只为见识python的强大之处
说明:
- Python 练习册,每天一个小程序。注:将 Python 换成其他语言,大多数题目也适用
- 点此链接,会看到部分题目的代码,仅供参考
- 本文本文由@史江歌([email protected] QQ:499065469)根据互联网资料收集整理而成,感谢互联网,感谢各位的分享。鸣谢!本文会不断更新。
写给自己:决定将很多人走过的路漫漫的走一遍,注定这会是一篇巨长的博文,仅做记录使用,并无参考价值,感谢互联网,感谢作者,决心静下来好好学一下python,先从小程序and别人优秀的代码学起,加油!坚持就是胜利。
一、problem0000
第 0000 题: 将你的 QQ 头像(或者微博头像)右上角加上红色的数字,类似于微信未读信息数量那种提示效果。
demo:
#!/bin/python3
from PIL import Image,ImageDraw,ImageFont
def add_number(img):
draw = ImageDraw.Draw(img)
myfont=ImageFont.truetype("/home/py_learning/show-me-the-code-master/simhei.ttf",80)
fillcolor = "#ff0000"
width,height = img.size
draw.text((width-50,10),'V',font = myfont , fill = fillcolor)
img.save('result.jpeg','jpeg')
if __name__ == '__main__':
image = Image.open("/home/py_learning/show-me-the-code-master/test.jpeg")
add_number(image)效果图:
处理前:

处理后:

2017.10.30
二、problem0001
第 0001 题:做为 Apple Store App 独立开发者,你要搞限时促销,为你的应用生成激活码(或者优惠券),使用 Python 如何生成 200 个激活码(或者优惠券)?。
demo:
#!/bin/python3
import random
def create_list():
base = []
for x in range(65,91): #生成26个大写的字母
a=str(chr(x)) #生成对应的ASCII码对应的字符串
base.append(a)
for x in range(97,123): #生成26个小写字母
a=str(chr(x))
base.append(a)
for x in range(10): #生成10个数字
base.append(str(x))
return base
def gen_code(base): #生成16位激活码
s=''
for x in range(16):
a=random.choice(base)
s=s+a
print(s)
return s
def create_txt(newlist):
strlist="".join(newlist)
txtnew=open("problem0001.txt","w")
txtnew.write(strlist)
txtnew.close()
if __name__ == '__main__':
store_list=['']
new_list=create_list()
for x in range(200): #生成200个激活码并生成txt文档
store_list.append(gen_code(new_list))
store_list.append('\n')
create_txt(store_list)
效果:


2017.10.31
三、problem0002
第 0002 题: 将 0001 题生成的 200 个激活码(或者优惠券)保存到 MySQL 关系型数据库中。
demo:
#!/bin/python3
import random
import pymysql
def create_db_table(): #创建数据库 表格,TESTDB需要提前创建
db = pymysql.connect("localhost","root","12345","TESTDB")
cursor = db.cursor()
cursor.execute("DROP TABLE IF EXISTS KEY_CODE")
sql = """CREATE TABLE KEY_CODE(\
KEY_ID INT,
KEY_VALUE CHAR(30)
) """
cursor.execute(sql)
db.close()
def make_insert():
new_list=create_list()
db = pymysql.connect("localhost","root","12345","TESTDB")
cursor=db.cursor()
for i in range(200):
key_value = gen_code(new_list)
sql = "INSERT INTO KEY_CODE(KEY_ID,\
KEY_VALUE) \
VALUES ('%d','%s') " % (i,key_value)
try:
cursor.execute(sql)
db.commit()
except:
db.rollback()
db.close()
if __name__ == '__main__':
create_db_table()
make_insert()效果:

2017.11.1
四、problem0004
第 0004 题:任一个英文的纯文本文件,统计其中的单词出现的个数。
demo:
#!/bin/python3
import re
def get_word_frequencies(file_name):
dic = {}
txt = open(file_name, 'r').read().splitlines()
no_flag=0
for line in txt:
line = re.sub(r'[.?!,""/\W]', ' ', line) #要替换的标点符号,英文字符可能出现的
for word in line.split():
#当字符为纯数字的时候,跳过不统计
if word.isdigit():
pass
# print("number is ++++++++++++++++++++:",word)
else:
dic.setdefault(word.lower(), 0) #不区分大小写
dic[word.lower()] += 1
print (dic)
if __name__ == '__main__':
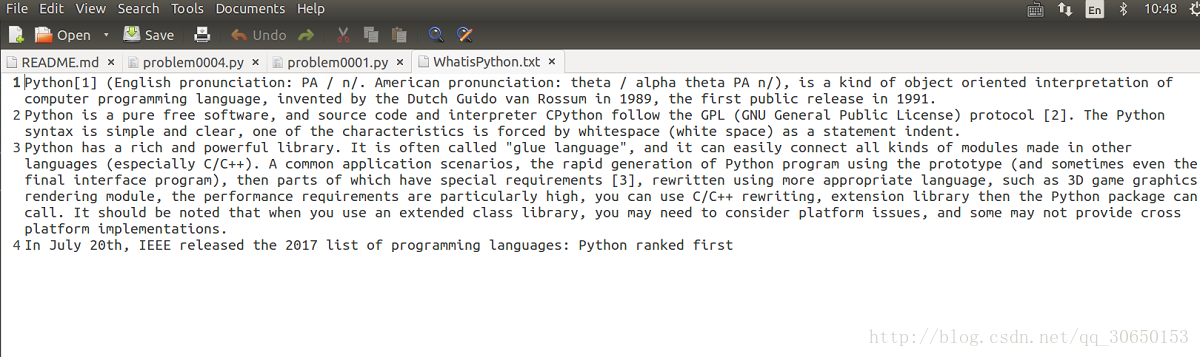
get_word_frequencies("WhatisPython.txt") 参考:[Python]任一个英文的纯文本文件,统计其中的单词出现的个数。(考虑单词-分行)
效果:
原文本:
统计图:
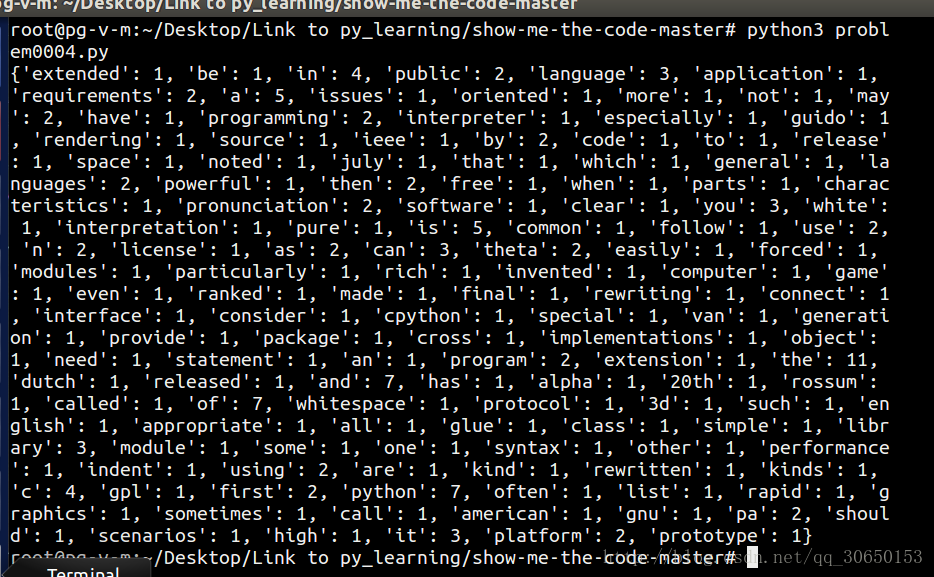
2017.11.2
五、problem0005
第 0005 题: 你有一个目录,装了很多照片,把它们的尺寸变成都不大于 iPhone5 分辨率的大小。
- 使用Python的PIL库对图片进行处理
- IPhone5屏幕分辨率为640 × 1136,将大于该分辨率的图片按照一定比例缩放至适合大小并保存。
demo:
#!/bin/python3
import os,sys
from PIL import Image
def processImage(filesource, destsource, name, imgtype):
'''
filesource是存放待转换图片的目录
destsource是存放输出转换后图片的目录
name是文件名
imgtype是文件类型
'''
imgtype = 'jpeg' if imgtype == '.jpg' else 'png'
#打开图片
im = Image.open(filesource + name)
# 缩放比例
rate = max(im.size[0]/640.0 if im.size[0] > 640 else 0, im.size[1]/1136.0 if im.size[1] > 1136 else 0)
if rate:
im.thumbnail((im.size[0]/rate, im.size[1]/rate))
im.save(destsource + name, imgtype)
def run(myPath):
# 切换到源目录,遍历源目录下所有图片
os.chdir(myPath)
for i in os.listdir(os.getcwd()):
# 检查后缀
postfix = os.path.splitext(i)[1]
if postfix == '.jpg' or postfix == '.png':
processImage(myPath, "./new", i, postfix)
if __name__ == '__main__':
run('./')
参考:Python Show-Me-the-Code 第 0005 题 批量图片处理
效果:
原图:

缩放图:

2017.11.3
六、problem0006
第 0006题: 你有一个目录,放了你一个月的日记,都是 txt,为了避免分词的问题,假设内容都是英文,请统计出你认为每篇日记最重要的词。
- 从txt文件中读出文章内容
- 使用 re.findall() 方法进行正则表达式匹配,值得注意的是 re.findall() 方法匹配后会返回一个由文章所有词组成的列表,且重复出现的单词不会被去重
- -使用 list.Counter() 方法对列表中单词出现次数进行排序,会返回一个单词—出现次数一一键值对应的字典
- 排除一些代词、冠词的干扰,即代码中使用filter_word进行的过滤词
- 使用 Counter.most_common() 方法对字典中的词按值排降序,会返回一个由许多元组所组成的列表,按值的大小依次降序排列
demo:
#!/bin/python3
import re,os
from collections import Counter
file_path = '/home/py_learning/show-me-the-code-master/problem0006'
filter_word = ['the','in','of','to','has','that','is','are','a','with','as','an']
def getCounter(filesource):
wordC = r'''[A-Za-z]+|$\d+%?$'''
with open(filesource) as f:
result = re.findall(wordC,f.read())
return Counter(result)
def run(file_path):
os.chdir(file_path)
counter_all = Counter()
for i in os.listdir(os.getcwd()):
if os.path.splitext(i)[1] == '.txt':
counter_all += getCounter(i)
for j in filter_word :
counter_all[j]=0
print (counter_all.most_common()[0][0])
if __name__ == '__main__':
run(file_path)
参考:Python Show-Me-the-Code 第 0006 题 最重要的词
参考:Python练习册 第 0006 题:你有一个目录,放了你一个月的日记,都是 txt,为了避免分词的问题,假设内容都是英文,请统计出你认为每篇日记最重要的词。
效果:

2017.11.4
七、problem0007
第 0007 题: 有个目录,里面是你自己写过的程序,统计一下你写过多少行代码。包括空行和注释,但是要分别列出来。
- os模块方法得到目录下自己的程序文件
- 读取每个文件,分别统计代码行、空行和注释
demo:
#!/bin/python3
import os
import re
def get_files(): #get all py files
files = os.listdir(os.getcwd())
py_list=[]
for f in files:
if f.split('.')[-1] == 'py':
print("This py is:",f)
py_list.append(f)
return py_list
def count(files): #count lines,blank and comments
code_line,blank,comments = 0,0,0
for fname in files:
f = open(fname,'r')
for line in f:
code_line += 1
if line == '\n':
blank +=1
if re.search(r'#',line):
comments +=1
f.close()
return [code_line,blank,comments]
if __name__ == '__main__' :
files = get_files()
lines = count(files)
print("Alright,the result is : Lines(s): %d ,blank: %d, comments: %d" % (lines[0],lines[1],lines[2]))
效果:

2017.11.6
八、problem0008
第 0008 题: 一个HTML文件,找出里面的正文。
- url下载网页内容
- beautifulsoup做文本解析
demo:
#!/bin/python3
from bs4 import BeautifulSoup
import requests
def get_html():
r = 'https://www.toutiao.com/a6485236648832401933/'
headers = {'user-agent':
'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 \
(KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'}
url = requests.get(r,headers=headers)
soup = BeautifulSoup(url.text,'lxml')
[script.extract() for script in soup.findAll('script')] #clear script
[style.extract() for style in soup.findAll('style')]
#return soup.prettify()
return soup.get_text()
if __name__ == '__main__':
print(get_html())参考:网页内容爬取:如何提取正文内容 BEAUTIFULSOUP的输出
效果:

2017.11.7
九、problem0009
第 0009 题: 一个HTML文件,找出里面的链接。
- url下载网页内容
- beautifulsoup做文本解析
demo:
#!/bin/python3
from bs4 import BeautifulSoup
import requests
import urllib.request
def get_html():
href=[]
r = 'https://www.baidu.com'
headers = {'user-agent':
'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 \
(KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'}
url = requests.get(r,headers=headers)
soup = BeautifulSoup(url.text,'lxml')
soup.prettify()
for hr in soup.findAll('a'):
print(hr.get('href'))
if __name__ == '__main__':
get_html()
效果:

2017.11.8
十、problem0010
第 0010 题: 使用 Python 生成类似于下图中的字母验证码图片

- random模块产生随机字母与背景和字体填充颜色
- PIL模块画图
demo:
#!/bin/python3
from PIL import Image,ImageDraw,ImageFilter,ImageFont
import random
def randomChar(): # return English letter
if random.randint(0,1)==0 :
return(chr(random.randint(65,90)))
else:
return chr(random.randint(97,122))
def randomBlackgroundColor():
return (random.randint(64,255),random.randint(64,255),random.randint(64,255))
def randomWordColor():
return (random.randint(32,127),random.randint(32,127),random.randint(32,127))
def createImage():
im = Image.new('RGB',(240,60),(255,255,255))
font = ImageFont.truetype('./simhei.ttf',40)
draw = ImageDraw.Draw(im)
for x in range(240):
for y in range(60):
draw.point((x,y),randomBlackgroundColor())
words =' '
for i in range(4):
word = randomChar()
draw.text((50*i+random.randint(10,40),random.randint(0,20)),word,font=font,fill=randomWordColor())
words += word
img = im.filter(ImageFilter.BLUR)
im.save('result.png')
print(words)
if __name__=='__main__':
createImage()
参考:python练习册之10
效果:

2017.11.9
十一、problem0011
第 0011 题: 敏感词文本文件 filterwords.txt,里面的内容为以下内容,当用户输入敏感词语时,则打印出 Freedom,否则打印出 Human Rights。
北京
程序员
公务员
领导
牛比
牛逼
你娘
你妈
love
sex
jiangge
- 读取文件获取敏感词,去除多余字符,并存入链表
- 采用脚本获取输入,遍历对比打印输出
demo:
#!/usr/bin/python3
from sys import argv
scripts,Input = argv
def getFilterwords():
filterwords = []
f=open('filterwords.txt')
for word in f:
filterwords.append(word[:-1])
f.close()
return filterwords
def checkFilterwords(filtWord,Input):
for w in filtWord:
if w == Input:
print('Freedom')
return
print('Human Rights')
return
if __name__ == '__main__':
checkFilterwords(getFilterwords(),Input)
效果:

2017.11.10
十二、problem0012
第 0012 题: 敏感词文本文件 ffilterwords.txt,里面的内容 和 0011题一样,当用户输入敏感词语,则用 星号 * 替换,例如当用户输入「北京是个好城市」,则变成「**是个好城市」。
- 读取文件获取敏感词,去除多余字符,并存入链表
- 采用脚本获取输入,遍历对比打印输出
- 完全是C语言处理数组的思路,缺陷:只能识别第一次出现的敏感词,同一敏感词多次出现只处理第一个
demo:
#!/usr/bin/python3
from sys import argv
scripts,Input = argv
def getFilterwords():
filterwords = []
f=open('filterwords.txt')
for word in f:
filterwords.append(word[:-1])
f.close()
return filterwords
def checkFilterwords(filtWord,Input):
for w in filtWord:
wlen=len(w)
slen=len(Input)
Input = list(Input)
if slen == wlen and w == "".join(Input):
print('*'*wlen)
return
elif slen > wlen:
for i in range(slen):
if w == "".join(Input[i:i+wlen]):
j=i
while (wlen):
Input[j]='*'
j+=1
wlen-=1
print("".join(Input))
return
if __name__ == '__main__':
checkFilterwords(getFilterwords(),Input) 效果:

2017.11.14
十三、problem0013
第 0013 题: 用 Python 写一个爬图片的程序,爬 这个链接里的日本妹子图片 :-)
- requests发请求获取html
- re正则表达式找到《src》里的图片地址
- urllib.requeset.urlretrieve下载图片
demo:
#!/bin/python3
import re
import urllib
import requests
def get_html():
response = requests.get("http://tieba.baidu.com/p/2166231880")
new_f = open("te.html",'w')
new_f.write(response.text)
new_f.close()
#print(response.text)
return response.text
def down_png(picHtml):
image = re.compile(r'src="(.+?\.jpg)" pic_ext')
imagelist = re.findall(image,picHtml)
x = 0
for imgurl in imagelist:
urllib.request.urlretrieve(imgurl,'%s.jpg' % x)
x+=1
if __name__=='__main__':
down_png(get_html())参考:
python2x与3x下urlretrieve的使用
Python爬虫爬取网页图片
效果:

2017.11.16
十四、problem0014
第 0014 题: 纯文本文件 student.txt为学生信息, 里面的内容(包括花括号)如下所示:
{
"1":["张三",150,120,100],
"2":["李四",90,99,95],
"3":["王五",60,66,68]
}
请将上述内容写到 student.xls 文件中,如下图所示:

- 读取文本,由<’class str’> 转化为 <’class dict’>
- 使用xlwt库来生成新的xls文件
demo:
#!/bin/python3
import xlwt
def get_text():
with open('student.txt',encoding='utf-8') as f:
str_temp=f.read()
data = eval(str_temp)
return data
def create_xls(dic):
wb = xlwt.Workbook()
ws = wb.add_sheet('Student')
row = 0
for k,v in dic.items():
ws.write(row,0,k)
col = 1
for items in v:
ws.write(row,col,items)
col += 1
row += 1
wb.save('student.xls')
if __name__ == '__main__':
create_xls(get_text())
效果:

2017.11.17
十五、problem0016
第 0016 题: 纯文本文件 numbers.txt, 里面的内容(包括方括号)如下所示:
[
[1, 82, 65535],
[20, 90, 13],
[26, 809, 1024]
]
请将上述内容写到 numbers.xls 文件中,如下图所示:

- 与上一题类似,不同的是数据类型变化
- 采用笨方法re模块正则匹配,切出自己想要的数据
- 写的很差劲很差劲只能当练习正则来看待
demo:
#!/bin/python3
import xlwt
import re
def get_txt():
with open('numbers.txt',encoding='utf-8') as f:
fileL=f.read()
fileLLL = re.sub(r'\s','',fileL)
fileLLLL = re.sub(r'\]',',A',fileLLL) #A作为换行flag,无实际意义
fiL = re.sub(r'\[|\{|\}','',fileLLLL)
fiLL = fiL.split(',')
print(fiL,type(fiL),len(fiL))
print(fiLL,type(fiLL),len(fiLL))
print ("{hehe hehe}")
return fiLL
def create_xls(fi):
wb = xlwt.Workbook()
ws = wb.add_sheet('numbers')
row=0
col=0
for num in fi:
if num !='A':
ws.write(row,col,num)
col += 1
else:
row+=1
col = 0
wb.save('numbers.xls')
if __name__ == '__main__':
create_xls(get_txt())
效果:
无效果
2017.11.18
总结
- 了解到很多python库,PIL,Beautifusoup,pymqsql,xlwt,urllib等等。
- 请重“质”不重“量”,虽说量的积累产生质的飞跃,但也必须注重”质“。
- 零零散散的写到这里,以上仅做记录使用。
- 排版错乱,图文不一,就是原作者我也懒得翻阅。
- 作为写的最长最烂的一篇博客,有必要让它存在着,提醒我!警示我!