文章目录
MySQL数据库事务操作、主从复制及Redis数据库读写分离、主从同步的实现机制
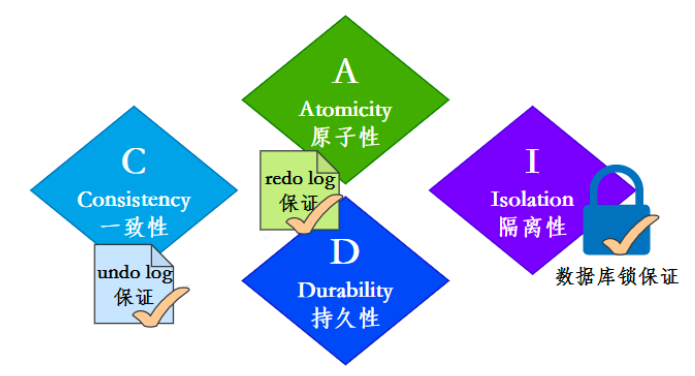
ACID及如何实现
原子性、一致性、隔离性与持久性
-
事务的隔离性是通过数据库锁的机制实现的。
-
事务的一致性由undo log来保证:undo log是逻辑日志,记录了事务的insert、update、deltete操作,回滚的时候做相反的delete、update、insert操作来恢复数据。
-
事务的原子性和持久性由redo log来保证:redolog被称作重做日志,是物理日志,事务提交的时候,必须先将事务的所有日志写入redo log持久化,到事务的提交操作才算完成。
事务隔离级别:
读未提交:当前事务读取时,可以看到其他事务未提交的数据,容易造成脏读;
读已提交:当前事务读取时,可以看到其他事务已提交的数据,在当前事务中可能多次读取的数据不相同,容易造成不可重复读;
可重复读:当前事务读取时,生成一个当前的读取快照,之后的每次读取数据,在快照中读取,但是对于其他事务新插入的数据是可以读到的,容易造成幻读。
串行化:是 4 种事务隔离级别中隔离效果最好的,解决了脏读、可重复读、幻读的问题,但是效果最差,它将事务的执行变为顺序执行,与其他三个隔离级别相比,它就是相当于单线程,后一个事务的执行必须等待前一个事务结束才能执行。
MVCC 多版本并发控制
通过维护数据历史版本,从而解决并发访问情况下的读一致性问题。
READ COMMITTED 是每次读取数据前都生成一个ReadView,这样就能保证自己每次都能读到其它事务提交的数据;
REPEATABLE READ 是在第一次读取数据时生成一个ReadView,这样就能保证后续读取的结果完全一致。
MySQL数据库主从复制
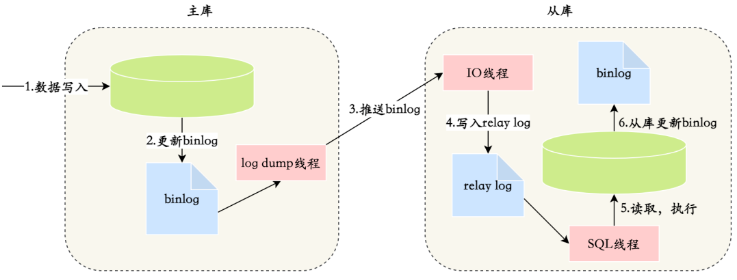
- master数据写入,更新binlog
- master创建一个dump(转存)线程向slave推送binlog
- slave连接到master的时候,会创建一个IO线程接收binlog,并记录到relay log中继日志中
- slave再开启一个sql线程读取relay log事件并在slave执行,完成同步
- slave记录自己的binglog
主从同步延迟怎么处理
主从同步延迟的原因
一个服务器开放N个链接给客户端来连接的,这样有会有大并发的更新操作, 但是从服务器的里面读取 binlog 的线程仅有一个,当某个 SQL 在从服务器上执行的时间稍长 或者由于某个 SQL 要进行锁表就会导致,主服务器的 SQL 大量积压,未被同步到从服务器里。这就导致了主从不一致, 也就是主从延迟。
主从同步延迟的解决办法
解决主从复制延迟有几种常见的方法:
- 写操作后的读操作指定发给数据库主服务器
例如,注册账号完成后,登录时读取账号的读操作也发给数据库主服务器。这种方式和业务强绑定,对业务的侵入和影响较大,如果哪个新来的程序员不知道这样写代码,就会导致一个bug。
- 读从机失败后再读一次主机
这就是通常所说的 “二次读取” ,二次读取和业务无绑定,只需要对底层数据库访问的 API 进行封装即可,实现代价较小,不足之处在于如果有很多二次读取,将大大增加主机的读操作压力。例如,黑客暴力破解账号,会导致大量的二次读取操作,主机可能顶不住读操作的压力从而崩溃。
- 关键业务读写操作全部指向主机,非关键业务采用读写分离
例如,对于一个用户管理系统来说,注册 + 登录的业务读写操作全部访问主机,用户的介绍、爰好、等级等业务,可以采用读写分离,因为即使用户改了自己的自我介绍,在查询时却看到了自我介绍还是旧的,业务影响与不能登录相比就小很多,还可以忍受。
还有:
1、优化网络环境:主从复制时,减小主从服务器之间网络延迟对数据库同步的影响。可以考虑优化网络之间连接的带宽、增加从库的硬件性能等。
2、增加从库数量:增加从库数量可以增加数据同步的速度和可靠性,同时也能减少每个从库的负担,提高从库响应速度。
3、调整数据库相关参数:可以调整一些MySQL数据库中的相关参数,比如调整binlog格式、binlog缓冲区大小、innodb_flush_log_at_trx_commit等参数,采用半同步模式,以加快数据的同步速度。
4、分区数据库:将数据库分成多个区,每个从库只复制自己所需要的数据区,可以有效的减少排队堵塞、网络传输等方面的延迟问题。
综上所述,优化网络环境、增加从库数量、调整数据库相关参数、分区数据库等方法可以有效的降低MySQL主从复制模式的延迟。
Redis 读写分离
1.什么是主从复制
主机数据更新后根据配置和策略,自动同步到备机的Master/Slaver,Master 以写为主,Slave以读为主
主从复制,是指将一台 Redis 服务器的数据,复制到其他的 Redis 服务器。前者称为 主节点(master),后者称为 从节点(slave)。且数据的复制是 单向 的,只能由主节点到从节点。Redis 主从复制支持 主从同步 和 从从同步 两种,后者是 Redis 后续版本新增的功能,以减轻主节点的同步负担。
从复制主要的作用?
- 数据冗余: 主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
- 故障恢复: 当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复 (实际上是一种服务的冗余)。
- 负载均衡: 在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务 (即写 Redis 数据时应用连接主节点,读 Redis 数据时应用连接从节点),分担服务器负载。尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高 Redis 服务器的并发量。
- 高可用基石: 除了上述作用以外,主从复制还是哨兵和集群能够实施的 基础,因此说主从复制是 Redis 高可用的基础。
2.读写分离的优点
1.读写分离,性能提高
2.容灾快速恢复
Redis为什么快呢?
Redis的速度⾮常的快,单机的Redis就可以⽀撑每秒十几万的并发,相对于MySQL来说,性能是MySQL的⼏⼗倍。速度快的原因主要有⼏点:
- 完全基于内存操作
- 使⽤单线程,避免了线程切换和竞态产生的消耗
- 基于⾮阻塞的IO多路复⽤机制
- C语⾔实现,优化过的数据结构,基于⼏种基础的数据结构,redis做了⼤量的优化,性能极⾼