我们知道Redis数据库是使用C语言写的,然而其内部的字符串的存储却并不是使用传统的C语言字符串表示,而是使用一种名为简单动态字符串(Simple Dynamic String,SDS) 的抽象数据类型。
首先我们来对SDS有一个大概的认识
如果我们客户端执行如下命令
127.0.0.1:6381> set msg "hello world"那么Redis将会在数据库中创建一个新的键值对,其中:
键值对的键是一个字符串对象,对象的底层的实现是一个保存着 "msg" 的SDS
同样,键值对的值的底层的实现就是一个保存着"hello world" 的SDS
SDS除了用来保存数据库中的字符串之外,SDS还被用作缓冲区(buffer),如AOF模块中的AOF缓冲区,以及客户端状态中的输入缓冲区
接下来我们来看一看SDS的定义
struct sdshdr{
int len; // SDS所保存的字符串的长度
int free; // buf数组中未使用的字节的数量
char buf[]; // 字节数组,用于保存字符串(大小等于 len+free+1)
};其中buf数组的大小等于len+free+1,其中加一的为末尾的标识 ‘\0’
如下SDS的存储示例
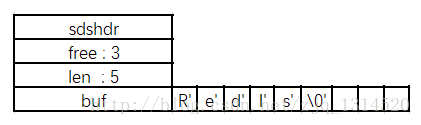
其中free=3 就是还有三个字节的空间未分配,len=5 就是存储的字符串Redis 的长度,而我们可以很明显的看出buf的长度为free+len+1=9
那么SDS与传统的C语言字符串的区别有哪些呢?
首先由于SDS的结构中有对应的free和len属性来记录相应的字符串的长度,所以获取SDS字符串长度的时间复杂度为
SDS并不会使得缓冲区溢出
我们知道传统的C语言字符串会导致溢出,因为其不会检查当前字符数组剩余空间的大小。
而SDS的内存分配策略则解决了这一问题,比如说当我们使用sdscat()函数在当前的字符串后面拼接字符串时,会检查给定的空间是否够用,如果不够则会事先扩充SDS的空间大小。
频繁的内存分配和内存回收就会带来性能问题,为此,Redis分别实现了空间预分配和惰性空间两种优化策略。
空间预分配
空间预分配用于优化SDS的字符串的增长操作:当SDS的API对一个SDS字符串进行修改,并且此时SDS的空间不够的时候,系统不仅会为SDS分配增长所必要的空间,还会分配额外的未使用的空间,其规则如下
如果对SDS进行修改之后,SDS的长度(
len)将会小于1MB,那么将会分配和len大小相等的未使用空间,这时候free=len如果对SDS进行修改之后,SDS的长度(
len)将会大于等于1MB,那么将会分配和1MB的未使用空间,这时候free=1MB
我们拿上面的第一点规则进行图示讲解
如有如下的SDS字符串,其使用空间为5,未使用空间为3
现在使用sdscat(str," dbase")进行拼接操作,这时候就需要分配额外空间
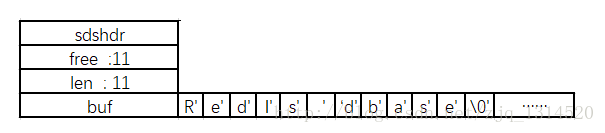
这时候分配内存后len=11,所以系统就会再额外的分配11字节的未使用空间,于是free=11
惰性空间释放
空间预分配用于优化SDS的字符串的缩短操作:当SDS的API对一个SDS字符串进行缩短时,程序并不会立即回收多余的未使用的空间,而是通过会增加free属性的值,将未使用的空间记录下来,并等待将来使用。
我们使用sdstrim()函数来做一个示例
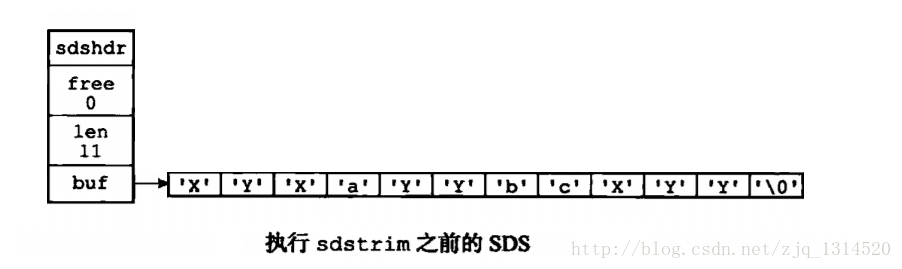
现在执行sdstrim(str,"XY"),来移除str中的所有'x'和'Y'字符
这样得到的结果为

看到上面我们就知道通过sdstrim(str,"XY")缩短字符串后多余的8个字节的空间并没有被回收掉,而是将free的值加了8从而记录下了多余的空间,从而可以再次利用。
此外,SDS还是二进制安全的,因为SDS字符串是通过len的大小判断字符串结束的(不是通过'\0'),从而其中可以存储'\0',这就是说其可以保存任意格式的二进制数据。
那么为什么还要在SDS字符串的末尾加上一个'\0'呢?
这是因为为了使SDS字符串兼容部分的C语言字符串函数,比如说<string.h>中过的函数,从而避免了代码的重复,达到重用的效果。