参考资料:https://www.bilibili.com/video/BV1BS4y1E7tf/?p=12&spm_id_from=pageDriver
Node2vec简述
DeepWalk的缺点
用完全随机游走,训练节点嵌入向量,仅能反应相邻节点的社群相似信息,无法反映节点的功能角色相似信息。
Node2vec
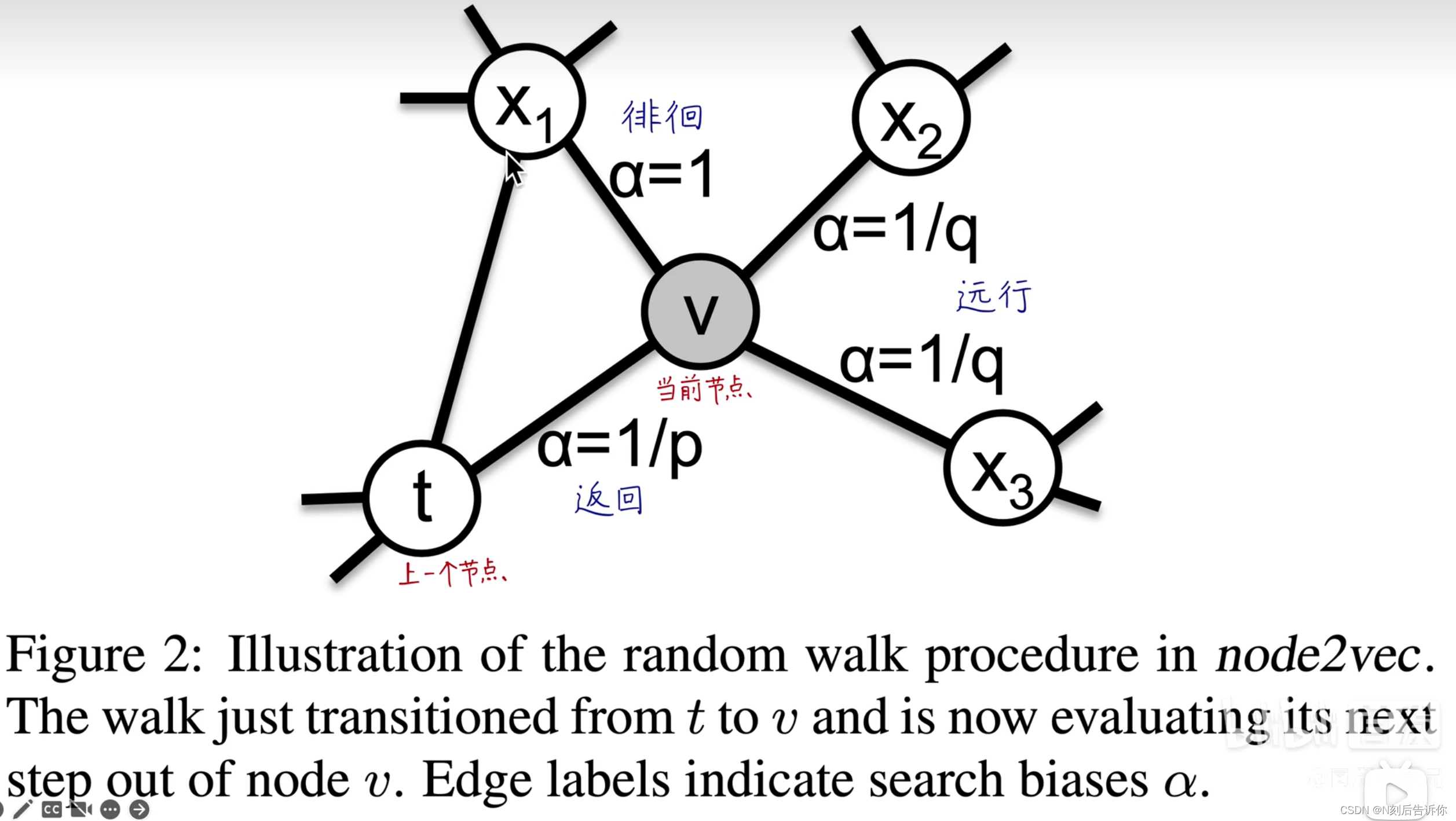
通过调节p和q的参数,可以调节权重。
p值很小,更愿意返回,则类似BFS,反映的是微观视角。
q值很小,更愿意返回,则类似DFS,反映宏观视角。
DFS捕捉的是homophily同质社群(社交网络)的特征
BFS捕捉的是Structural equivalence节点功能角色(中枢、桥接、边缘)的特征。
伪代码


一些技术细节
Alias Sampling:用空间换时间,时间复杂度O(1)的采样算法。
AliasSampling参考资料:https://keithschwarz.com/darts-dice-coins/
Node2vec论文精读
任何监督学习算法要求有内含丰富语义,有分类区分性以及相互独立的特征。
图嵌入的方法:
1.手动构造特征
2.基于矩阵分解的图嵌入
3.基于随机游走的图嵌入
4.基于神经网络
同一个社群的节点、同一个功能角色的节点,应该被编码成相近的embedding
使用二阶随机游走方法来产生节点的邻域。
一阶随机游走(一阶马尔科夫性):下一个节点仅与当前节点有关(deepwalk,pagerank)
二阶随机游走(二阶马尔科夫性):下一个节点不仅与当前节点有关,还与上一个节点有关扫描二维码关注公众号,回复: 16893572 查看本文章
p,q的不同对应不同的探索策略,具有可解释性。
最优的p,q可以通过调惨得到。
贡献
1.提出node2vec,可以通过调节p、q来探索网络的不同特性,使用SGD来优化
2.node2vec符合网络科学的准则,提供了灵活的表示
3.node2vec将节点嵌入推广到了连接嵌入
4.在多类别分类任务和连接预测任务上进行了实验。
3.Node2vec算法
图: G = ( V , E ) G=(V,E) G=(V,E)
采样策略: S S S
节点 u u u的领域节点 N S ( u ) ⊂ V N_S(u) \subset V NS(u)⊂V
任务:学习映射 f : V → R d f: V \rightarrow \mathbb{R}^d f:V→Rd:d是词嵌入后的维度
目标函数:
max f ∑ u ∈ V log Pr ( N S ( u ) ∣ f ( u ) ) \max _f \sum_{u \in V} \log \operatorname{Pr}\left(N_S(u) \mid f(u)\right) fmaxu∈V∑logPr(NS(u)∣f(u))
为了简化问题,做出两个假设:
- 条件独立性假设:周围节点互相不影响:
Pr ( N S ( u ) ∣ f ( u ) ) = ∏ n i ∈ N S ( u ) Pr ( n i ∣ f ( u ) ) \operatorname{Pr}\left(N_S(u) \mid f(u)\right)=\prod_{n_i \in N_S(u)} \operatorname{Pr}\left(n_i \mid f(u)\right) Pr(NS(u)∣f(u))=ni∈NS(u)∏Pr(ni∣f(u)) - 特征空间的对称性:两个节点之间相互影响的程度是一样的,因此可以用特征的点乘来表示概率
Pr ( n i ∣ f ( u ) ) = exp ( f ( n i ) ⋅ f ( u ) ) ∑ v ∈ V exp ( f ( v ) ⋅ f ( u ) ) \operatorname{Pr}\left(n_i | f(u)\right)=\frac{\exp \left(f\left(n_i\right) \cdot f(u)\right)}{\sum_{v \in V} \exp (f(v) \cdot f(u))} Pr(ni∣f(u))=∑v∈Vexp(f(v)⋅f(u))exp(f(ni)⋅f(u))
设 Z u = ∑ v ∈ V exp ( f ( u ) ⋅ f ( v ) ) Z_u=\sum_{v \in V} \exp (f(u) \cdot f(v)) Zu=∑v∈Vexp(f(u)⋅f(v)),称为配分函数,则目标函数可化为
Pr ( n i ∣ f ( u ) ) = exp ( f ( n i ) ⋅ f ( u ) ) ∑ v ∈ V exp ( f ( v ) ⋅ f ( u ) ) \operatorname{Pr}\left(n_i \mid f(u)\right)=\frac{\exp \left(f\left(n_i\right) \cdot f(u)\right)}{\sum_{v \in V} \exp (f(v) \cdot f(u))} Pr(ni∣f(u))=∑v∈Vexp(f(v)⋅f(u))exp(f(ni)⋅f(u))
3.1 传统搜索策略
如何定义领域 N S ( u ) N_S(u) NS(u)依赖于策略 S S S。不同策略下,邻域是不一样的。
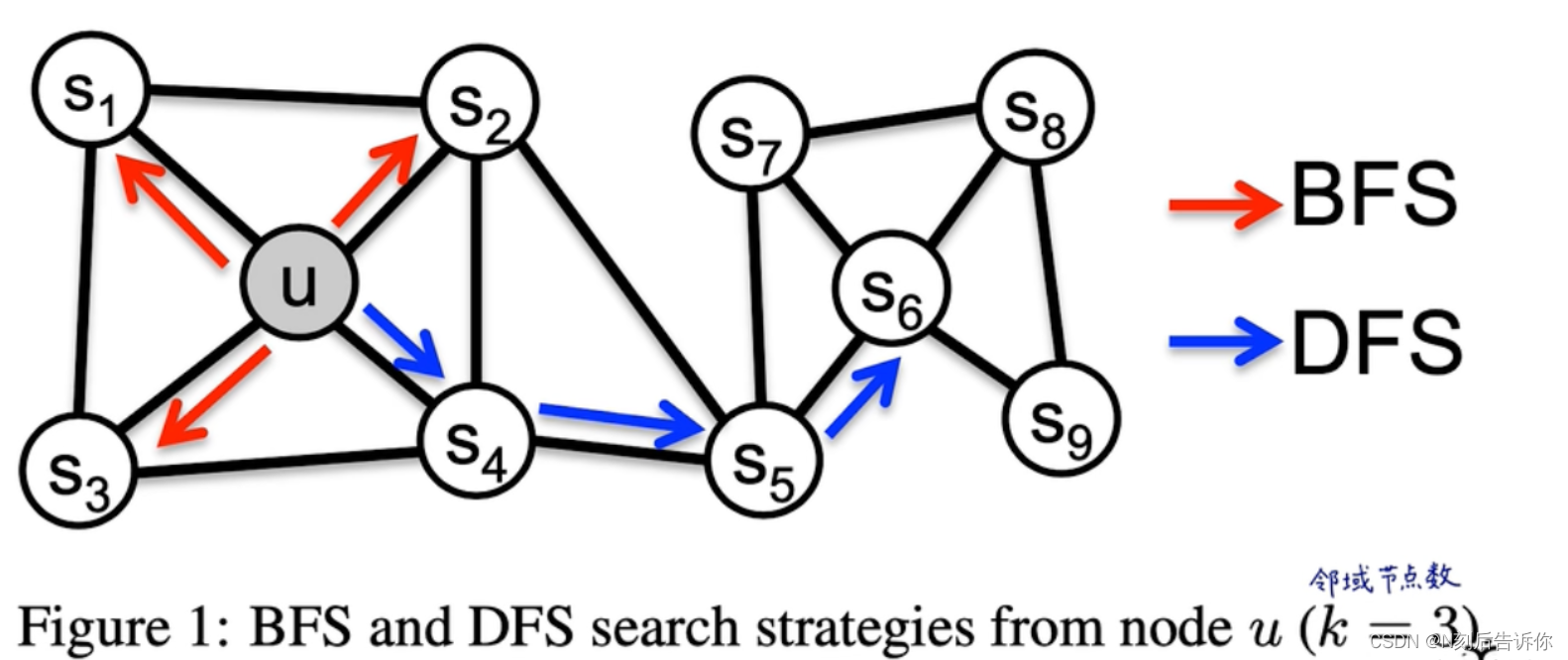
BFS:只探索近邻。
DFS:渐行渐远,探索离原节点较远的节点。
在homophily(同质性)假设下(对应BFS),同一个社区的节点,词嵌入后会比较相似。如s1和u
在structural equivalence假设下(对应DFS),有相同结构角色功能的节点,词嵌入后会比较相似。如u和s6
在真实图里,这两种不是互斥的,一个图可能既有homophily特质,也有structural equivalence特质。
BFS采样结果比较稳定,方差较小。
DFS采样结果比较不稳定,方差较大。
3.2 node2vec
3.2.1 随机游走
u u u:起始点
t t t:上一节点
v v v:当前节点
x x x:下一节点
N s ( t ) N_s(t) Ns(t):上一节点的邻居节点
k k k:当前节点v的邻居节点个数
l l l:随机游走序列节点个数
下一个节点的生成概率公式:
P ( c i = x ∣ c i − 1 = v ) = { π v x Z if ( v , x ) ∈ E 0 otherwise P\left(c_i=x \mid c_{i-1}=v\right)= \begin{cases}\frac{\pi_{v x}}{Z} & \text { if }(v, x) \in E \\ 0 & \text { otherwise }\end{cases} P(ci=x∣ci−1=v)={
Zπvx0 if (v,x)∈E otherwise
其中, π v x \pi_{v x} πvx是未归一化的转移概率。
3.2.2 搜索的偏向 α \alpha α
直接用权重作为游走概率,则无法调节搜索策略。直接用BFS或者DFS则太极端,无法平滑调节。
于是考虑带参数p和q的二阶随机游走:
α p q ( t , x ) = { 1 p if d t x = 0 1 if d t x = 1 1 q if d t x = 2 \alpha_{p q}(t, x)= \begin{cases}\frac{1}{p} & \text { if } d_{t x}=0 \\ 1 & \text { if } d_{t x}=1 \\ \frac{1}{q} & \text { if } d_{t x}=2\end{cases} αpq(t,x)=⎩
⎨
⎧p11q1 if dtx=0 if dtx=1 if dtx=2
π v x = α p q ( t , x ) ⋅ w v x \pi_{v x}=\alpha_{p q}(t, x) \cdot w_{v x} πvx=αpq(t,x)⋅wvx
因为既要下一个节点x考虑当前节点v可达,也要考虑x与上一个节点t的距离,所以是二阶的随机游走
空间复杂度:随机游走需要存邻接表 O ( ∣ E ∣ ) O(|E|) O(∣E∣)。为了方便,二阶随机游走需要存 O ( a 2 ∣ V ∣ ) O(a^2|V|) O(a2∣V∣)来记录距离,其中 a a a是图中每个点的平均连接数。
时间复杂度: O ( l k ( l − k ) ) O\left(\frac{l}{k(l-k)}\right) O(k(l−k)l),k是领域的节点个数
随着硬件的发展,空间复杂度没有时间复杂度重要
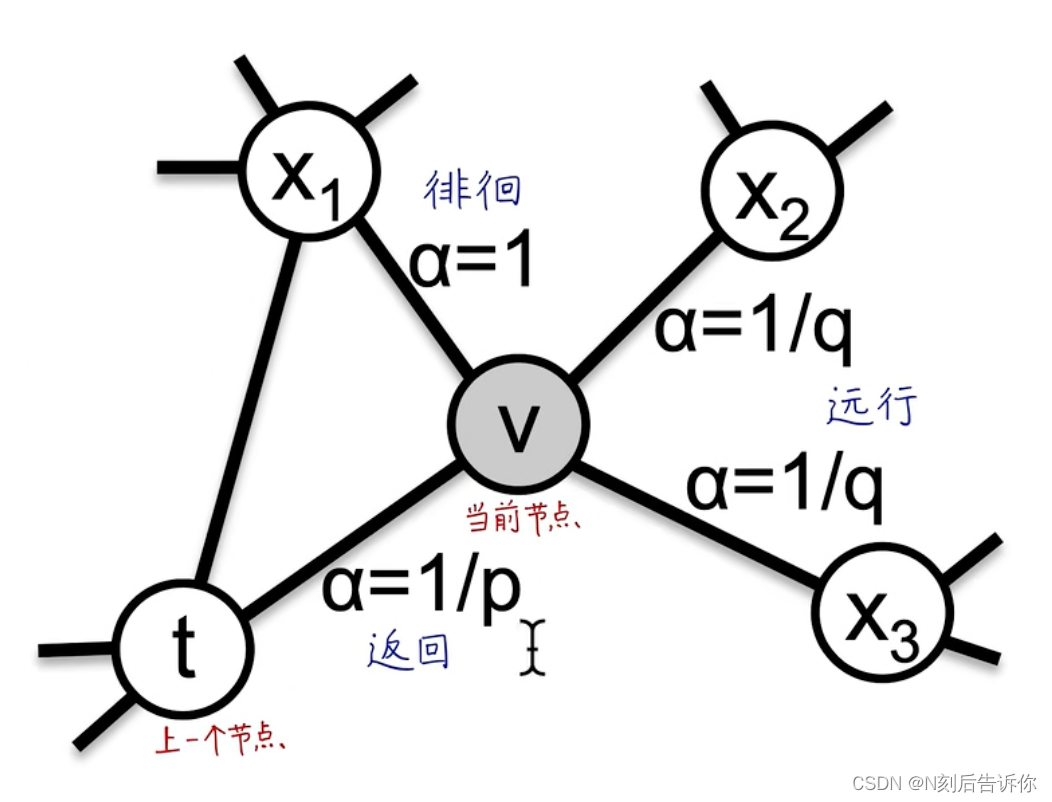
3.2.3 伪代码

总共分为三个阶段:
- 已知p,q和图权重,生成随机游走的采样策略,存入表中
- 每个节点生成r个随机游走序列,其中node2vecWalk函数用于生成起始点为u,长为l的随机游走序列。

- 用生成的随机游走序列,通过skip-gram模型训练得到节点嵌入表示
AliasSampling是用空间(预处理)换时间的方法,它的时间复杂度是O(1),特别适用于大量反复抽样情况下,优势很突出。它将离散分布抽样转换为均匀分布抽样。
随机游走过程中,会有隐式的偏差。所以每个节点都采样r次,尽可能减少偏差。
每个阶段都可以并行,并且可以异步训练,可扩展性非常好
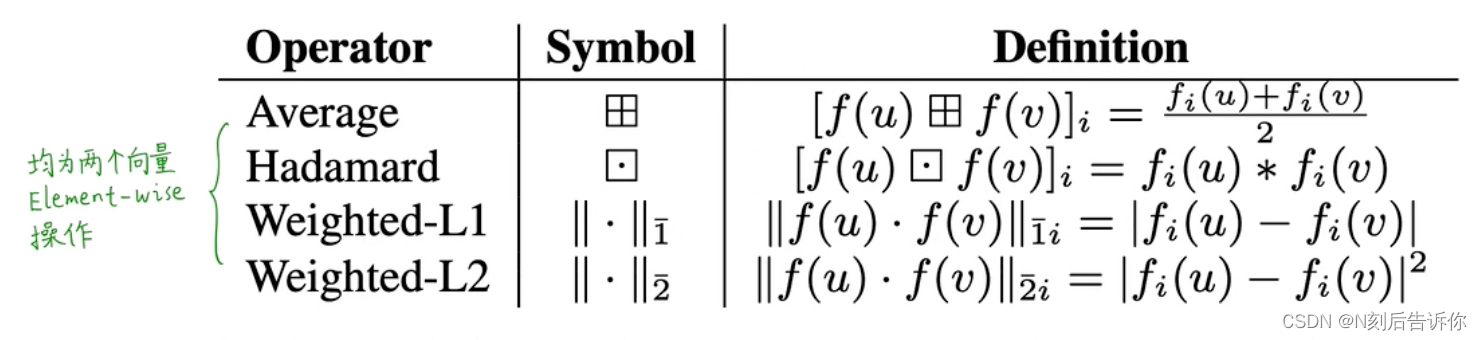
3.3 学习连接的特征
将node embedding扩展到link embedding
给定两个节点,定义一个二元操作符 ∘ \circ ∘来生成连接的表示:
4.实验
4.1:悲惨世界人物关系图的图嵌入
4.2 实验设置
与其他算法对比
严格控制各对比实验的条件
4.3 多标签分类
4.4 参数敏感度
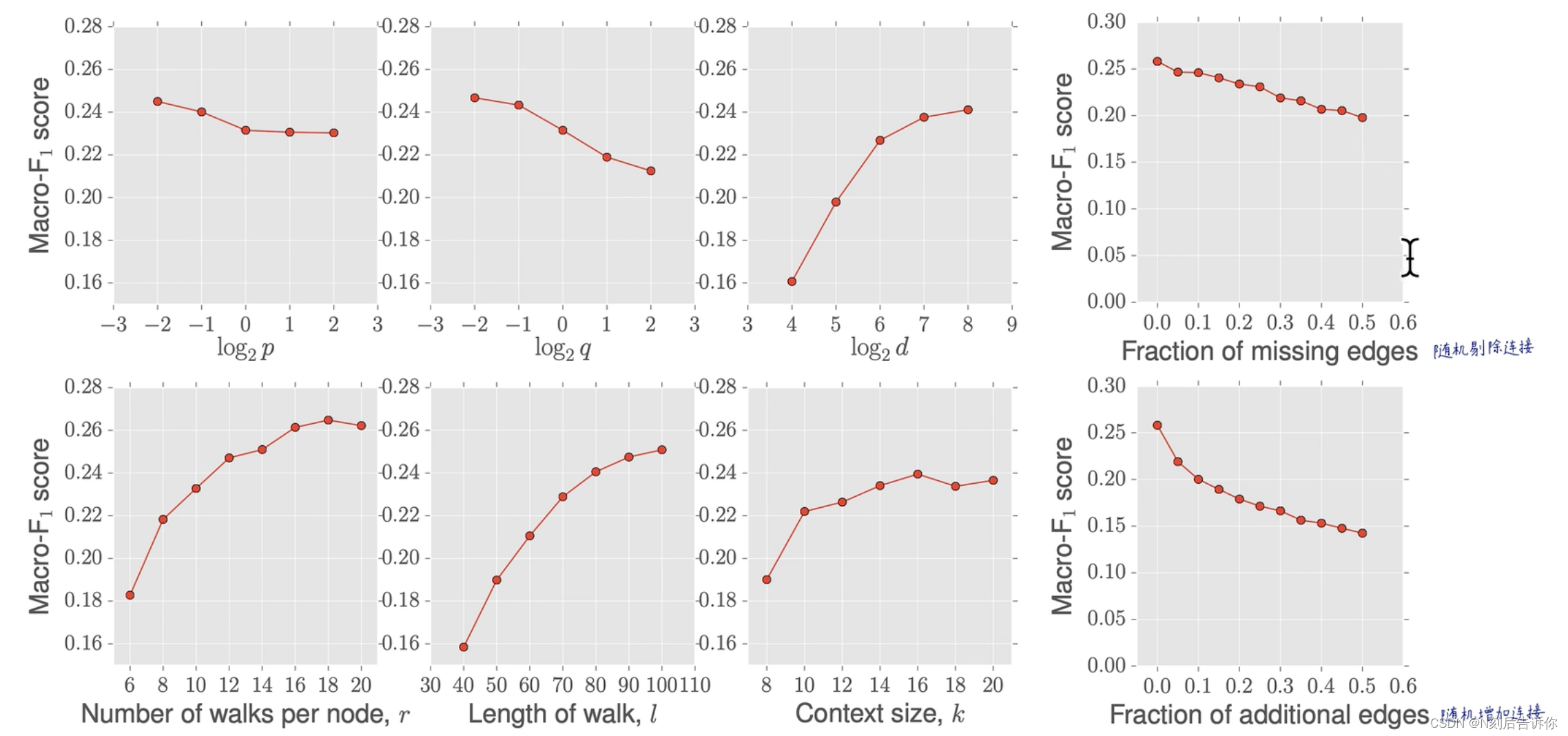
随机剔除一些连接,性能会缓慢下降
4.5 扰动分析
缺失连接:保证连通域不变的情况下,进行剪枝,不会造成新的孤岛。
噪声增加连接:随机增加连接,在传感器网络中更常见。
4.6 可扩展性
构建E-R随机图,节点数从100到100万,来做node2vec算法,来看时间。可以看到时间复杂度近似为线性。
4.7 连接预测
构建正负样本的二分类问题。
采集测试集:从网络中取50%的边,同时确保不改变剩下的网络的连通性。再从网络中随机选取一些不相邻的节点对,作为负样本。然后可以训练二分类模型了。
5.讨论和结论
node2vec展示了一定的可解释性,p、q参数是灵活可调的,在复杂任务上的性能不错,特别是在扰动数据集上。
节点嵌入可以拓展到连接嵌入上。
代码实现
参考:https://www.bilibili.com/video/BV1VS4y1E7Me/?p=14&spm_id_from=pageDriver