本文共计2820字,预计阅读时间6分钟
目录
进程的缺陷
每个进程具有独立的内存空间,因此在创建和复制进程时将给操作系统带来较大的负担。这些开销除了来自创建进程、进程间数据交换外,还有来自“上下文切换”(Context Switch)的开销,而“上下文切换”所耗费的资源也是最多的。
上下文切换 , 其实际含义是任务切换, 或者CPU寄存器切换。当多任务内核决定运行另外的任务时, 它保存正在运行任务的当前状态, 也就是CPU寄存器中的全部内容。这些内容被保存在任务自己的堆栈中, 入栈工作完成后就把下一个将要运行的任务的当前状况从该任务的栈中重新装入CPU寄存器, 并开始下一个任务的运行, 这一过程就是“上下文切换”。
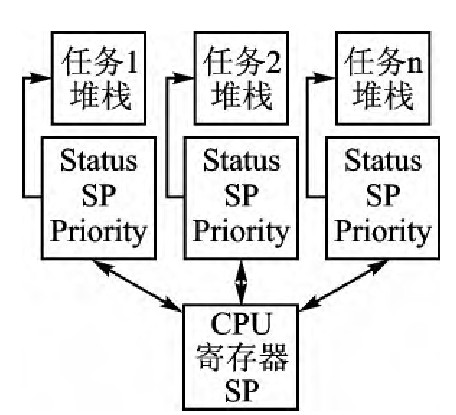
为了将进程的优点保留,并且改进进程所带来的空间以及转移数据的时间消耗,人们设计了“线程”。
线程的创造减少了由进程带来的各种影响,并且线程相比于进程有以下优点:
- 线程的创建和上下文切换比进程的创建和上下文切换更快。
- 线程间交换数据时无需引入额外技术。
线程和进程的差异
每个进程内存空间都由保存全局变量的数据区、堆(由动态分配函数malloc等所提供的空间)和栈(函数运行时所产生的)所构成。每个进程都拥有这种独立空间,其模型如下图所示:

线程则基于进程的设计模型,将多条代码的执行流集中在数据区和堆中,而隔开栈区域,设计了以下模型结构:

多个线程将可以共享数据区和堆。
因此我们可以将进程和线程的定义大致总结如下:
- 进程:操作系统资源分配的最小单元,是线程的容器
- 线程:于进程中构成单独执行流的单位,是CPU调度的基本单位
线程的创建和执行流程
pthread_create
线程具有单独的执行流,因此需要设计专门的main函数,并且需要请求操作系统在执行流中执行该函数。
线程的创建,可以引用下列头文件和函数:
#include <pthread.h>
int pthread_create (pthread_t * restrict thread , const pthread_attr_t * restrict attr , void * (* start_routine)(void * ), void * restrict arg);
// 成功时返回 0, 失败时返回其他值。
/* 参数含义
thread: 保存新创建线程 ID 的变量地址值。线程与进程相同,也需要用于区分不同线程的ID。
attr: 用于传递线程属性的参数,传递 NULL时,创建默认属性的线程。
start routïne: 相当于线程 main 函数的、在单独执行流中执行的函数地址值(函数指针) 。
arg: 通过第三个参数传递调用函数时包含传递参数信息的变量地址值。
*/示例:
#include <stdio.h>
#include <pthread.h>
#include <unistd.h>
void *thread_func1(void *arg);
int main(int argc, char *argv[])
{
pthread_t t_id; // 线程的id,类比与进程号
int thread_cycle = 10;
if (pthread_create(&t_id, NULL, thread_func1, (void *)&thread_cycle /*注意要强转*/) != 0)
{
puts("pthread creation error");
return -1;
};
sleep(11); //让Main函数停留 11 s,一般而言,等待事件设置的都比理论上的多1-2s,以保证能够执行完整
puts("thread execution end");
return 0;
}
void *thread_func1(void *arg)
{
int i;
int cnt = *((int *)arg); // 将指向void类型的指针类型转换为指向int类型的指针,然后再对其进行取值
for (i = 0; i < cnt; i++)
{
sleep(1);
printf("cycle: %d \n", i);
}
return NULL;
}运行结果:
如果将上述代码main函数中的sleep修改为比线程理论执行时间总和要低的数值时,将会导致执行流的不完整。
但是sleep这个时间是客观时间,即按照现实时间所预估的。计算机执行线程中的函数时未必会按照这个时间来进行,那么有没有更加精准的方法来控制线程执行流的时间片呢?
pthread_join
我们可以尝试用 pthread_join 这个函数,其结构及引用头文件如下:
# include <pthread.h>
int pthread_join(pthread_t thread , void ** status);
//成功时返回 0 ,失败时返回其他值。
/* 参数含义
thread:欲操作的线程,以该线程的id传入。
status:保存该线程 main 函数所返回的指针变量地址值 。
*/示例:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <pthread.h>
#include <unistd.h>
void* thread_func2(void *arg);
int main(int argc, char *argv[])
{
pthread_t t_id;
int thread_cycle= 5;
void * thr_ret;
if(pthread_create(&t_id, NULL, thread_func2, (void*)&thread_cycle)!=0)
{
puts("pthread creation error");
return -1;
};
//等待线程t_id的执行完毕。完毕后该线程返回的数据将存放在thr_ret中
if(pthread_join(t_id, &thr_ret)!=0)
{
puts("pthread_join error");
return -1;
};
//将线程执行完后的返回值输出。执行这条指令时线程已结束。
printf("Thread return message: %s \n", (char*)thr_ret);
free(thr_ret);
return 0;
}
void* thread_func2(void *arg)
{
int i;
int cnt=*((int*)arg);
char * msg=(char *)malloc(sizeof(char)*20);
strcpy(msg, "Hello, I’m thread but now I am dead and buried. \n");
for(i=0; i<cnt; i++)
{
sleep(1);
printf("cycle: %d \n",i);
}
return (void*)msg; //这是
}运行结果:

当循环结束后,也就是理论的5s钟后,线程便结束并返回数值了。此时,该变量在pthread_join函数之后被正确输出出来。很明显,这种方法相较于手动用sleep预估,可以更加精确的把控时间。