大家好,我是龙一,专注AI轻创副业项目分享,今天给大家分享一款阿里近日推出的开源的图片生成视频的Ai工具,目前可免费使用,没有使用次数的限制,效果非常好,不得不说比RunwayGen2香多了。
可以根据用户输入的静态图像和文本生成目标接近、语义相同的视频,生成的视频具高清(1280 * 720)、宽屏(16:9)、时序连贯、质感好等特点。
这个项目的名字叫I2VGen-XL,由阿里达摩院研发的高清视频生成基础模型,旨在解决根据输入图像生成高清视频任务。生成的视频还支持二次修改和高清化,你要是觉得不满意可以多点几下重新生成,内容要是不满意还可以输入提示词调整视频内容、运镜、运动方向等等,输出高清视频。
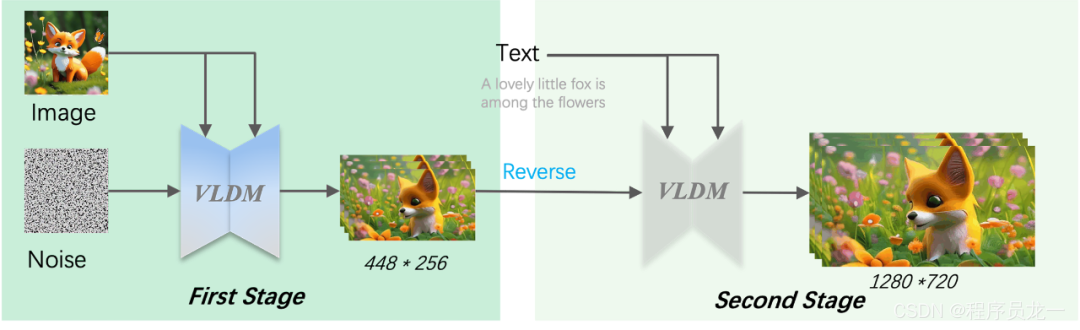
具体的原理如下,参数量共计约37亿,总结下来分为两个阶段,就是通过输入图片生成图片序列,然后可以通过文字进行微调并生成高清图片。
下面展示一下具体的生成的案例,由于文章无法放入视频,我选择插入gif图片,展示效果会大打折扣,想搞完整高清的可以去我的视频号看最新视频介绍。左边是原图,右边是生成的效果。






同时还支持自己部署,不过对于设备的要求比较高。I2VGen-XL包含2个模型:图片生成视频模型MS-Image2Video和视频生成视频模型MS-Vid2Vid。
MS-Image2Video建立在Stable Diffusion之上,如给出的原理图所示,通过专门设计的时空UNet在隐空间中进行时空建模并通过解码器重建出最终视频。
在1*A100的环境配置下运行 (可以单卡运行, 图生视频模型显存要求20G,视频生成视频显存要求28G)
torch2.0.1+cu117,python>=3.8
安装miniconda
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
一直[ENTER], 最后一个选项yes即可
sh Miniconda3-latest-Linux-x86_64.sh
conda虚拟环境搭建
conda create --name ms-sft python=3.8
conda activate ms-sft
安装最新的ModelScope
pip install "modelscope" --upgrade -f https://pypi.org/project/modelscope/
确定你的系统安装了ffmpeg命令,如果没有,可以通过以下命令来安装
sudo apt-get update && apt-get install ffmpeg libsm6 libxext6 -y
安装依赖库
pip install xformers==0.0.20
pip install torch==2.0.1
pip install torchsde
pip install open_clip_torch>=2.0.2
pip install opencv-python-headless
pip install opencv-python
pip install einops>=0.4
pip install rotary-embedding-torch
pip install fairscale
pip install scipy
pip install imageio
pip install pytorch-lightning
下载好模型,模型链接后台回复Ai视频即可获取。
通过以下代码,实现模型的下载和推理。
第一步:图生视频 (所需显存单卡20G)
from modelscope.pipelines import pipeline
from modelscope.outputs import OutputKeys
pipe = pipeline(task="image-to-video", model='damo/Image-to-Video', model_revision='v1.1.0')
IMG_PATH: your image path (url or local file)
IMG_PATH = './example.png'
output_video_path = pipe(IMG_PATH, output_video='./output.mp4')[OutputKeys.OUTPUT_VIDEO]
print(output_video_path)
第二步:提升视频分辨率 (所需显存单卡28G)
pipe =pipeline(task="video-to-video", model='damo/Video-to-Video', model_revision='v1.1.0')
# VID_PATH: your video path
# TEXT : your text description
VID_PATH = './output.mp4'
TEXT = 'A lovely little fox is among the flowers.'
p_input = {
'video_path': VID_PATH,
'text': TEXT
}
output_video_path = pipe(p_input, output_video='./output.mp4')[OutputKeys.OUTPUT_VIDEO]
print(output_video_path)
如果自己不想部署,想白嫖的兄弟,公z号【龙一的编程life】后台回复Ai视频获取体验链接。
其他更多Ai干货看我往期作品!
好了内容分享到这里就结束了,我是龙一,持续为大家分享AI+自媒体的干货,请大家多多关注点赞!