本系列文章是我从《通用源码指导书:MyBatis源码详解》一书中的笔记和总结
本书是基于MyBatis-3.5.2版本,书作者 易哥 链接里是CSDN中易哥的微博。但是翻看了所有文章里只有一篇简单的介绍这本书。并没有过多的展示该书的魅力。接下来我将自己的学习总结记录下来。如果作者认为我侵权请联系删除,再次感谢易哥提供学习素材。本段说明将伴随整个系列文章,尊重原创,本人已在微信读书购买改书。
版权声明:本文为CSDN博主「架构师易哥」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/onlinedct/article/details/107306041
MyBatis 作为 ORM 框架,向上连接着 Java 业务应用,向下则连接着数据库。datasource包则是 MyBatis与数据库交互时涉及的最为主要的包。通过 datasource包,MyBatis将完成数据源的获取、数据连接的建立等工作,为数据库操作语句的执行打好基础。
1.背景
datasource 包作为与数据库交互的包,必然要涉及许多数据库相关的类。这些类是MyBatis连接具体数据库数据的重要桥梁。理解好它们对于读懂 MyBatis的源码大有裨益。
1.1 java.sql包
java.sql通常被称为 JDBC核心API包,它为 Java提供了访问数据源中数据的基础功能。基于该包能实现将 SQL语句传递给数据库、从数据库中以表格的形式读写数据等功能。java.sql提供了一个Driver接口作为数据库驱动的接口。不同种类的数据库厂商只需根据自身数据库特点开发相应的 Driver实现类,并通过DriverManager进行注册即可。这样,基于 JDBC便可以连接不同公司不同种类的数据库。
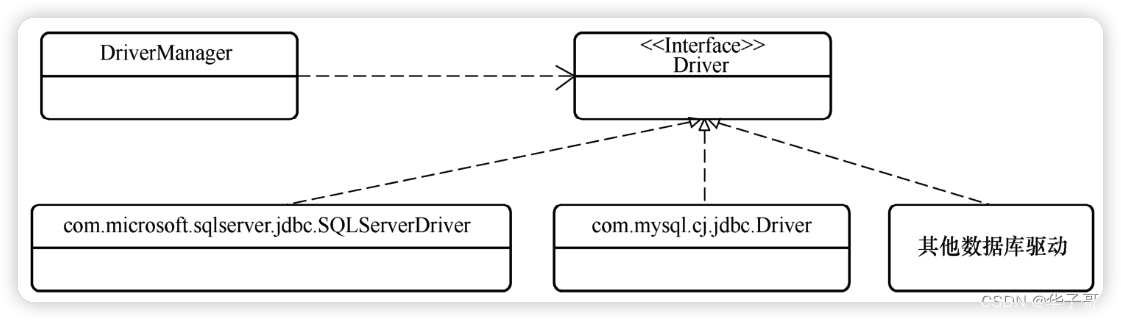
基于 java.sql包,Java程序能够完成各种数据库操作。通常完成一次数据库操作的流程如下所示。
- 建立 DriverManager对象。
- 从 DriverManager对象中获取 Connection对象。
- 从 Connection对象中获取 Statement对象。
- 将 SQL 语句交给 Statement 对象执行,并获取返回的结果,结果通常放在ResultSet中。
1.2 javax.sql包
javax.sql通常被称为 JDBC扩展 API包,它扩展了 JDBC核心API包的功能,提供了对服务器端的支持,是 Java企业版的重要部分。
例如,javax.sql提供了 DataSource接口,通过它可以获取面向数据源的 Connection对象,与 java.sql 中直接使用DriverManager 建立连接的方式相比更为灵活(实际上,DataSource接口的实现中也是通过 DriverManager对象获取Connection对象的)。除此之外,javax.sql还提供了连接池、语句池、分布式事务等方面的诸多特性。使用javax.sql包扩展了java.sql包之后,建议使用DataSource来获取Connection对象,而不是直接使用 DriverManager对象。于是,一条 SQL语句的执行过程如下:
- 建立 DataSource对象。
- 从 DataSource对象中获取 Connection对象。
- 从 Connection对象中获取 Statement对象。
- 将 SQL 语句交给 Statement 对象执行,并获取返回的结果,结果通常放在ResultSet中。
1.3 DriverManager
DriverManager 接口位于 java.sql,它是 JDBC 驱动程序管理器,可以管理一组 JDBC驱动程序。DriverManager的一个重要功能是能够给出一个面向数据库的连接对象 Connection,该功能是由 DriverManager中的getConnection方法提供的。当调用 getConnection 方法时,DriverManager 会尝试在已经加载的驱动程序中找出合适的一个,并用找出的驱动程序建立一个面向指定数据库的连接,最后将建立的连接返回。
DriverManager 中主要有下面几个方法。这些方法都是静态方法,不需要建立DriverManager对象便可以直接调用。
- void registerDriver:向 DriverManager中注册给定的驱动程序。
- void deregisterDriver:从 DriverManager中删除给定的驱动程序。
- Driver getDriver:查找能匹配给定 URL路径的驱动程序。
- Enumeration getDrivers:获取当前调用者可以访问的所有已加载的 JDBC 驱动程序。
- Connection getConnection:建立到给定数据库的连接。
1.4 DataSource
DataSource是 javax.sql的一个接口。顾名思义,它代表了一个实际的数据源,其功能是作为工厂提供数据库连接。
DataSource接口中只有以下两个接口方法,都用来获取一个Connection对象。
- getConnection():从当前的数据源中建立一个连接。
- getConnection(String,String):从当前的数据源中建立一个连接,输入的参数为数据源的用户名和密码。
javax.sql中的 DataSource仅仅是一个接口,不同的数据库可以为其提供多种实现。常见的实现有以下几种。
- 基本实现:生成基本的到数据库的连接对象 Connection。
- 连接池实现:生成的 Connection对象能够自动加到连接池中。
- 分布式事务实现:生成的 Connection对象能够参与分布式事务。
正因为 DataSource 接口可以有多种实现,与直接使用DriverManager 获得连接对象Connection的方式相比更为灵活。在日常的开发过程中,建议使用 DataSource来获取数据库连接。而实际上,在 DataSource 的具体实现中,最终也是基于DriverManager 获得Connection,因此 DataSource只是DriverManager的进一步封装。
1.5 Connection
Connection接口位于 java.sql中,它代表对某个数据库的连接。基于这个连接,可以完成 SQL语句的执行和结果的获取等工作。
Connection中常用的方法如下。
- Statement createStatement:创建一个 Statement对象,通过它能将 SQL语句发送到数据库。
- CallableStatement prepareCall:创建一个CallableStatement对象,通过它能调用存储过程。
- PreparedStatement prepareStatement:创建一个PreparedStatement对象,通过它能将参数化的 SQL语句发送到数据库。
- String nativeSQL:将输入的 SQL语句转换成本地可用的SQL语句。
- void commit:提交当前事务。
- void rollback:回滚当前事务。
- void close:关闭当前的 Connection对象。
- boolean isClosed:查询当前 Connection对象是否关闭。
- boolean isValid:查询当前 Connection是否有效。
- void setAutoCommit:根据输入参数设定当前 Connection对象的自动提交模式。
- int getTransactionIsolation:获取当前 Connection对象的事务隔离级别。
- void setTransactionIsolation:设定当前 Connection对象的事务隔离级别。
- DatabaseMetaData getMetaData:获取当前 Connection 对象所连接的数据库的所有元数据信息。
上述方法主要用来完成获取 Statement对象、设置 Connection属性等功能。同时,Connection 中存在事务管理的方法,如 commit、rollback 等。通过调用这些事务管理方法可以控制数据库完成相应的事务操作。
1.6 Statement
Statement接口位于 java.sql中,该接口中定义的一些抽象方法能用来执行静态 SQL语句并返回结果。通常 Statement对象会返回一个结果集对象 ResultSet。
Statement接口中的主要方法有:
- void addBatch:将给定的 SQL命令批量添加到 Statement对象的 SQL命令列表中。
- void clearBatch:清空 Statement对象的 SQL命令列表。
- int[] executeBatch:让数据库批量执行多个命令。如果执行成功,则返回一个数组。数组中的每个元素都代表了某个命令影响数据库记录的数目。
- boolean execute:执行一条 SQL语句。
- ResultSet executeQuery:执行一条 SQL语句,并返回结果集 ResultSet对象。
- int executeUpdate:执行给定 SQL 语句,该语句可能为INSERT、UPDATE、DELETE或 DDL语句等。
- ResultSet getResultSet:获取当前结果集 ResultSet对象。
- ResultSet getGeneratedKeys:获取当前操作自增生成的主键。
- boolean isClosed:获取是否已关闭了此 Statement对象。
- void close:关闭 Statement对象,释放相关的资源。
- Connection getConnection:获取生成此 Statement对象的Connection对象。
上述方法主要用来完成执行 SQL语句、获取 SQL语句执行结果等功能。
2.数据源工厂
datasource 包采用了典型的工厂方法模式。DataSourceFactory 作为所有工厂的接口,javax.sql包中的DataSource作为所有工厂产品的接口。
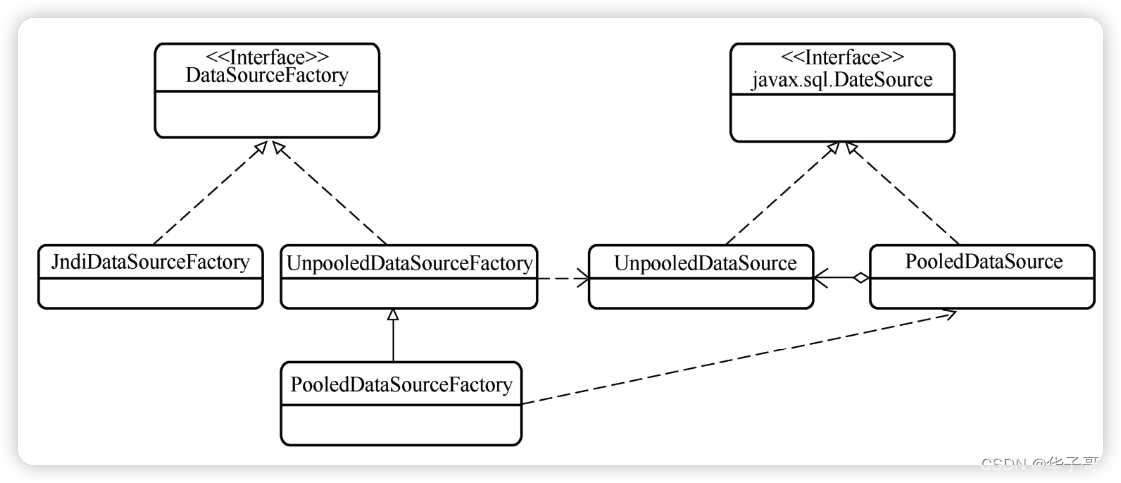
既然是工厂方法模式,那在使用时就需要选择具体的实现工厂。在XMLConfigBuilder类中的 dataSourceElement方法中,可以看到与选择实现工厂相关的源码:
/**
* 解析配置信息,获取数据源工厂
* 被解析的配置信息示例如下:
* <dataSource type="POOLED">
* <property name="driver" value="{dataSource.driver}"/>
* <property name="url" value="{dataSource.url}"/>
* <property name="username" value="${dataSource.username}"/>
* <property name="password" value="${dataSource.password}"/>
* </dataSource>
*
* @param context 被解析的节点
* @return 数据源工厂
* @throws Exception
*/
private DataSourceFactory dataSourceElement(XNode context) throws Exception {
if (context != null) {
// 通过这里的类型判断数据源类型,例如POOLED、UNPOOLED、JNDI
String type = context.getStringAttribute("type");
// 获取dataSource节点下配置的property
Properties props = context.getChildrenAsProperties();
// 根据dataSource的type值获取相应的DataSourceFactory对象
DataSourceFactory factory = (DataSourceFactory) resolveClass(type).newInstance();
// 设置DataSourceFactory对象的属性
factory.setProperties(props);
return factory;
}
throw new BuilderException("Environment declaration requires a DataSourceFactory.");
}
MyBatis是基于 XML文件中配置的dataSource的 type属性进行实现工厂的选择的,我们可以选择DataSource接口的任意一种实现类作为数据源工厂。
2.1 JNDI
JNDI数据源工厂datasource包中的 jndi子包提供了一个 JNDI数据源工厂JndiDataSourceFactory。
在阅读 JndiDataSourceFactory的源码之前,我们先了解什么是 JNDI,以及什么是 JNDI数据源。JNDI(Java Naming and Directory Interface)是 Java命名和目录接口,它能够为 Java应用程序提供命名和目录访问的接口,我们可以将其理解为一个命名规范。在使用该规范为资源命名并将资源放入环境(Context)中后,可以通过名称从环境中查找(lookup)对应的资源。
数据源作为一个资源,就可以使用 JNDI命名后放入环境中,这就是 JNDI数据源。之后只要通过名称信息,就可以将该数据源查找出来。例如,Tomcat等应用服务器在启动时可以将相关的数据源都命名好后放入环境中,而 MyBatis 可以通过该数据源的名称信息将其从环境中查找出来。这样的好处是应用开发人员只需给 MyBatis 设置要查找的数据源的JNDI名称即可,而不需要关心该数据源的具体信息(地址、用户名、密码等)与生成细节。
JndiDataSourceFactory的作用就是从环境中找出指定的 JNDI数据源。在 MyBatis的配置文件中使用字符串“JNDI”来代表JNDI数据源。
<environment id="uat">
<transactionManager type="JDBC"/>
<dataSource type="JNDI" >
<!--起始环境信息-->
<property name="initial_context" value="java:/comp/env"/>
<!--数据源JNDI名称-->
<property name="data_source" value="java:comp/env/jndi/mybatis" />
<!--以"env."开头的其他环境配置信息-->
<property name="env.encoding" value="UTF8" />
</dataSource>
</environment>
- initial_context:给出的是起始环境信息,MyBatis 会到这里寻找指定的数据源。该值也可以不设置,则 MyBatis会在整个环境中寻找数据源。
- data_source:给出的是数据源的名称。
JndiDataSourceFactory中的 getDataSource方法只负责将成员变量中的 DataSource对象返回,而从环境中找出指定的DataSource的操作是在 setProperties方法中进行的。从本质上讲,JndiDataSourceFactory 不是在生产数据源,而只是负责查找数据源。
/**
* 配置数据源属性,其中包含了数据源的查找工作
* @param properties 属性信息
*/
@Override
public void setProperties(Properties properties) {
try {
// 初始上下文环境
InitialContext initCtx;
// 获取配置信息,根据配置信息初始化环境
Properties env = getEnvProperties(properties);
if (env == null) {
initCtx = new InitialContext();
} else {
initCtx = new InitialContext(env);
}
// 从配置信息中获取数据源信息
if (properties.containsKey(INITIAL_CONTEXT)
&& properties.containsKey(DATA_SOURCE)) {
// 定位到initial_context给出的起始环境
Context ctx = (Context) initCtx.lookup(properties.getProperty(INITIAL_CONTEXT));
// 从起始环境中寻找指定数据源
dataSource = (DataSource) ctx.lookup(properties.getProperty(DATA_SOURCE));
} else if (properties.containsKey(DATA_SOURCE)) {
// 从整个环境中寻找指定数据源
dataSource = (DataSource) initCtx.lookup(properties.getProperty(DATA_SOURCE));
}
} catch (NamingException e) {
throw new DataSourceException("There was an error configuring JndiDataSourceTransactionPool. Cause: " + e, e);
}
}
/**
* 获取数据源
* @return 数据源
*/
@Override
public DataSource getDataSource() {
return dataSource;
}
3 非池化数据源及工厂
datasource包中的 unpooled子包提供了非池化的数据源工厂及非池化的数据源。
3.1 非池化数据源工厂
UnpooledDataSourceFactory 是非池化的数据源工厂。与只负责从环境中查找指定数据源的 JndiDataSourceFactory不同,unpooled子包下的 UnpooledDataSourceFactory需要真正创建一个数据源。不过这个创建过程非常简单,UnpooledDataSourceFactory 直接在自身的构造方法中创建了数据源对象,并保存在了自身的成员变量中。
/**
* UnpooledDataSourceFactory的构造方法,包含了创建数据源的操作
*/
public UnpooledDataSourceFactory() {
this.dataSource = new UnpooledDataSource();
}
UnpooledDataSourceFactory 的 setProperties 方法负责为工厂中的数据源设置属性。给数据源设置的属性分为两类:以“driver.”开头的属性是设置给数据源内包含的DriverManager对象的;其他的属性是设置给数据源本身的。
/**
* 为数据源设置配置信息
* @param properties 配置信息
*/
@Override
public void setProperties(Properties properties) {
// 驱动的属性
Properties driverProperties = new Properties();
// 生成一个包含DataSource对象的元对象
MetaObject metaDataSource = SystemMetaObject.forObject(dataSource);
// 设置属性
for (Object key : properties.keySet()) {
String propertyName = (String) key;
if (propertyName.startsWith(DRIVER_PROPERTY_PREFIX)) {
// 取出以"driver."开头的配置信息
// 记录以"driver."开头的配置信息
String value = properties.getProperty(propertyName);
driverProperties.setProperty(propertyName.substring(DRIVER_PROPERTY_PREFIX_LENGTH), value);
} else if (metaDataSource.hasSetter(propertyName)) {
// 通过反射为DataSource设置其他的属性
String value = (String) properties.get(propertyName);
Object convertedValue = convertValue(metaDataSource, propertyName, value);
metaDataSource.setValue(propertyName, convertedValue);
} else {
throw new DataSourceException("Unknown DataSource property: " + propertyName);
}
}
if (driverProperties.size() > 0) {
// 将以"driver."开头的配置信息放入DataSource的driverProperties属性中
metaDataSource.setValue("driverProperties", driverProperties);
}
}
非池化数据源非池化数据源是最简单的数据源,它只需要在每次请求连接时打开连接,在每次连接结束时关闭连接即可。在MyBatis的配置文件中使用字符串“UNPOOLED”来代表非池化数据源。
<dataSource type="UNPOOLED">
<!--数据库驱动-->
<property name="driver" value="com.mysql.jdbc.Driver"/>
<!--数据源地址-->
<property name="url" value="jdbc:mysql://127.0.0.1:3306/yeecode"/>
<!--数据源用户名-->
<property name="username" value="yeecode"/>
<!--数据源密码-->
<property name="password" value="yeecode_passward"/>
<!--是否自动提交-->
<property name="autoCommit" value="true" />
<!--默认的事务隔离级别-->
<property name="defaultTransactionlsoltionLevel" value="1"/>
<!--默认最长等待时间-->
<property name="defaultNetworkTimeout" value="2000"/>
<!-- 省略了一些其他属性 -->
</dataSource>
UnpooledDataSource类中的属性和上面的配置信息一一对应。
public class UnpooledDataSource implements DataSource {
// 驱动加载器
private ClassLoader driverClassLoader;
// 驱动配置信息
private Properties driverProperties;
// 已经注册的所有驱动
private static Map<String, Driver> registeredDrivers = new ConcurrentHashMap<>();
// 数据库驱动
private String driver;
// 数据源地址
private String url;
// 数据源用户名
private String username;
// 数据源密码
private String password;
// 是否自动提交
private Boolean autoCommit;
// 默认事务隔离级别
private Integer defaultTransactionIsolationLevel;
// 最长等待时间。发出请求后,最长等待该时间后如果数据库还没有回应,则认为失败
private Integer defaultNetworkTimeout;
4.池化数据源
池化数据源在一个应用程序中,常常会进行大量的数据库操作。而如果每一次数据库操作时都建立和释放数据库连接 Connection对象,则会降低整个程序的运行效率。因此,引入数据库连接池非常必要。在连接池中总保留一定数量的数据库连接以备使用,可以在需要时取出,用完后放回,减少了连接的创建和销毁工作,提升了整体的效率。
在从非池化的数据源 UnpooledDataSource 中获取Connection 对象时,实际上是由UnpooledDataSource 对象内部的 DriverManager 对象给出的。显然,这些连接Connection对象不属于任何一个连接池。datasource包的 pooled子包提供了数据源连接池相关的类。其中 PooledDataSourceFactory类继承了UnpooledDataSourceFactory 类,并仅仅重写了构造方法而已。
4.1 池化数据源类的属性
在 MyBatis 的配置文件中使用字符串“POOLED”来代表池化数据源,在池化数据源的配置中,除了非池化数据源中的相关属性外,还增加了一些与连接池相关的属性。最重要的是以下三个属性:state、dataSource、expectedConnectionTypeCode。
public class PooledDataSource implements DataSource {
private final PoolState state = new PoolState(this);
// 持有一个UnpooledDataSource对象
private final UnpooledDataSource dataSource;
// 和连接池设置有关的配置项
protected int poolMaximumActiveConnections = 10;
protected int poolMaximumIdleConnections = 5;
protected int poolMaximumCheckoutTime = 20000;
protected int poolTimeToWait = 20000;
protected int poolMaximumLocalBadConnectionTolerance = 3;
protected String poolPingQuery = "NO PING QUERY SET";
protected boolean poolPingEnabled;
protected int poolPingConnectionsNotUsedFor;
// 存储池子中的连接的编码,编码用("" + url + username + password).hashCode()算出来
// 因此,整个池子中的所有连接的编码必须是一致的,里面的连接是等价的
private int expectedConnectionTypeCode;
- state属性
state是一个 PoolState对象,存储了所有的数据库连接及状态信息。
在设置池化的数据源时,掌握好连接池的大小十分必要。如果连接池设置得过大,则会存在大量的空闲连接,从而导致内存等资源的浪费;如果连接池设置得过小,则需要频繁地创建和销毁连接,从而降低程序运行的效率。
数据库连接池大小的设置需要根据业务场景判断,在这个判断过程中需要有连接池的运行数据进行支持。因此,对连接池的运行数据进行统计非常必要。PooledDataSource 没有直接使用列表而是使用 PoolState 对象来存储所有的数据库连接,就是为了统计连接池运行数据的需要。
在 PoolState 类的属性中,除了使用idleConnections 和 activeConnections 两个列表存储了所有的空余连接和活跃连接外,还有大量的属性用来存储连接池运行过程中的统计信息。
public class PoolState {
// 池化数据源
protected PooledDataSource dataSource;
// 空闲的连接
protected final List<PooledConnection> idleConnections = new ArrayList<>();
// 活动的连接
protected final List<PooledConnection> activeConnections = new ArrayList<>();
// 连接被取出的次数
protected long requestCount = 0;
// 取出请求花费时间的累计值。从准备取出请求到取出结束的时间为取出请求花费的时间
protected long accumulatedRequestTime = 0;
// 累积被检出的时间
protected long accumulatedCheckoutTime = 0;
// 声明的过期连接数
protected long claimedOverdueConnectionCount = 0;
// 过期的连接数的总检出时长
protected long accumulatedCheckoutTimeOfOverdueConnections = 0;
// 总等待时间
protected long accumulatedWaitTime = 0;
// 等待的轮次
protected long hadToWaitCount = 0;
// 坏连接的数目
protected long badConnectionCount = 0;
-
dataSource当池化的数据源在连接池中的连接不够时,也需要创建新的连接。
而属性 dataSource是一个 UnpooledDataSource对象,在需要创建新的连接时,由该属性给出。 -
expectedConnectionTypeCode一个数据源连接池必须确保池中的每个连接都是等价的,这样才能保证我们每次从连接池中取出连接不会存在差异。expectedConnectionTypeCode 存储的是该数据源连接类型编码。
/**
* 计算该连接池中连接的类型编码
* @param url 连接地址
* @param username 用户名
* @param password 密码
* @return 类型编码
*/
private int assembleConnectionTypeCode(String url, String username, String password) {
return ("" + url + username + password).hashCode();
}
该值在 PooledDataSource 对象创建时生成,然后会赋给每一个从该 PooledDataSource对象的连接池中取出的PooledConnection。当 PooledDataSource 使用结束被归还给连接池时会校验该值,从而保证还回来的 PooledDataSource对象确实属于该连接池。
可以把 PooledConnection 理解为一个要出借东西的主人。在出借之前,他会在东西上签上自己的名字;在东西归还时,他会检查东西上是不是自己的签名。这样就避免了别人的东西错还到自己这里。
4.2 池化连接的给出与收回
对于池化数据源 PooledDataSource而言,最重要的工作就是给出与收回池化连接。
- 给出池化连接给出池化连接的方法是 popConnection
/**
* 从池化数据源中给出一个连接
* @param username 用户名
* @param password 密码
* @return 池化的数据库连接
* @throws SQLException
*/
private PooledConnection popConnection(String username, String password) throws SQLException {
boolean countedWait = false;
PooledConnection conn = null;
// 用于统计取出连接花费的时长的时间起点
long t = System.currentTimeMillis();
int localBadConnectionCount = 0;
while (conn == null) {
// 给state加同步锁
synchronized (state) {
if (!state.idleConnections.isEmpty()) {
// 池中存在空闲连接
// 左移操作,取出第一个连接
conn = state.idleConnections.remove(0);
if (log.isDebugEnabled()) {
log.debug("Checked out connection " + conn.getRealHashCode() + " from pool.");
}
} else {
// 池中没有空余连接
if (state.activeConnections.size() < poolMaximumActiveConnections) {
// 池中还有空余位置
// 可以创建新连接,也是通过DriverManager.getConnection拿到的连接
conn = new PooledConnection(dataSource.getConnection(), this);
if (log.isDebugEnabled()) {
log.debug("Created connection " + conn.getRealHashCode() + ".");
}
} else {
// 连接池已满,不能创建新连接
// 找到借出去最久的连接
PooledConnection oldestActiveConnection = state.activeConnections.get(0);
// 查看借出去最久的连接已经被借了多久
long longestCheckoutTime = oldestActiveConnection.getCheckoutTime();
if (longestCheckoutTime > poolMaximumCheckoutTime) {
// 借出时间超过设定的借出时长
// 声明该连接超期不还
state.claimedOverdueConnectionCount++;
state.accumulatedCheckoutTimeOfOverdueConnections += longestCheckoutTime;
state.accumulatedCheckoutTime += longestCheckoutTime;
// 因超期不还而从池中除名
state.activeConnections.remove(oldestActiveConnection);
if (!oldestActiveConnection.getRealConnection().getAutoCommit()) {
// 如果超期不还的连接没有设置自动提交事务
// 尝试替它提交回滚事务
try {
oldestActiveConnection.getRealConnection().rollback();
} catch (SQLException e) {
// 即使替它回滚事务的操作失败,也不抛出异常,仅仅做一下记录
log.debug("Bad connection. Could not roll back");
}
}
// 新建一个连接替代超期不还连接的位置
conn = new PooledConnection(oldestActiveConnection.getRealConnection(), this);
conn.setCreatedTimestamp(oldestActiveConnection.getCreatedTimestamp());
conn.setLastUsedTimestamp(oldestActiveConnection.getLastUsedTimestamp());
oldestActiveConnection.invalidate();
if (log.isDebugEnabled()) {
log.debug("Claimed overdue connection " + conn.getRealHashCode() + ".");
}
} else {
// 借出去最久的连接,并未超期
// 继续等待,等待有连接归还到连接池
try {
if (!countedWait) {
// 记录发生等待的次数。某次请求等待多轮也只能算作发生了一次等待
state.hadToWaitCount++;
countedWait = true;
}
if (log.isDebugEnabled()) {
log.debug("Waiting as long as " + poolTimeToWait + " milliseconds for connection.");
}
long wt = System.currentTimeMillis();
// 沉睡一段时间再试,防止一直占有计算资源
state.wait(poolTimeToWait);
state.accumulatedWaitTime += System.currentTimeMillis() - wt;
} catch (InterruptedException e) {
break;
}
}
}
}
if (conn != null) {
// 取到了连接
// 判断连接是否可用
if (conn.isValid()) {
// 如果连接可用
if (!conn.getRealConnection().getAutoCommit()) {
// 该连接没有设置自动提交
// 回滚未提交的操作
conn.getRealConnection().rollback();
}
// 每个借出去的连接都到打上数据源的连接类型编码,以便在归还时确保正确
conn.setConnectionTypeCode(assembleConnectionTypeCode(dataSource.getUrl(), username, password));
// 数据记录操作
conn.setCheckoutTimestamp(System.currentTimeMillis());
conn.setLastUsedTimestamp(System.currentTimeMillis());
state.activeConnections.add(conn);
state.requestCount++;
state.accumulatedRequestTime += System.currentTimeMillis() - t;
} else {
// 连接不可用
if (log.isDebugEnabled()) {
log.debug("A bad connection (" + conn.getRealHashCode() + ") was returned from the pool, getting another connection.");
}
state.badConnectionCount++;
localBadConnectionCount++;
// 直接删除连接
conn = null;
// 如果没有一个连接能用,说明连不上数据库
if (localBadConnectionCount > (poolMaximumIdleConnections + poolMaximumLocalBadConnectionTolerance)) {
if (log.isDebugEnabled()) {
log.debug("PooledDataSource: Could not get a good connection to the database.");
}
throw new SQLException("PooledDataSource: Could not get a good connection to the database.");
}
}
}
}
// 如果到这里还没拿到连接,则会循环此过程,继续尝试取连接
}
if (conn == null) {
if (log.isDebugEnabled()) {
log.debug("PooledDataSource: Unknown severe error condition. The connection pool returned a null connection.");
}
throw new SQLException("PooledDataSource: Unknown severe error condition. The connection pool returned a null connection.");
}
return conn;
}
因为上面的代码比较冗长,我们可以使用伪代码总结该流程。
在源码阅读过程中,有很多方法可以帮助我们梳理源码的执行流程,如流程图、伪代码、时序图等。它们能够让我们摆脱繁杂的细节去抓住整个程序执行的主线。而这些方法中,伪代码具有书写简单、与源码契合度高等特点,能够让我们更加专注于源码本身而不会囿于排版、绘制等无关的过程。因此,推荐大家使用伪代码进行源码的流程梳理。

- 收回池化连接的方法是 pushConnection方法
/**
* 收回一个连接
* @param conn 连接
* @throws SQLException
*/
protected void pushConnection(PooledConnection conn) throws SQLException {
synchronized (state) {
// 将该连接从活跃连接中删除
state.activeConnections.remove(conn);
if (conn.isValid()) {
// 当前连接是可用的
// 判断连接池未满 + 该连接确实属于该连接池
if (state.idleConnections.size() < poolMaximumIdleConnections && conn.getConnectionTypeCode() == expectedConnectionTypeCode) {
state.accumulatedCheckoutTime += conn.getCheckoutTime();
if (!conn.getRealConnection().getAutoCommit()) {
// 如果连接没有设置自动提交
// 将未完成的操作回滚
conn.getRealConnection().rollback();
}
// 重新整理连接
PooledConnection newConn = new PooledConnection(conn.getRealConnection(), this);
// 将连接放入空闲连接池
state.idleConnections.add(newConn);
newConn.setCreatedTimestamp(conn.getCreatedTimestamp());
newConn.setLastUsedTimestamp(conn.getLastUsedTimestamp());
// 设置连接为未校验,以便取出时重新校验
conn.invalidate();
if (log.isDebugEnabled()) {
log.debug("Returned connection " + newConn.getRealHashCode() + " to pool.");
}
state.notifyAll();
} else {
// 连接池已满或者该连接不属于该连接池
state.accumulatedCheckoutTime += conn.getCheckoutTime();
if (!conn.getRealConnection().getAutoCommit()) {
conn.getRealConnection().rollback();
}
// 直接关闭连接,而不是将其放入连接池中
conn.getRealConnection().close();
if (log.isDebugEnabled()) {
log.debug("Closed connection " + conn.getRealHashCode() + ".");
}
conn.invalidate();
}
} else {
// 当前连接不可用
if (log.isDebugEnabled()) {
log.debug("A bad connection (" + conn.getRealHashCode() + ") attempted to return to the pool, discarding connection.");
}
state.badConnectionCount++;
}
}
}
伪代码:

3. 池化数据源中连接的等价性
一个数据源的连接池必须保证池中的每个连接都是等价的,PooledDataSource 通过存储在expectedConnectionTypeCode 中的数据源连接类型编码来保证这一点。PooledDataSource 在每次给出连接时会给连接写入编码,在收回连接时会校验编码。这就避免了非本池的连接被放入该连接池。
但是大家可能还有一个疑问:在 PooledDataSource对象建立并使用一段时间之后,会有一些连接被给出,有一些连接尚在连接池中空闲。如果这时我们将其数据库的 driver、url、username、password 中的一个或者多个属性改变后会发生什么?会不会导致连接池中存在属性不同的两批PooledConnection对象呢?
对于 PooledDataSource 而言,它的 Connection 对象是由属性 dataSource 持有的UnpooledDataSource对象给出的。而driver、url、username、password这些属性就存在于这个UnpooledDataSource对象中。要想修改 driver、url、username、password 等属性,则必须调用 PooledDataSource的 setDriver、setUrl、setUsername、setPassword等方法。
public void setUrl(String url) {
dataSource.setUrl(url);
forceCloseAll();
}
public void setUsername(String username) {
dataSource.setUsername(username);
forceCloseAll();
}
public void setPassword(String password) {
dataSource.setPassword(password);
forceCloseAll();
}
/**
* 将活动和空闲的连接全部关闭
*/
public void forceCloseAll() {
synchronized (state) {
// 增加同步锁
// 重新计算和更新连接类型编码
expectedConnectionTypeCode = assembleConnectionTypeCode(dataSource.getUrl(), dataSource.getUsername(), dataSource.getPassword());
// 依次关闭所有的活动连接
for (int i = state.activeConnections.size(); i > 0; i--) {
try {
PooledConnection conn = state.activeConnections.remove(i - 1);
conn.invalidate();
Connection realConn = conn.getRealConnection();
if (!realConn.getAutoCommit()) {
realConn.rollback();
}
realConn.close();
} catch (Exception e) {
// ignore
}
}
// 依次关闭所有的空闲连接
for (int i = state.idleConnections.size(); i > 0; i--) {
try {
PooledConnection conn = state.idleConnections.remove(i - 1);
conn.invalidate();
Connection realConn = conn.getRealConnection();
if (!realConn.getAutoCommit()) {
realConn.rollback();
}
realConn.close();
} catch (Exception e) {
// ignore
}
}
}
if (log.isDebugEnabled()) {
log.debug("PooledDataSource forcefully closed/removed all connections.");
}
}
发现 setDriver、setUrl、setUsername、setPassword 等方法都调用了 forceCloseAll方法。
在 forceCloseAll方法中,会将所有的空闲连接和活动连接全部关闭。因此,如果在 PooledDataSource 对象建立并使用一段时间之后,再将其数据库的driver、url、username、password 中的一个或者多个属性进行改变,会导致所有的活动连接和空闲连接都被关闭。不会出现连接池中存在属性不同的两批PooledConnection 对象的情况。这种机制便保证了池化数据源中的连接始终是等价的。
4.3 池化连接
当我们要关闭一个非池化的数据库连接时,该连接会真正地关闭;而当我们要关闭一个池化连接时,它不应该真正地关闭掉,而是应该将自己放回连接池。正因为如此,通过PooledDataSource获得的数据库连接不能是普通的Connection类的对象。
pooled子包中存在一个 PooledConnection类,该类是普通Connection类的代理类。它的一个重要工作就是修改Connection类的 close方法的行为。该代理将 Connection对象的关闭方法过滤出来,替换成归还到连接池的操作,而不是真正地关闭连接。
PooledConnection 类继承了 InvocationHandler 接口成为一个动态代理类,直接查看其 invoke方法。
/**
* 代理方法
* @param proxy 代理对象,未用
* @param method 当前执行的方法
* @param args 当前执行的方法的参数
* @return 方法的返回值
* @throws Throwable
*/
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
// 获取方法名
String methodName = method.getName();
if (CLOSE.hashCode() == methodName.hashCode() && CLOSE.equals(methodName)) {
// 如果调用了关闭方法
// 那么把Connection返回给连接池,而不是真正的关闭
dataSource.pushConnection(this);
return null;
}
try {
// 校验连接是否可用
if (!Object.class.equals(method.getDeclaringClass())) {
checkConnection();
}
// 用真正的连接去执行操作
return method.invoke(realConnection, args);
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
}
5.论数据源工厂
在阅读 DataSourceFactory实现类的源码时,我们可能会隐隐察觉到它们并不是典型的工厂。通常情况下,典型的工厂工作流程。

工厂的产品是在最后一个阶段才生产出来的,不断调用最后一个阶段可以产生多个产品。而 JndiDataSourceFactory 的产品是在设置工厂产品属性阶段生成的,UnpooledDataSourceFactory 的产品是在工厂初始化阶段产生的。datasource 包中工厂的工作流程:
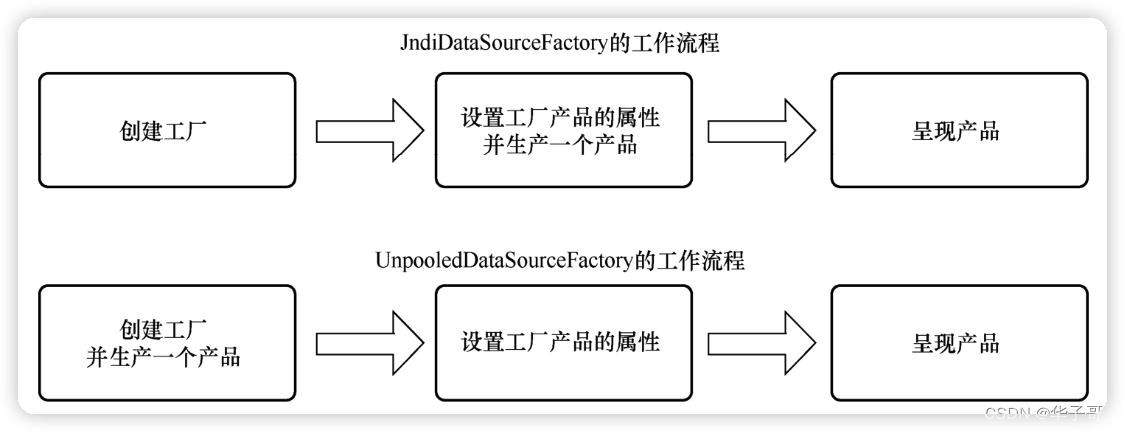
工厂流程会带来以下几个问题。
- 设置工厂产品的属性会导致已出厂的产品受到影响。例如,通过调用 getDataSource方法拿到 DataSource 对象后,对工厂调用 setProperties 方法会影响已经拿到的DataSource对象。
- 多次获取工厂产品却只能拿到同一个产品。例如,多次调用getDataSource 方法拿到的是同一个对象,成了一种单例模式。