作者:英特尔软件应用工程师 周兆靖
本文目的
市面上有很多自然语言处理模型,本文旨在帮助开发者快速将OpenAI*的热门NLP模型Whisper部署至英特尔® 开发套件 艾克斯开发板上,由于开发板内存有限,所以我们选择较轻量化的Base Whisper模型通过OpenVINO™工具套件进行AI推理部署。由于声音处理应用的广泛性,开发者可以基于本项目继续进行AI应用的顶层开发。
项目介绍
语音识别是人工智能中的一个领域,它允许计算机理解人类语音并将其转换为文本。 该技术用于 Alexa* 和各种聊天机器人应用程序等设备。 而我们最常见的就是语音转录,语音转录可以语音转换为文字记录或字幕。通过输入音频,通过OpenVINO™优化过的Whisper模型,将音频进行AI处理,最后输出音频处理结果。此结果可以根据开发者不同的需求,继续进行再次开发。
英特尔®开发套件——艾克斯开发板简介
英特尔®认证的开发套件——AIxBoard(爱克斯板*)开发板是专为支持入门级边缘AI应用程序所设计的嵌入式硬件,它能够满足开发者对于人工智能学习、开发、实训等应用场景的使用需求。
基于x86平台所设计的开发板,可支持Linux* Ubuntu*及 完整版Windows*操作系统,很方便开发者进行软硬件开发,以及尝试所有x86平台能够应用的软件功能。开发板搭载一颗英特尔®赛扬®N5105 4核4线程处理器,睿频可达2.9 GHz,且内置英特尔® 超核芯显卡,含有24个执行单元,分辨率最大支持4K60帧,同时支持英特尔® Quick Sync Video 技术可以快速转换便携式多媒体播放器的视频。板载 64GB eMMC存储及LPDDR4x 2933MHz(4GB/6GB/8GB),内置蓝牙和Wi-Fi模组,支持USB 3.0、HDMI视频输出、3.5mm音频接口,1000Mbps以太网口。
此外, 其接口与Jetson Nano载板兼容,GPIO与树莓派兼容,能够最大限度地复用树莓派、Jetson Nano等生态资源,无论是摄像头物体识别,3D打印,还是CNC实时插补控制都能稳定运行。可作为边缘计算引擎用于人工智能产品验证、开发;也可以作为域控核心用于机器人产品开发。

图1:艾克斯板硬件参数

图2:艾克斯板实物拍摄
OpenVINO™工具套件介绍
OpenVINO™是一个开源工具包,可优化和部署深度学习模型。它提供了针对视觉、音频和语言模型的深度学习性能加速,支持流行框架如TensorFlow、PyTorch等。
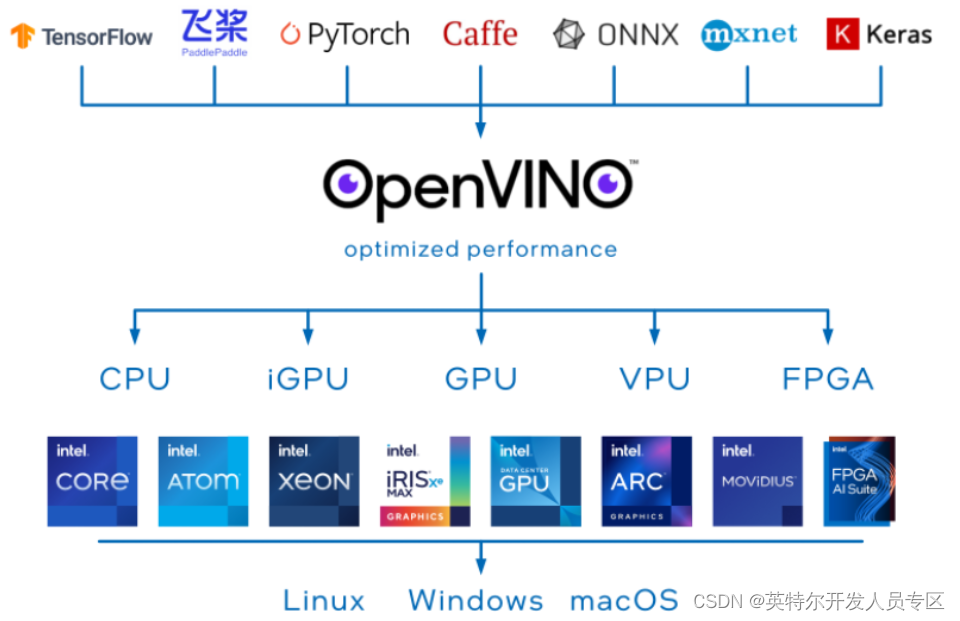
图3:OpenVINO™工具套件部署架构图
OpenVINO™可以优化几乎任何框架的深度学习模型,并在各种英特尔处理器和其他硬件平台上以最佳性能进行部署。OpenVINO™ Runtime可以自动使用激进的图形融合、内存重用、负载平衡和跨CPU、GPU、VPU等进行集成并行处理,以优化深度学习流水线。您可以集成和卸载加速器附加操作,以减少端到端延迟并提高吞吐量。通过OpenVINO™的后训练优化工具和神经网络压缩框架中提供的量化和其他最先进的压缩技术,进一步提高模型的速度。这些技术还可以减少模型的大小和内存需求,使其能够部署在资源受限的边缘硬件上。
Whisper模型介绍
Whisper来自于知名AI组织OpenAI*,这个模型是一种通用的语音识别模型。它是在各种音频的大型数据集上训练的,也是一个多任务模型,可以执行多语言语音识别、语音翻译和语言识别。
wav2vec2、Conformer 和 Hubert 等最先进模型的最新发展极大地推动了语音识别领域的发展。 这些模型采用无需人工标记数据即可从原始音频中学习的技术,从而使它们能够有效地使用未标记语音的大型数据集。 它们还被扩展为使用多达 1,000,000 小时的训练数据,远远超过学术监督数据集中使用的传统 1,000 小时,但是以监督方式跨多个数据集和领域预训练的模型已被发现表现出更好的鲁棒性和对持有数据集的泛化,所以执行语音识别等任务仍然需要微调,这限制了它们的全部潜力 。 为了解决这个问题OpenAI 开发了 Whisper,一种利用弱监督方法的模型。
 图4:Whisper模型框图
图4:Whisper模型框图
主要采用的结构是编码器-解码器结构。
模型的输入音频重采样设为16000 Hz,针对音频的特征提取方法是使用25毫秒的窗口和10毫秒的步幅计算80通道的log Mel谱图。最后对输入特征进行归一化,将输入在全局内缩放到-1到1之间,并且在预训练数据集上具有近似为零的平均值。
编码器/解码器:
该模型的编码器和解码器采用Transformers。
编码器的过程:
编码器首先使用一个包含两个卷积层(滤波器宽度为3)的词干处理输入表示,使用GELU激活函数。
第二个卷积层的步幅为 2,然后将正弦位置嵌入添加到词干的输出中,然后应用编码器 Transformer 块。
Transformers使用预激活残差块,编码器的输出使用归一化层进行归一化。
解码的过程:
在解码器中,使用了学习位置嵌入和绑定输入输出标记表示。
编码器和解码器具有相同的宽度和数量的Transformers块。
训练:
为了改进模型的缩放属性,它在不同的输入大小上进行了训练。
通过 FP16、动态损失缩放,并采用数据并行来训练模型。
使用AdamW和梯度范数裁剪,在对前 2048 次更新进行预热后,线性学习率衰减为零。
使用 256 个批大小,并训练模型进行 220次更新,这相当于对数据集进行两到三次前向传递。
Whisper在不同数据集上的对比结果,相比wav2vec取得了目前最低的词错误率,如下表:
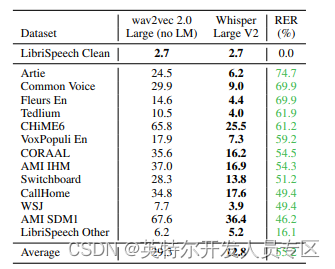
图5:Whisper模型与wav2vec词错误率对比表
项目流程
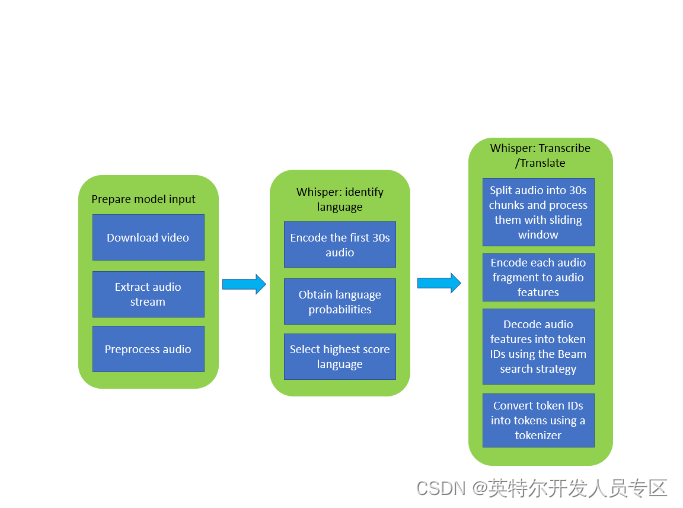
图6:Whisper模型语音处理流程图
利用Whisper模型进行视频文字识别的流程如上,首先准备语音文件,常规操作是将语音流从视频流中分离,然后通过Whisper模型编码语音文件的前30秒,输出该语音文件对于的语言种类的多种可能性,选择可能性最高的一种语言继续进行编码。将整段语音文件分割成多个30秒的小段进行编码,再通过Beam搜索算法将音频特征都转为token ID, 最后将token ID翻译成tokens就可以获得识别到的文本了。
使用OpenVINO™工具套件对Whisper模型进行推理加速,主要在Encoder和Decoder上使用OpenVINO™ Runtime,对应到流程图中,我们在不更改主体pipeline的前提下,OpenVINO™为流程中的“Positional Encoding”和“Cross attention”赋能,代码实现层面就是使用OpenVINO™ Runtime API替换掉原先的Encoder和Decoder,使得OpenVINO™得以加入到这个音频处理流程中,如下图所示:
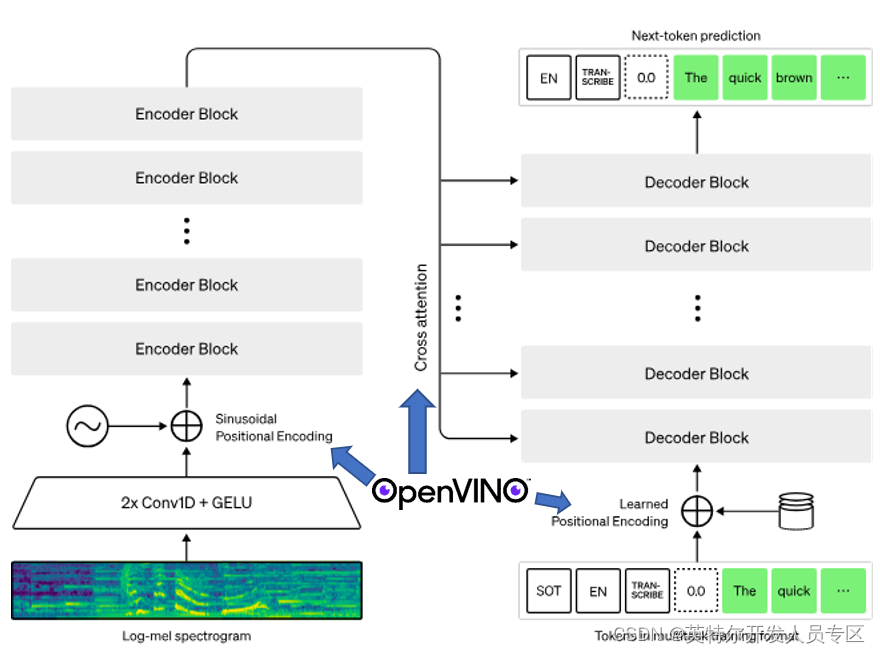
图7:OpenVINO™赋能Whisper模型项目示意图
实验流程
硬件:英特尔®开发套件——艾克斯开发板
OS:Ubuntu 20.04LTS
软件:OpenVINO™ 2023.0,Whisper
由于Whisper预训练模型根据参数量分为Tiny, Base, Small, Medium, Large。本次实验中选择参数量为74M的base模型进行实验,使用预训练模型直接通过OpenVINO™的模型优化器API转换为IR格式文件,将Whisper的编解码器构建成流水线,便可对视频进行语音转文字的AI处理了。
安装依赖:
为实现最快速的部署,我们直接下载OpenVINO™ Open Model Zoo里的现成Notebook进行实验。
Git clone https://github.com/openvinotoolkit/ openvino_notebooks.git构建虚拟环境,安装OpenVINO™,Whisper以及其他依赖:
python3 -m venv openvino_env
source env/bin/activate命令行中运行如下pip安装指令:
pip install openvino
pip install -q "python-ffmpeg<=1.0.16" moviepy transformers onnx
python -m pip install pytube
pip install -q -U gradio
pip install git+https://github.com/openai/whisper.git
进入notebooks/227-whisper-subtitles-generation/目录中,安装Jupyter Notebook并打开227-whisper-convert.ipynb文件:
pip install notebook
jupyter notebook
下面进入227-whisper-convert.ipynb文件中运行代码
首先,下载Whisper现成的预训练模型,代号为“base”
import whisper
model = whisper.load_model("base")
model.to("cpu")
model.eval()
pass
模型主要是编码器-解码器的结构,所以我们先把Encoder部分被转成IR模型,保存至本地:
import torch
import openvino as ov
mel = torch.zeros((1, 80, 3000))
audio_features = model.encoder(mel)
encoder_model = ov.convert_model(model.encoder, example_input=mel)
ov.save_model(encoder_model, WHISPER_ENCODER_OV)
后把模型的Decoder部分也转成IR模型,保存至本地:
tokens = torch.ones((5, 3), dtype=torch.int64)
logits, kv_cache = model.decoder(tokens, audio_features, kv_cache=None)
tokens = torch.ones((5, 1), dtype=torch.int64)
decoder_model = ov.convert_model(model.decoder, example_input=(tokens, audio_features, kv_cache))
ov.save_model(decoder_model, WHISPER_DECODER_OV)
创建core对象,启用OpenVINO™ Runtime:
core = ov.Core()推理设备选择“AUTO”Plugin,表示自动选择当前系统最优的推理硬件:
device = widgets.Dropdown(
options=core.available_devices + ["AUTO"],
value='AUTO',
description='Device:',
disabled=False,
)
我们的实验将复用原生模型处理音频的pipeline,只需要将原来的编码器和解码器用OpenVINO™ Runtime API重写,即可得到OpenVINO™加速过的pipeline。
当前文件目录下包含“utils.py”,此脚本中集成了三个最重要的类,分别是patch_whisper_for_ov_inference, OpenVINOAudioEncoder, OpenVINOTextDecoder。patch_whisper_for_ov_inference主要提供了一些功能函数,比如获取音频,增加时间戳,生成字幕文件等等。另外两个类在这里的作用是使用OpenVINO™ Runtime API对原始模型Encoder和Decoder进行重写,利用OpenVINO™ Runtime替换掉原始模型中的Encoder和Decoder以加速优化模型运行的速度。
from utils import patch_whisper_for_ov_inference, OpenVINOAudioEncoder, OpenVINOTextDecoder
patch_whisper_for_ov_inference(model)
model.encoder = OpenVINOAudioEncoder(core, WHISPER_ENCODER_OV, device=device.value)
model.decoder = OpenVINOTextDecoder(core, WHISPER_DECODER_OV, device=device.value)
最终,调用model.transcribe函数,运行AI推理,并将生成的字幕文件保存为srt格式文件:
output_file = Path("downloaded_video.mp4")
from utils import get_audio
audio = get_audio(output_file)
task = widgets.Select(
options=["transcribe", "translate"],
value="translate",
description="Select task:",
disabled=False
)
task
transcription = model.transcribe(audio, task=task.value)
from utils import prepare_srt
srt_lines = prepare_srt(transcription)
# save transcription
with output_file.with_suffix(".srt").open("w") as f:
f.writelines(srt_lines)
注意,由于Notebook提供的视频是YTB的视频,可能遇到无法下载的情况,这里我们也提供了一小段英文视频可供读者自由下载:http://985.so/2nu1c只需将下载视频替换notebook里的视频路径即可体验AI字幕的功能。
结果展示:
原视频截图:

图8:未进行字幕识别的原始视频截图
视频播放软件可以直接导入SRT字幕文件生成字幕:
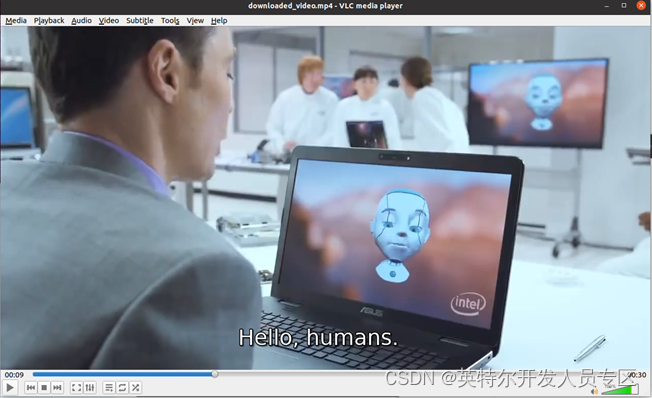
图9:已经进行字幕识别的原始视频截图
小结
英特尔®认证的开发套件—— 艾克斯开发板以Intel® Celeron™ N5105作为处理核心,在相同的功耗下获得了优秀的计算性能。在本次实验中,它在OpenVINO™工具套件的加持下可以轻松完成语音转文字的任务,通过轻量化AI模型(Whisper)实现字幕实时生成的功能。回顾之前搭建流媒体服务器的文章,我们可以使用开发板搭建一个RTMP流媒体服务器,然后可以将它们结合,将输入服务器的视频流实时生成字幕之后进行输出,这样就可以获得一个能给视频加英文字幕的流媒体服务器。艾克斯板的I/O接口丰富,摄像头,麦克风,传感器都可以进行接入,并且开发板有着不错的CPU处理性能,可以在OpenVINO™工具套件的加持下处理一些常规的AI推理任务,开发者可以根据项目需求进行巧妙搭配,组合创新。作为英特尔®认证的开发套件,这块小小的开发板却蕴含着巨大的能量,可以兼容市面上大多数的扩展设备,也可以应用上英特尔提供的软硬件技术,加上集成显卡能为编解码处理与AI推理赋能,这块板子还是能创造出许多有趣的应用的。如果你对这块开发板感兴趣,那就赶快行动起来,开始你的开发创造之旅吧。