ACL2021 | 利用加权的词袋进行大规模的文本到图像的检索
简介
目前的跨模态检索方法主要分为查询相关和查询无关两种。查询无关的方法(双塔) 通过点积度量相似度,使得检索速度较快,但是缺少了模态间的交互限制了检索精度。查询相关的方法(单塔) 通过深层次的模态间交互提升了检索精度,但是高昂的计算复杂度使得检索非常慢。

然而在大规模的场景下这两种方法都不适用,即使查询无关的方法可以提前建立索引,但是点积的计算仍然不能实现实时检索,并且稠密向量的索引需要大量的内存。针对这些问题,作者提出了VisualSparta,兼顾了准确率和检索速度。本文的贡献包括:
- 提出了一个新的基于片段交互作用的图文检索模型,并取得了SOTA的性能;
- 反向索引 (Inverted index) 被证实对图文检索有效。
该模型利用词袋模型表示文本查询,预训练模型编码图像的多模态表示。由于文本查询的离散表示,可以将图像进行倒排索引,降低了检索的时间复杂度,这保证了高效率,可以应用在大规模跨模态检索的场景中。同时,引入的大规模图文预训练模型,保证了检索的高精度。在MSCOCO和Flickr30K上的实验结果验证了方法在检索效率和检索精度上的有效性。
模型结构
文本查询的表示
由于查询处理是在检索过程中的在线操作,因此需要很好地考虑编码查询的效率。
不同于一些方法对query编码成文本序列,本方法先将query编码成词向量。将查询中所有单词的词嵌入作为查询的表示,没有常规模型中的上下文编码,减少检索时的计算量。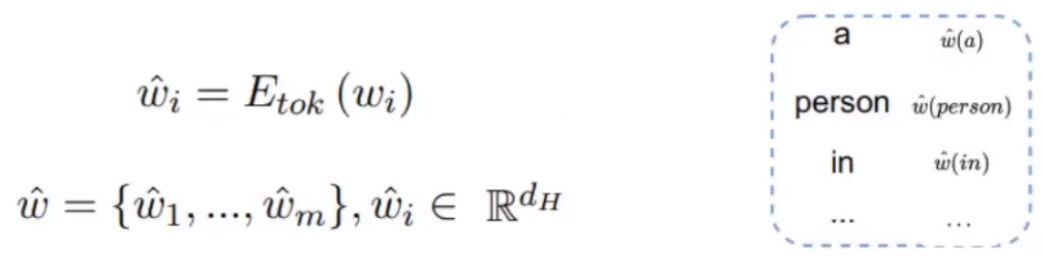
图像的表示
包含区域中物体的视觉表示和文本表示(属性;标签)。
对于每幅图像,作者采用了三种特征:局部的深度特征,局部的位置特征,目标标签特征。
- 局部的深度特征 (regional deep feature):采用Faster-RCNN提取,即:
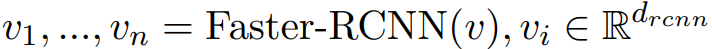
- 局部的位置特征 (regional location feature):每个局部都包含六个位置特征,即:
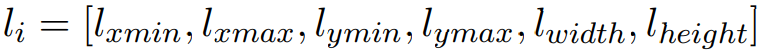
每个图像的局部都采用上述两个特征的级联: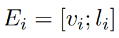
,图像特征为: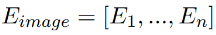
- 目标标签特征 (object label feature):对于每个局部都采用三种编码,即:word embedding、position embedding、segment embedding,即:
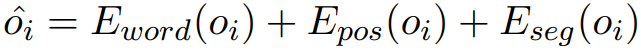
,图像的标签特征为: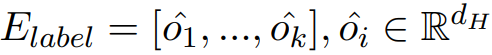
图像特征表示为: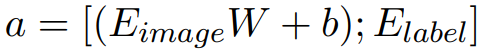
,最后再输入到Transformer中:
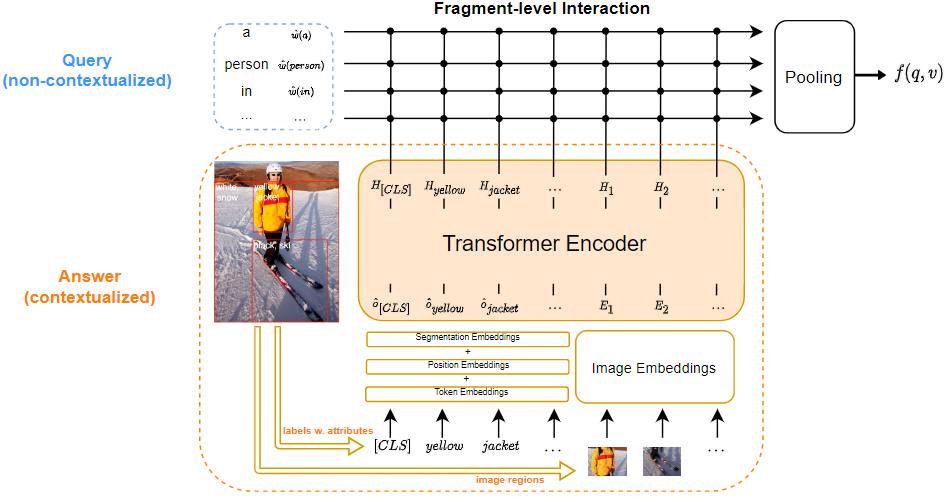
VisualSparta模型。它首先计算上下文化的图像区域表示和非上下文化的查询令牌表示。然后计算每个查询标记和图像区域之间的匹配得分,这些得分可以存储在一个反向索引中以便进行有效的搜索。
相似度函数
逐一计算文本和图像中细粒度级别的相似度。
先捕获每个图像区域与每个查询单词令牌之间的片段级相互作用,计算每个局部与每个单词的相似度yi;通过relu和可训练的偏差的组合产生稀疏的嵌入输出;对所有局部相似度取log(防止得分过高)并进行累加总结得分。
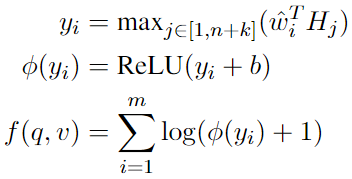
索引和检索
提前计算所有图像和词表中每一个词的相似度,倒排索引:
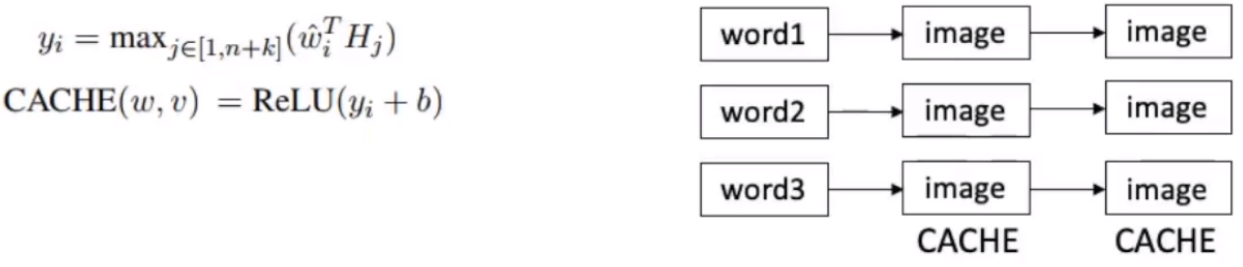
检索:

实验
数据集
本文中的数据集,我们使用MSCOCO和Flickr30k数据集进行文本到图像检索任务的培训和评估。MSCOCO是一个大规模的多任务数据集,包括对象检测,语义分割和图像字幕数据。在本实验中,我们遵循以前的工作,并使用图像字幕数据拆分进行文本模型培训和评估。Flickr30k是另一个公共可用的图像字幕数据集,总共包含31,783张图像,使用了29,783张图像进行训练,并使用1,000张图像进行验证。根据1,000张测试图像的结果报告得分。对于速度实验,除了MSCOCO 1K和5K拆分外,我们还创建了113K分配和1M拆分,两次新数据拆分以测试大规模检索设置中的性能。由于这些拆分仅用于速度实验,因此我们直接重复了现有数据集中的训练数据,而不必担心训练和测试阶段之间的数据泄漏。
评估指标
我们使用召回率作为我们的准确评估指标。在MSCOCO和FLIKR30K数据集中,我们报告了Reacll@t,t = [1,5,10],并与以前的工作进行比较。为了进行速度性能评估,我们选择每秒查询,而延迟(MS)作为评估度量,以测试每个模型在不同尺寸的图像索引下以速度的性能。
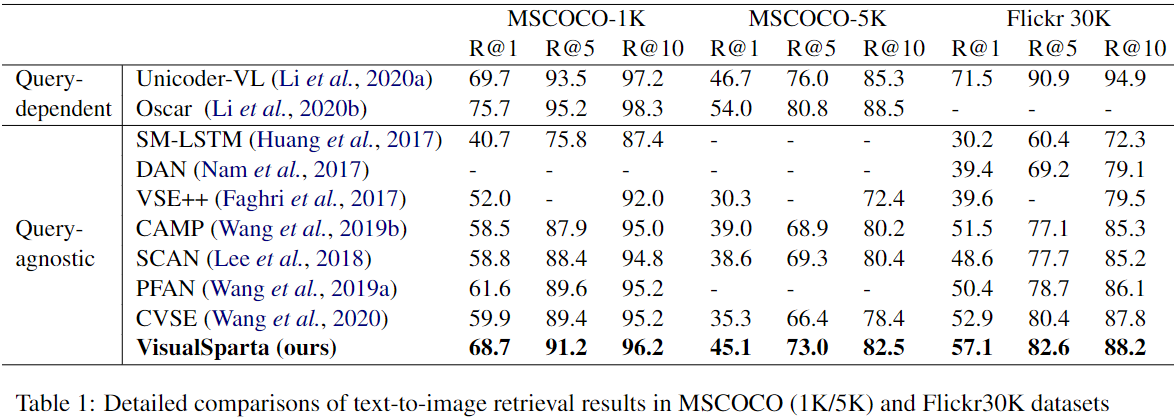
实验结果
优于所有查询无关方法,稍差于查询相关方法。
总结思考
提出了VisualSparta,一个高效的跨模态检索模型,同时保证检索精度;
该模型结合了预训练编码器和细粒度级别的打分方式;
大规模的图像倒排索引使得检索非常高效,适合现实场景的跨模态检索。
据我们所知,VisualSparta是第一个基于transformer的文本对图像检索模型,主要创新之处在于将强大的预训练图像编码器与片段级评分相结合。可以实现实时搜索非常大的数据集,与以前的最新方法相比,准确性的改进很大。