前言
在机器学习和深度学习中,训练集和验证集是两个非常重要的概念。训练集用于训练模型,而验证集则用于调整模型的超参数以及评估模型的性能。在训练过程中,我们通常会记录训练集与验证集的损失值,以便在训练完成后对模型进行评估。然而,训练集损失值与验证集损失值之间的关系却有很多种可能性,在本文中,我们将讨论以下几种情况。
训练集损失值持续降低 但验证集损失趋于收敛
如图:
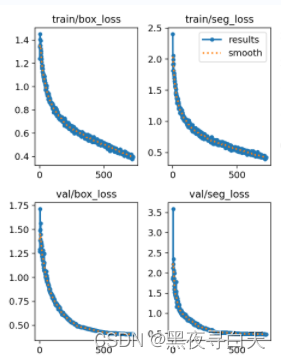
原因可能来自于两方面:
一、模型过拟合 二、训练集与测试集不是独立同分布的
先从数据方面考虑:
数据来源是否一致:
可能的情况:
1、训练集与测试集的拍摄环境不同:例如训练集灯光分布均匀,亮度合适的环境,测试集在光照分布不均匀,出现强曝光、低曝光等等因素
2、摄像头不一致,且存在拍摄效果差别较大:例如摄像头拍摄后 图像的清晰度、对比度等等
3、数据集的噪声干扰项不同,例如训练集正常拍摄,而测试集加入了背景干扰、亮度猛烈变化、光照不均匀等等
解决思路:
将训练集与测试集打散,重新划分训练集与测试集,做到两者分布是一致的
若数据同分布,应该是模型过拟合
过拟合是指模型在训练集上表现良好,但在验证集上表现不佳的现象。这意味着模型已经学会了训练集中的噪声,而没有学到泛化的特征。为了解决这个问题,我们可以采用以下方法:
1、增加训练数据量,也可以在原数据集上进行数据增强:例如扭曲、添加噪声点、模糊、上下翻转、左右翻转等等;
2、减少模型复杂度;
3、使用正则化技术,如L1或L2正则化;
4、增加dropout层的数量或使用其他dropout技术
参考链接:
https://blog.csdn.net/weixin_44438120/article/details/107513046?ops_request_misc=&request_id=&biz_id=102&utm_term=%E8%AE%AD%E7%BB%83%E9%9B%86%E6%8D%9F%E4%BC%A4%E4%BB%8D%E7%84%B6%E5%9C%A8%E4%B8%8B%E9%99%8D%20%E4%BD%86%E6%98%AF%E9%AA%8C%E8%AF%81%E9%9B%86%E6%8D%9F%E5%A4%B1%E5%B7%B2%E7%BB%8F%E6%94%B6%E6%95%9B&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduweb~default-1-107513046.142v94insert_down1&spm=1018.2226.3001.4187