插入操作
假设数组的长度为 n,现在,如果我们需要将一个数据插入到数组中的第 k 个位置。为了把第 k 个位置腾出来,给新来的数据,我们需要将第 k~n 这部分的元素都顺序地往后挪一位。那插入操作的时间复杂度是多少呢?
如果在数组的末尾插入元素,那就不需要移动数据了,这时的时间复杂度为 O(1)。但如果在数组的开头插入元素,那所有的数据都需要依次往后移动一位,所以最坏时间复杂度是 O(n)。 因为我们在每个位置插入元素的概率是一样的,所以平均情况时间复杂度为 (1+2+...n)/n=O(n)。
如果数组中的数据是有序的,我们在某个位置插入一个新的元素时,就必须按照刚才的方法搬移 k 之后的数据。但是,如果数组中存储的数据并没有任何规律,数组只是被当作一个存储数据的集合。在这种情况下,如果要将某个数据插入到第 k 个位置,为了避免大规模的数据搬移,我们还有一个简单的办法就是,直接将第 k 位的数据搬移到数组元素的最后,把新的元素直接放入第 k 个位置。
为了更好地理解,我们举一个例子。假设数组 a[10]中存储了如下 5 个元素:a,b,c,d,e。我们现在需要将元素 x 插入到第 3 个位置。我们只需要将 c 放入到 a[5],将 a[2]赋值为 x 即可。最后,数组中的元素如下: a,b,x,d,e,c。

利用这种处理技巧,在特定场景下,在第 k 个位置插入一个元素的时间复杂度就会降为 O(1)
删除操作
跟插入数据类似,如果我们要删除第 k 个位置的数据,为了内存的连续性,也需要搬移数据,不然中间就会出现空洞,内存就不连续了。
和插入类似,如果删除数组末尾的数据,则最好情况时间复杂度为 O(1);如果删除开头的数据,则最坏情况时间复杂度为 O(n);平均情况时间复杂度也为 O(n)。
实际上,在某些特殊场景下,我们并不一定非得追求数组中数据的连续性。如果我们将多次删除操作集中在一起执行,删除的效率是不是会提高很多呢?我们继续来看例子。数组 a[10]中存储了 8 个元素:a,b,c,d,e,f,g,h。现在,我们要依次删除 a,b,c 三个元素
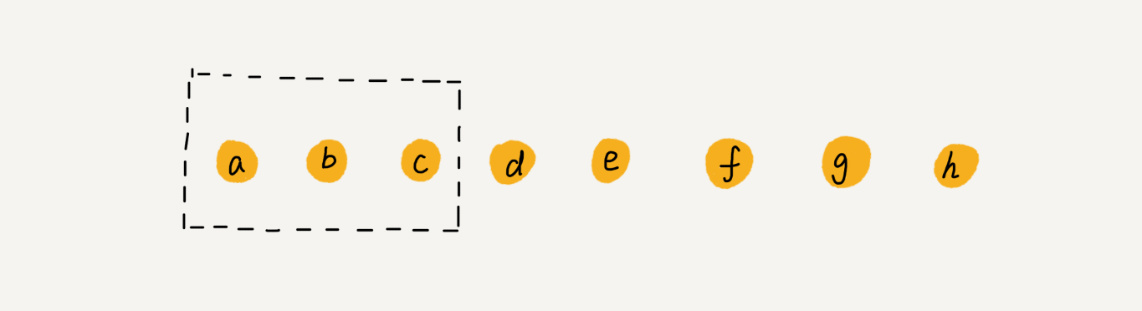
为了避免 d,e,f,g,h 这几个数据会被搬移三次,我们可以先记录下已经删除的数据。每次的删除操作并不是真正地搬移数据,只是记录数据已经被删除。当数组没有更多空间存储数据时,我们再触发执行一次真正的删除操作,这样就大大减少了删除操作导致的数据搬移。
如果你了解 JVM,你会发现,这不就是 JVM 标记清除垃圾回收算法的核心思想吗?没错,数据结构和算法的魅力就在于此,很多时候我们并不是要去死记硬背某个数据结构或者算法,而是要学习它背后的思想和处理技巧,这些东西才是最有价值的。如果你细心留意,不管是在软件开发还是架构设计中,总能找到某些算法和数据结构的影子。
此文章为5月Day9学习笔记,内容来源于极客时间《数据结构与算法之美》