文章目录
Powered By Poe
一、数据全栈知识架构
数据开发
- 是指使用编程和技术工具来处理和管理数据的过程。它涉及从不同来源收集数据,清洗、转换和集成数据,构建和维护数据管道,以及将数据存储在适当的数据仓库或数据库中。数据开发还包括编写和维护数据处理脚本、作业和工作流程,以确保数据的质量、一致性和可靠性。
- 数据开发的目标是为数据科学家、分析师和业务用户提供可靠的和有意义的数据,以支持业务决策和洞察发现。数据开发人员与数据工程师、数据科学家和业务团队密切合作,理解业务需求,设计和实现数据解决方案,并确保数据的准确性和完整性。
- 数据开发通常涉及使用编程语言(如Python、SQL等)和技术工具(如ETL工具、数据流处理框架等)进行数据处理和转换。数据开发人员需要具备数据建模、数据库管理、数据仓库设计和数据治理等方面的知识,并熟悉数据处理流程和最佳实践。
- 总而言之,数据开发是数据管道的构建和维护过程,旨在支持数据驱动的决策和分析工作。它在现代数据驱动的组织中发挥着关键的作用,帮助实现数据的可靠性、可用性和可操作性。
数据开发人员需要具备以下技能和知识:
- 编程语言和脚本编写能力:数据开发人员应熟练掌握至少一种编程语言,如Python、SQL等,并能编写高效的脚本和代码来处理和转换数据。
- 数据库和数据仓库:理解关系型数据库和非关系型数据库的基本概念,熟悉SQL语言,能够设计和管理数据库表结构,以及进行高效的数据查询和操作。
- 数据处理和转换:具备数据清洗、转换和整合的技能,能够使用ETL(Extract, Transform, Load)工具或编程语言进行数据处理,解决数据质量问题和数据结构转换等任务。
- 数据模型和数据架构:了解数据建模和数据架构设计的原理和方法,能够设计和优化数据模型,确保数据的有效存储和检索。
- 数据流和数据管道:熟悉数据流处理框架(如Apache Kafka、Apache Flink等)和工作流调度工具(如Apache Airflow),能够构建和管理数据流和数据管道,实现实时数据处理和批处理任务。
- 数据质量和数据治理:了解数据质量管理和数据治理的概念和实践,能够制定和执行数据质量规则,确保数据的准确性、一致性和完整性。
- 版本控制和团队协作:熟悉版本控制系统(如Git)的使用,能够与团队成员协作开发和维护数据处理代码和工作流程。
- 业务理解和沟通能力:具备对业务需求的理解和分析能力,能够与数据科学家、分析师和业务团队有效沟通,理解他们的需求并提供相应的数据解决方案。
1、数据方法(思维,统计学,实践,北极星)
数据方法是指在处理和分析数据时采用的一套方法论和技术。它结合了多个领域的知识和工具,包括思维方法、统计学原理、实践经验和指标体系,以帮助人们更好地理解和利用数据。
思维方法: 数据方法强调科学思维和逻辑思维的应用。在数据分析中,需要具备清晰的问题意识、假设提出和验证的能力。思维方法还包括系统思考和整体观察,帮助发现数据背后的潜在关联和规律。
统计学: 统计学是数据方法的重要基础。它提供了一套概率和推断的工具,用于从数据中抽取有意义的信息。统计学方法包括描述统计、推断统计和回归分析等,可以帮助揭示数据之间的关系、验证假设,并进行预测和决策。
实践经验: 实践经验是指通过实际应用数据方法进行数据分析和解决问题的经验积累。实践经验包括对数据质量的认识、数据预处理的技巧、模型选择和优化的实践等。通过实践,数据分析师可以更好地理解数据的特点和局限性,并提高分析的准确性和效果。
北极星指标: 北极星指标是一种衡量绩效和评估目标达成情况的指标体系。它通过设定关键绩效指标(KPIs)和设定可度量的目标,帮助组织或个人定量化地追踪和评估业务或工作的表现。北极星指标可以应用于各个领域,包括市场营销、销售、运营等,以衡量和改进业务绩效。
北极星指标(Balanced Scorecard)是一种绩效管理工具,用于衡量组织或个人在实现业务目标和战略方向上的绩效表现。它不仅关注财务指标,还包括客户、内部业务流程和学习与成长等方面的指标,以提供一个全面的绩效评估体系。
北极星指标最早由Robert Kaplan和David Norton于1992年提出,并在之后的发展中得到广泛应用。它基于一个核心观点:仅仅关注财务指标无法全面反映组织的绩效和潜力。因此,北极星指标通过衡量四个不同的维度,为组织提供一个更全面、平衡的绩效评估框架。
以下是北极星指标的四个维度:
-
财务维度(Financial Perspective):这个维度关注组织在财务方面的表现,包括收入、利润、现金流等指标。财务维度通常是评估组织经济状况和可持续发展的重要指标。
-
客户维度(Customer Perspective):客户维度关注组织在满足客户需求和提供价值方面的表现。这包括客户满意度、市场份额、客户留存率等指标,旨在衡量组织如何通过产品或服务满足客户期望并建立客户关系。
-
内部业务流程维度(Internal Business Process Perspective):这个维度关注组织内部流程和运作的效率和质量。 它涉及关键的业务流程,如生产流程、供应链管理、客户服务等,以确保组织能够高效地交付产品或服务。
-
学习与成长维度(Learning and Growth Perspective):学习与成长维度关注组织员工的培训、发展和创新能力。 它包括员工满意度、员工培训投入、创新项目等指标,旨在评估组织的学习和成长能力,以推动组织的长期发展。
2、数据工具:数据仓库
数据仓库(Data Warehouse)是一种用于存储、管理和分析大量结构化和非结构化数据的中心化数据存储系统。 它是一个面向主题的、集成的、稳定的、可查询的数据集合,用于支持企业决策和数据分析。
数据仓库的主要目标是将来自不同数据源的数据集成到一个统一的数据模型中,以便用户可以方便地进行数据分析和查询。 它通过数据抽取、转换和加载(ETL)过程,将源系统的数据转化为适合分析和查询的形式,并存储在数据仓库中。
-
面向主题:数据仓库以业务主题为中心,组织数据以支持特定的分析需求。主题可以是销售、客户、产品等,使用户能够针对特定业务领域进行深入分析。
-
集成的:数据仓库集成来自不同数据源的数据,包括关系型数据库、操作系统日志、传感器数据等。通过将数据集成到一个统一的数据模型中,消除了数据分散和冗余的问题。
-
稳定性和可靠性:数据仓库是一个稳定和可靠的数据存储系统,用于长期存储和管理数据。它具有高可用性和数据冗余机制,以确保数据的安全性和可靠性。
-
可查询的:数据仓库提供灵活且高性能的查询功能,以支持各种数据分析和报表需求。通过使用查询语言(如SQL)和分析工具,用户可以从数据仓库中提取所需的信息。
-
支持决策:数据仓库为企业决策提供重要的数据支持。通过对数据进行分析和挖掘,用户可以发现潜在的业务趋势、模式和关联,以做出更准确的决策。
下面是一些常用且有名的数据仓库:
-
Teradata: Teradata是一家知名的数据仓库解决方案提供商。他们提供了高性能且可扩展的数据仓库平台,用于存储和分析大规模数据。Teradata的特点包括并行处理能力、高可用性、灵活的数据模型和丰富的分析功能。
-
Snowflake: Snowflake是一种云原生的数据仓库解决方案,具有强大的弹性和灵活性。它采用了分布式架构和列存储技术,支持结构化和半结构化数据,并提供了高性能的查询和扩展能力。Snowflake还提供了全球性的数据复制和安全性功能。
-
Amazon Redshift: Amazon Redshift是亚马逊AWS提供的一种高性能的数据仓库服务。它基于列存储技术和并行处理架构,适用于处理大规模数据集。Redshift具有弹性扩展能力,可以根据需求自动调整计算和存储资源。
-
Google BigQuery: Google BigQuery是一种托管的云数据仓库服务,由Google Cloud提供。它具有快速的查询性能和强大的扩展能力,支持大规模数据分析和实时查询。BigQuery还集成了机器学习和AI功能,可用于数据挖掘和模型训练。
-
Microsoft Azure Synapse Analytics: Azure Synapse Analytics(之前称为Azure SQL Data Warehouse)是微软Azure平台上的企业级数据仓库解决方案。它提供了高性能的数据存储和处理能力,支持结构化和非结构化数据。Synapse Analytics还集成了数据湖存储和机器学习功能。
-
阿里云数仓(AnalyticDB):阿里云数仓是阿里云提供的大数据分析和存储解决方案。它基于分布式架构和列存储技术,具有高性能和可扩展性。阿里云数仓支持PB级数据存储和实时查询,广泛应用于电商、金融、物流等领域。
-
腾讯云数仓(TencentDB for TDSQL):腾讯云数仓是腾讯云提供的数据仓库解决方案。它提供了分布式的、高可用的数据存储和计算能力,支持PB级数据的处理和分析。腾讯云数仓广泛应用于游戏、社交媒体、广告等领域。
-
华为云数仓(FusionInsight):华为云数仓是华为云提供的大数据分析平台。它提供了强大的数据存储和分析能力,支持结构化和半结构化数据。华为云数仓适用于各种行业,如金融、制造、电信等。
-
京东云数仓(JD Cloud DWS):京东云数仓是京东云提供的大数据仓库解决方案。它基于列存储和分布式计算技术,具有高性能和弹性扩展能力。京东云数仓广泛应用于电商、物流、金融等领域。
以下是一些常见的数仓使用方法和技巧:
-
数据模型设计:良好的数据模型设计是数据仓库的基础。在设计数据模型时,需要考虑业务需求和分析目标,合理组织数据结构,建立适当的关联和层级关系。常用的数据模型包括星型模型和雪花模型等,选择合适的数据模型有助于简化查询和提高性能。
-
数据清洗和转换:在将数据加载到数据仓库之前,通常需要进行数据清洗和转换的过程。这包括处理缺失值、重复值、异常值等数据质量问题,并对数据进行规范化、标准化和格式化。数据清洗和转换的目的是确保数据的一致性和准确性,提高后续分析的可靠性。
-
定期维护和更新:数据仓库需要定期进行维护和更新,以确保数据的及时性和准确性。这包括定时的数据抽取、转换和加载(ETL)过程,以及数据质量检查和校正。定期更新数据仓库还可以保持数据模型的完整性和适应性,以应对业务需求的变化。
-
使用合适的查询工具和技术:选择适合的查询工具和技术可以提高数据仓库的查询和分析效率。常见的查询工具包括SQL查询语言和商业智能工具(如Tableau、Power BI等),它们提供了直观的界面和丰富的可视化功能。此外,使用查询优化技术和索引等方法可以加快查询速度和提升性能。
-
利用数据仓库的分析能力:数据仓库不仅是一个数据存储的地方,还提供了丰富的分析能力。用户可以利用数据仓库进行数据挖掘、统计分析、趋势分析、预测建模等工作。通过运用合适的分析方法和算法,可以发现隐藏在数据中的有价值的信息,并支持决策和业务优化。
-
数据安全和权限管理:数据仓库中存储的数据可能包含敏感信息,因此数据安全和权限管理是重要的考虑因素。确保数据仓库的访问权限受到限制,并采取适当的安全措施,如数据加密、访问日志监控、用户权限管理等,以保护数据的机密性和完整性。
3、数据规范
数据开发中的数据规范是为了保证数据的一致性、可靠性和可维护性而定义的一系列规则和标准。以下是一些常见的数据规范:
-
命名规范:命名规范用于定义数据对象(表、列、视图等)的命名方式。这包括使用有意义的、可理解的命名,遵循一定的命名约定(如驼峰命名法或下划线命名法),避免使用保留字和特殊字符等。
-
数据类型规范:数据类型规范定义了各个字段应该使用的数据类型,例如整数、浮点数、字符串等。确保选择合适的数据类型可以节省存储空间并提高查询性能。
-
约束规范:约束规范用于定义数据对象的约束条件,如主键、唯一键、外键等。这些约束条件可以保证数据的完整性和一致性,防止不符合业务规则的数据被插入或修改。
-
数据格式规范:数据格式规范定义了数据的存储格式和展示格式,如日期时间格式、货币格式、数字精度等。这有助于保持数据的一致性,并确保正确的数据处理和计算。
-
数据字典规范:数据字典规范定义了数据对象的元数据信息,包括字段含义、取值范围、业务规则等。数据字典可以帮助数据开发人员和数据使用者理解数据的含义和用途,提高数据的可理解性和可维护性。
-
编码规范:编码规范用于定义数据开发的编码标准和规则。这包括代码的缩进、命名规范、注释规范等,以提高代码的可读性、可维护性和可重用性。
-
数据质量规范:数据质量规范定义了数据的质量标准和检查规则。这包括数据完整性、准确性、一致性、及时性等方面的规定,以确保数据的高质量和可信度。
-
数据安全规范:数据安全规范用于定义数据的安全标准和保护措施。这包括访问权限管理、数据加密、敏感信息处理等,以确保数据的机密性和安全性。
二、数据分析工具
1、大数据平台
大数据平台是指用于存储、处理和分析大规模数据的技术平台。以下是一些常见的大数据平台:
-
Apache Hadoop:Hadoop是最为广泛使用的开源大数据平台,被许多公司采用。包括Cloudera、Hortonworks、MapR等公司都提供了基于Hadoop的商业解决方案。
-
Apache Spark:Spark是近年来快速崛起的大数据处理平台,被许多公司所广泛采用。大型科技公司如Facebook、Netflix、Uber等都在使用Spark进行大数据处理和分析。
-
Apache Kafka:Kafka是一个流式处理平台,在实时数据传输和处理方面非常受欢迎。许多大型互联网公司如LinkedIn、Netflix、Uber等都在使用Kafka作为数据流平台。
-
Amazon Web Services (AWS): AWS提供了一系列的云计算服务,包括大数据处理和分析的服务。其大数据服务包括Amazon EMR、Amazon Redshift、Amazon Kinesis等,被许多公司广泛采用。
-
Google Cloud Platform (GCP):GCP也提供了各种大数据处理和分析的服务。Google BigQuery、Google Cloud Dataflow等服务在许多公司中被广泛使用,包括Spotify、HSBC等。
-
Microsoft Azure:Azure是微软提供的云计算平台,也提供了大数据处理和分析的服务。Azure HDInsight、Azure Data Lake Analytics等服务在许多公司中得到应用,包括Adobe、Walmart等。
-
Cloudera:Cloudera是一家提供基于Hadoop的企业级大数据解决方案的公司。其产品包括Cloudera Distribution for Hadoop(CDH)和Cloudera Data Platform(CDP),被许多公司在大数据领域使用。
-
MapR:MapR是另一家提供基于Hadoop的企业级大数据解决方案的公司。其产品包括MapR Data Platform,被许多公司在大数据处理和分析方面采用。
以下是中国一些大公司常用的大数据平台:
-
需要注意的是,大公司的大数据平台通常是根据自身业务需求和技术栈进行定制开发或选择合适的开源解决方案,因此具体的平台和技术选择可能因公司而异。此外,一些公司也会采用多个大数据平台来满足不同的需求。
-
阿里巴巴集团:阿里巴巴拥有自己的大数据平台,包括MaxCompute(分布式数据处理平台)、AnalyticDB(大规模分布式数据库)、DataWorks(数据集成和开发平台)等。阿里巴巴还开源了一些大数据相关技术,如Flink SQL、Blink等。
-
腾讯集团:腾讯的大数据平台包括TencentDB(大规模分布式数据库)、Tencent Data Warehouse(数据仓库)、Tencent Cloud Data Lake(数据湖)等。腾讯还广泛使用Hadoop、Spark等开源大数据技术。
-
TDW:腾讯分布式数据仓库(Tencent distributed Data Warehouse, 简称TDW)
基于开源软件Hadoop和Hive进行构建,并且根据公司数据量大、计算复杂等特定情况进行了大量优化和改造,目前单集群最大规模达到5600台,每日作业数达到100多万,已经成为公司最大的离线数据处理平台。 -
百度公司:百度拥有自己的大数据平台,包括Baidu Data Warehouse(数据仓库)、Baidu BigQuery(大数据分析平台)、Baidu FusionInsight(大数据处理和分析平台)等。
-
字节跳动:字节跳动在大数据领域采用了自研的数据平台,包括DolphinDB(高性能分布式数据处理和分析引擎)、Bytedance Data Platform(大数据处理平台)等。
-
华为技术有限公司:华为提供了FusionInsight HD(大数据处理和分析平台)、FusionInsight LibrA(数据管理和分析平台)等大数据解决方案。
-
美团点评:美团点评在大数据领域采用了自己的数据平台,包括DolphinDB(高性能分布式数据处理和分析引擎)、美团云数聚等。
-
京东集团:京东在大数据领域使用了自己的数据平台,包括JDP(大数据平台)、JDP Fusion(数据处理平台)等。
2、数据开发:入库+计算(重点)
联机分析处理 (OLAP) 系统和联机事务处理 (OLTP) 系统是为不同用途设计的两种不同的数据处理系统。OLAP 针对复杂的数据分析和报告进行了优化,OLTP 则针对事务处理和实时更新进行了优化。
就记住T比较快就行。

KV 存储是一种常见的数据存储方式,其中K 表示键(key),V 表示值(value)
DB 存储,关系数据库。
模型需要有定义。
增量表 存量表。数仓中的全量表,增量表,拉链表,流水表,快照表
全量表:每天的所有的最新状态的数据。
(1)全量表,有无变化,都要报
(2)每次上报的数据都是所有的数据(变化的 + 没有变化的)
增量表:新增数据,增量数据是上次导出之后的新数据。
(1)记录每次增加的量,而不是总量;
(2)流量是指在一定时间内的增量;
(3)流量一般设计成增量表(日报-常用、月报);
(4)流量和存量的区别:流量是增量;存量是总量;
(5)增量表,只报变化量,无变化不用报
3、数据管理:字典+维表 (重点)
数据字典 维表
表信息 数据信息 任务信息 数仓信息
数据字典通常包含以下信息:
- 数据元素名称:记录数据元素的名称,例如表名、列名等。
数据元素定义:描述数据元素的含义和用途,包括业务含义和技术定义。
数据类型:指定数据元素的数据类型,如整数、字符串、日期等。
长度和精度:指定数据元素的长度和精度限制,如字符字段的最大长度、小数字段的小数位数等。
取值范围:定义数据元素的取值范围或允许的值列表,以确保数据的有效性和一致性。
数据格式:指定数据元素的格式,如日期时间格式、货币格式等。
约束条件:指定数据元素的约束条件,如主键、唯一键、外键等。
关联关系:记录数据元素之间的关联关系,如表之间的关系、列之间的关系等。
数据字典的作用包括:
- 数据理解和文档化:数据字典提供了对数据元素的定义和描述,帮助用户理解数据的含义和用途。它可以作为数据文档,方便用户查阅和参考。
- 数据管理和维护:数据字典记录了数据元素的属性和约束条件,可以用于数据管理和维护。例如,可以通过数据字典检查数据的完整性、一致性和准确性。
- 数据开发和数据集成:数据字典为数据开发人员提供了数据元素的定义和属性,帮助他们在数据开发和数据集成过程中使用正确的数据元素。
维表,即维度表,是数据仓库中用于描述事实数据的维度属性的表。
维表通常包含与业务相关的信息,如产品、客户、时间等维度的属性。维表的设计包括定义维度的属性、层级关系、维度关系等,以支持数据分析和报表查询。
在数据字典中,维表的信息可以包括:
- 维表名称:记录维表的名称。
维表字段:描述维表中的字段,包括字段名称、数据类型、长度等。
维度属性:记录维度的属性,如产品名称、客户名称、时间等。
层级关系:定义维度属性之间的层级关系,如产品类别、产品子类别、产品名称等。
维度关系:记录维度之间的关系,如产品维度和客户维度之间的关联关系。
————————————————————————
列表检索, 数据详情与字段描述, 关联任务
列表检索(List Retrieval)是指在数据管理系统或应用程序中使用查询操作获取符合特定条件的数据集合,并以列表形式呈现给用户。列表检索常用于查找和展示数据的摘要信息,以便用户可以快速浏览和筛选结果。
列表检索一般包括以下步骤:
- 查询条件定义:用户指定需要检索的数据的条件,可以是基于一个或多个字段的过滤条件,例如日期范围、关键字、状态等。
- 数据查询:系统根据用户定义的查询条件执行查询操作,检索满足条件的数据。
- 数据呈现:查询结果以列表形式展示给用户,通常包括每条数据的关键字段或摘要信息,以便用户可以快速浏览和筛选结果。
- 分页和排序:如果查询结果数据量较大,通常会进行分页操作,将结果分为多个页面展示。此外,用户还可以指定排序规则,以便按特定字段对结果进行排序。
数据详情与字段描述(Data Details and Field Descriptions)是指提供有关特定数据对象(如表、列、字段等)的详细信息和属性描述。这些信息通常包括数据对象的定义、用途、数据类型、长度、约束条件等。
数据详情与字段描述的作用包括:
- 数据理解和解释:提供数据对象的详细信息和属性描述,帮助用户理解数据的含义和用途。
- 数据开发和数据使用:对于数据开发人员和数据使用者来说,数据详情和字段描述提供了有关数据对象的必要信息,以便正确地使用和处理数据。
- 数据文档和元数据管理:数据详情和字段描述可以作为数据文档的一部分,用于记录和管理数据对象的元数据信息,方便维护和共享。
关联任务(Join Tasks)是指在数据管理和数据分析中,将多个数据表或数据集根据共享的字段进行关联操作,以获取更丰富的数据信息。关联任务常用于合并不同来源或不同维度的数据,以便进行更全面的数据分析和报表生成。
关联任务一般包括以下步骤:
- 关联字段选择:确定用于关联的共享字段,这些字段在不同的数据表中具有相同或相似的值。
- 数据关联:根据选择的关联字段,执行关联操作将数据表或数据集连接起来,生成一个包含关联数据的新数据表或数据集。
- 关联类型:根据关联字段的匹配情况,确定关联类型,如内连接、左连接、右连接等。
- 结果呈现:将关联后的数据结果进行呈现,通常以新的数据表或数据集形式展示给用户或供后续分析使用。
数据血缘,分区信息,数据预览,数据标签标注
数据血缘(Data Lineage)是指在数据管理和数据分析中追踪和记录数据的来源、传输路径和变换过程的信息。 它提供了对数据的溯源能力,帮助用户了解数据的生成、转换和使用历史,以及数据之间的关系和依赖关系。
数据血缘可以包括以下信息:
- 数据源:记录数据的原始来源,可以是数据库表、文件、外部系统等。
- 数据传输路径:描述数据在不同系统、组件或任务之间的传输路径,包括数据的输入、输出和传递过程。
- 数据变换操作:记录对数据进行的变换操作,如过滤、聚合、计算等,以及变换操作的顺序和参数。
- 数据使用:追踪数据被哪些任务、分析或报表使用,以及它们之间的依赖关系。
通过数据血缘,用户可以了解数据的全局视图,追踪数据的变化和流动,识别数据质量问题的根源,以及分析数据的可靠性和可信度。
分区信息(Partition Information)是指在数据存储系统中,将数据按照特定的分区策略进行组织和管理的信息。分区信息可以帮助提高数据查询和处理的效率,以及优化数据存储和访问的性能。
分区信息一般包括以下内容:
- 分区键(Partition Key):用于划分数据的字段或属性,例如日期、地区、产品等。根据分区键的取值,数据将被分配到相应的分区中。
- 分区类型:指定分区键的数据类型,如整数、日期、字符串等。
- 分区规则:定义数据如何根据分区键进行划分和组织,可以是范围分区、哈希分区、列表分区等。
- 分区数量:指定分区的数量,决定了数据在物理存储中的分布和存储结构。
通过分区信息,可以将数据按照分区键进行划分和组织,使得查询和处理只需访问特定的分区,减少了数据的扫描范围,提高了查询效率和性能。
数据预览(Data Preview)是指在数据管理系统或工具中,提供对数据的样本或摘要信息进行查看和预览的功能。数据预览允许用户在执行具体的查询或操作之前,快速了解数据的结构、内容和质量,以便做出相应的决策和调整。
数据预览通常包括以下内容:
- 数据样本:展示数据的部分记录或样本,以便用户了解数据的结构和内容。
- 字段摘要:提供数据字段的基本统计信息, 如字段类型、最大值、最小值、平均值等。
- 数据质量检查:检查数据中的缺失值、重复值、异常值等数据质量问题,并给出相应的提示或警告。
数据预览可以帮助用户快速了解数据的特征和质量状况,以便在数据处理和分析过程中做出相应的调整和决策。
数据标签标注(Data Tagging and Labeling)是指为数据对象(如表、列、记录等)添加标签或标识,以便对数据进行分类、组织和管理。数据标签标注可以根据业务需求和数据特征进行,使得数据可以被更容易地搜索、索引和识别。
数据标签标注的方式和内容可以根据具体需求进行定义,例如:
-
业务标签:为数据对象添加与业务相关的标签,如产品类别、客户类型、地理位置等,以便按照业务分类和组织数据。
-
数据质量标签:标记数据对象的质量状况,如完整性、准确性、一致性等,方便对数据进行质量管理和控制。
-
安全标签:为数据对象添加安全级别或敏感性标签,以便进行数据权限控制和保护。
-
关联标签:标记数据对象之间的关联关系,如主外键关系、数据集之间的依赖关系等,方便进行数据关联和分析。
数据标签标注可以帮助组织和管理数据,使得数据更易于搜索和发现,加快数据的定位和访问速度,同时也为数据分析、数据治理和合规性要求提供支持。通过标签标注,可以对数据进行更细粒度的管理和利用。
————————————————————————
数据维表管理
数据分类,分组,筛选
数据维表管理(Data Dimension Table Management)是指在数据管理系统或数据仓库中,对数据维表进行管理和维护的过程。 数据维表是存储与业务相关的维度信息的表,如产品维度、时间维度、地理维度等。数据维表管理包括数据的导入、更新、清理和维护,以确保维表数据的准确性和一致性。
数据维表管理的主要任务包括:
- 数据导入:将维表数据从源系统或外部数据源导入到数据管理系统中,通常通过ETL(Extract, Transform, Load)流程实现。
- 数据更新:根据业务需求和维度信息的变化,及时更新维表数据,保持数据的及时性和准确性。更新可以是全量更新或增量更新。
- 数据清理:对维表数据进行清理和修复,处理重复值、缺失值、错误值等数据质量问题,确保维表数据的一致性和完整性。
- 数据维护:监控维表数据的变化和使用情况,进行维表数据的备份、恢复和性能优化,保证数据的可靠性和可用性。
数据分类(Data Classification)是指将数据按照一定的规则和标准进行分类和组织,以便更好地管理和利用数据。数据分类可以基于多个维度,如业务领域、数据类型、安全级别等,对数据进行分类和归类。
数据分类的目的包括:
- 数据组织:将数据按照一定的分类方式组织,使得数据更易于查找、访问和管理。例如,按照业务领域将数据分为销售数据、财务数据、人力资源数据等。
- 数据权限控制:根据数据的安全级别和敏感性,对数据进行分类和标记,以便进行相应的权限控制和数据保护。例如,将数据分为公开数据、内部数据、机密数据等。
- 数据分析和报表生成:将数据按照需求进行分类和分组,方便进行数据分析和生成相应的报表。例如,将销售数据按照产品类别进行分类,以便生成产品销售报表。
数据分类可以根据具体的需求和业务规则进行定义,通过分类和组织数据,提高数据的管理效率和利用价值。
分组(Grouping)是指在数据分析和查询过程中,将数据按照某个字段或多个字段的值进行分组,以便进行聚合计算或统计分析。分组操作常用于数据报表、数据摘要和数据可视化等场景。
分组操作可以帮助用户对数据进行更深入的分析和理解,提供对数据的汇总信息和统计结果,支持决策和洞察的生成。
筛选(Filtering)是指根据特定的条件或规则,从数据集中选择符合条件的数据记录,将符合条件的数据筛选出来。筛选操作常用于数据查询、数据分析和数据处理等场景。
筛选操作可以帮助用户根据需要获取特定的数据子集,过滤掉不相关或不符合条件的数据,提供更精确和有针对性的数据分析和处理能力。
4、数据分析:报表
数据分析是指通过对数据进行收集、清洗、转换和解释,从中提取有用的信息、洞察和模式,以支持决策制定和问题解决的过程。数据分析可以应用于各个领域和行业,帮助人们更好地理解数据、发现趋势、识别关联性,并做出基于数据的有效决策。
报表是数据分析的一种形式,它是对数据进行汇总、整理和呈现的结果。报表通常以表格、图表、图形或其他可视化方式展示,以便用户能够更直观地理解和解释数据。
数据分析报表的特点和目的包括:
- 汇总和总结:报表对大量数据进行汇总和总结,以提供数据的概览和核心指标。例如,销售报表可以展示总销售额、销售量、平均销售价格等指标。
- 可视化展示:报表通过图表、图形等可视化方式呈现数据,使数据更易于理解和比较。常见的报表图表类型包括柱状图、折线图、饼图等。
- 趋势分析:报表可以展示数据的时间变化趋势,帮助用户发现周期性、季节性或长期趋势。趋势分析可以通过折线图、面积图等方式呈现。
- 对比和关联:报表可以将不同维度或不同数据集之间的数据进行对比和关联分析,揭示它们之间的关系和差异。例如,市场份额报表可以对比不同产品的销售占比。
- 决策支持:报表提供数据的可视化和整合,帮助决策者更准确地理解数据,并基于数据做出决策。报表可以为决策者提供重要的指导和依据。
——————
在创建数据分析报表时,以下步骤常常涉及:
- 数据准备:收集、清洗和整理需要分析的数据,确保数据的准确性和完整性。
- 报表设计:确定报表的目标、受众和内容,选择适当的图表类型和展示方式。
- 数据汇总和计算:对数据进行汇总、计算和聚合,生成报表中的指标和数值。
- 可视化展示:使用图表、图形等方式将数据可视化呈现,增加报表的易读性和可理解性。
- 解读和分析:对报表中的数据进行解读、分析和洞察,提供对数据的理解和见解。
- 报表发布和共享:将报表分享给相关的利益相关者,以便他们能够访问和使用报表。
三、数据语言 (DDL,DML)
在数据库管理系统中,DDL(Data Definition Language)和DML(Data Manipulation Language)是两种常见的数据语言,用于定义和操作数据库中的数据和结构。
-
DDL(Data Definition Language)用于定义和管理数据库的结构和对象,包括表、索引、视图、约束等。常见的DDL命令包括:
CREATE:用于创建数据库对象,如创建表、视图、索引等。
ALTER:用于修改数据库对象的结构,如修改表结构、添加列、修改约束等。
DROP:用于删除数据库对象,如删除表、视图、索引等。
TRUNCATE:用于快速删除表中的所有数据,但保留表结构。
COMMENT:用于给数据库对象添加注释或说明。 -
DML(Data Manipulation Language)用于操作数据库中的数据,包括插入、查询、更新和删除数据。常见的DML命令包括:
SELECT:用于查询数据库中的数据,并返回结果集。
INSERT:用于向数据库表中插入新的数据。
UPDATE:用于更新数据库表中的数据。
DELETE:用于删除数据库表中的数据。
除了DDL和DML,还有其他一些数据语言,如DCL(Data Control Language)和TCL(Transaction Control Language):
-
DCL(Data Control Language)用于定义和管理数据库的安全性和权限,包括授权用户访问权限、撤销权限等。常见的DCL命令包括GRANT和REVOKE。
-
TCL(Transaction Control Language)用于管理数据库事务,包括控制事务的提交和回滚。常见的TCL命令包括COMMIT和ROLLBACK。
这些数据语言提供了对数据库的定义、操作和管理的能力。在使用数据库时,可以使用DDL定义数据库结构,使用DML操作数据库中的数据,使用DCL管理数据库的安全性和权限,使用TCL管理数据库事务的一致性和并发控制。
SQL命令(重点)
SQL(Structured Query Language)是一种用于与关系型数据库进行交互的标准化语言。下面是SQL的基础语法和常见的关键字和语句:
- 创建表:
CREATE TABLE table_name (
column1 datatype,
column2 datatype,
column3 datatype,
...
);
- 插入数据:
INSERT INTO table_name (column1, column2, column3, ...)
VALUES (value1, value2, value3, ...);
- 查询数据:
SELECT column1, column2, ...
FROM table_name
WHERE condition;
- 更新数据:
UPDATE table_name
SET column1 = value1, column2 = value2, ...
WHERE condition;
- 删除数据:
DELETE FROM table_name
WHERE condition;
- 查询数据的过滤和排序:
SELECT column1, column2, ...
FROM table_name
WHERE condition
ORDER BY column1 ASC/DESC;
- 使用聚合函数:
SELECT aggregate_function(column) AS alias
FROM table_name
GROUP BY column;
常见的聚合函数包括COUNT、SUM、AVG、MIN和MAX。
- 连接多个表:
SELECT column1, column2, ...
FROM table1
JOIN table2 ON table1.column = table2.column;
常见的连接类型包括INNER JOIN、LEFT JOIN、RIGHT JOIN和FULL JOIN。
- 使用子查询:
SELECT column1, column2, ...
FROM table_name
WHERE column IN (SELECT column FROM another_table WHERE condition);
- 创建索引:
CREATE INDEX index_name
ON table_name (column1, column2, ...);
以上是SQL的基础语法和常见的关键字和语句。SQL语言非常灵活,还有许多高级功能和语法可以用于复杂的查询、数据操作和数据库管理。
SQL表连接(补充)
当使用SQL进行表连接时,可以使用不同类型的连接(INNER JOIN、LEFT JOIN、RIGHT JOIN和FULL JOIN)来处理表之间的关系。下面是每种连接的定义和具体示例:
-
内连接(INNER JOIN):,交集
- 定义:内连接返回两个表中满足连接条件的行,即只返回两个表中交集部分的数据。
- 示例:
SELECT Orders.OrderID, Customers.CustomerName FROM Orders INNER JOIN Customers ON Orders.CustomerID = Customers.CustomerID; ``` 在以上示例中,内连接将Orders表和Customers表连接起来,连接条件是两个表中的CustomerID列相等。结果将返回满足连接条件的OrderID和CustomerName列。 -
左连接(LEFT JOIN):左集+交集
- 定义:左连接返回左表中的所有行和右表中满足连接条件的行,如果右表中没有匹配的行,则右侧列显示为NULL。
- 示例:
SELECT Customers.CustomerName, Orders.OrderID FROM Customers LEFT JOIN Orders ON Customers.CustomerID = Orders.CustomerID; ``` 在以上示例中,左连接将Customers表和Orders表连接起来,连接条件是两个表中的CustomerID列相等。结果将返回所有的CustomerName和对应的OrderID,如果某个CustomerID在Orders表中没有匹配的行,则OrderID列显示为NULL。 -
右连接(RIGHT JOIN):右集+交集
- 定义:右连接返回右表中的所有行和左表中满足连接条件的行,如果左表中没有匹配的行,则左侧列显示为NULL。
- 示例:
SELECT Customers.CustomerName, Orders.OrderID FROM Customers RIGHT JOIN Orders ON Customers.CustomerID = Orders.CustomerID; ``` 在以上示例中,右连接将Customers表和Orders表连接起来,连接条件是两个表中的CustomerID列相等。结果将返回所有的CustomerName和对应的OrderID,如果某个CustomerID在Customers表中没有匹配的行,则CustomerName列显示为NULL。 -
全连接(FULL JOIN):,并集
- 定义:全连接返回左表和右表中的所有行,如果左表或右表中没有匹配的行,则对应的列显示为NULL。
- 示例:
SELECT Customers.CustomerName, Orders.OrderID FROM Customers FULL JOIN Orders ON Customers.CustomerID = Orders.CustomerID; ``` 在以上示例中,全连接将Customers表和Orders表连接起来,连接条件是两个表中的CustomerID列相等。结果将返回所有的CustomerName和对应的OrderID,如果某个CustomerID在Customers表或Orders表中没有匹配的行,则对应的列显示为NULL。 -
自连接(Self Join):
语法:SELECT columns FROM table1 JOIN table2 ON condition
匹配条件:将同一表中的两个别名视为不同的表,并根据连接条件进行匹配。
结果:用于在同一表中比较不同行之间的关系。
注意事项:自连接需要使用不同的表别名来区分两个表。
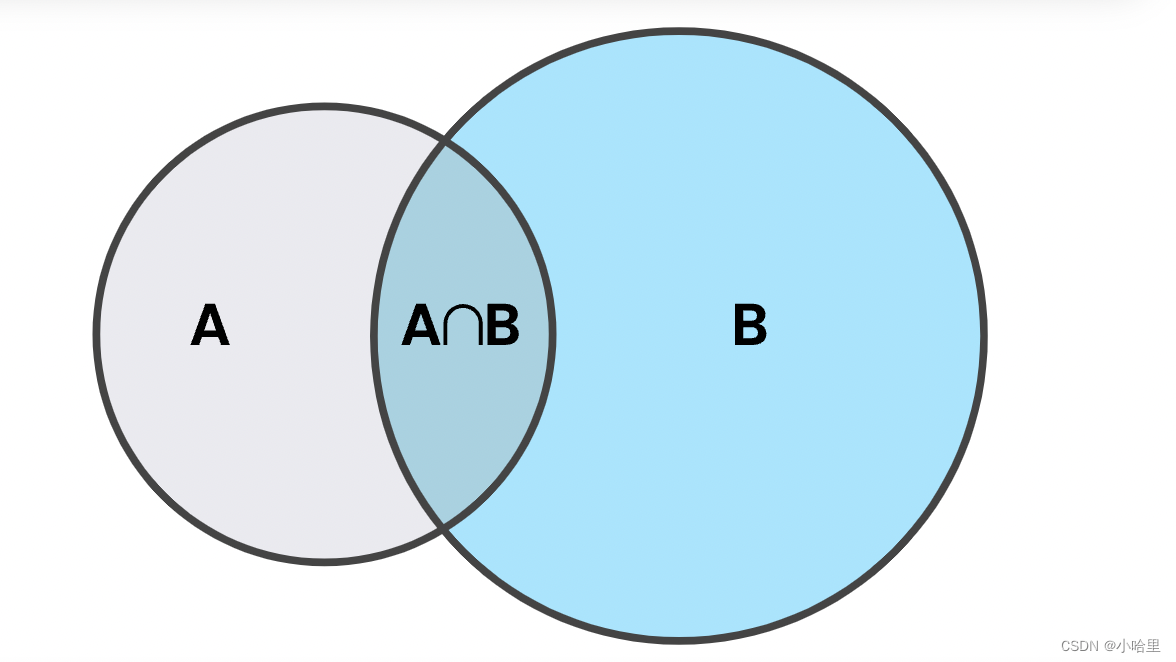
以上是各种表连接类型的定义和示例。根据数据之间的关系和查询需求,选择适当的连接类型可以实现需要的数据组合和关联操作。
在SQL中,默认的表连接类型是内连接(INNER JOIN)。
当在查询中使用多个表,并且没有显式地指定连接类型时,SQL会默认使用内连接来关联这些表。内连接只返回满足连接条件的行,即两个表中的交集部分。
例如,以下示例中的查询使用了多个表,但没有指定连接类型:
SELECT Orders.OrderID, Customers.CustomerName
FROM Orders, Customers
WHERE Orders.CustomerID = Customers.CustomerID;
在这种情况下,默认的表连接类型是内连接。连接条件是Orders表的CustomerID列和Customers表的CustomerID列相等。只有当两个表中的CustomerID匹配时,才会返回OrderID和CustomerName列。
需要注意的是,使用隐式的内连接语法可能会导致查询的可读性和维护性下降。因此,推荐显式地使用JOIN关键字来指定连接类型,以增强查询的可理解性和可维护性。
python(Spark等)
Python拥有广泛的数据开发库,以下是一些常见的Python数据开发库:
-
NumPy:NumPy是Python中最基础和常用的数值计算库。它提供了高效的多维数组对象和广播功能,以及丰富的数学函数库,是进行科学计算和数据分析的基础库。
-
pandas:pandas是一个强大的数据分析和数据处理库。它提供了高性能、灵活的数据结构(如DataFrame和Series),以及各种数据操作和处理功能,包括数据清洗、数据转换、数据筛选、数据统计等。
-
Matplotlib:Matplotlib是一个用于绘制高质量图表和可视化的库。它提供了广泛的绘图功能,包括线图、散点图、柱状图、饼图等,可用于探索数据、展示分析结果和生成报告。
-
seaborn:seaborn是基于Matplotlib的统计数据可视化库。它提供了更高级别、更美观的图表样式和绘图接口,可以轻松地创建各种统计图表,如热力图、箱线图、密度图等。
-
scikit-learn:scikit-learn是一个广泛使用的机器学习库,提供了丰富的机器学习算法和工具。它支持数据预处理、特征工程、模型训练和评估等任务,是进行机器学习和数据挖掘的重要工具。
-
TensorFlow和PyTorch:TensorFlow和PyTorch是两个流行的深度学习框架,用于构建和训练神经网络模型。它们提供了灵活的计算图构建和自动微分功能,支持各种深度学习任务,如图像分类、自然语言处理等。
-
SQLalchemy:SQLalchemy是一个强大的SQL工具包,提供了对关系型数据库的访问和操作接口。它支持多种数据库后端,可以通过Python代码来执行SQL查询、数据写入和数据管理等操作。
-
PySpark:PySpark是Python与Apache Spark的集成库,用于大规模数据处理和分布式计算。它提供了高级API和工具,支持分布式数据处理、机器学习和图计算等任务。
这些库覆盖了数据分析、可视化、机器学习和大数据处理等多个领域,为Python开发者提供了丰富的工具和功能,支持各种数据相关的开发和应用场景。
PySpark是Python编程语言与Apache Spark的集成库,用于大规模数据处理和分布式计算。Apache Spark是一个快速、通用且可扩展的开源集群计算系统,可处理大规模数据集并支持复杂的数据分析和机器学习任务。
PySpark提供了与Spark核心功能的完整集成,使Python开发者能够利用Python的简洁性和易用性来进行大规模数据处理。以下是PySpark的一些特点和功能:
- 分布式数据处理:PySpark基于Spark的分布式计算引擎,可以处理大规模数据集。它支持在集群上并行处理数据,充分利用集群的计算资源,提高数据处理效率。
- 高性能:PySpark利用Spark的内存计算和基于RDD(弹性分布式数据集)的数据模型,实现了高性能的数据处理。它能够在内存中缓存数据并进行迭代计算,大大加快了数据处理速度。
- 数据抽象和操作:PySpark提供了丰富的数据抽象和操作接口,包括DataFrame和SQL查询。DataFrame是一个类似于关系型数据库表的数据结构,支持类似于SQL的查询、过滤、聚合和连接操作,使数据处理更方便和直观。
- 机器学习支持:PySpark内置了机器学习库(MLlib),提供了常见的机器学习算法和工具。它支持特征提取、模型训练、模型评估和预测等机器学习任务,可以处理大规模的机器学习数据集。
- 流式处理:PySpark支持流式数据处理,可以实时处理数据流并进行流式计算。它集成了Spark Streaming和Structured Streaming,可以从多个数据源接收数据流,并以微批方式进行处理和分析。
- 数据源支持:PySpark支持多种数据源的读写操作,包括HDFS、Hive、JSON、CSV、Parquet等。它可以从不同类型的数据源中读取数据,并将处理结果写回到数据源中。
- 扩展性和生态系统:PySpark具有良好的扩展性,可以集成第三方Python库和工具。此外,Spark生态系统提供了丰富的工具和库,如Spark SQL、Spark Streaming和GraphX等,可以与PySpark无缝集成,拓展数据处理和分析的功能。
——————————————————
当使用PySpark进行数据处理和分析时,以下是一些常用的功能函数及其代码实现和解释:
- 读取数据:
from pyspark.sql import SparkSession
# 创建SparkSession对象
spark = SparkSession.builder.getOrCreate()
# 读取CSV文件数据
df = spark.read.csv("data.csv", header=True, inferSchema=True)
解释:上述代码使用SparkSession创建了一个Spark会话对象,并使用read.csv函数读取了一个CSV文件数据。header=True表示第一行为列名,inferSchema=True表示自动推断列的数据类型。
- 数据预览:
# 显示DataFrame前几行数据
df.show(5)
# 查看DataFrame的列名
df.columns
# 查看DataFrame的行数和列数
df.count(), len(df.columns)
解释:上述代码中,show函数用于显示DataFrame的前几行数据,默认显示前20行。columns属性返回DataFrame的列名列表。count()函数返回DataFrame的行数,len(df.columns)返回DataFrame的列数。
- 数据筛选和过滤:
# 筛选满足条件的数据
filtered_df = df.filter(df["age"] > 30)
# 多个条件的筛选
filtered_df = df.filter((df["age"] > 30) & (df["gender"] == "Male"))
解释:上述代码中,filter函数用于筛选满足条件的数据。可以使用列名和运算符来构建筛选条件,如大于(>)、等于(==)等。多个条件可以使用逻辑运算符进行组合,如与(&)。
- 数据聚合和统计:
from pyspark.sql import functions as F
# 计算某列的平均值
avg_age = df.select(F.avg("age")).first()[0]
# 按某列分组并统计数量
grouped_df = df.groupBy("gender").count()
# 按某列分组并计算平均值
grouped_df = df.groupBy("gender").agg(F.avg("age"))
解释:上述代码中,avg函数用于计算某列的平均值。groupBy函数用于按某列进行分组,然后可以使用count函数计算每组的数量,或使用agg函数计算每组的其他统计量。
- 数据排序:
# 按某列升序排序
sorted_df = df.orderBy("age")
# 按多列排序
sorted_df = df.orderBy(["age", "salary"], ascending=[False, True])
解释:上述代码中,orderBy函数用于按某列或多列进行排序,默认为升序排序。ascending参数可指定升序或降序排序。
- 数据写入:
# 将DataFrame写入CSV文件
df.write.csv("output.csv", header=True)
# 将DataFrame写入数据库表
df.write.format("jdbc").option("url", "jdbc:mysql://localhost/mydatabase") \
.option("dbtable", "mytable").option("user", "username") \
.option("password", "password").save()
解释:上述代码中,write.csv函数用于将DataFrame写入CSV文件,可指定是否包含列名。write.format("jdbc")函数用于将DataFrame写入数据库表,需要提供数据库连接URL、表名和身份验证信息。
——————————————————
除了Spark,Python还有一些其他的大数据开发库,以下是其中一些常用的库:
- Dask:Dask是一个灵活的并行计算库,可以在单机或分布式环境下进行大规模数据处理。它提供了类似于Pandas的API,并支持并行化和分布式计算,可以处理超出单个机器内存限制的数据集。
- Hadoop:Hadoop是一个开源的分布式计算框架,用于处理大规模数据集。Python提供了与Hadoop集成的库,如Hadoop Streaming,允许使用Python编写MapReduce作业并在Hadoop集群上运行。
- Apache Kafka:Kafka是一个高吞吐量的分布式消息系统,用于处理实时流数据。Python提供了Kafka客户端库,可以使用Python编写生产者和消费者,实现流数据的传输和处理。
- Apache Flink:Flink是一个分布式流处理和批处理框架,用于实时和离线数据处理。Python提供了Flink的Python API,可以使用Python编写Flink作业,并在Flink集群上进行分布式计算。
- Apache Airflow:Airflow是一个可编程、可调度和可监控的工作流管理平台,用于构建和调度数据管道。Python是Airflow的主要编程语言,可以使用Python编写工作流任务和调度逻辑。
- Apache Storm:Storm是一个分布式实时计算系统,用于处理高速数据流。Python提供了Storm的Python API,可以使用Python编写Storm拓扑,实现实时流数据的处理和分析。