1. 引言
前序博客有:
- Polygon Miden:扩展以太坊功能集的ZK-optimized rollup
- Polygon Miden zkRollup中的UTXO+账户混合状态模型
- Polygon Miden交易模型:Actor模式 + ZKP => 并行 + 隐私
在Polygon Miden交易模型:Actor模式 + ZKP => 并行 + 隐私中已指出,Polygon Miden中的交易,同时支持:
- 并行计算
- 客户端证明
- 公开智能合约
Polygon Miden的功能集需要一种全新的方法来捕捉网络状态,该方法组合了:
- 以太坊等基于账户的系统 的状态模型
- 与 比特币和Zcash等基于UTXO的系统 的状态模型
相结合。
本文将介绍Polygon Miden的状态模型的设计和实现,以及该新架构如何在不牺牲隐私或吞吐量的情况下处理普遍存在的区块链状态膨胀问题。
Polygon Miden的愿景是:
- 数百万用户将同时使用Polygon Miden上的应用程序。
因此,Polygon Miden被设计成一个可作为可持续价值层的rollup。
Polygon Miden 预计将于2023年Q4推出公共测试网。其核心目标是:
- 扩展EVM的功能集,以创建一个前瞻性的扩容解决方案,该解决方案仍然继承以太坊的安全性。
2. 何为状态?为何会状态膨胀?
何为状态?
状态是对一切情况的描述。在区块链上,state描述了谁在某个时间点拥有什么,以及所有智能合约在该时间点的状况。
Polygon Miden的状态定义,以及,其它rollup和智能合约区块链的状态定义均如此。
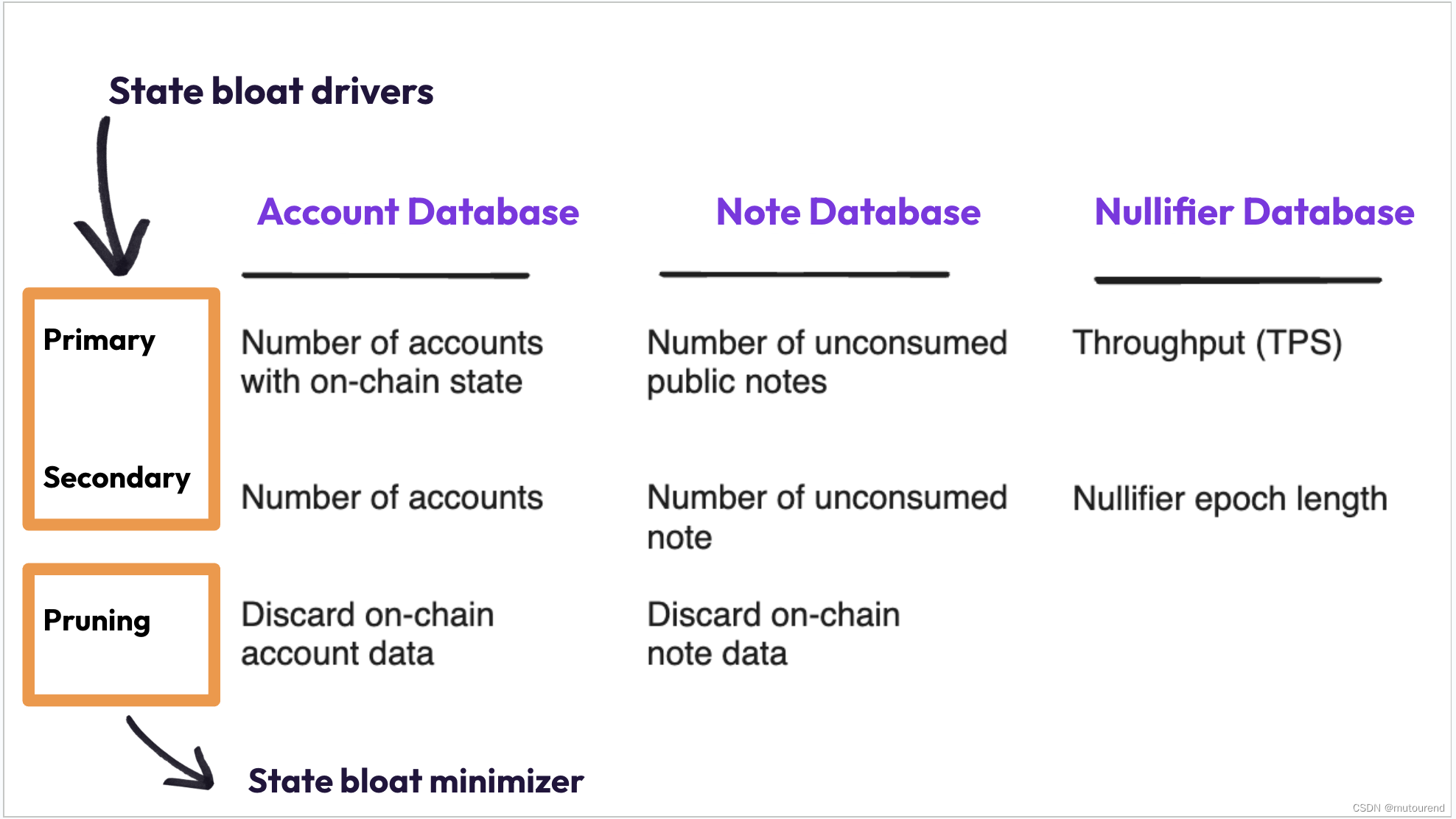
区块链使用得越多,其状态就越大。这个问题被称为状态膨胀。
- 在以太坊基于账户的状态模型中,随着越来越多的人使用该链,账户数量自然会增长,而且不能删除这些账户。
- 状态膨胀带来了危险的后果:
- 减缓了网络的速度并使网络集中,因为应对不断增长的状态的要求也在提高。最终,每个公共区块链都需要解决状态的问题。
对于Polygon Miden,一个核心考虑因素是:
- 使内置状态膨胀最小化。
- 实际上,其目标是:不需要存储整个状态的情况下,实现产块和区块验证。
- 对于区块验证:可通过零知识(ZK)证明实现的。这就是ZK的全部意义:能够在不需要查看信息的情况下验证信息。
- 对于产块:Polygon Miden引入了并发状态模型。
3. Polygon Miden中的状态
如Polygon Miden zkRollup中的UTXO+账户混合状态模型中所述,Polygon Miden中有账户和notes:
- notes为帐户发送和接收资产的方式。
- 账户消费和生成notes。
这样一来,账户就会改变状态。账户和notes有各自的状态,即它们在某个时间点的特定状况。Polygon Miden的当前状态是:
- 在某个时间点上所有帐户和notes的状态。
Polygon Miden的全局状态存储在三个数据库中:
- 帐户数据库:在Tiered Sparse Merkle Tree (TSMT)中记录每个帐户的最新状态。
- notes数据库:在append-only Merkle Mountain Range中记录所有notes。
- Nullier数据库:在Tiered Sparse Merkle Tree (TSMT)中记录 某note是否已被消费。
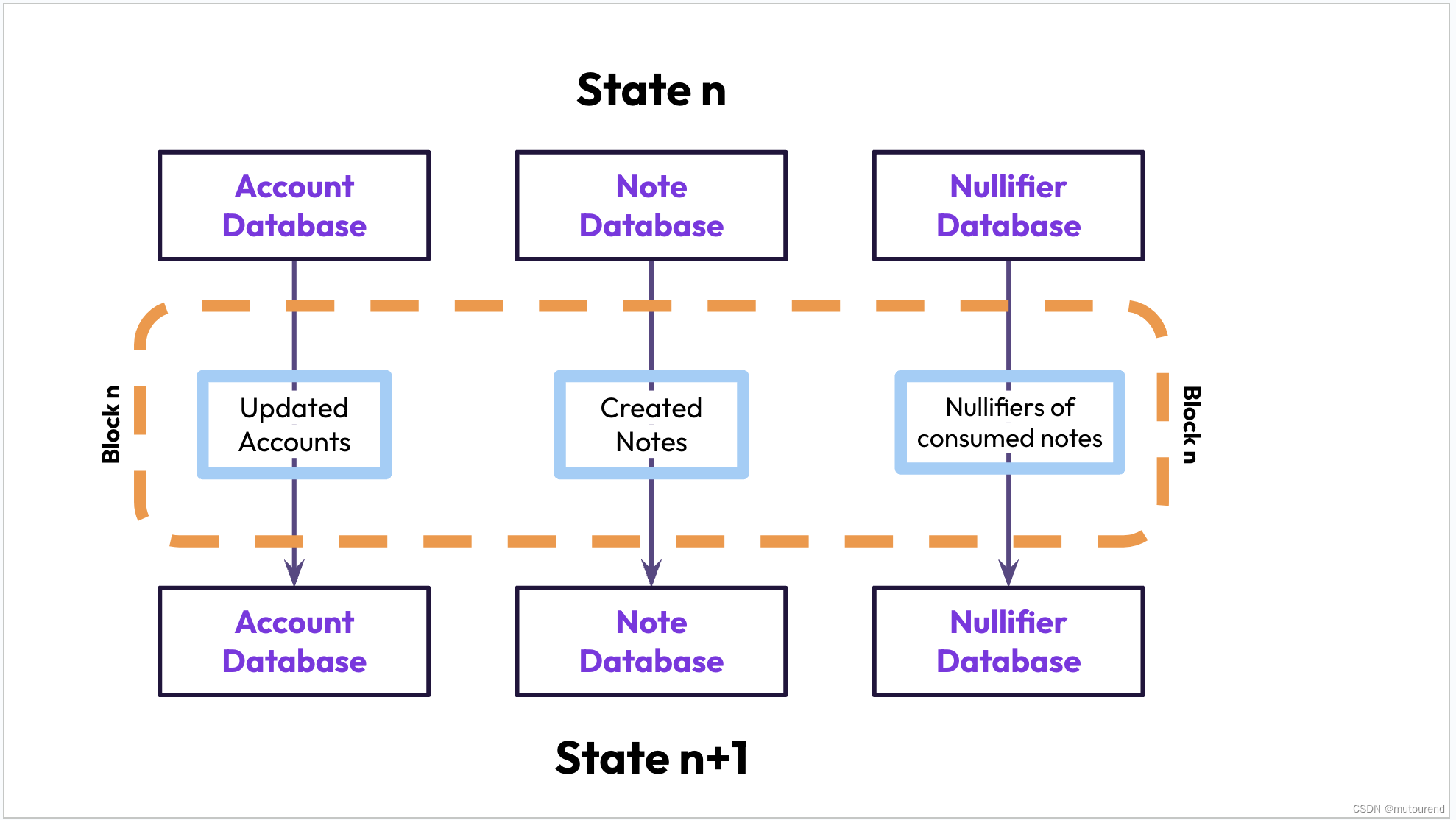
为什么Polygon Miden有两个note数据库?
- note数据库为append-only且永久存储所有notes,
- 而nullifier数据库存储哪些notes不能再被消费。
将notes分别存储到这两个数据库中,为Polygon Miden提供了客户端证明和高级隐私。
- 1)将notes和nullifier分开的第一个原因是客户端证明。
当用户在本地创建proofs时,必须证明其想要消费的notes在note数据库中。
该note的Merkle路径被用作proof的witness data。在像Merkle Mountain Range这样的append-only数据结构中,更新数据结构时,此witness data不会过时。这意味着,即使用户没有这个数据库的最新状态,也可以生成有效的证明,因此无需向Operators查询不断变化的状态。而Merkle树的根会随着每次更新而变化。 - 2)将notes和nullifier分开的第二个原因是隐私。
在Polygon Miden中,nullifiers会破坏已创建notes和已消费notes之间的可链接性。当notes被消费时,其nullifier在nullifier数据库中被设置为1。然而,要知道某note的nullifier,需要知道该note的所有细节。这意味着,如果某note是私人的,并且Opertor仅存储该note的哈希值,那么只有那些拥有该note详细信息的人才能知道该note是否已被消费。ZCash首先引入了Nullifier这种方法。
但这种增强隐私的解决方案会引入另一个问题:
- 若所有notes都被永久存储,那么维护这些数据所需的存储空间将快速增长。
在揭示Polygon Miden如何进一步管理状态膨胀之前,先描述:
- 如何生成全局状态的区块?
- 谁来生成全局状态的区块?
- 如何验证全局状态的区块?
- 谁来验证全局状态的区块?
3.1 Operators
在Polygon Miden中,全局状态由Operators管理。Operators运行Polygon Miden节点并确保三个数据库的完整性。为了防止双花,Operators有责任确保在交易中创建的nullifiers尚未出现在nullifier数据库中。这就是为什么Operators需存储一个完整的nullifier数据库。
然而,Polygon Miden也将一些数据存储的相关责任推给了用户:
- 激励用户在本地保存notes数据,并且只公开存储这些notes的承诺值。这允许Operators积极地裁剪nullifier数据库,并只存储notes的承诺值。
- 激励用户自己处理帐户状态存储,而不是向Operators公开存储所有内容。同样,Operators存储用户账户状态的承诺值并确保任何更改的正确性。不过用户也可选择向Operators公开存储帐户数据和note数据。
4. Polygon Miden如何管理状态膨胀?
由于Operators不需要知道整个状态来验证或生成新区块,所以Operators不需要存储整个状态。那么,区块验证和区块生产是如何实现的呢?
其核心思想很简单:
- 用户存储其数据,而不是与Operators一起存储完整的状态数据,Polygon Miden只跟踪对数据的承诺值。至少对大多数账户来说,某些智能合约需公开可见。
- 这最大限度地减少了状态膨胀——因为Operators不需要存储不断增长的数据库——并提供了隐私,因为所有其他用户和Operators只看到其他用户数据的哈希值。
- 同样,无完整状态的情况下,区块验证之所以可行,是因为ZK证明的美妙之处。Operators可存储一个私人帐户,这是对某个状态的承诺值,即意味着只是一个哈希值。这样,Operators就不知道某个特定账户中有多少资产,也不知道某note上到底写着什么,但Operators仍可验证状态变化的正确性。即使在长时间的高使用率下,帐户数据库和note数据库也可保持可管理性。
与以太坊不同,Polygon Miden上私人账户的规模对状态膨胀的影响可忽略不计。每个私人帐户只为全局状态贡献40个字节(帐户ID为8个字节,帐户哈希为32个字节)。这意味着10亿个私人帐户只需要40GB。Operators只需要知道哈希值就可以验证单个状态转换。
如前所述,Operators仍然必须存储完整的nullifier数据库以进行区块验证。nullifier数据库将随着所消费交易的数量而线性增长。这将对状态膨胀非常不利——在1000个TPS的情况下,该状态将以每年约1TB的速度增长。
因此,在Polygon Miden中,有epochs,并且在每个epoch之后都会创建一个新的nullifier数据库。Operators存储最后两个完整的树和所有历史nullifiers’ tree的树根。这意味着老的notes仍可被消费;用户只需要做多一点点工作。通过将这个epoch参数添加到nullifier数据库,状态膨胀的主要驱动因素变成了每秒交易数(TPS)。
借助Polygon Miden的并发状态模型,所产区块仅具有部分状态是可能的。一个区块包含新创建的notes和nullifiers:
- Notes只是附加到Notes数据库中。
- 对于nullifiers,Operators需要更新nullifier Merkle树,如前所述,这需要完整树的知识。
- 但Operators不需要知道该账户的内容就可以更新它——就像以太坊不需要确切知道rollup上发生了什么就可以在相应的智能合约中更新rollup的状态根一样。这意味着,在Polygon Miden中,每个帐户都可被视为第3层(Layer 3)。
具有这些功能的架构所生成的rollup,在隐私最大化的同时,最大限度地减少了状态增长。这创建了一个强大的反馈循环。
总结下,Polygon Miden使用的状态模型非常独特,是:
- 账户模型(如以太坊)、
- UTXO模型(如比特币)
- 和 ZK证明
的组合。从而获得一个具有并发链下状态的基于actor的模型。
参考资料
[1] Polygon Labs 2023年6月博客 Polygon Miden: State Model