
一、说明
二、正确完成实时 AI:及时大规模洞察和行动
在我之前的博客文章中,我列出了当前人工智能架构的挑战以及它们对数据科学家和开发人员施加的固有限制。这些挑战阻碍了我们利用实时数据增长、满足消费者日益增长的期望、适应日益动态的市场以及提供经过验证的实时业务成果的能力。简而言之,即使人工智能带来了一些巨大的好处,但由于以下原因,它仍然不足:
- 基于广泛的人口统计数据的定向预测,无法提供改变行为和推动影响所需的洞察力。
- 批处理和历史分析无法跟上快速发展的消费者需求。
- 时间、成本和复杂性延迟了我们学习新模式和采取行动以满足不断变化的市场需求的速度。
- 团队之间缺乏可见性以及各种工具堆栈,这进一步使 AI 从业者在尝试构建提供价值的应用程序时变得复杂和延迟。
简而言之,这种将数据引入ML / AI系统的过时模型无法以企业和消费者所需的速度提供所需的结果类型。但是,有一种更好的方法可以通过 AI 提供实时影响并推动价值。
现在,让我们探讨一下组织如何超越这些限制,加入将ML引入数据的企业行列,以提供更智能的应用程序,并在确切的时间进行更准确的AI预测,从而产生最大的业务影响。
三、重新思考数据架构,利用 AI 推动影响力
借助实时 AI,开发人员现在可以构建 AI 驱动的应用程序,这些应用程序不仅可以预测行为,还可以驱动操作——在它可能产生最大影响的确切时刻。有了实时人工智能,您现在有了各种可能性——从改变个人层面的消费者行为,到洞察用户意图和背景,再到采取预防措施来保护制造正常运行时间和供应链弹性,无所不包。根据对用户的广泛人口统计理解,远离你所说的世界,这是将流失的用户百分比,并转移到一个模型,在这个模型中,你可以了解特定的个人并推动决策,在当下,增加参与度。
实现这种转变需要改变人工智能系统的构建方式。今天的大多数人工智能都是基于大量的历史数据,每天或有时每周分批收集。其结果是基于广泛的模式和人口统计数据对历史行为的后视镜观察。借助实时 AI,您可以在一系列事件展开时连接到它们,从而可以在它们发生时立即发现关键时刻、信号和结果。其结果是对消费者行为、安全威胁、系统性能等的高度个性化理解,以及干预以改变结果的能力。
例如,音乐应用程序的目标不仅仅是提供正确的内容,而是提供个性化、引人入胜的内容,让用户停留更长时间,探索新的音乐领域、新的艺术家和新的流派,并让他们如此参与,以至于他们续订了订阅。该应用程序需要的不仅仅是基于用户的历史记录,而是基于用户在积极参与时在应用程序中的意图来提供音乐。
想想那些整个早上都在听着有助于提高生产力的器乐的听众,但现在是中午,他们要去健身房。他们想要音乐来帮助激励他们。如果应用程序在用户想要锻炼碧昂斯时继续提供贝多芬,那么应用程序就达不到要求,给用户带来了搜索的负担和潜在的挫败感。
那么,当用户在应用程序中时,应用程序如何检测意图的转变呢?这可以通过实时行为和行动来揭示。可能是用户留下了他们一直在听的歌曲,并根据排名算法滚动选择,但没有进行选择。然后,用户转到应用提供的轮播之一,但同样不会选择任何选项,因为它们都是播客。也许他们会播放他们旧的锻炼播放列表中的一首歌。此外,背景很重要;它可以从诸如星期几或一天中的时间甚至用户的位置等因素中收集。现在,有了意图和上下文,实时 ML 模型可以更准确地预测当前会话中所需的内容。
部署到应用程序后,实时 AI 依赖于功能新鲜度和低延迟 - 功能更新时间以及应用程序随后可以多快采取行动。正确的基础架构消除了响应滞后,并通过实时计算这些功能来更有效地利用资源,以便仅针对活动用户进行预测。这种体验在听众需要时为他们提供了他们需要的东西,这将推动参与度和订阅续订的最终目标。
四、灵活性和响应能力
实时 AI 是为速度和规模而构建的;它能够在正确的时间在正确的基础架构上交付正确的数据。这反过来又可以在上下文中捕获机会,根据历史和实时数据训练模型,以做出更准确、更及时的决策。
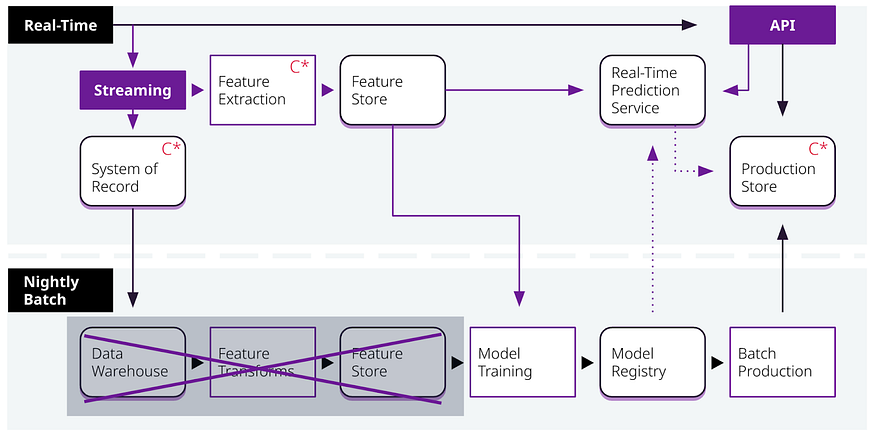
在最先进的情况下,实时 AI 可以监控 ML 模型的性能。如果模型的性能下降,则会触发自动重新训练。或者,可以训练“影子”模型,如果它们开始比生产中的模型表现更好,则可以将它们换成性能不佳的模型。
实时人工智能还可以更轻松地确保所有人口统计数据得到平等对待,从而允许监控和实时调整意外后果的能力。想象一下,生产中的模型开始通过公平性和偏见测试。在实时中,企业可以将模型从生产中翻转出来,并回退到基于规则的系统或代表业务标准和准则的模型。这种方法可提供动态变化的高风险环境中所需的灵活性和响应能力。
五、减少时间、成本和复杂性
传统人工智能的主要局限性之一是与数据传输和存储相关的大量工作和成本。相比之下,将 ML 功能引入数据本身可以通过消除这些数据传输来节省时间、成本和复杂性,因为通过简化的架构,您可以获得一个环境来处理事件数据、功能和模型,从而即时大规模摄取数据。此外,通过简化复杂性并提高特征和训练数据集沿袭的可理解性,可以提高速度和生产力。换句话说,可以更清晰、更清楚地了解跨多个管道、湖泊、视图和转换所发生的情况。通过访问直接数据源,您可以加快理解速度,尤其是在提升团队或个人能力时。
由于许多客户并非每天都活跃,因此无需在整个客户群中生成每日预测,从而节省了更多的成本。例如,如果一个组织使用批处理系统,并且每天有 100,000 个活跃用户,而每月有 100 亿个活跃用户,则没有必要每晚重新评分 100 亿个客户。这样做会增加不必要的大量成本。存储这些数据所产生的成本不断增加。
重新训练模型以合并行为更改需要保留或能够重现每个训练数据集,以实现故障排除和审核。为了减少随时间推移复制和存储的数据量,每次重新训练模型时,都应该能够访问数据的原始、未转换版本,并能够使用训练期间使用的特征版本重现训练数据集。这对于批处理系统来说是非常困难的,因为数据已经经历了跨多个系统和语言的多次转换。在实时系统中,直接从原始事件中表达用于训练和生产的完整功能,可以减少通常需要存储在多个位置的所有数据的重复量。
将 AI/ML 引入数据源会创建表达转换的单一方法。您现在可以知道您已连接到正确的源,您知道这是转换的确切定义,并且您可以在几行代码中更简洁地表达数据转换中所需的内容 - 而不是管道到管道到管道,这些多次传输涉及混乱。
六、减少摩擦和焦虑
正如我在之前的博客文章中指出的那样,跨越数据、ML 和应用程序堆栈的团队成员通常无法对 ML 项目进行广泛的可见性或深入理解。这些工具根据团队成员在堆栈中的位置而有很大差异。
这些孤岛给流程注入了摩擦和混乱,并围绕诸如“这是否准备好生产了吗?“一旦我们真正投入生产,这能奏效吗?”“或者,”尽管投入了数百万美元,但这些模式是否只能产生最小的影响——远远达不到提供价值的承诺或愿景?
将 AI/ML 引入数据可实现具有一组抽象的统一接口,以支持训练和生产。相同的特征定义可以生成任意数量的训练/测试数据集,并使特征存储与新数据流保持最新。此外,使用声明性框架可以导出功能定义及其所依赖的资源定义,以将内容签入代码存储库或 CI/CD 管道,并在不同区域中使用新数据启动新环境,而无需将数据传出该区域。这使得集成最佳实践变得容易,简化了测试,并缩短了学习曲线。这也本质上降低了摩擦,提供了更高的可见性,并通过更标准化的格式,更清楚地了解特定代码集中正在发生的事情。
七、正确完成实时 AI
实时 AI 解决方案将大规模实时数据与集成机器学习整合到专为开发人员构建的完整开放数据堆栈中,这是一种新方法。正确的堆栈和正确的抽象,具有令人难以置信的前景,可以创建新一代应用程序,从而推动更准确的业务决策、预测性操作以及更具吸引力、更具吸引力的消费者体验。这有可能以一种除了少数几家企业之外所有人都无法实现的方式释放人工智能的价值和承诺。这将产生对各种形式的大规模数据的即时访问。借助集成智能,实时 AI 将为全球分布式运营、数据和用户提供时效性洞察。
在即将发布的博客文章中,我将讨论Apache Cassandra®在这个实时AI堆栈中的关键作用,以及您可以从DataStax期待的一些令人兴奋的新事物。