ODConv动态卷积模块
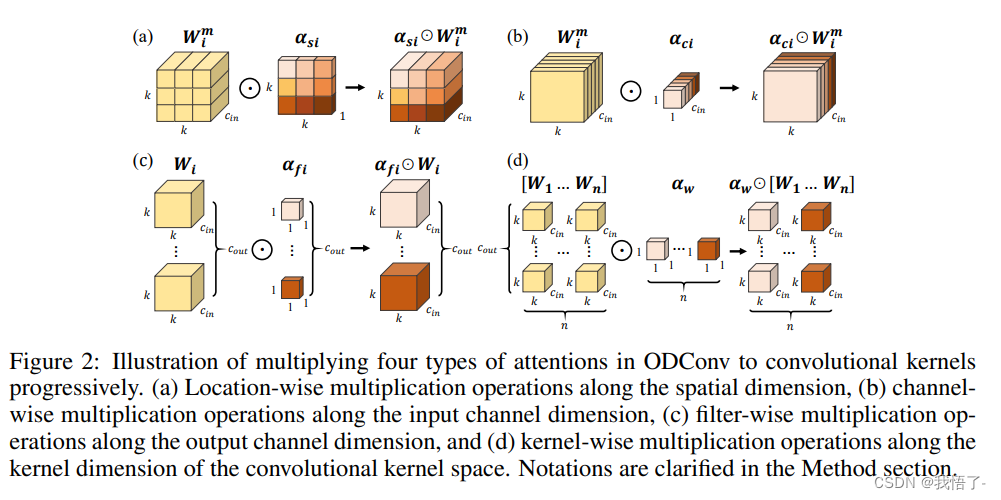
ODConv可以视作CondConv的延续,将CondConv中一个维度上的动态特性进行了扩展,同时了考虑了空域、输入通道、输出通道等维度上的动态性,故称之为全维度动态卷积。ODConv通过并行策略采用多维注意力机制沿核空间的四个维度学习互补性注意力。作为一种“即插即用”的操作,它可以轻易的嵌入到现有CNN网络中。ImageNet分类与COCO检测任务上的实验验证了所提ODConv的优异性:即可提升大模型的性能,又可提升轻量型模型的性能,实乃万金油是也!值得一提的是,受益于其改进的特征提取能力,ODConv搭配一个卷积核时仍可取得与现有多核动态卷积相当甚至更优的性能。
原文地址:Omni-Dimensional Dynamic Convolution
代码实现:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.autograd
from models.common import Conv, autopad
class Attention(nn.Module):
def __init__(self, in_planes, out_planes, kernel_size, groups=1, reduction=0.0625, kernel_num=4, min_channel=16):
super(Attention, self).__init__()
attention_channel = max(int(in_planes * reduction), min_channel)
self.kernel_size = kernel_size
self.kernel_num = kernel_num
self.temperature = 1.0
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.fc = Conv(in_planes, attention_channel, act=nn.ReLU(inplace=True))
self.channel_fc = nn.Conv2d(attention_channel, in_planes, 1, bias=True)
self.func_channel = self.get_channel_attention
if in_planes == groups and in_planes == out_planes: # depth-wise convolution
self.func_filter = self.skip
else:
self.filter_fc = nn.Conv2d(attention_channel, out_planes, 1, bias=True)
self.func_filter = self.get_filter_attention
if kernel_size == 1: # point-wise convolution
self.func_spatial = self.skip
else:
self.spatial_fc = nn.Conv2d(attention_channel, kernel_size * kernel_size, 1, bias=True)
self.func_spatial = self.get_spatial_attention
if kernel_num == 1:
self.func_kernel = self.skip
else:
self.kernel_fc = nn.Conv2d(attention_channel, kernel_num, 1, bias=True)
self.func_kernel = self.get_kernel_attention
self._initialize_weights()
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
if isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def update_temperature(self, temperature):
self.temperature = temperature
@staticmethod
def skip(_):
return 1.0
def get_channel_attention(self, x):
channel_attention = torch.sigmoid(self.channel_fc(x).view(x.size(0), -1, 1, 1) / self.temperature)
return channel_attention
def get_filter_attention(self, x):
filter_attention = torch.sigmoid(self.filter_fc(x).view(x.size(0), -1, 1, 1) / self.temperature)
return filter_attention
def get_spatial_attention(self, x):
spatial_attention = self.spatial_fc(x).view(x.size(0), 1, 1, 1, self.kernel_size, self.kernel_size)
spatial_attention = torch.sigmoid(spatial_attention / self.temperature)
return spatial_attention
def get_kernel_attention(self, x):
kernel_attention = self.kernel_fc(x).view(x.size(0), -1, 1, 1, 1, 1)
kernel_attention = F.softmax(kernel_attention / self.temperature, dim=1)
return kernel_attention
def forward(self, x):
x = self.avgpool(x)
x = self.fc(x)
return self.func_channel(x), self.func_filter(x), self.func_spatial(x), self.func_kernel(x)
class ODConv2d(nn.Module):
def __init__(self, in_planes, out_planes, k, s=1, p=None, g=1, act=True, d=1,
reduction=0.0625, kernel_num=1):
super(ODConv2d, self).__init__()
self.in_planes = in_planes
self.out_planes = out_planes
self.kernel_size = k
self.stride = s
self.padding = autopad(k, p)
self.dilation = d
self.groups = g
self.kernel_num = kernel_num
self.attention = Attention(in_planes, out_planes, k, groups=g,
reduction=reduction, kernel_num=kernel_num)
self.weight = nn.Parameter(torch.randn(kernel_num, out_planes, in_planes//g, k, k),
requires_grad=True)
self._initialize_weights()
self.bn = nn.BatchNorm2d(out_planes)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
if self.kernel_size == 1 and self.kernel_num == 1:
self._forward_impl = self._forward_impl_pw1x
else:
self._forward_impl = self._forward_impl_common
def _initialize_weights(self):
for i in range(self.kernel_num):
nn.init.kaiming_normal_(self.weight[i], mode='fan_out', nonlinearity='relu')
def update_temperature(self, temperature):
self.attention.update_temperature(temperature)
def _forward_impl_common(self, x):
# Multiplying channel attention (or filter attention) to weights and feature maps are equivalent,
# while we observe that when using the latter method the models will run faster with less gpu memory cost.
channel_attention, filter_attention, spatial_attention, kernel_attention = self.attention(x)
batch_size, in_planes, height, width = x.size()
x = x * channel_attention
x = x.reshape(1, -1, height, width)
aggregate_weight = spatial_attention * kernel_attention * self.weight.unsqueeze(dim=0)
aggregate_weight = torch.sum(aggregate_weight, dim=1).view(
[-1, self.in_planes // self.groups, self.kernel_size, self.kernel_size])
output = F.conv2d(x, weight=aggregate_weight, bias=None, stride=self.stride, padding=self.padding,
dilation=self.dilation, groups=self.groups * batch_size)
output = output.view(batch_size, self.out_planes, output.size(-2), output.size(-1))
output = output * filter_attention
return output
def _forward_impl_pw1x(self, x):
channel_attention, filter_attention, spatial_attention, kernel_attention = self.attention(x)
x = x * channel_attention
output = F.conv2d(x, weight=self.weight.squeeze(dim=0), bias=None, stride=self.stride, padding=self.padding,
dilation=self.dilation, groups=self.groups)
output = output * filter_attention
return output
def forward(self, x):
return self.act(self.bn(self._forward_impl(x)))