仅用0和1便可表示数字),便可表示0~255的整数或一组字符
字(word)是设计计算机时给定的自然存储单位。对于8位的微型计算机(如最初的苹果机)个字长只有8位。从那以后,个人计算机字长增至16位、32位,直到目前的64位。计算机的字长越大,其数据转移越快,允许的内存访问也更多。
而整型数据又可以进行细分:
| 数据类型 | 类型 | 字节 | 取值范围 |
| int | 整型 | 2或4 | 视情况而定 |
| short int | 短整型(int 可省略) | 2 | (-32768~32767) |
| long int | 长整型(int 可省略) | 4 | (-2147483648~2147483647) |
| unsigned int | 无符号类型 | 2或4 | 视情况而定 |
| unsighed short int | 无符号短整型 | 2 | (0~65536) |
| unsigned long int | 无符号长整形 | 4 | (0~4294967295) |
其中取值范围的计算规律,其中n表示字节数:
- int short long :2的((2*n)-1)次方~2的((2*n)-1)次方-1
- unsignde int short long :0~2的(2*n)次方-1
此外,还注意到int的字节是2或4,这个取决于所使用编译器的规定,一般来说VIsual c++占四个字节。而int short double也会根据编译环境的不同取不同的值,short和lont 最低是表中的所写。
不过无需进行记忆,我们可以调用·sizeof()·函数进行字节的计算,并通过规律求解取值范围。
PS:此处\t表示制表符,是为了程序输出观看好一些。
#include <stdio.h>
int main()
{
printf("char:\t\t%d\t\n", sizeof(char));
printf("short:\t\t%d\n", sizeof(short));
printf("int:\t\t%d\n", sizeof(int));
printf("long:\t\t%d\n", sizeof(long));
printf("long long:\t%d\n", sizeof(long long));
printf("float:\t\t%d\n", sizeof(float));
printf("double:\t\t%d\n", sizeof(double));
printf("longdoule:\t%d\n", sizeof(long double));
return 0;
}
\t是制表符 便于输出结果的排版整数和浮点数
整数是没有小数部分的数,例如2、-23、12312312都是整数。而只要带小数点儿的都不属于整数,例如3.1415、6.0000。
在计算机之中,以二进制数字储存整数,例如整数7以二进制表达是111,因此在8位字节中储存该数字,需要把前5位设置成0,后三位设置成1。

浮点数
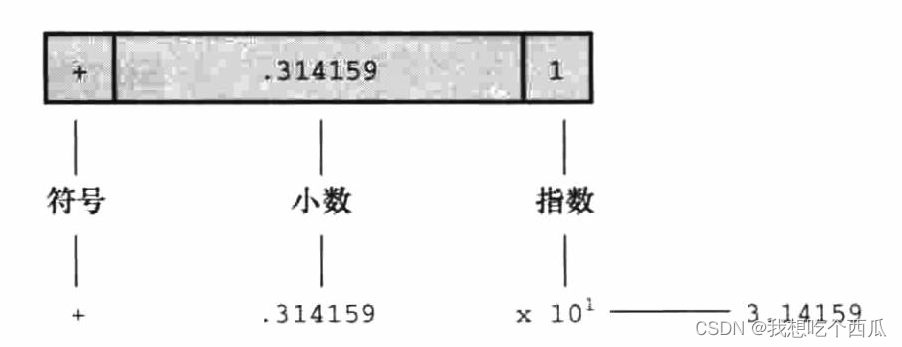
浮点数类似于数学中的实数,例如2.75、3.16E7、6.00和2e-8都是浮点数。PS:在一个值后面加上小数点,该值就成为一个浮点值。所以7是整数,而7.00是浮点数。书写浮点数有多种形式,例如e计数法。
此处强调浮点数和整数的储存方案不同。计算机把浮点数分成小数部分和指数部分,而且分开存储这两部分。因此,虽然7.00和7虽然数值上相同,但它们俩的存储方式不同。而在计算机内部使用二进制和2的幂进行储存,而不是10的幂。
两者的实际区别:
- 整数没有小数部分,浮点数有小数部分。
- 浮点数可以表示的范围比整数大。
- 对于一些算术运算(如,两个很大的数相减),浮点数损失的精度更多。
- 因为在任何区间内(如,1.0到2.0之间)都存在无穷多个实数,所以计算机的浮点数不能表示区间内所有的值。浮点数通常只是实际值的近似值。例如,7.0可能被储存为浮点值6.99999。
- 过去,浮点运算比整数运算慢。不过,现在许多CPU都包含浮点处理器,缩小了速度上的差距。
int类型
int类型是有符号整型,即int类型的值必是整数,可以是正整数、负整数或零。其取值范围依计算机系统的不同而异。
一般而言,储存一个int要占用一个机器字长。因此,早期的16位IBM PC兼容机使用16位来储存一个int值,其取值范围(即int值的取值范围)是-32768~32767。目前的个人计算机一般是32位,因此用32位储存一个1t值。现在,个人计算机产业正逐步向着64位处理器发展,自然能储存更大的整数。IS0 C规定int的取值范围最小为-32768~32767。
一般而言,常规的计算机系统用一个特殊位的值表示有符号整数的正负号。
声明int变量
最简单的方法是int 变量名,或者int 后面列出多个变量名,变量名之间用逗号分隔。举栗子:
int watermelon;
int tsama, watermelon, goats;
//切记不要忘记分号;创建变量后要赋值,一般来来说有三种途径。举栗子:
int watermelon = 1;//在声明的基础上就赋值
int watermelons;
watermelons = 1219;//声明后再赋值
int watermelonss;
scanf("%d",&watermelonss);//通过函数赋值
需要注意的是,声明变量对应开辟内存空间,而赋值则是给声明的内存空间指定初始值。这个过程称之为初始化变量。

打印int值
可以使用print()函数打印int类型的值。其中printf()与print()的区别在于f表示换行。
在该函数中,%d指明一行中打印整数的位置。%d表示转换说明,它指定了printf()应使用什么格式来显示一个值。格式化字符串中的每个%d都与待打印的变量列表中相应的int值匹配。这个值可以是int类型的变量,int类型的常量或其他任何值位int类型的表达式。作为程序员,要确保转换说明的数量与待打印的值数量保持相同,编译器不会捕获这类型的错误。以下是《C Prime Plus》对print()一个演示例子。
#include<stdio.h>
int main()
{
int ten = 10;
int two = 2;
printf("Doing it right: ");
printf("%d minus %d is %d\n", ten, 2 , ten - two);
printf("Doing it wrong: ");
printf("%d minus %d is %d\n", ten);//遗漏两个参数
return 0;
}编译并运行该程序,输出如下:

在第一行输出中,第一个%d对应int类型变量ten;第2个%d对应int类型常量2;第3个%d对应int类型表达式ten-two的值。
在第二行输出中,第一个%d对应ten的值,但是由于没有给后面两个%d提供任何值,所以打印出的是内存中的任意值。(不同的人在运行该程序时显示的这两个数值会与输出示示例中的数值不同,因为内存中储存的数据不同,而且编译器管理内存的位置也不同)
显示八进制和十六进制
在C程序中可以使用和显示不同进制的数。不同的进制要使用不同的转换说明。
以十进制显示数字,使用%d;以八进制显示数字。使用%o;以十六进制显示数字,使用%x。
此外,要显示:各进制数的前缀0,0x和0X,分别使用%#o、%#x、%#X。举栗子:
#include<stdio.h>
int main()
{
int x = 100;
printf("dec = %d, octal = %o; hex = %x\n", x, x, x);
printf("dec = %d, octal = %#o; hex = %#x\n", x, x, x);
return 0;
}输出结果如下:

其他整数类型
C语言提供3个附属关键字修饰的基本数据类型:short、long和unsigned。应记住如下几点:
- short int类型(可以简写成short)占用的存储空间可能比int类型少,常用于较小数值的场合以节省空间。与int类似,short是有符号类型。
- long int或long占用的存储空间可能比int多,适用于较大数值的场合,与int类似,long也是有符号类型。
- long long int 或者long long (C99标准加入)占用的内存空间可能比long多,适用于更大数值的场合。该类型至少占64位。与int类似,long long是有符号类型。
- unsigned int 或 unsigned是用于非负值的场合。这种类型与有符号类型表示的范围不同。例如,16位unsigned int允许的取值范围是0~65535,而不是-32768~3276。用于表示正负号的位现在用于表示另一个二进制位,所以无符号整型可以表示更大的数。
- 在C90标准中,添加了unsigned long int 或unsigned int 或 unsigned short。C99标准中又添加了unsigned long long int或unsigned long long。
- 在任何有符号类型前面添加关键字signed,可以强调有符号类型的意图。例如,short、short in、signed short、sigened short和signed short int 表示同一种类型。
使用多种整数类型的原因
为什么说short类型“可能”比int类型占用的空间少,为什么说int类型“可能”比long类型占用的空间少呢?因为C语言只规定了short占用的存储空间不能多于int,long占用的存储空间不能少于int。这样规定在过去是为了适应不同的机器,而现在计算机普遍使用64位处理器,为了储存64位的整数,才引入了 long long类型。现在个人计算机上最常见的设置是,long long占64位,long占32位,short占16位,int占16位或者64位(依计算机的自然字长而定)。原则上,这四种类型代表四种不同的大小,但是在实际使用中,有些类型之间通常有重叠。
C标准对基本数据类型只规定了允许的最小大小。而int的类型那么多,在选择时候可以优先考虑unsigned类型。这种类型的数常用于技术,因为计不用负数,而且unsigned类型可以表示更大的正数。
如果一个数超出了int类型的取值范围,且在long类型的取值范围内,使用long类型。然而,对于那些long占用的空间int大的系统,使用long类型会影响运算速度。因此,如非必要,请不要使用long类型。此外,要注意一点,如果在long类型和int类型占用空间相同的机器上编写代码,当确实需要32位的整数时,应使用long类型而不是int类型,以便把程序移植到16位机后仍然可以正常工作。类似的,如果确实需要64位的整数,应该使用long long类型。
如果在int设置为32位的系统中要使用16位的值,应使用short类型以节省空间。通常,只有当程序使用相对于系统可用内存较大的整型数组时,才需要重点考虑节省空间的问题。使用short类型的另一个原因是,计算机中某些组件使用的硬件寄存器是16位。
long常量和long long常量
通常,程序代码使用的数字通常被储存位int类型,类似于100000超出int范围的大数字,编译器会将其视为long int类型(假设这种类型可以表示该数字),再假如数字超出long可表示的最大值,编译器则将其视为unsigned int类型,诸如此类。
整数溢出,举栗子:
#include<stdio.h>
int main()
{
int i = 214783647;
unsigned int j = 4294967295;
printf("%d %d %d\n", i, i+1, j+2);
printf("%u %u %u\n", j, j+1, j+2);
return 0;
}输出结果:

可以把无符号整数j看作是汽车的历程表。当达到它能表示的最大值时,会重新从起始点开始。整数i也是类似的情况。它们的主要区别是,在超过最大值时,unsigned int 类型的常量j从0开始;而int类型的变量i则从-2147483648开始。注意,当i超出(溢出)其相应类似所能表示的最大值时,系统并未通知用户。因此,在编程的时候必须注意这类问题。
溢出行文是未定义的行为,C标准并未定义有符号类型的溢出规则。以上描述的溢出行为比较有代表性,但是也可能会出现其他情况。
打印unsign int类型的值,用%u转换说明;打印long类型的值,使用%ld转换说明。
使用字符:char类型
char类型用于储存字符,但是从技术层面看,char是整数类型。因为char类型实际上是储存的是整数而不是字符。计算机使用数字编码来处理字符,即用特定的整数表示特定的字符。美国最常用的编码是ASCII编码,这里也是如此。
在ASCII编码中,整数65代表大写字母A,因此储存字母A实际上是储存的是整数65。
标准ASCII码的范围是0~127,只需7位二进制数即可表示。通常,char类型被定义为8位的储存单元,因此容纳标准ASCII码绰绰有余,许多其他系统还提供扩展ASCII码,也在8位的表示范围之内。一般而言,C语言会保证char类型足够大,以储存系统(实现C语言的系统)的基本字符集。
许多字符集都超过了127,例如中国汉字字符集(GB 2312),商用的统一码(Unicode) 创建了一个能表示世界范围内多种字符集的系统, 目前包含的字符已经超过110000个。
char变量的声明与其他变量相同,此处省略。
字符常量和初始化
将一个字符常量初始化成字母'A':
char grade = 'A';在C语言中,用单引号括起来的单个字符被称为字符常量(character constant)。编译器一旦发现'A',就会将其转换成对应 的代码值。单引号必不可少。
非打印字符
单引号只适用于字符、数字和标点符号,浏览ASCI表会发现,有些ASCⅡ字符打印不出来。例如,一些代表行为的字符(如,退格、换行、终端响铃或蜂鸣)。C语言提供了3种方法表示这些字符。
第1种方法前面介绍过一使用ASCI码。例如,蜂鸣字符的ASCIⅡ值是7,因此可以这样写:
char beep 7;第2种方法是,使用特殊的符号序列表示一些特殊的字符。这些符号序列叫作转义序列(escapsequence)。

现在,我们来仔细分析一下转义序列。使用C90新增的警报字符(a)是否能产生听到或看到的警报,取决于计算机的硬件,蜂鸣是最常见的警报(在一些系统中,警报字符不起作用)。C标准规定警报字符不得改变活跃位置。标准中的活跃位置(active position)指的是显示设备(屏幕、电传打字机、打印机等)中下一个字符将出现的位置。简而言之,平时常说的屏幕光标位置就是活跃位置。在程序中把警报字符输出在屏幕上的效果是,发出一声蜂鸣,但不会移动屏幕光标。
而接下来的转义字符\b、\f、\n、\r、\t和\v是常用的输出设备控制字符。
了解它们最好的方式是查看它们对活跃位置的影响。
- 换页符(\£)把活跃位置移至下一页的开始处:
- 换行符(\n)把活跃位置移至下一行的开始处:
- 回车符(\r)把活跃位置移动到当前行的开始处:
- 水平制表符(\t)将活跃位置移至下一个水平制表点(通常是第1个、第9个、第17个、第25个等字符位置):
- 垂直制表符(\v)把活跃位置移至下一个垂直制表点。
接下来的3个转义序列(\\、\'、\")用于打印\、'、"字符(由于这些字符用于定义字符常量,是printf()函数的一部分,若直接使用它们会造成混乱)。举栗子:
如果想打印下面一行代码:
Gramps sez,"a is a backslash."
应这样编写代码:
printf ("Gramps sez,\"a \is a backslash.\"\n");在这个例子中,为何没有用单引号把转义序列括起来?
无论是普通字符还是转义序列,只要是双引号括起来的字符集合,就无需用单引号括起来。双引号中的字符集合叫作字符串。注意,该例中的其他字符(G、x、a、m、p、s等)都没有用单引号括起来。与此类似,printf("Hello!\007\n");将打印字符并发出一声蜂鸣,而printf("Hello!7\n");则打印Hello!7。不是转义序列中的数字将作为普通字符被打印出来。
那么何时使用ASCII码又何时使用转义序列呢?如果要在转义序列(假设使用'\f')和ASCIⅡ码('\014')之间选择,请选择前者(即'f')。这样的写法不仅更好记,而且可移植性更高。·\f'在不使用 ASCII码的系统中,仍然有效。
如果要使用ASCIⅡ码,为何要写成\032'而不是032?首先,\032'能更清晰地表达程序员使用字符编码的意图。其次,类似032这样的转义序列可以嵌入C的字符串中,如printf("HelIo!\007\n");中就嵌入了\007。
打印字符
printf()函数用c指明待打印的字符。前面介绍过,一个字符变量实际上被储存为1字节的整数值。因此,如果用号d转换说明打印char类型变量的值,打印的是一个整数。而号c转换说明告诉printf()打印该整数值对应的字符。举栗子:
//显示字符的代码编号
#include <stdio.h>
int main()
{
char ch;
printf("Please enter a character.\n");
scanf_s("%c", &ch); /*用户输入字符*/
printf("The code for %c is %d.\n", ch, ch);
return 0;
}输出示例: 输出小写s,显示s对应的代码编号为115

运行该程序时,在输入字母后不要忘记按下Enter或Return键。随后,scanf()函数会读取用户输入的字符,&符号表示把输入的字符赋给变量ch。接着,printf()函数打印ch的值两次,第1次打印一个字符(对应代码中的号c),第2次打印一个十进制整数值(对应代码中的d)。注意,printf()函数中的转换说明决定了数据的显示方式,而不是数据的储存方式.

Bool类型 布尔类型
C99标准添加了Bool类型,用于表示布尔值,即逻辑值true和fa1se。因为C语言用值1表示true,值0表示false,所以Bool类型实际上也是一种整数类型。但原则上它仅占用1位存储空间,因为对0和1而言,1位的存储空间足够了。
可移植类型:stdint.h和inttypes.h
非常规知识,详情可以自行搜索。
Float、int和double
浮点类型能表示包括小数在内的更大范围的数,而浮点数的表示类似于科学计数法(即用小数乘以10的幂来表示数字)。该记数系统常用于表示非常大或非常小的数。举栗子:

C标准规定,float类型必须至少能表示6位有效数字,且取值范围至少是10的负37次方~10的37次方。前一项规定指float类型必须至少精确表示小数点后的6位有效数字,如33.333333。后一项规定用于方便地表示诸如太阳质量(2.030千克)、一个质子的电荷量(1.6e19库仑)或国家债务之类的数字。通常,系统储存一个浮点数要占用32位。其中8位用于表示指数的值和符号,剩下24位用于表示非指数部分(也叫作尾数或有效数)及其符号。
提供的另一种浮点类型是double(意为双精度)。double类型和f1oat类型的最小取值范围相同,但至少必须能表示10位有效数字。一般情况下,double占用64位而不是32位。一些系统将多出的32位全部用来表示非指数部分,这不仅增加了有效数字的位数(即提高了精度),而且还减少了舍入误差。另一些系统把其中的一些位分配给指数部分,以容纳更大的指数,从而增加了可表示数的范围。无论哪种方法,double类型的值至少有13位有效数字,超过了标准的最低位数规定。
第3种浮点类型是long double,以满足比double类型更高的精度要求。不过,C只保证long double类型至少与double类型的精度相同。
sizeof()函数
sizeof()是C语言的内置运算符,以字节为单位给出指定类型的大小。C99和C11提供%zd转换说明匹配sizeof的返回类型。一些不支持C99和C11的编译器可用%u或lu代替%zd。
四、字符串与格式化输入/输出
字符串
字符串(character string)是一个或多个字符的序列,如下所示:
"Do not go gentle into that good night"//
双引号不是字符串的一部分,双引号仅告知编译器它括起来的是字符串,正如单引号用于标识单个字符一样。
char类型数组和null字符
C语言没有专门用于储存字符串的变量类型,字符串都被储存在char类型的数组中。数组由连续的存储单元组成,字符串中的字符被储存在相邻的存储单元中,每个单元储存一个字符。
而数组末尾位置的字符\0。这是空字符(null character),C语言用它标记字符串的结束。空字符不是数字0,它是非打印字符,其ASII码值是0(或等价于)。C中的字符串一定以空字符结束,这意味着数组的容量必须至少比待存储字符串中的字符数多1。
数组
所以,什么是数组?可以把数组当作是一行连续的多个存储单元。更正式的说法是:数组是同类型数据元素的有序序列。
char name [40];name后面的方括号表明这是一个数组,方括号中的40表明该数组中的元素数量。char表明每个元素的类型。举栗子说明声明变量和数组的差别:

字符串看上去比较复杂,还必须先创建一个数组,把字符串中的字符逐个放入数组,还要记得在末尾加上一个\0。不过还好,计算机可以自己处理这些细节。
使用字符串:
运行以下程序,感受使用字符串的过程:
/*praisel.c--使用不同类型的字符串*/
#include <stdio.h>
#define PRAISE "You are an extraordinary being."
int main(){
char name[40];
printf("What's your name?\n");
scanf("%s", name);
printf("Hello,%s,\n%s\n", name, PRAISE);
return 0;
}%s告诉printf()打印一个字符串。而%s出现了两次,因为程序要打印两个字符串:一个储存在name数组中;一个由宏定义PRAISE来表示。其输出如下表示:
What's your name?
Angela Plains
Hello,Angela.
You are an extraordinary being.你不用亲自把空字符放入字符串尾,scanf()在读取输入时就已完成这项工作。也不用在字符串常量PRAISE末尾添加空字符。稍后我们会解释#define指令,现在先理解PRAISE后面用双引号括起来的文本是一个字符串。编译器会在末尾加上空字符。注意(这很重要),scanf()只读取了Angela Plains中的Angela,它在遇到第1个空白(空格、制表符或换行符)时就不再读取输入。因此,scanf()在读到Angela和Plains之间的空格时就停止了。一般而言,根据%s转换说明,scanf()只会读取字符串中的一个单词,而不是一整句。
字符串和字符
字符串常量"x"和字符常量'x'不同。区别之一在于'x'是基本类型(char),而"x"是派生类型(char数组):区别之二是"x"实际上由两个字符组成:'x'和空字符\0。

strlen()函数
这里我们补充一个数组常用的函数,上面我们提到了sizeof()运算符,它以字节为单位给出对象的大小。而strlen()函数给出字符串中的字符长度。因为1字节储存一个字符,可能认为把两种方法应用于字符串得到的结果相同,但事实并非如此。举栗子:
/*praise2.c*/
//如果编译器不识别%zd,尝试换成%u或%lu.
#include <stdio.h>
#include <string.h>
/*提供strlen()函数的原型*/
#define PRAISE "You are an extraordinary being."
int main()
{
char name[40];
printf("What's your name?\n");
scanf("%s", name);
printf("Hello,%s,%s\n", name, PRAISE);
printf("Your name of %zd letters occupies %zd memory cells.\n",
strlen(name), sizeof name);
printf("The phrase of praise has %zd letters ",
strlen(PRAISE));
printf("and occupies zd memory cells.\n", sizeof PRAISE);
return 0;
}如果使用ANSI C之前的编译器,必须移除这一行:
#include <string.h>
string.h头文件包含多个与字符串相关的函数原型,包括strlen()。(顺带一提,一些ANSI之前的UNIX系统用strings.h代替string.h,其中也包含了一些字符串函数的声明)。
一般而言,C把函数库中相关的函数归为一类,并为每类函数提供一个头文件。例如,printf()和scanf()都隶属标准输入和输出函数,使用stdio.h头文件。string.h头文件中包含了strlen()函数和其他一些与字符串相关的函数(如拷贝字符串的函数和字符串查找函数)。
注意,上述例子使用了两种方法处理很长的printf()语句。第1种方法是将printf()语句分为两行(可以在参数之间断为两行,但是不要在双引号中的字符串中间断开):第2种方法是使用两个printf()语句打印一行内容,只在第2条printf()语句中使用换行符(\n)。a运行该程序,其交互输出如下:
What's your name?
Jack
Hello,Jack.You are an extraordinary being.
Your name of 4 letters occupies 40 memory cells.
The phrase of praise has 31 letters and occupies 32 memory cells.
sizeof运算符报告,name数组有40个存储单元。但是,只有前4个单元用来储存Jack,所以strlen()得出的结果是4.name数组的第5个单元储存空字符,strlen()并未将其计入。

对于PRAISE,用strlen()得出的也是字符串中的字符数(包括空格和标点符号)。
然而,sizeof运算符给出的数更大,因为它把字符串末尾不可见的空字符也计算在内。该程序并未明确告诉计算机要给字符串预留多少空间,所以它必须计算双引号内的字符数。
常量和C预处理器
有一个很常见的常量是圆周率派pi=3.14115926
circumference = 3.14159 * diameter; 该例中,输入实际值便可使用pi这个常量。然而这种情况使用符号常量(symbolic constant)会更好。也就是说,使用下面的语句,计算机稍后会用实际值完成替换:
circumference = pi * diameter;
为什么使用符号常量更好?首先,常量名比数字表达的信息更多。请比较以下两条语句:
owed = 0.015 * housevalue;
owed = taxrate * housevalue;
如果阅读一个很长的程序,第2条语句所表达的含义更清楚。
另外,程序中的多处使用某个常量有时需要改变它的值。毕竟,税率通常是浮动的。如果程序使用符号常量,则只需更改符号常量,不用在程序中查找使用常量的地方,然后逐一修改。
那么,如何创建符号常量?方法之一是声明一个变量,然后将该变量设置为所需的常量。可以这样写:
float taxrate;
taxrate = 0.015;这样做提供了一个符号名,但是taxrate是一个变量,程序可能会无意间改变它的值。C语言还提供了一个更好的方案。即C预处理器也可用来定义常量。只需在程序顶部添加下面一行:
#define预指令
#define TAXRATE 0.015编译程序时,程序中所有的TAXRATE都会被替换成0.015。这一过程被称为编译时替换(compile-timesubstitution)。在运行程序时,程序中所有的替换均已完成。通常,这样定义的常量也称为明示常量(manifest constant).注意,末尾不用加分号,因为这是一种由预处理器处理的替换机制。此处TAXRATE要用大写,因为用大写表示符号常量是C语言一贯的传统。这样,在程序中看到全大写的名称就立刻明白这是一个符号常量,而非变量。大写常量只是为了提高程序的可读性,即使全用小写来表示符号常量,程序也能照常运行。尽管如此,初学者还是应该养成大写常量的好习惯。
还有一个不常用的命名约定,即在名称前带c或k前缀来表示常量(如,c_leve1或k_line)。符号常量的命名规则与变量相同。可以使用大小写字母、数字和下划线字符,首字符不能为数字。
此外,#define指令还可以定义字符和字符串常量,前者使用单引号,后者使用双引号。
#define BEEP '\a'
#define TEE 'T'
#define ESC '033'
#define OOPS "Now you have done it!"切记#define预指令不需要等号!
/*错误的格式*/
#define TOES = 20
如果这样做,替换TOES的是= 20,而不是20。这种情况下,下面的语句:
digits = fingers + TOES;
将被转换成错误的语句:
digits = fingers + = 20;const限制符
C90标准新增了const关键字,用于限定一个变量为只读。(变量非常量)
const int MONTHS = 12;
//MONTHS在程序中不可更改,值为12.这使得MONTHS成为一个只读值。也就是说,可以在计算中使用MONTHS,可以打印12,但是不能更改MONTHS的值。const用起来比#define更灵活,后面讨论与const相关的内容。
明示常量
C头文件limits.h和float.h分别提供了与整数类型和浮点类型大小限制相关的详细信息。
每个头文件都定义了一系列供实现使用的明示常量。例如,limits.h头文件包含以下类似的代码:
#define INT MAX 32767
#define INT MIN -32768 这些明示常量代表int类型可表示的最大值和最小值。
如果系统使用32位的int,该头文件会为这些明示常量提供不同的值。如果在程序中包含limits.h头文件,就可编写下面的代码:
printf("Maximum int value on this system =&d\n",INT MAX); 如果系统使用4字节的int,limits.h头文件会提供符合4字节int的INT MAX和INT MIN。
下图列出了limits.h中能找到的一些明示常量:

类似地,float.h头文件中也定义一些明示常量,如FLT DIG和DBL DIG,分别表示float类型和double类型的有效数字位数。下表列出了float.h中的一些明示常量(可以使用文本编辑器打开并查看系统使用的float.h头文件)。表中所列都与float类型相关。把明示常量名中的LT分别替换成DBL和LDBL,即可分别表示double和1 ong double类型对应的明示常量(表中假设系统使用2的幂来表示浮点数)。

//defines.c--使用limit.h和float头文件中定义的明示常量
#include <stdio.h>
#include <limits.h> //整型限制
#include <float.h> //浮点型限制
int main()
{
printf("Some number limits for this system:\n");
printf("Biggest int: &d\n", INT MAX);
printf("Smallest longlong: $11d\n", LLONG MIN);
printf("One byte &d bits on this system.\n", CHAR BIT);
printf("Largest double:e\n", DBL MAX);
printf("Smallest normal float:%e\n", FLT MIN);
printf("float precision &d digits\n", FLT DIG);
printf("float epsilon=号e\n", FLT EPSILON);
return 0;
}printf()和scanf()& I/O函数
printf()函数和scanf()函数能让用户可以与程序交流,它们是输入/输出函数,或简称为I/O函数。它们不仅是C语言中的I/O函数,而且是最多才多艺的函数。过去,这些函数和C库的一些其他函数一样,并不是C语言定义的一部分。最初,C把输入/输出的实现留给了编译器的作者,这样可以针对特殊的机器更好地匹配输入/输出。后来,考虑到兼容性的问题,各编译器都提供不同版本的printf()和scanf()。尽管如此,各版本之间偶尔有一些差异。C90和C99标准规定了这些函数的标准版本,本书亦遵循这一标准。
虽然printf()是输出函数,scanf()是输入函数,但是它们的工作原理几乎相同。两个函数都使用格式字符串和参数列表。
printf()
请求printf()函数打印数据的指令要与待打印数据的类型相匹配。例如,打印整数时用%d,打印字符时使用%c。这些符号被称为转换说明(conversion specification),它们指定了如何把数据转换成可显示的形式。

printf()函数的格式:
printf(格式字符串,待打印项1,待打印项2,...);待打印项1、待打印项2等都是要打印的项。它们可以是变量、常量,甚至是在打印之前先要计算的表达式。格式字符串应包含每个待打印项对应的转换说明。例如,考虑下面的语句:
printf("The &d contestants ate $f berry pies.\n",number,pies);格式字符串是双引号括起来的内容。上面语句的格式字符串包含了两个待打印项number和poes对应的两个转换说明。格式字符串包含两种不同的信息:
- 实际要打印的字符;
- 转换说明;


格式字符串中的转换说明一定要与后面的每个项相匹配,若忘记这个基本要求会导致严重的后果。千万别写成下面这样:
printf("The score was Squids %d,slugs %d.\n",score1);
这里,第2个%d没有对应任何项。不同的系统导致的结果也不同。不过,出现这种问题最好的状况是得到无意义的值。
如果只打印短语或句子,就不需要使用任何转换说明。如果只打印数据,也不用加入说明文字。
printf("Farewell! thou art too dear for my possessing,\n");
printf("%c%d\n" , '$' , 2 * cost);注意第2条语句,待打印列表的第1个项是一个字符常量,不是变量:第2个项是一个乘法表达式。这说明printf()使用的是值,无论是变量、常量还是表达式的值。由于printf()函数使用%符号来标识转换说明,因此打印%符号就成了个问题。如果单独使用一个%符号,编译器会认为漏掉了一个转换字符。解决方法很简单,使用两个号%号就行了:
pc = 2 * 6:
printf("Only %d%% of Sally's gribbles were edible.\n", pc);
输出结果:Only 12% of Sally's gribbles were edible.printf()的转换说明修饰符

注意 类型可移植性
sizeof运算符以字节为单位返回类型或值的大小。这应该是某种形式的整数,但是标准只规定了该值是无符号整数。在不同的实现中,它可以是unsigned int、unsigned long甚至是unsigned longlong。因此,如果要用printf()函数显示sizeof表达式,根据不同系统,可能使用%u、%lu或%llu。这意味着要查找你当前系统的用法,如果把程序移植到不同的系统还要进行修改。鉴于此,C提供了可移植性更好的类型。首先,stddef.h头文件(在包含stdio.h头文件时已包含其中)把size_t定义成系统使用sizeof返回的类型,这被称为底层类型(underlying type)。其次,printf()使用z修饰符表示打印相应的类型。同样,C还定义了ptrdiff_t类型和t修饰符来表示系统使用的两个地址差值的底层有符号整数类型。
注意 float参数的转换
对于浮点类型,有用于double和long double类型的转换说明,却没有float类型的。这是因为在K&RC中,表达式或参数中的float类型值会被自动转换成double类型。一般,ANSIC不会把float自动转换成double。然而,为保护大量假设float类型的参数被自动转换成double的现有程序,printf()函数中所有float类型的参数(对未使用显式原型的所有C函数都有效)仍自动转换成double类型。因此,无论是K&RC还是ANSI C,都没有显示float类型值专用的转换说明。

字段宽度程序
//defines.c--使用limit.h和float头文件中定义的明示常量
#include <stdio.h>
#define PAGES 959
int main()
{
printf("*%d*\n", PAGES);
printf("*%2d*\n", PAGES);
printf("*%10d*\n", PAGES);
printf("*%-10d*\n", PAGES);
return 0;
}
输出结果;
*959*
*959*
* 959*
*959 *第1个转换说明%d不带任何修饰符,其对应的输出结果与带整数字段宽度的转换说明的输出结果相同。在默认情况下,没有任何修饰符的转换说明,就是这样的打印结果。第2个转换说明是%2d,其对应的输出结果应该是2字段宽度。因为待打印的整数有3位数字,所以字段宽度自动扩大以符合整数的长度。第3个转换说明是%10d,其对应的输出结果有10个空格宽度,实际上在两个星号之间有7个空格和3位数字,并且数字位于字段的右侧。最后一个转换说明是号-10d,其对应的输出结果同样是10个空格宽度,-标记说明打印的数字位于字段的左侧。熟悉它们的用法后,能很好地控制输出格式。试着改变PAGES的值,看看编译器如何打印不同位数的数字。
浮点字节宽度输出
//floats.c--一些浮点型修饰符的组合
#include <stdio.h>
int main()
{
const double RENT = 3852.99;//const变量
printf("*%f*\n", RENT);
printf("*%e*\n", RENT);
printf("*%4.2f*\n", RENT);
printf("*%3.1f*\n", RENT);
printf("*%10.3f*\n", RENT);
printf("*%10.3E*\n", RENT);
printf("*%+4.2f*\n", RENT);
printf("*%010.2f*\n", RENT);
return 0;
}
输出结果如下:
*3852.990000*
*3.852990e+03*
*3852.99*
*3853.0*
* 3852.990*
* 3.853E+03*
*+3852.99*
*0003852.99*本例的第1个转换说明是%f。在这种默认情况下,字段宽度和小数点后面的位数均为系统默认设置,即字段宽度是容纳带打印数字所需的位数和小数点后打印6位数字。
第2个转换说明是%e。默认情况下,编译器在小数点的左侧打印1个数字,在小数点的右侧打印6个数字。这样打印的数字太多!解决方案是指定小数点右侧显示的位数,程序中接下来的4个例子就是这样做的。请注意,第4个和第6个例子对输出结果进行了四舍五入。另外,第6个例子用E代替了e。
第7个转换说明中包含了+标记,这使得打印的值前面多了一个代数符号(+)。0标记使得打印的值前面以0填充以满足字段要求。注意,转换说明%010.2f的第1个是标记,句点(。)之前、标记之后的数字(本例为10)是指定的字段宽度。
字符串格式输出
/*stringf.c -- 字符串格式*/
#include <stdio.h>
#define BLURB "Authentic imitation!"
int main()
{
printf("[%2s]\n", BLURB);
printf("[%24s]\n", BLURB);
printf("[%24.5s]\n", BLURB);
printf("[%-24.5s]\n", BLURB);
return 0;
}
输出结果:
[Authentic imitation!]
[ Authentic imitation!]
[ Authe]
[Authe ]注意,虽然第1个转换说明是号2S,但是字段被扩大为可容纳字符串中的所有字符。还需注意,精度限制了待打印字符的个数。.5告诉printf()只打印5个字符。另外,-标记使得文本左对齐输出。
转换说明的意义
下面深入探讨一下转换说明的意义。转换说明把以二进制格式储存在计算机中的值转换成一系列字符(字符串)以便于显示。例如,数字76在计算机内部的存储格式是二进制01001100.%d转换说明将其转换成字符7和6,并显示为76:%×转换说明把相同的值(01001100)转换成十六进制记数法4c:%c转换说明把01001100转换成字符L。因为在计算机底层都是以二进制保存的,所以相同的二进制数可以通过转换说明来表示不同的字符,这样就增加了可表示数的可能性。
转换(conversion)可能会误导读者认为原始值被转替换成转换后的值。实际上,转换说明是指翻译说明,%d的意思是“把给定的值翻译成十进制整数文本并打印出来”。
转换不匹配
前面强调过,转换说明应该与待打印值的类型相匹配。通常都有多种选择。例如,如果要打印一个int类型的值,可以使用%d、%x或%o。这些转换说明都可用于打印int类型的值,其区别在于它们分别表示一个值的形式不同。类似地,打印double类型的值时,可使用%f、%e或%g。
转换说明与待打印值的类型不匹配会怎样?上一章中介绍过不匹配导致的一些问题。匹配非常重要,一定要牢记于心。下面程序演示了一些不匹配的整型转换示例。
/*intconv.c--一些不匹配的整型转换*/
#include <stdio.h>
#define PAGES 336
#define WORDS 65618
int main()
{
short num = PAGES;
short mnum = -PAGES;
printf("num as short and unsigned short: %hd %hu\n", num, num);
printf("-num as short and unsigned short:%hd %hu\n", mnum, mnum);
printf("num as int and char: %d %c\n", num, num);
printf("WORDS as int,short,and char: %d %hd %c\n", WORDS, WORDS, WORDS);
return 0;
}
输出结果:
num as short and unsigned short: 336 336
-num as short and unsigned short:-336 65200
num as int and char: 336 P
WORDS as int,short,and char: 65618 82 R 输出的第1行,num变量对应的转换说明%hd和%hu输出的结果都是336。这没有任何问题。然而,第2行mnum变量对应的转换说明%u(无符号)输出的结果却为65200,并非期望的336。这是由于有符号short int类型的值在我们的参考系统中的表示方式所致。
首先,short int的大小是2字节:其次,系统使用二进制补码来表示有符号整数。这种方法,数字0~32767代表它们本身,而数字32768~65535则表示负数。其中,65535表示-1,65534表示-2,以此类推。因此,-336表示为65200(即,65536-336)。所以被解释成有符号int时,65200代表-336:而被解释成无符号int时,65200则代表65200。一定要谨慎!一个数字可以被解释成两个不同的值。尽管并非所有的系统都使用这种方法来表示负整数,但要注意一点:别期望用%u转换说明能把数字和符号分开。
第3行演示了如果把一个大于255的值转换成字符会发生什么情况。在我们的系统中,short int是2字节,char是1字节。当printf()使用c打印336时,它只会查看储存336的2字节中的后1节。这种截断相当于用一个整数除以256,只保留其余数。在这种情况下,余数是80,对应的ASCII值是字符P。用专业术语来说,该数字被解释成“以256为模”(modulo256),即该数字除以256后取其余数。

最后,我们在该系统中打印比short int类型最大整数(32767)更大的整数(65618)。这次,计算机也进行了求模运算。在本系统中,应把数字65618储存为4字节的int类型值。用hd转换说明打印时,printf()只使用最后2个字节。这相当于65618除以65536的余数。这里,余数是82。鉴于负数的储存方法,如果余数在32767~65536范围内会被打印成负数。对于整数大小不同的系统,相应的处理行为类似,但是产生的值可能不同。