点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
今天自动驾驶之心为大家解读一篇大火的世界模型相关文章DriveDreamer,文章一作是自动驾驶之心的好朋友王啸峰博士,他们提出了首个真实世界驱动的自动驾驶world model,论文单位包括极佳科技GigaAI和清华大学!文章作者已经授权自动驾驶之心原创,如果需要转载,请在文末联系!
编辑 | 自动驾驶之心

作者:王啸峰
论文:https://arxiv.org/pdf/2309.09777
代码:https://github.com/JeffWang987/DriveDreamer
项目地址:https://drivedreamer.github.io
1. 背景意义
世界模型(World Models)由于其理解环境、和环境交互的能力,正在自动驾驶领域引起广泛关注。世界模型具有生成高质量驾驶视频和用于端到端驾驶的巨大潜力。然而,目前在自动驾驶领域的世界模型研究主要关注游戏环境或模拟环境,缺乏对真实世界驾驶情景的表现。因此,我们引入了DriveDreamer,这是一个完全源自真实世界驾驶情境的开创性世界模型。考虑到在复杂驾驶场景中对世界进行建模涉及庞大的搜索空间,我们提出使用强大的扩散模型来构建对复杂环境的表征。此外,我们引入了一个两阶段的训练流程。在初始阶段,DriveDreamer获得了对结构化交通约束的深刻理解,而随后的阶段则赋予了它预测未来状态的能力。所提出的DriveDreamer是首个建立在真实世界驾驶情境之上的世界模型。我们在具有挑战性的nuScenes基准上实例化了DriveDreamer,并进行了大量实验,验证了DriveDreamer能够实现精确可控的视频生成,忠实地捕捉了真实世界交通情景的结构约束。此外,DriveDreamer使得生成逼真和合理的驾驶策略成为可能,为互动和实际应用开辟了途径。


2. 相关工作
2.1 扩散模型(Diffusion Models)
扩散模型代表了一类概率生成模型的家族,它们逐渐引入噪声到数据中,随后学习逆转这一过程,以生成样本。这些模型最近引起了广泛关注,因为它们在各种应用中表现出卓越性能,为图像合成、视频生成和三维内容生成设定了新的基准。ControlNet、GLIGEN、T2I-Adapter和Composer等文章进一步引入了额外的学习参数来增强可控生成能力。它们利用了各种控制输入,包括深度图、分割图、Canny边缘和草图。同时,BEVControl和CityDreamer加入了布局条件来增强图像生成。基于扩散的生成模型的基本本质在于它们理解和理解世界的复杂性。借助这些扩散模型的力量,DriveDreamer旨在理解复杂的自动驾驶场景。
2.2 Video Generation
视频生成和视频预测是理解视觉世界的有效方法。在视频生成领域,已经采用了几种标准架构,包括变分自编码器(VAEs)、自回归模型、基于流的模型和生成对抗网络(GANs)。最近,新兴的扩散模型也已扩展到视频生成领域,展示了更高质量的视频生成能力,能够生成逼真的帧和帧之间的连续过渡,同时提供可控的视频生成能力。视频预测模型代表了视频生成模型的一种专门形式,它们共享许多相似之处。具体而言,视频预测涉及根据历史视频观察来预测未来视频变化。DriveGAN通过指定未来的驾驶策略,建立了驾驶动作和像素之间的关联,从而预测未来的驾驶视频。相比之下,DriveDreamer将结构化交通条件、文本提示和驾驶动作作为输入,实现了与真实世界驾驶情景紧密对齐的精确、逼真的视频和动作生成。
2.3 World Models
世界模型已在基于模型的模仿学习中得到广泛探讨,并在各种应用中取得了显著的成功。这些方法通常利用VAE和LSTM来建模转换动态和渲染功能。世界模型的目标是建立环境的动态模型,使代理能够对未来有预测能力。在自动驾驶领域,这一方面至关重要,因为对未来的精确预测对安全操控至关重要。然而,在自动驾驶中构建世界模型面临着独特的挑战,主要是由于真实世界驾驶任务中固有的高样本复杂性。为了解决这些问题,ISO-Dream引入了对视觉动态的明确解缠分为可控状态和不可控状态。MILE 将世界建模融入BEV语义分割空间中,通过模仿学习增强了世界建模。SEM2 将Dreamer框架扩展到BEV分割图中,采用强化学习进行训练。尽管在世界模型方面取得了进展,但相关研究的一个关键局限性在于其主要关注模拟仿真环境。转向真实世界驾驶情景仍然是一个未充分探索的领域。
3. DriveDremear方法设计
DriveDreamer的总体框架如下图所示。框架始于初始参考帧及其对应的道路结构信息(即HDMap和3D框)。DriveDreamer利用提出的ActionFormer来在潜在空间中预测即将到来的道路结构特征。这些预测的特征作为条件提供给Auto-DM,后者生成未来的驾驶视频。同时,利用文本提示允许对驾驶情景风格进行动态调整(例如,天气和时间)。此外,DriveDreamer还结合了历史行动信息和从Auto-DM中提取的多尺度潜在特征,这些特征组合在一起生成合理的未来驾驶动作。
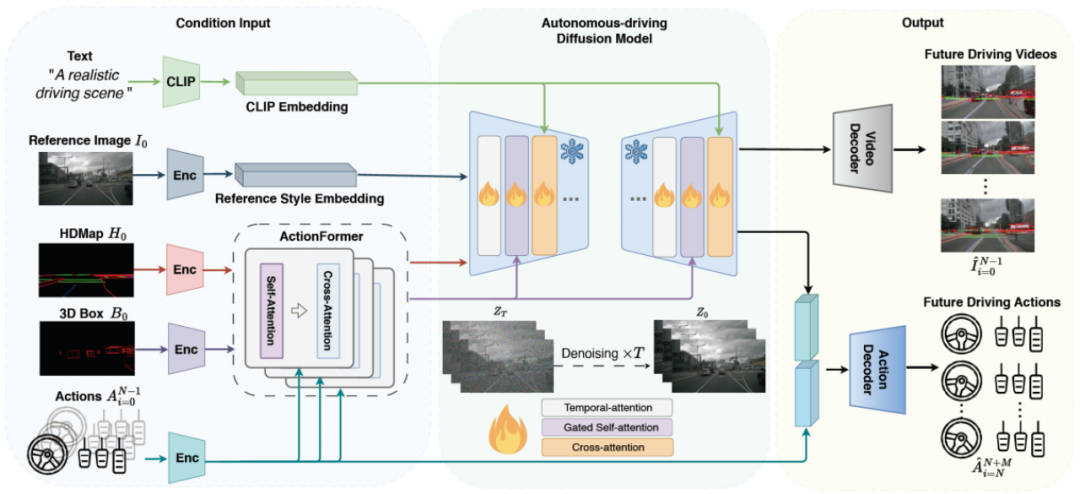
DriveDreamer集成了多模态输入,以生成未来的驾驶视频和驾驶策略,从而提升了自动驾驶系统的能力。关于在真实世界驾驶情景中建立世界模型的庞大搜索空间,我们引入了DriveDreamer的两阶段训练策略。这个策略旨在显著提高采样效率并加速模型的收敛速度。两阶段训练如下图所示。在第一阶段训练中有两个步骤。第一步涉及使用单帧结构化条件,引导DriveDreamer生成驾驶场景图像,促进其理解结构性交通约束。第二步将其理解扩展到视频生成。利用交通结构条件,DriveDreamer输出驾驶场景视频,进一步增强了其对运动过渡的理解。在第二阶段,训练的重点是使DriveDreamer能够与环境互动并有效地预测未来状态。这个阶段将初始帧图像及其对应的结构化信息作为输入。同时,提供了顺序驾驶动作,模型被期望生成未来的驾驶视频和未来的驾驶动作。这种互动赋予了DriveDreamer预测和操控未来驾驶情景的能力。在接下来的章节中,我们将深入探讨模型架构和训练流程的具体细节。

3.1 一阶段训练
在DriveDreamer中,我们引入了Auto-DM,用于从真实世界驾驶视频中建模和理解驾驶情景。值得注意的是,仅从像素空间理解驾驶场景在真实世界驾驶情景中存在挑战,因为搜索空间非常广泛。为了缓解这一问题,我们明确地将结构化交通信息作为条件输入。Auto-DM的总体结构如下图所示,结构化交通条件被投影到图像平面上,生成HDMap条件,以及3D框条件,还有框的类别。为了实现可控性,HDMap条件被2D卷积编码后与由前向扩散过程生成的嘈杂的潜在特征进行串联处理。对于3D框条件,我们利用Gated Self-attention(参考GLIGEN)进行控制条件的嵌入。为了进一步增强Auto-DM对驾驶动态的理解能力,我们引入了Temporal-attention,这些层增强了生成的驾驶视频中的帧的连贯性:首先,我们将视觉信号从N×C×H×W重塑为RC×NHW的形状。这种形状变换有助于后续的自注意力层学习帧间的动态关系。此外,还使用了Cross-attention来促进文本输入和视觉信号之间的特征交互,使文本描述能够影响驾驶场景属性,如天气和时间。
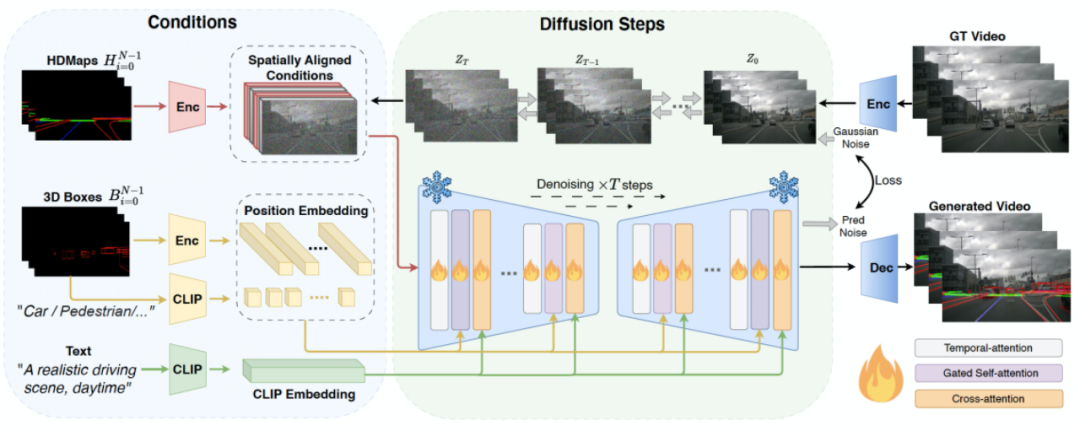
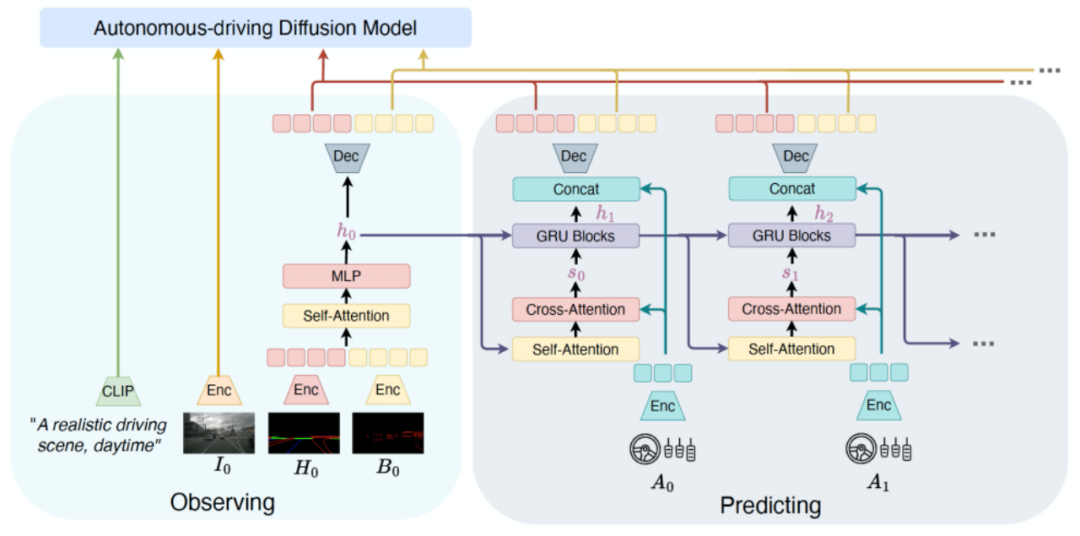
3.2 二阶段训练
目前一阶段的Auto-DM可以基于序列结构信息生成驾驶视频。然而,在视频预测任务中,超过当前时间戳的未来交通结构条件是不可用的。为了解决这个挑战,我们在第二阶段的训练中引入了ActionFormer,它利用驾驶动作来迭代预测未来的结构条件。ActionFormer的总体架构如下图所示。首先,初始结构条件被编码并展平为1D特征。该特征特征通过自注意力和MLP层进行串联和汇总,生成隐藏状态h0。随后,利用交叉注意力层构建了隐藏状态和驾驶动作之间的关联。为了预测未来的隐藏状态,我们使用门控循环单元(GRUs)进行迭代更新:这些隐藏状态与动作特征进行串联,然后被解码为未来的交通结构条件。值得注意的是,ActionFormer在特征级别预测未来的交通结构条件,这有助于减轻像素级别的噪音干扰,从而产生更鲁棒的预测。除了ActionFormer生成的交通结构条件和文本提示条件外,我们参考Video-LDM处理初始的图像观测。最后,我们将得到的交通结构化条件、初始帧图像条件、以及文本条件一起作为Auto-DM的输入。在二阶段训练中,视频预测和动作预测部分可以被建模为高斯分布和拉普拉斯分布。因此,我们使用均方差误差和L1损失来优化视频预测的训练。对于驾驶策略的预测,我们首先从Auto-DM中池化多尺度UNet特征。然后,将这些特征与历史动作特征串联在一起,然后通过MLP层解码生成未来的驾驶动作。基于这两阶段的训练,DriveDreamer已经获得了对驾驶世界的全面理解,包括交通结构的结构约束、未来驾驶状态的预测以及与已建立的世界模型进行互动。
4. 实验结果
4.1 可控视频生成
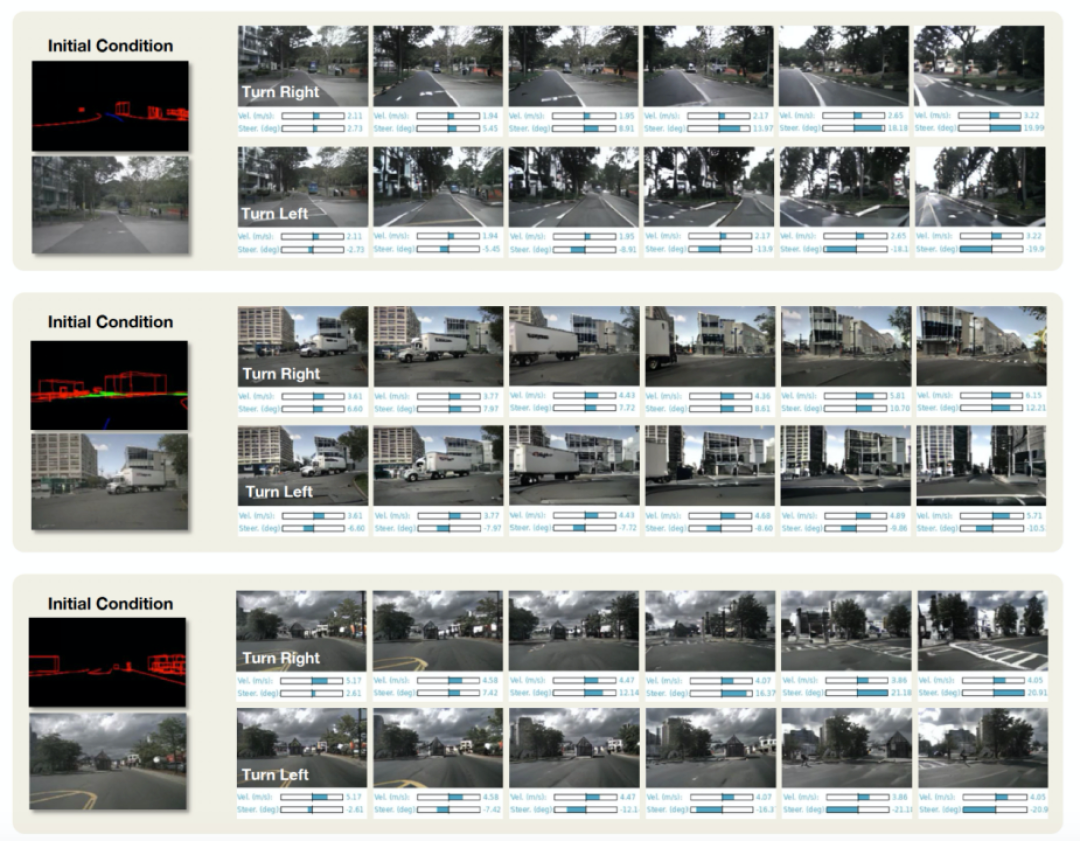
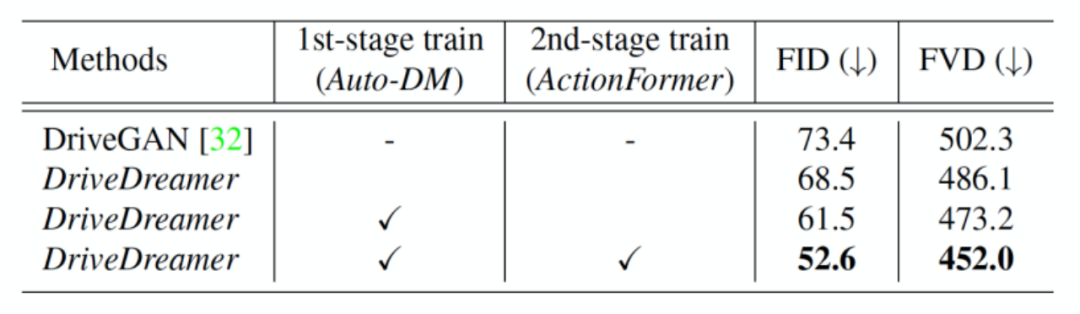
如图6所示,DriveDreamer在生成各种各样严格遵循结构化交通条件(包括HD地图和3D框等元素)的驾驶场景视频方面表现出效果。重要的是,我们还可以操控文本提示来诱发生成视频的变化,包括天气和一天中时间的变化。这种增强的适应性显著提高了生成视频输出的多样性。除了利用结构化交通条件生成驾驶视频外,DriveDreamer还具备通过适应不同驾驶动作来增加生成的驾驶视频多样性的能力。如图7所示,从初始帧及其对应的结构信息开始,DriveDreamer可以基于各种驾驶动作生成不同的视频,例如显示左转和右转的视频。总之,DriveDreamer在生成广泛范围的驾驶场景视频方面表现出色,具有高度可控性和多样性。因此,DriveDreamer在培训自动驾驶系统上具有巨大潜力,涵盖了各种任务,甚至包括边际情况和长尾场景。为了量化我们的两阶段训练方法的优势,我们提供了定量评估(如表1所示),与DriveGAN相比,我们的方法在没有第一阶段训练的情况下获得了更高的FID和FVD分数。此外,我们的研究结果表明,经过第一阶段训练后的DriveDreamer表现出对驾驶场景中的结构化信息的理解能力提高,从而生成更高质量的视频。最后,我们观察到,所提出的ActionFormer有效地利用了第一阶段训练期间获得的交通结构信息知识。进一步提高了生成视频的质量。

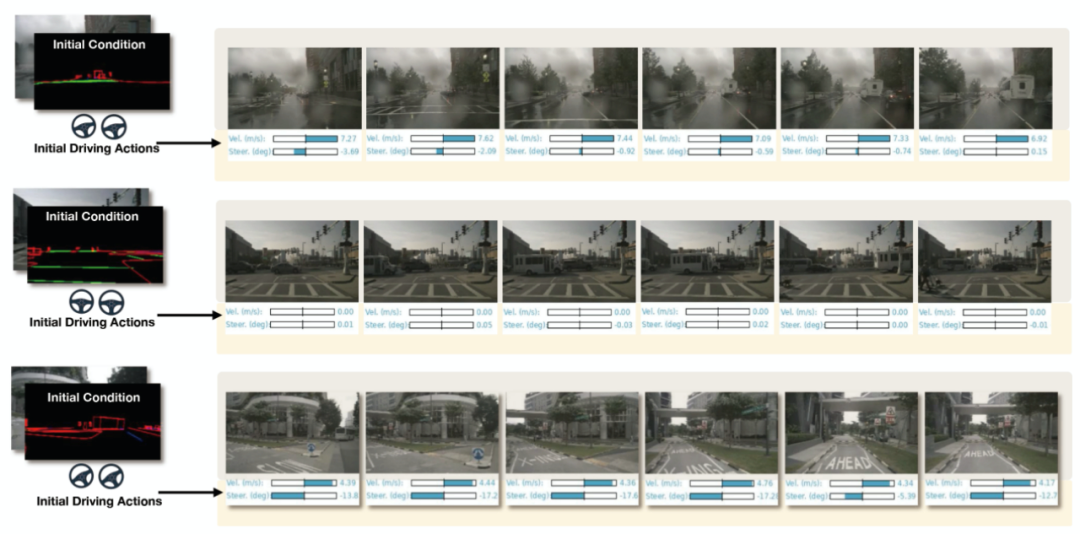
4.2 驾驶策略生成
除了生成可控的驾驶视频外,DriveDreamer还展示了预测合理驾驶动作的能力。如图8所示,给定初始帧条件和过去的驾驶动作,DriveDreamer可以生成与真实世界情景相符的未来驾驶动作。与相应的实际视频进行的生成动作的比较分析表明,即使在复杂情况下,如十字路口、遵守交通信号灯和执行转弯,DriveDreamer仍然能够一致地预测合理的驾驶动作。此外,我们进行了预测准确性的定量评估。在nuScenes数据集上进行的开环评估结果如表2所示。值得注意的是,仅使用历史驾驶动作作为输入,DriveDreamer在预测未来驾驶动作方面实现了高准确性。偏航角的平均预测误差仅为0.49°,速度预测误差仅为0.15 m/s。此外,通过将多尺度UNet特征与历史驾驶动作结合使用,我们进一步提高了预测准确性。需要注意的是,开环评估具有固有的限制,限制了驾驶动作预测的上限。因此,我们未来的工作将集中在闭环评估上,以进一步验证和增强DriveDreamer的性能。

5. 总结和展望
DriveDreamer代表了在自动驾驶领域中世界模型的重要探索,通过专注于真实世界的驾驶情境,并利用扩散模型的能力,DriveDreamer展示了其理解复杂环境、生成高质量驾驶视频和预测驾驶策略的能力。未来的工作将包括使用由DriveDreamer生成的数据来训练驾驶的foundation model。此外,我们计划扩展DriveDreamer的能力,以进行长时间和高分辨率的视频生成。此外,我们打算在闭环场景中评估DriveDreamer。这些努力将共同有助于增强世界建模在自动驾驶应用中的实用性。
投稿作者为『自动驾驶之心知识星球』特邀嘉宾,如果您希望分享到自动驾驶之心平台,欢迎联系我们!
① 全网独家视频课程
BEV感知、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、协同感知、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)
 视频官网:www.zdjszx.com
视频官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
近2000人的交流社区,涉及30+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(2D检测、分割、2D/3D车道线、BEV感知、3D目标检测、Occupancy、多传感器融合、多传感器标定、目标跟踪、光流估计)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多模态感知、Occupancy、多传感器融合、transformer、大模型、点云处理、端到端自动驾驶、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向。扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】平台矩阵,欢迎联系我们!
