我们在项目中通常会碰到查重,也就是查看数据库中是否已经存在某条记录的情况,存在则update否则insert,那么通常我们都会用count函数去统计总数,如果是大于0就认为存在,那么有没有更简单快捷的办法呢,答案是有的,就是把select count(1) where.... 改成select 1 where...limit 1;,废话不多说,直接上代码:
1、准备数据:准备一张订单表,里面只有一个主键id字段和订单id,然后往里面插入100w条数据
CREATE TABLE `t_order` (
`id` int NOT NULL AUTO_INCREMENT,
`order_id` int DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1001001 DEFAULT CHARSET=utf8mb3;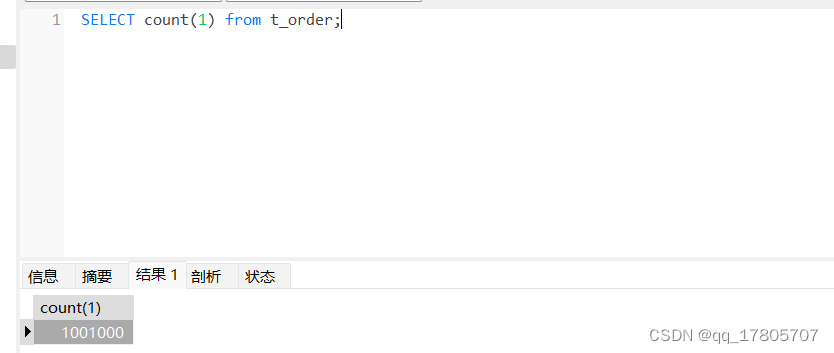
2、实验:
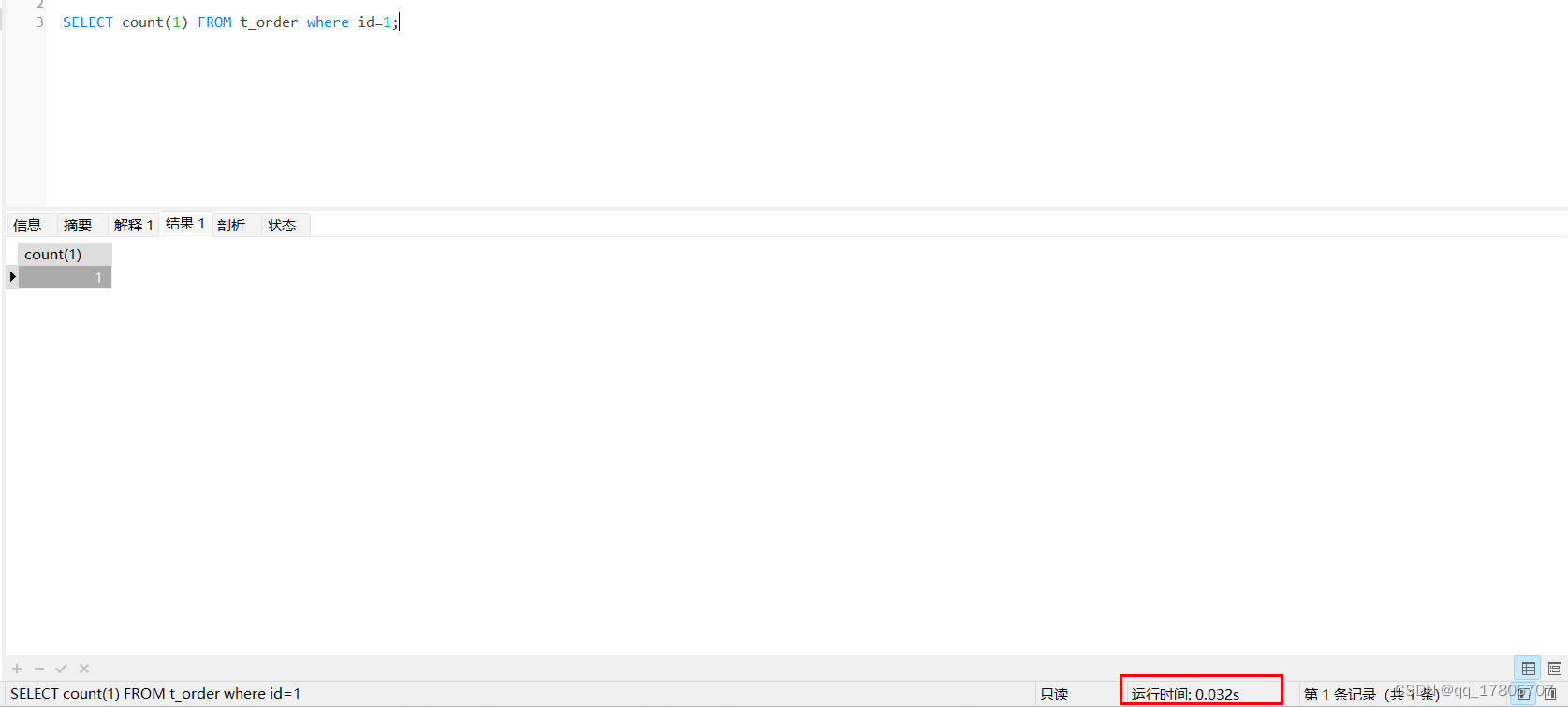
场景1:根据主键id查看数据是否存在:SELECT count(1) FROM t_order where id=1;
我们知道这个sql一定会走主键索引的:

我们用select 1的方式改写这个sql:

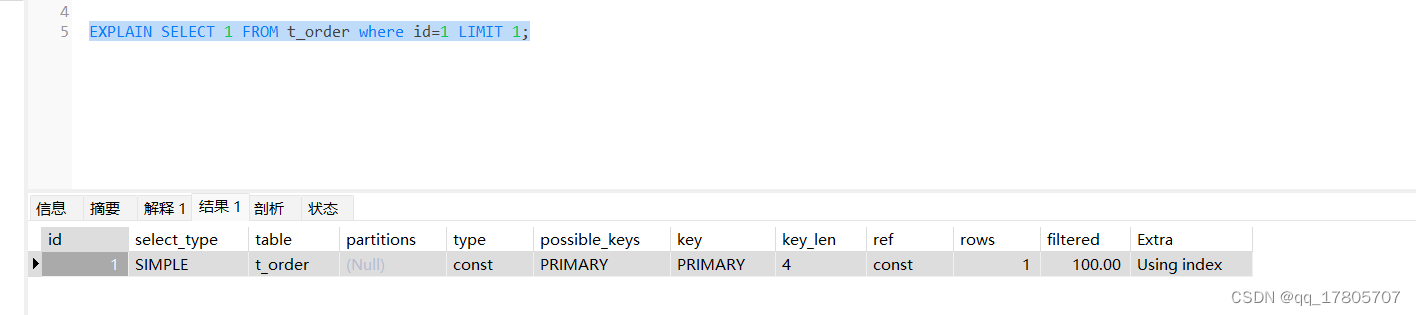
执行时间和索引使用情况是一模一样的
结论1:在使用主键索引的时候两种sql执行效率和索引使用情况一样
场景2:我们给order_id字段加上索引,然后根据order_id字段去查询,加索引的操作就不在这里演示了:
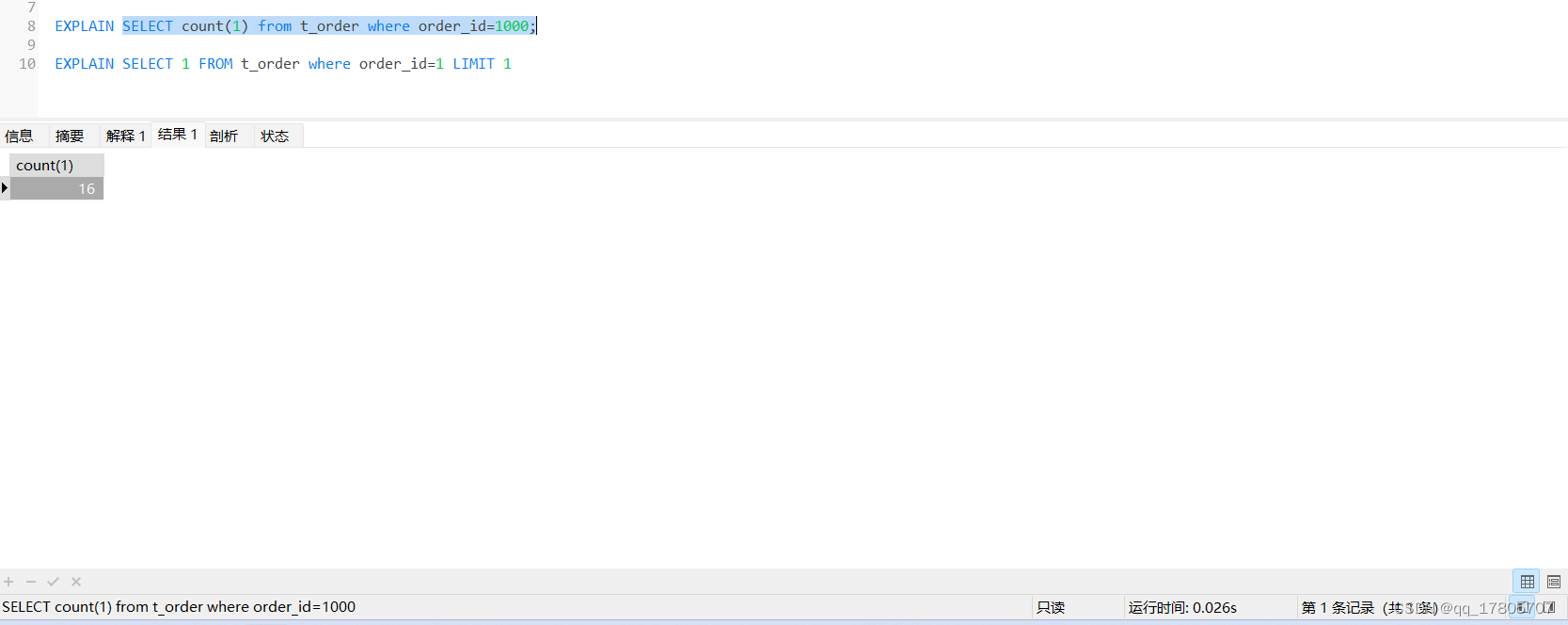
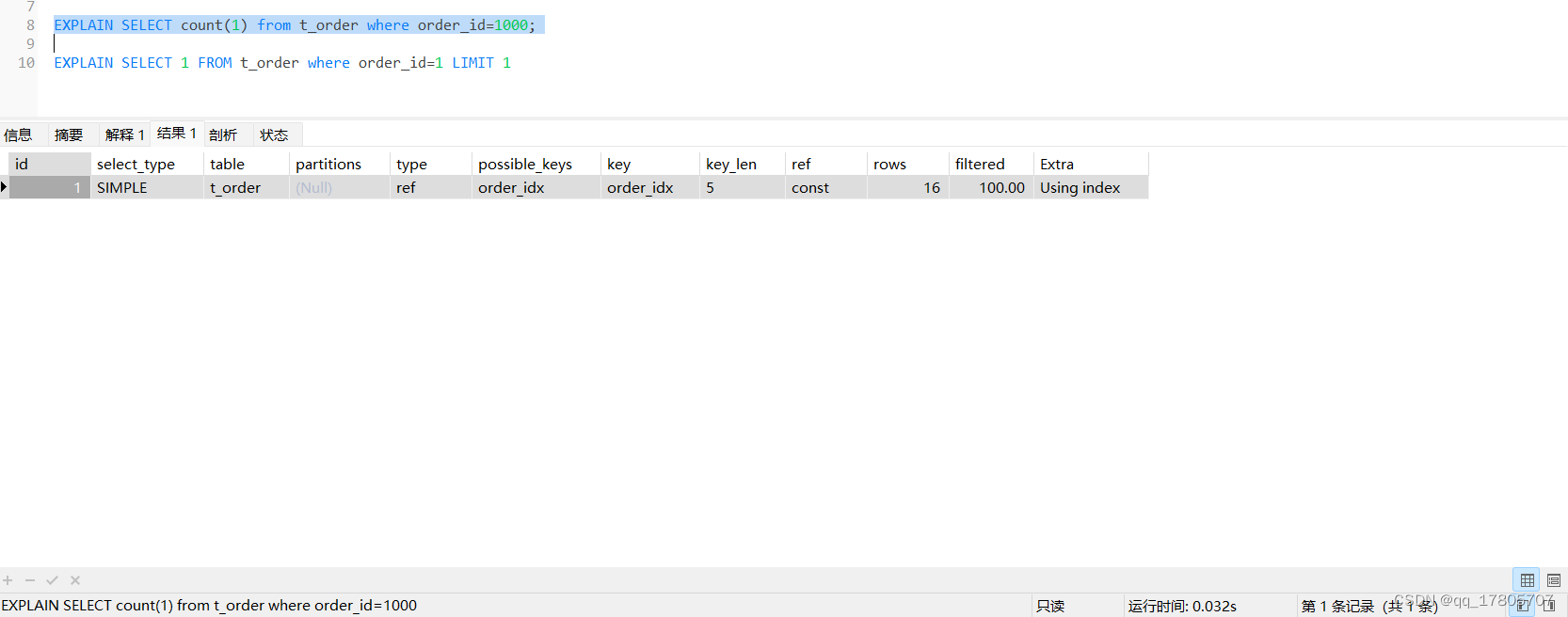
效率与场景1差不多,只是索引使用情况不一样,用select 1的方式改写:
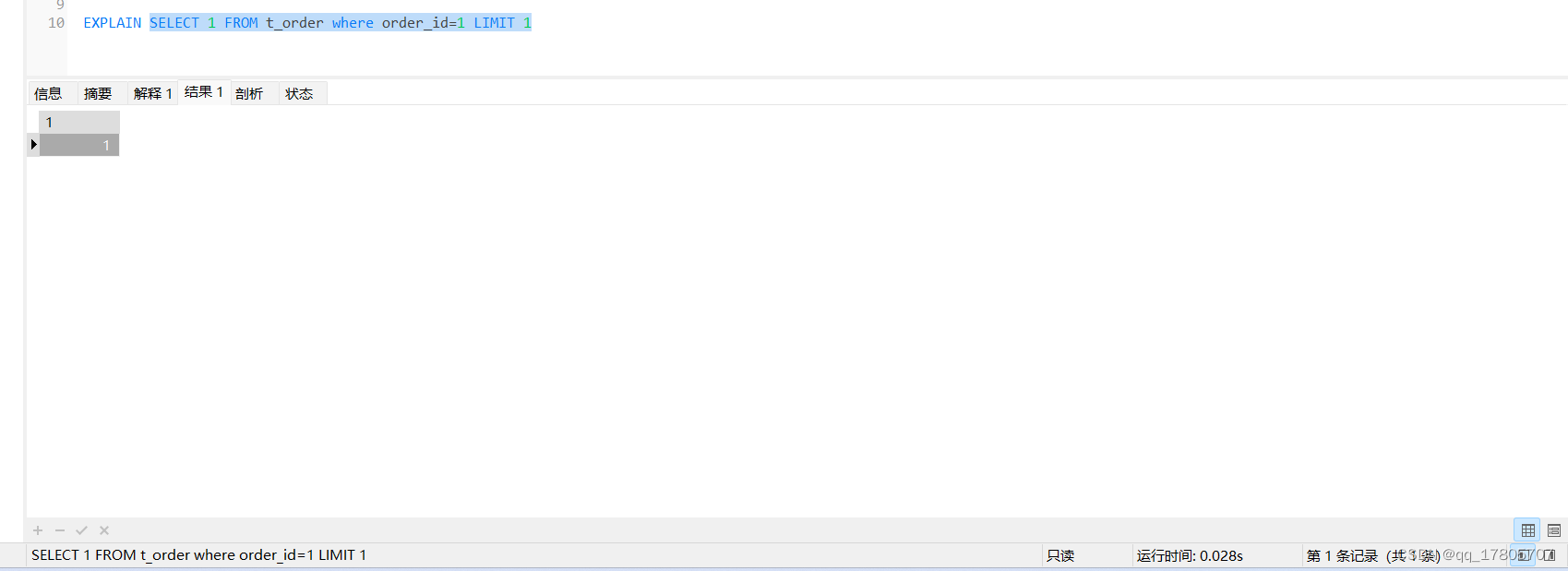

可见两种情况几乎是一模一样
结论2:当where后面的字段有索引的时候,两种写法执行效率差不多
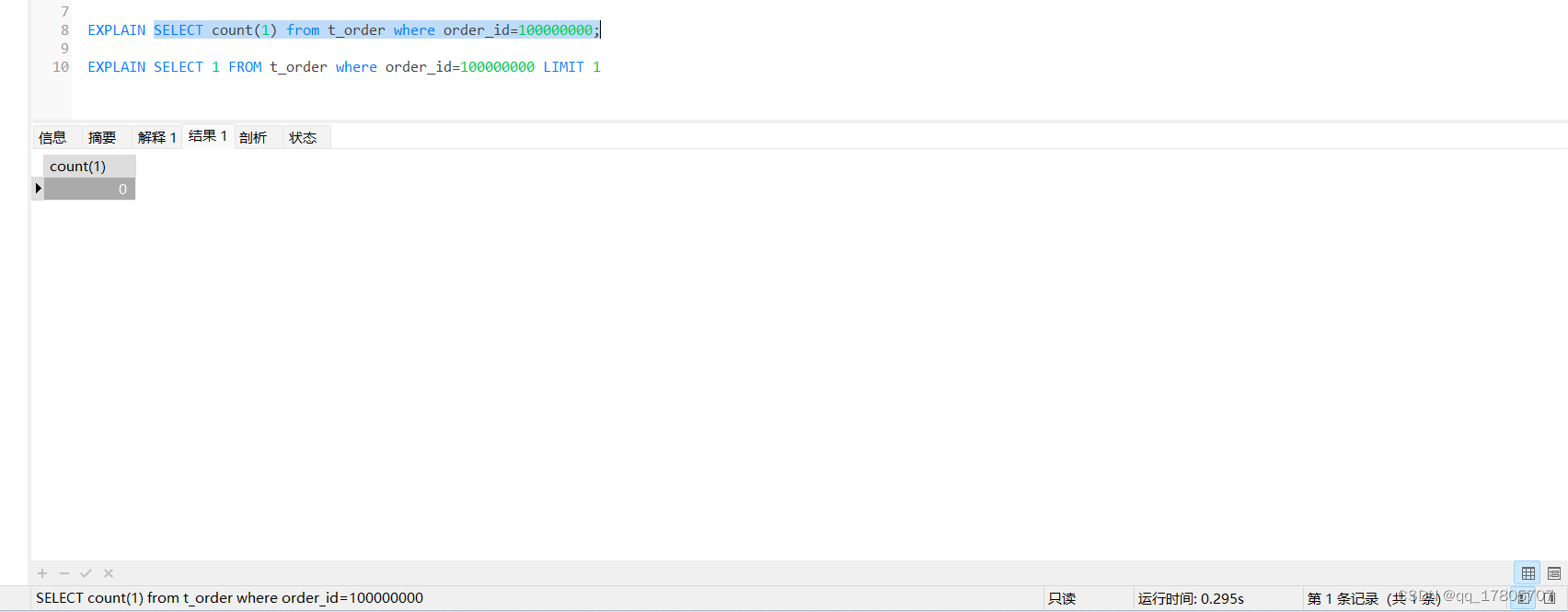
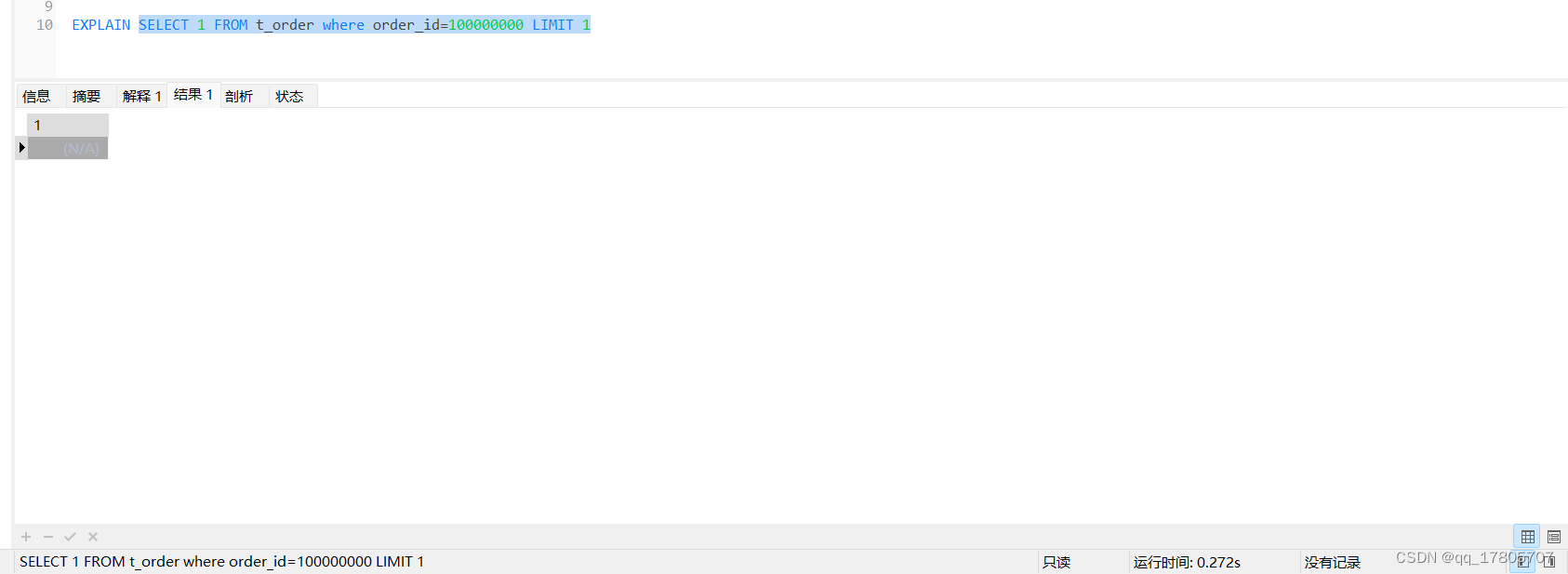
场景3:我们去掉order_id字段上面的索引,再执行场景2的两种sql:


用select 1的方式:
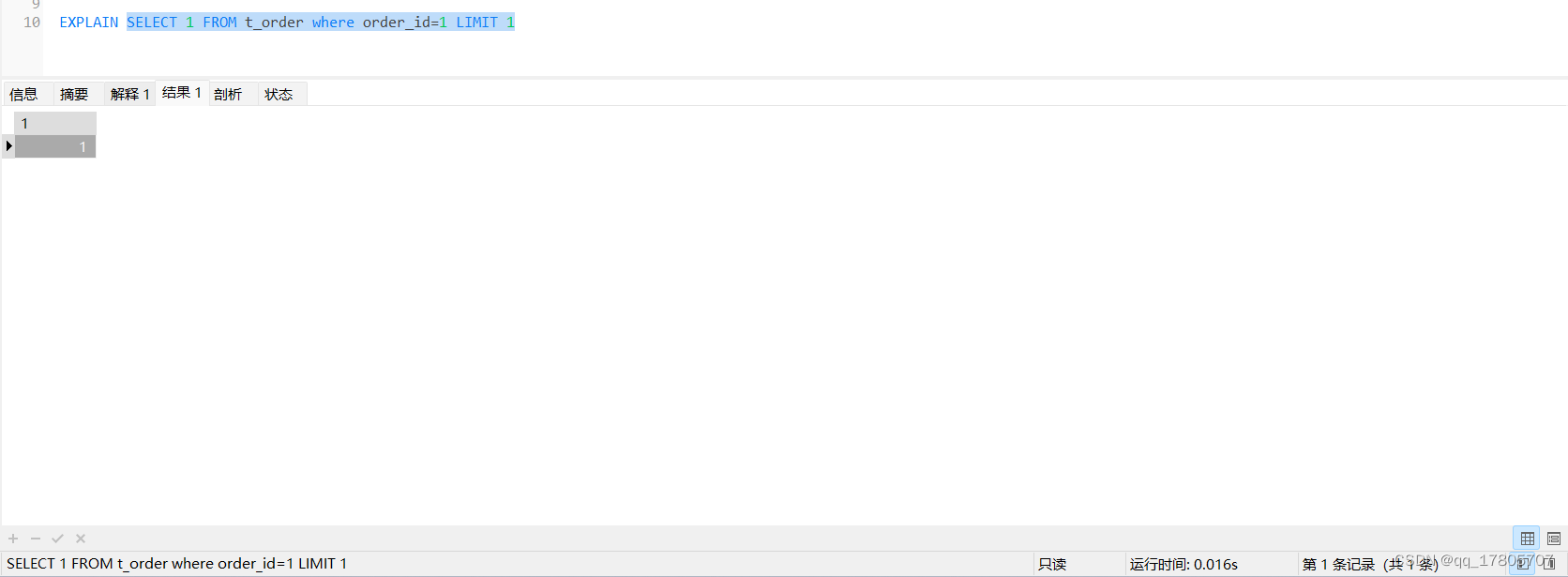

结论3:在没有使用到索引的情况下,select 1的执行效率比count快一个数量级
总结:在查看数据库是否存在某一条记录的时候,推荐使用select 1 where ....limit 1;这种写法,如果存在返回的是1,不存在则返回的是null,那么在代码里面只需要判断结果是否为null即可,其实大家可以想象的到,count是要逐行扫描进行统计的,select 1 只需要取第一行数据,效率当然要更快
ps:如果where 后面跟的条件最终没有查出数据,那么不论是哪种场景,两种sql的执行效率都是差不多的: