目录
一、前缀树的介绍和定义
前缀树是一种多叉树结构,经常用于快速检索匹配、敏感词匹配替换、文章多词语匹配查找高亮等场景。
1.前缀树的定义
(1).前缀树的根节点不包含字符;
(2).前缀树上除叶子节点外,任意一个节点都包含一个字符,并且任意节点下都可能含有n个子节点;
(3).前缀树上除根节点外每个节点都应有一个标识来表明其是否是一个词的结尾;
(4).前缀树上的叶子节点一定是一个词的结尾;
2.前缀树的结构
假如我有如下14个词语:
“菜鸡”,“菜狗”,“张三丰满”, “张三丰”, “张三”, “张三丰是狗”, “张全”,
“张力”, “张力懦夫”,“王五”,“王五王八”, “王六滚蛋”,“滚蛋”, “滚”
将每个词语拆分后将其放入前缀树上,那么这棵前缀树看起来像是这样的:
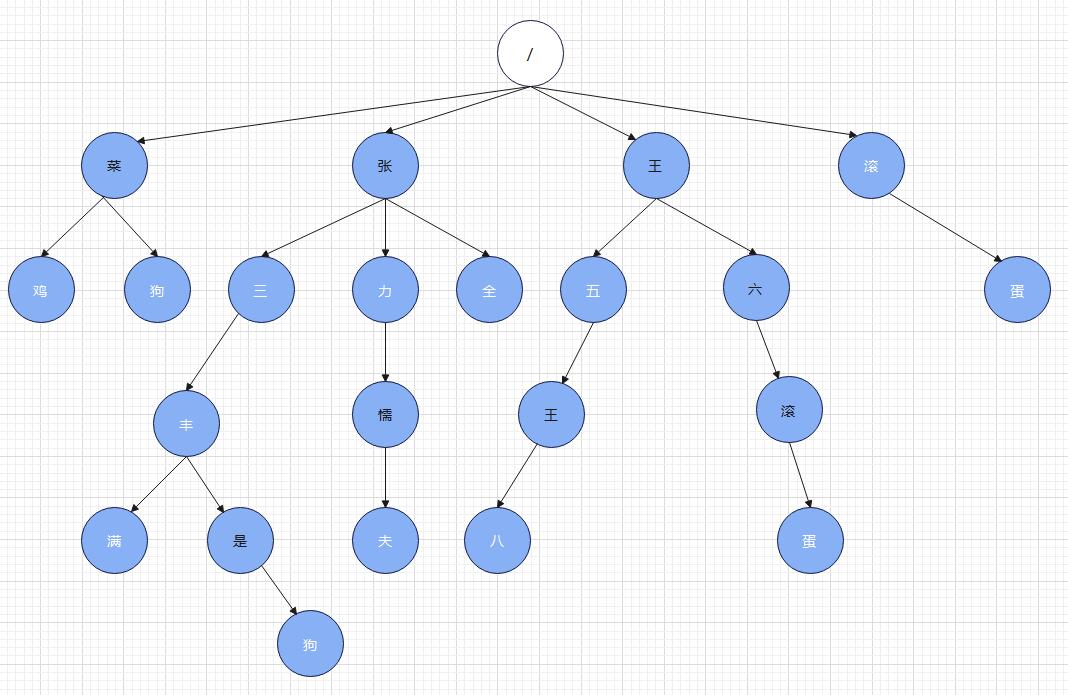
在这棵前缀树上如果该节点的字符是一个词语的结尾我就用白色字体表示,即如果该节点的字符颜色是白色的那么从根节点到该节点的所有节点连起来是一个词语。
比如:
从根节点开始,“鸡” 这个节点的字符是白色的,说明从根节点到这个节点是一个词语,也就是 “菜鸡” 是一个词语;
同理,“五” 是白色的,那 “王五” 就是个词语;
“八” 是白色的,那 “王五王八” 就是个词语;
所以如果给出一个像上面的前缀树,可以容易的反推出前缀树上有 “菜鸡”、“张三”、“张三丰”、“张三丰满”、“滚” 、 “滚蛋” 等词语。
二、前缀树的实现
一般经常用 数组 或者 HashMap 来存储节点的子节点,在这里我用 HashMap 来存储节点的子节点,这样可以很快的对子节点进行搜索。
1.向前缀树中增加词语
(1)如果该词语每个字符节点都不存在于前缀树上,则从根节点开始加入该词语的每个字符节点,并将最后一个字符节点的词语标识设为 true;
(2)如果该词语的开头部分字符在前缀树上,前缀树上找到其节点,将词语剩余字符节点加入其节点下,并将最后一个字符节点的词语标识设为 true;
(3)如果该词语是前缀树上另一个词语的开头部分,在前缀树上找到要添加词语的最后字符节点,将其词语标识设为 true;
2.向前缀树中删除词语
有多种情况,需要判断要删除的词语是否在前缀树上,如果要删除的词语在前缀树上:
(1)若要删除的词语其最后一个字符子节点下没有节点,并且该词语的其他子节点下都只有一个子节点,那么可以从根节点删除此词语;或者该词语只是一个字,且其下没有子节点,那么也可以从根节点删除此词语;
例如:前缀树上张开头的词语只有一个 "张力懦夫" ,如果要删除该词语可以从根节点直接删除。
(2)若最后一个字符节点下有子节点,那么要将该最后一个字符节点的词语标识设为false;
例如:前缀树上张开头的词语只有两个 "张力懦夫" 和 "张力懦夫啊" ,如果要删除词语 "张力懦夫" 只能将 "夫" 这个节点下的词语标识设置为 false,不能删除任何节点,否则会影响另一个词。
(3)若该词语的最后一个字符节点下没有子节点,并且离最后一个字符节点最近的其他节点的子节点数有大于1或有词语标识为true 的,那么可以从那个节点把要删除词语的剩余字符节点从前缀树删除;
例如:前缀树上张开头的词语只有两个 "张力" 和 "张力懦夫啊" ,要删除"张力懦夫啊",只能删除 "力" 这个字符节点下的 "懦夫啊" ;
前缀树上张开头的词语只有两个 "张力懦夫吗" 和 "张力懦夫啊" ,要删除"张力懦夫啊",只能删除 "啊" 这个字符节点;
3.对于使用前缀树进行词语标识:
需要区分一个词语中是否包含另一个词,如果包含的话需要找到最长的那个词来标记、
如:前缀树上有 "张力" 、 "张力懦夫啊"、"王五" 三个词,需要标记的文本是 "王五张力是谁?王五张力懦夫啊",最终标记的结果是 "【王五】【张力】是谁?【王五】【张力懦夫】啊" ,而不能是 "【王五】【张力】是谁?【王五】【张力】懦夫啊"
其他前缀树敏感词替换、判断词语是否在前缀树比较简单,这里不再进行说明。
4.前缀树的实现代码
import java.util.*;
/**
* 前缀树
*/
public class TrieTree {
/**
* 前缀树总的词语数
*/
private int size;
/**
* 根节点
*/
private Node root = new Node(new HashMap<>(), false);
private static class Node {
private Map<Character, Node> childNodeMap;
private boolean isWord;
private Node(Map<Character, Node> childNodeMap, boolean isWord) {
this.childNodeMap = childNodeMap;
this.isWord = isWord;
}
public void setIsWord(boolean isWord) {
this.isWord = isWord;
}
public boolean getIsWord() {
return isWord;
}
public Map<Character, Node> getChildNodeMap() {
return childNodeMap;
}
public void setChildNodeMap(Map<Character, Node> childNodeMap) {
this.childNodeMap = childNodeMap;
}
}
/**
* 清空前缀树
*/
public void clear() {
root = new Node(new HashMap<>(), false);
size = 0;
}
/**
* 获取前缀树的词语数
*/
public int size() {
return size;
}
/**
* 向前缀树中增加节点
*/
public void add(String[] addValues) {
if (addValues != null) {
Arrays.stream(addValues).forEach(this::add);
}
}
/**
* 向前缀树中增加节点
*/
public void add(List<String> addValues) {
if (addValues != null) {
addValues.forEach(this::add);
}
}
/**
* 向前缀树中增加节点
*/
public void add(String str) {
if (str == null || str.trim().isEmpty()) {
return;
}
Map<Character, Node> fatherNodeMap = root.childNodeMap;
int index = 0;
int addValueLength = str.length();
while (index != addValueLength) {
char ch = str.charAt(index);
if (fatherNodeMap.containsKey(ch)) {
Node node = fatherNodeMap.get(ch);
if (index != addValueLength - 1) {
if (node.childNodeMap == null) {
node.childNodeMap = new HashMap<>();
}
fatherNodeMap = node.childNodeMap;
} else {
if (!node.isWord) {
node.setIsWord(true);
size++;
}
}
} else {
if (index != addValueLength - 1) {
Node nodeNew = new Node(new HashMap<>(), false);
fatherNodeMap.put(ch, nodeNew);
fatherNodeMap = nodeNew.childNodeMap;
} else {
Node nodeNew = new Node(null, true);
fatherNodeMap.put(ch, nodeNew);
size++;
}
}
index++;
}
}
/**
* 返回前缀树上以 inputStr 开头的词语
*/
public List<String> matchStartWord(String inputStr) {
List<String> matches = new ArrayList<>();
if (root.childNodeMap.size() == 0) {
return matches;
}
Node node = havaWord(inputStr, root, matches);
if (node != null) {
getMatchStr(new StringBuilder(inputStr), new StringBuilder(""), matches, node.childNodeMap);
}
return matches;
}
private void getMatchStr(StringBuilder inputStr, StringBuilder afterStr, List<String> matches, Map<Character, Node> childNodeMap) {
if (childNodeMap != null) {
for (Map.Entry<Character, Node> m : childNodeMap.entrySet()) {
Character key = m.getKey();
StringBuilder afterStr1 = new StringBuilder(afterStr);
afterStr1.append(key);
Node node = m.getValue();
boolean isWord = node.getIsWord();
StringBuilder inputStrOriginl = new StringBuilder(inputStr);
if (isWord) {
matches.add(inputStrOriginl.append(afterStr1).toString());
}
if (node.childNodeMap != null) {
if (!isWord) {
getMatchStr(inputStrOriginl.append(afterStr1), new StringBuilder(""), matches, node.childNodeMap);
} else {
getMatchStr(inputStrOriginl, new StringBuilder(""), matches, node.childNodeMap);
}
}
}
}
}
/**
* 从前缀树中删除词语 str
* 如果 str 每个字符节点下都只有其下一个字符节点,并且最后一个字符节点下没有节点则可以从根节点删除这个词语,否则将词语的最后一个字符的词语标识设置为false
*/
public void deleteWord(String str) {
//判断前缀树上是否有该词语
if (null != str && haveWord(str)) {
int index = 0;
Node deleteNode = null;
Node startNode = root;
char[] charArray = str.toCharArray();
for (int i = 0; i < charArray.length; i++) {
char ch = charArray[i];
Map<Character, Node> childNodeMap = startNode.childNodeMap;
if (i != charArray.length - 1) {
Node node = childNodeMap.get(ch);
if (node.childNodeMap.size() > 1 || node.isWord) {
deleteNode = node;
index = i;
}
startNode = node;
} else {
Node node = childNodeMap.get(ch);
Map<Character, Node> childNodeMap1 = node.childNodeMap;
node.isWord = false;
if (null != childNodeMap1 && childNodeMap1.size() > 0) {
//如果该最后一个字符不是叶子节点,即它还有子节点
deleteNode = null;
} else {
//如果该最后一个字符是叶子节点
if (deleteNode == null) {
deleteNode = root;
} else {
index++;
}
}
}
}
if (deleteNode != null) {
Map<Character, Node> childNodeMap = deleteNode.childNodeMap;
if (childNodeMap.size() > 1) {
childNodeMap.remove(str.charAt(index));
} else {
deleteNode.childNodeMap = null;
}
}
size--;
}
}
/**
* 判断前缀树上的所有词语,词语 str
*/
public boolean haveWord(String str) {
if (null == str) {
return false;
}
List<String> list = new ArrayList<>();
havaWord(str, root, list);
return list.size() > 0 && str.equals(list.get(0));
}
/**
* 判断前缀树上的所有词语,是否有 str 开头的
*/
public boolean startWordWith(String str) {
if (null == str) {
return false;
}
List<String> list = new ArrayList<>();
Node node = havaWord(str, root, list);
if (list.size() == 0) {
return node != null;
}
return list.size() == 1 && str.equals(list.get(0));
}
/**
* 判断前缀树上是否有 以 inputStr 开头的词语,
* -有,则返回 inputStr 最后一个字符的子节点,若最后一个节点没有子节点则返回最后一个字符的节点
* 若返回的节点不为 null,且 matches 的大小为 0,则返回的是最后一个字符的子节点(即表明 inputStr 是前缀树上的一个词语的开头,如:前缀树上有 “一生一世” 这个词,但 inputStr 是 “一生一”)
* 若返回的节点不为 null,且 matches 的大小为 1,则返回的是 inputStr 倒数第二个字符的节点(即表明 inputStr 是前缀树上的一个词语,如:前缀树上有 “一生一世” 这个词,但 inputStr 是 “一生一世”)
* -没有,则返回 null
*/
private Node havaWord(String inputStr, Node startNode, List<String> matches) {
char[] charArray = inputStr.toCharArray();
for (int i = 0; i < charArray.length; i++) {
char ch = charArray[i];
Map<Character, Node> childNodeMap = startNode.childNodeMap;
if (childNodeMap.containsKey(ch)) {
Node node = childNodeMap.get(ch);
if (node.childNodeMap == null && i != charArray.length - 1) {
return null;
}
if (node.childNodeMap != null || charArray.length == 1) {
startNode = node;
}
if (null != matches && i == charArray.length - 1 && node.isWord) {
matches.add(inputStr);
}
if (i == charArray.length - 1 && node.isWord && node.childNodeMap == null) {
return null;
}
} else {
return null;
}
}
return startNode;
}
/**
* 字符串敏感词替换,若 text 文本中的的词语有在前缀树上的,将其替换为 *
*/
public String sensitiveWordReplace(String text) {
return text != null ? markWordAndWordReplace(text, null, null) : text;
}
/**
* 字符串敏感词标记,若 text 文本中的的词语有在前缀树上的,用 strartSymbol和 endSymbol 将其标记
* 如:
* 例1:
* 假如 "张三"、"今天" 这两个词语在前缀树上
* 当调用 markWord("张三你好,你今天过得怎么样", "【", "】");
* 得到的结果是 "【张三】你好,你【今天】过得怎么样"
*/
public String markWord(String text, String strartSymbol, String endSymbol) {
if (text != null && strartSymbol != null && endSymbol != null) {
return markWordAndWordReplace(text, strartSymbol, endSymbol);
}
return text;
}
//敏感词替换、敏感词标记通用方法
private String markWordAndWordReplace(String text, String strartSymbol, String endSymbol) {
Node startNode = root;
//isMarkWord 为 true 则为敏感词标记,false 为敏感词替换
boolean isMarkWord = strartSymbol != null && endSymbol != null;
//存储最终的结果
StringBuilder result = new StringBuilder();
//若为敏感词替换(也就是isMarkWord为false)starOrCh用于存放* ,即匹配到一个字符就存入* 。若为敏感词标记,则starOrCh用于存放匹配的词
StringBuilder starOrCh = new StringBuilder();
//存放匹配到的字符,即匹配到一个字符就存入
StringBuilder matchCh = new StringBuilder();
int index = 0;
while (index != text.length()) {
char ch = text.charAt(index);
Map<Character, Node> childNodeMap = startNode.childNodeMap;
if (childNodeMap.containsKey(ch)) {
starOrCh.append(isMarkWord ? ch : "*");
Node node = childNodeMap.get(ch);
if (node.childNodeMap != null) {
startNode = node;
}
if (node.isWord) {
StringBuilder saveTemp = new StringBuilder(starOrCh);
//判断该字符后的字符在前缀树上是否在该词语的后面(如:text是"张力懦夫",当前字符ch是"张",匹配到"张力"这个词语,但是"张力懦夫"也是个词语,需要向后再判断其是否在前缀树上,并判断其是否是一个词语)
int nextWordEndIndex = nextCh(text, index + 1, index, node);
if (nextWordEndIndex > index) {
int nextStart = index + 1;
StringBuilder temp = new StringBuilder();
temp.append(saveTemp);
for (int i = nextStart; i <= nextWordEndIndex; i++) {
char nextCh = text.charAt(i);
temp.append(isMarkWord ? nextCh : "*");
index++;
}
appendResuleClearTemp(result, temp, matchCh, starOrCh, strartSymbol, endSymbol);
} else {
//将该词语用*号替换拼接到result , 并清空 starOrCh、temMatch
appendResuleClearTemp(result, starOrCh, matchCh, starOrCh, strartSymbol, endSymbol);
}
//重新设置根节点为开始遍历的节点,方便下一个字符匹配
startNode = root;
} else {
matchCh.append(ch);
}
} else {
if (matchCh.length() > 0) {
appendResuleClearTemp(result, matchCh, matchCh, starOrCh);
}
Map<Character, Node> rootChildNodeMap = root.childNodeMap;
if (rootChildNodeMap.containsKey(ch)) {
matchCh.append(ch);
starOrCh.append(isMarkWord ? ch : "*");
startNode = rootChildNodeMap.get(ch);
} else {
result.append(ch);
}
}
index++;
}
return result.toString();
}
private void appendResuleClearTemp(StringBuilder result, StringBuilder joinBuilder, StringBuilder matchCh, StringBuilder starOrCh, String strartSymbol, String endSymbol) {
if (strartSymbol != null) {
result.append(strartSymbol);
}
result.append(joinBuilder);
if (endSymbol != null) {
result.append(endSymbol);
}
matchCh.setLength(0);
starOrCh.setLength(0);
}
private void appendResuleClearTemp(StringBuilder result, StringBuilder joinBuilder, StringBuilder matchCh, StringBuilder starOrCh) {
result.append(joinBuilder);
matchCh.setLength(0);
starOrCh.setLength(0);
}
//返回从text 的 index 下标开始,node 节点下匹配到的最长词语,返回最长的词语的最后一个字符在 text 的下标,即 wordIndex
private int nextCh(String text, int index, int wordIndex, Node node) {
if (index <= text.length() - 1) {
char nextCh = text.charAt(index);
Map<Character, Node> childNodeMap = node.childNodeMap;
if (childNodeMap != null) {
if (childNodeMap.containsKey(nextCh)) {
Node nextNode = childNodeMap.get(nextCh);
if (nextNode.isWord) {
wordIndex = index;
}
return nextCh(text, index + 1, wordIndex, childNodeMap.get(nextCh));
} else {
return wordIndex;
}
}
}
return wordIndex;
}
}
三、前缀树使用及测试
1.向前缀树上增加词语
String[] array = new String[]{
"菜鸡","菜狗","张三","张三丰满", "张三丰", "张三丰是狗", "张全", "张力", "张力懦夫","王五","王五王八", "王六滚蛋","滚蛋","滚"};
TrieTree trieTree = new TrieTree();
//将数组里面的所有词语加入到前缀树上
trieTree.add(array);
2.根据输入匹配前缀树上的词语
一般像百度这样的搜索引擎会将用户经常搜索的文本加入到前缀树,这样用户只要在搜索框输入一两个字,搜索引擎就从前缀树上返回匹配到的相关前缀的词语,将其以下拉框的形式展示,方便用户选择。
String[] array = new String[]{
"菜鸡","菜狗","张三","张三丰满", "张三丰", "张三丰是狗", "张全", "张力", "张力懦夫","王五","王五王八", "王六滚蛋","滚蛋","滚"};
//将数组里面的所有词语加入到前缀树上
trieTree.add(array);
//匹配前缀树上 "张" 开头的词语有哪些
List<String> matchResult = trieTree.matchStartWord("张");
//输出:[张全, 张三, 张三丰, 张三丰满, 张三丰是狗, 张力, 张力懦夫]
System.out.println(matchResult);
3.判断前缀树上是否有某个词语
String[] array = new String[]{
"菜鸡","菜狗","张三","张三丰满", "张三丰", "张三丰是狗", "张全", "张力", "张力懦夫","王五","王五王八", "王六滚蛋","滚蛋","滚"};
//将数组里面的所有词语加入到前缀树上
trieTree.add(array);
//判断前缀树上是否有 "张三" 这个词语
boolean existWord = trieTree.haveWord("张三");
System.out.println(existWord); //true
//判断前缀树上是否有 "张三四" 这个词语
boolean existWord1 = trieTree.haveWord("张三四");
System.out.println(existWord1); //false
4.判断输入的字符串是否是前缀树上某个词语的开头
String[] array = new String[]{
"菜鸡","菜狗","张三","张三丰满", "张三丰", "张三丰是狗", "张全", "张力", "张力懦夫","王五","王五王八", "王六滚蛋","滚蛋","滚"};
//将数组里面的所有词语加入到前缀树上
trieTree.add(array);
//判断前缀树上是否有 "王六滚" 开头的词语
boolean haveStar = trieTree.startWordWith("王六滚");
System.out.println(haveStar); //true
//判断前缀树上是否有 "王六滚蛋" 开头的词语
boolean haveStar = trieTree.startWordWith("王六滚蛋");
System.out.println(haveStar); //true
5.从前缀树上删除某个词语
String[] array = new String[]{
"菜鸡","菜狗","张三","张三丰满", "张三丰", "张三丰是狗", "张全", "张力", "张力懦夫","王五","王五王八", "王六滚蛋","滚蛋","滚"};
//将数组里面的所有词语加入到前缀树上
trieTree.add(array);
System.out.println("没删除前前缀树含有"+trieTree.size()+"个词语");
trieTree.deleteWord("张三");
System.out.println("删除后前缀树含有"+trieTree.size()+"个词语");
System.out.println("删除后前缀树是否含有词语 \"张三\" :"+trieTree.haveWord("张三"));
输出:
没删除前前缀树含有14个词语
删除后前缀树含有13个词语
前缀树是否含有词语 "张三" :false
6.使用前缀树进行敏感词过滤
String[] array = new String[]{
"菜鸡","菜狗","张三","张三丰满", "张三丰", "张三丰是狗", "张全", "张力", "张力懦夫","王五","王五王八", "王六滚蛋","滚蛋","滚"};
trieTree.add(array);
String text = "小张打游戏很厉害,但是张三打游戏真菜鸡。上次我在游戏里说张三菜狗他就生气了。他说滚,我就滚滚蛋了。\n"+
"王五斗地主很厉害,上次王五王炸,张三丰就骂他,我们是队友你炸我干嘛,然后骂王五王八,王五听错了以为张三丰骂的,于是回骂张三丰是狗。\n"+
"然后场面一度失控,旁边的张力也被波及,什么张力懦夫张力滚蛋王五王八王五滚蛋都被乱七八糟的骂!";
//过滤后的文本
String textFilter = trieTree.sensitiveWordReplace(text);
System.out.println(textFilter);
输出:
小张打游戏很厉害,但是**打游戏真**。上次我在游戏里说****他就生气了。他说*,我就***了。
**斗地主很厉害,上次**王炸,***就骂他,我们是队友你炸我干嘛,然后骂****,**听错了以为***骂的,于是回骂*****。
然后场面一度失控,旁边的**也被波及,什么****************都被乱七八糟的骂!
7.使用前缀树对文章、消息进行敏感词标记
String[] array = new String[]{
"菜鸡","菜狗","张三","张三丰满", "张三丰", "张三丰是狗", "张全", "张力", "张力懦夫","王五","王五王八", "王六滚蛋","滚蛋","滚"};
trieTree.add(array);
String text = "小张打游戏很厉害,但是张三打游戏真菜鸡。上次我在游戏里说张三菜狗他就生气了。他说滚,我就滚滚蛋了。\n"+
"王五斗地主很厉害,上次王五王炸,张三丰就骂他,我们是队友你炸我干嘛,然后骂王五王八,王五听错了以为张三丰骂的,于是回骂张三丰是狗。\n"+
"然后场面一度失控,旁边的张力也被波及,什么张力懦夫张力滚蛋王五王八王五滚蛋都被乱七八糟的骂!";
//标记后的文本
String mark = trieTree.markWord(text, "【", "】");
System.out.println(mark);
输出:
小张打游戏很厉害,但是【张三】打游戏真【菜鸡】。上次我在游戏里说【张三】【菜狗】他就生气了。他说【滚】,我就【滚】【滚蛋】了。
【王五】斗地主很厉害,上次【王五】王炸,【张三丰】就骂他,我们是队友你炸我干嘛,然后骂【王五王八】,【王五】听错了以为【张三丰】骂的,于是回骂【张三丰是狗】。
然后场面一度失控,旁边的【张力】也被波及,什么【张力懦夫】【张力】【滚蛋】【王五王八】【王五】【滚蛋】都被乱七八糟的骂!