一、什么是多进程
要让Python程序实现多进程(multiprocessing),我们先了解操作系统的相关知识。Unix/Linux操作系统提供了一个fork() 系统调用,它非常特殊。普通的函数调用,调用一次,返回一次,但是fork()调用一次,返回两次,因为操作系统自动把当前进程(称为父进程)复制了一份(称为子进程),然后,分别在父进程和子进程内返回。子进程永远返回0,而父进程返回子进程的ID。这样做的理由是,一个父进程可以fork出很多子进程,所以,父进程要记下每个子进程的ID,而子进程只需要调用getppid()就可以拿到父进程的ID。
Python的 os 模块封装了常见的系统调用,其中就包括fork,可以在Python程序中轻松创建子进程:
这里我们也可以理解为创建了一个进程
import os
# os.getpid()获取当前进程的PID号;
print("主进程%s正在启动....." %(os.getpid()))
# 创建子进程
# 会返回2个值, 一个为0, 一个为非0;
# 子进程永远返回的是0, 父进程返回的是子进程的pid;
# 父进程里面会有很多子进程, 必须记录子进程的pid号;
pid = os.fork()
if pid == 0:
print("这是一个子进程, pid为%d, 父进程的pid为%d" %(os.getpid(), os.getppid()))
else:
print("这个是父进程, 创建了一个子进程, 子进程id为%s" %(pid))

我们能够看到上面的运行结果,来尝试理解一下:主进程就为这个脚本本身的运行环境我们也可以在shell下通过top命令来查看他们的关系(查看他们的进程PID);
有了fork调用,一个进程在接到新任务时就可以复制出一个子进程来处理新任务,常见的Apache服务器就是由父进程监听端口,每当有新的http请求时,就fork出子进程来处理新的http请求。
二、multiprocessing--创建多个进程
如果你打算编写多进程的服务程序,Unix/Linux无疑是正确的选择。由于Windows没有fork调用,难道在Windows上无法用Python编写多进程的程序?由于Python是跨平台的,自然也应该提供一个跨平台的多进程支持。multiprocessing模块就是跨平台版本的多进程模块。
multiprocessing模块提供了一个Process类来代表一个进程对象,下面的例子演示了启动一个子进程并等待其结束:
from multiprocessing import Process
import os
# 子进程要执行的代码
def run_proc(name):
print('Run child process %s (%s)...' % (name, os.getpid()))
if __name__=='__main__':
print('Parent process %s.' % os.getpid())
print('Child process will start.')
#这里相当于实例化了一个子进程;
p = Process(target=run_proc, args=('test',))
# 开始这个进程
p.start()
# 等待所有的子进程全部执行结束, 再执行主进程;
p.join()
print('Child process end.')

创建子进程时,只需要传入一个执行函数和函数的参数,创建一个Process实例,用start()方法启动,这样创建进程比fork()还要简单。join()方法可以等待子进程结束后再继续往下运行,通常用于进程间的同步。
上面我们只是实例化了一个子进程,如果需要我们可以实例化多个子进程,但是对于大批量的任务来说一个一个的创建子进程太过于浪费时间,虽然CPU的处理速度很快但是对于大批量的请求来说,CPU大部分的时间在等待环境的准备;结合上一节的内容,相同的在多进程任务中也有pool;
三、Pool--进程池
如果要启动大量的子进程,可以用进程池的方式批量创建子进程:
例子:
from multiprocessing import Pool
import os, time
def long_time_task(name):
print('运行任务...%s (pid:%s)...' % (name, os.getpid()))
start = time.time()
time.sleep(3)
end = time.time()
print('任务 %s 运行了 %0.2f seconds.' % (name, (end - start)))
def pool_main():
print('父进程 %s.' % os.getpid())
# 规定进程池的大小,可以同时处理4个进程
p = Pool(4)
# for循环了5次,可以理解为同时实例化了5个进程
for i in range(5):
p.apply_async(long_time_task, args=(i,))
print('等待所有子过程完成...')
p.close()
p.join()
print('所有子过程完成.')
if __name__=='__main__':
pool_main()
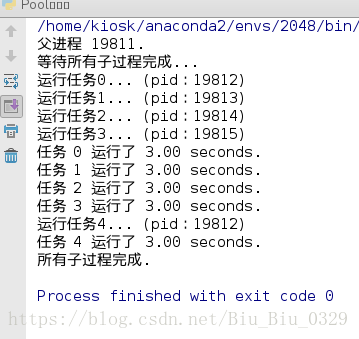
代码解读:
对Pool对象调用 join()方法会等待所有子进程执行完毕,调用 join() 之前必须先调用 close() ,调用 close() 之后就不能继续添加新的Process了。请注意输出的结果,task 0,1,2,3,是立刻执行的,而task 4要等待前面某个task完成后才执行,这是因为 Pool 的默认大小在我的电脑上是4,因此,最多同时执行4个进程。这是Pool有意设计的限制,并不是操作系统的限制。如果改成:
p = Pool(5)
结果如下:
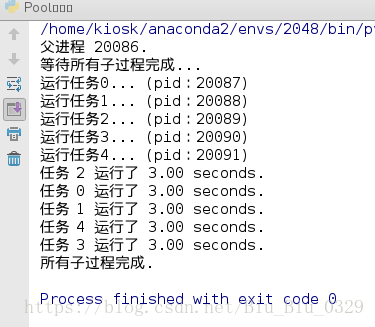
由于 Pool的默认大小是CPU的核数,如果你不幸拥有8核CPU,你要提交至少9个子进程才能看到上面的等待效果。
四、守护进程
概念:Daemon(守护进程)是运行在后台的一种特殊进程。它独立于控制终端并且周期性地执行某种任务或等待处理某些发生的事件。它不需要用户输入就能运行而且提供某种服务,不是对整个系统就是对某个用户程序提供服务。Linux系统的大多数服务器就是通过守护进程实现的。常见的守护进程包括系统日志进程syslogd、 web服务器httpd、邮件服务器sendmail和数据库服务器mysqld等。
守护进程一般在系统启动时开始运行,除非强行终止,否则直到系统关机都保持运行。守护进程经常以超级用户(root)权限运行,因为它们要使用特殊的端口(1-1024)或访问某些特殊的资源。
守护进程的父进程是init进程,因为它真正的父进程在fork出子进程后就先于子进程exit退出了,所以它是一个由init继承的孤儿进程。守护进程是非交互式程序,没有控制终端,所以任何输出,无论是向标准输出设备stdout还是标准出错设备stderr的输出都需要特殊处理。
守护进程的名称通常以d结尾,比如sshd、xinetd、crond等。
import multiprocessing
import os
import time
def work(num):
time.sleep(3)
print('work-%s' %(num))
# 获取当前进程的名称
print("进程%s正在运行, pid=%s" %(multiprocessing.current_process().name,
os.getpid()))
print("父进程:%s" %(os.getpid()))
jobs = []
for i in range(10):
name = "进程%s" %(i)
# 1. 创建多进程,name=xxx指定进程的名称;
p = multiprocessing.Process(name=name,target=work, args=(i,) )
# 设置为守护进程,
# 如果没有join方法时, 主进程结束, 子进程也结束;
# 如果有join方法, 主进程会等待所有子进程执行结束再执行;
p.daemon = True
# 跟多线程的类比
# import threading
# threading.Thread(target=work, args=(1,))
jobs.append(p)
# 启动多进程;
p.start() # 启动了一个进程,
for p in jobs:
# 等待所有的子进程全部执行结束, 再执行主进程;
p.join()
print("主进程结束, pid=%s, ppid=%d" %(os.getpid(), os.getppid()))
五、终止进程
isAlive()方法: 判断当前的线程是否处于活动状态
活动状态是指线程已经启动且尚未终止,线程处于正在运行或准备开始运行的状态,就认为线程是存活的
import multiprocessing
import os
import time
# p.terminate()强制终止结束进程, 结束之后通过join方法更新状态;
def work(num):
print('work-%s' %(num))
time.sleep(2)
# 获取当前进程的名称
print("进程%s正在运行, pid=%s" %(multiprocessing.current_process().name,
os.getpid()))
p = multiprocessing.Process(target=work, args=(1,))
print('Before:', p, p.is_alive())
p.start()
print('During:', p , p.is_alive())
# 结束进程的执行;
# p.terminate()
print("正在中之进程:", p, p.is_alive())
p.join()
print("更新状态后:", p, p.is_alive())
六、派生多进程
import os
import multiprocessing
import time
class Subprocess(multiprocessing.Process):
def __init__(self,num):
super(Subprocess, self).__init__()
# self.name = name
self.num = num
def run(self):
print('work-%s' % (self.num))
time.sleep(3)
print('进程%s 正在运行,pid = %s' % (multiprocessing.current_process().name, os.getpid()))
print("父进程:%s" % os.getpid())
jobs = []
for i in range(5):
# name = "进程%s" %(i)
p = Subprocess(i)
jobs.append(p)
p.start() # 3
# p.join()
# 1
for j in jobs:
j.join()
print("主进程结束,pid = %s"%(os.getpid()))