 rome:
rome:
检测到无壳,32位
直接用IDA打开,转到main函数
int func()
{
int result; // eax
int v1[4]; // [esp+14h] [ebp-44h]
unsigned __int8 v2; // [esp+24h] [ebp-34h] BYREF
unsigned __int8 v3; // [esp+25h] [ebp-33h]
unsigned __int8 v4; // [esp+26h] [ebp-32h]
unsigned __int8 v5; // [esp+27h] [ebp-31h]
unsigned __int8 v6; // [esp+28h] [ebp-30h]
int v7; // [esp+29h] [ebp-2Fh]
int v8; // [esp+2Dh] [ebp-2Bh]
int v9; // [esp+31h] [ebp-27h]
int v10; // [esp+35h] [ebp-23h]
unsigned __int8 v11; // [esp+39h] [ebp-1Fh]
char v12[29]; // [esp+3Bh] [ebp-1Dh] BYREF
strcpy(v12, "Qsw3sj_lz4_Ujw@l");
printf("Please input:");
scanf("%s", &v2);
result = v2;
if ( v2 == 65 )
{
result = v3;
if ( v3 == 67 )
{
result = v4;
if ( v4 == 84 )
{
result = v5;
if ( v5 == 70 )
{
result = v6;
if ( v6 == 123 )
{
result = v11;
if ( v11 == 125 )
{
v1[0] = v7;
v1[1] = v8;
v1[2] = v9;
v1[3] = v10;
*(_DWORD *)&v12[17] = 0;
while ( *(int *)&v12[17] <= 15 )
{
if ( *((char *)v1 + *(_DWORD *)&v12[17]) > 64 && *((char *)v1 + *(_DWORD *)&v12[17]) <= 90 )
*((_BYTE *)v1 + *(_DWORD *)&v12[17]) = (*((char *)v1 + *(_DWORD *)&v12[17]) - 51) % 26 + 65;// A到O
if ( *((char *)v1 + *(_DWORD *)&v12[17]) > 96 && *((char *)v1 + *(_DWORD *)&v12[17]) <= 122 )
*((_BYTE *)v1 + *(_DWORD *)&v12[17]) = (*((char *)v1 + *(_DWORD *)&v12[17]) - 79) % 26 + 97;
++*(_DWORD *)&v12[17];
}
*(_DWORD *)&v12[17] = 0;
while ( *(int *)&v12[17] <= 15 )
{
result = (unsigned __int8)v12[*(_DWORD *)&v12[17]];
if ( *((_BYTE *)v1 + *(_DWORD *)&v12[17]) != (_BYTE)result )
return result;
++*(_DWORD *)&v12[17];
}
return printf("You are correct!");
}
}
}
}
}
}
return result;
}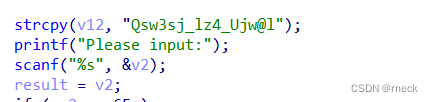
看到最前面的v12字符串,就知道大概是最后用来检验的key串,然后输入v2串

看到最前面把"字符串"v2给临时变量四个字节的result,不太合理
再看看上面的对于变量的定义,这实际上是将字符串存储到了以v2作为首地址开头的栈中
并且由高地址向着低地址存储(注意这是栈)
一直是存到了v11,数一数,一共是22个字节,因为上面那张图表示v11正好存储了“}”
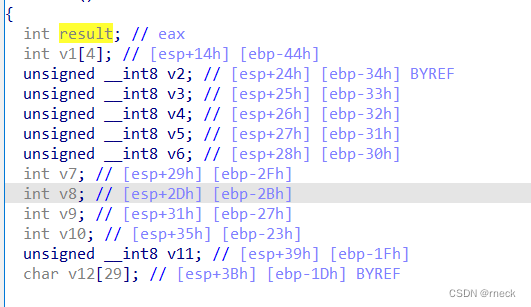
而且上面那几个连续的if都仅仅表示了括号外的东西,没用,仅仅作为标识、

下面直接看最核心的部分

重点来了,*(_DWORD *)&v12[17]表示取v12(最上面的定义的char类型的,占一个字节)的首地址然后强行转化为dd类型的指针,然后再以指针形式赋予这四个字节为一个整数0(也就是
int v12=0)
所有这里可以把*(_DWORD *)&v12[17]这一串东西看作就是一个临时变量,作为index
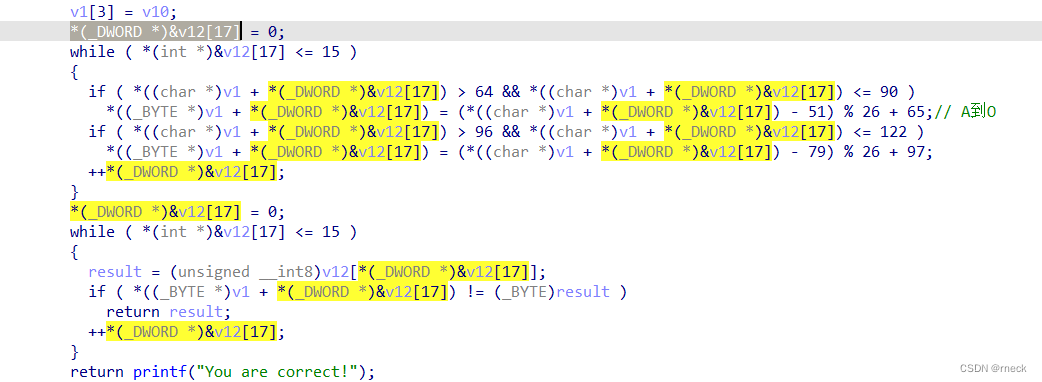
这里也不要看花眼了
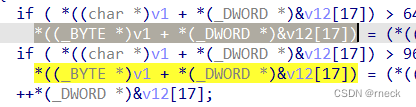
实际上是把int类型的v1并以它为首地址转化为byte类型,此时还是指针,然后指针加上我上述的index,最后才*然后变为一个实际值,实际上就是一个字符串数组
知道了这些以后,下面程序的操作就异常简单,也就是简单的针对大写字母与小写字母做了一个移位,分别是向后移位14位和向后移位18位
这道题的脚本有两种写法
第一种是逆向移位写出脚本
这里推荐用python,因为python是取模运算(C/java是取余运算),取模运算更方便负数情况的移位(你懂的)
下面就是类凯撒加密解密固定脚本
key="Qsw3sj_lz4_Ujw@l"
flag=""
for c in key:
if c>='a' and c<='z':
flag+=chr((ord(c)-18-97)%26+97)
elif c>='A' and c<='Z':
flag+=chr((ord(c)-14-65)%26+65)
else:
flag+=c
print(flag)
##原始数据加减移位值,-97或者是-65然后%26变为索引值,再加上97或者是65变为asiic码第二种是正向爆破(就是爆破原flag或者未中间值)
key="Qsw3sj_lz4_Ujw@l"
flag=""
for i in range(16):
if key[i]<='Z' and key[i]>='A':
for j in range(65,91,1):
if ord(key[i]) == (j-51)%26+65:
flag+=chr(j)
break
elif key[i]<='z' and key[i]>='a':
for j in range(97, 123, 1):
if ord(key[i]) == (j - 79) % 26 + 97:
flag += chr(j)
break
else:
flag+=key[i]
print(flag)得到flag{Cae3ar_th4_Gre@t}
easyre
有壳先脱壳,UPX壳
来到主函数

简单看一下,就是把flag的核心部分强制转化为byte类型然后asiic码值减一再花生为索引值再与v4逐个比较
写出脚本
key="*F'\"N,\"(I?+@"
flag=""
list=[]
data="~}|{zyxwvutsrqponmlkjihgfedcba`_^]\[ZYXWVUTSRQPONMLKJIHGFEDCBA@?>=<;:9876543210/.-,+*)('&%$# !\""
for i in range(12):
for j in range(len(data)):
if key[i]==data[j]:
list.append(j)
break;
for i in range(12):
flag += chr(list[i] + 1)
print(flag)flag{U9X_1S_W6@T?}
pyre(python逆向)
是一个pyc文件
拿到在线网站上去反编译
#!/usr/bin/env python
# visit https://tool.lu/pyc/ for more information
# Version: Python 2.7
print 'Welcome to Re World!'
print 'Your input1 is your flag~'
l = len(input1)
for i in range(l):
num = ((input1[i] + i) % 128 + 128) % 128
code += num
for i in range(l - 1):
code[i] = code[i] ^ code[i + 1]
print code
code = [
'%1f',
'%12',
'%1d',
'(',
'0',
'4',
'%01',
'%06',
'%14',
'4',
',',
'%1b',
'U',
'?',
'o',
'6',
'*',
':',
'%01',
'D',
';',
'%',
'%13']
写出脚本(正逆向,方便对比)
#!/usr/bin/env python
# visit https://tool.lu/pyc/ for more information
# Version: Python 2.7
input1="flag{Just_Re_1s_Ha66y!}"
code=[]
l = len(input1)
for i in range(l):
num = ((ord(input1[i]) + i) % 128 + 128) % 128
code.append(num)
print(code)
for i in range(l - 1):
code[i] = code[i] ^ code[i + 1]
code = [
'\x1f',
'\x12',
'\x1d',
'(',
'0',
'4',
'\x01',
'\x06',
'\x14',
'4',
',',
'\x1b',
'U',
'?',
'o',
'6',
'*',
':',
'\x01',
'D',
';',
'%',
'\x13']
for i in range(len(code)-2,-1,-1):
code[i]=chr(ord(code[i])^ord(code[i+1]))
print(code)
flag=""
for i in range(len(code)):
flag+=chr((ord(code[i])-i)%128)
print(flag)
flag{Just_Re_1s_Ha66y!}
刮开有奖
无壳打开IDA搜搜main函数搜不到然后搜索字符串查看敏感字符串来到下图
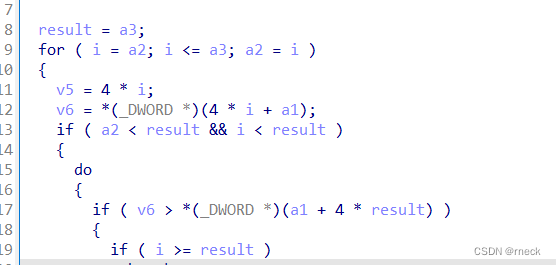
sub_4010F0可正向复盘
下面两个函数有base64有关的敏感字符串
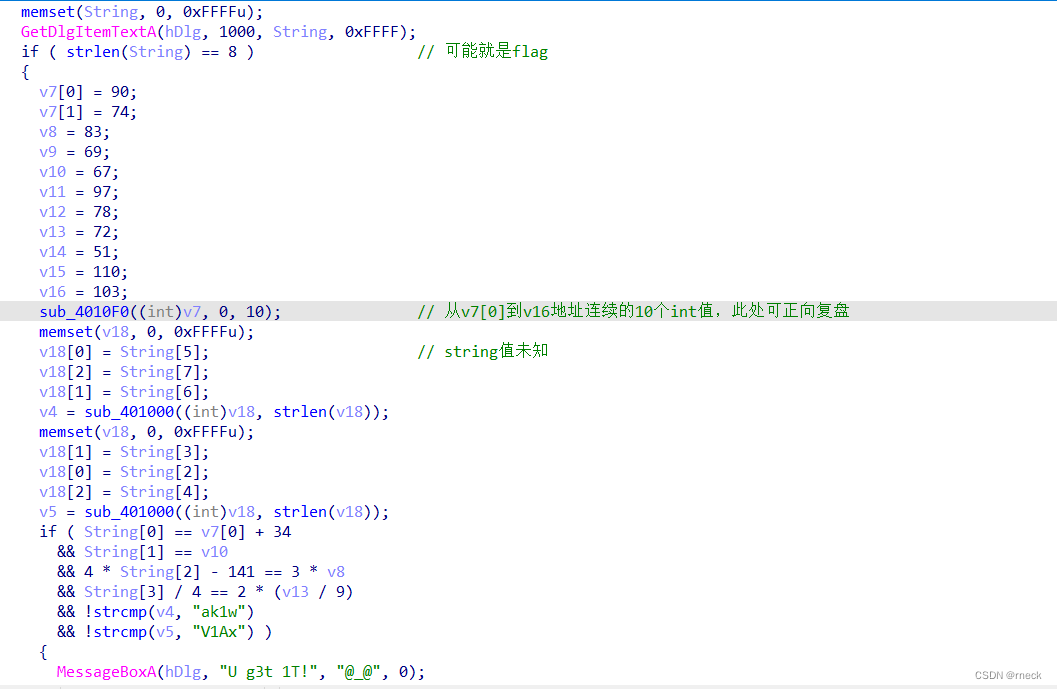
下面两个字符串拿去解码,然后正向复盘得到v7,v10
复盘代码:
#include <iostream>
using namespace std;
void sub_4010F0(char *a1, int a2, int a3)
{
int result; // eax
int i; // esi
int v5; // ecx
int v6; // edx
result = a3;
for ( i = a2; i <= a3; a2 = i )
{
v5 = i;
v6 = a1[i];
if ( a2 < result && i < result )
{
do
{
if ( v6 > a1[result] )
{
if ( i >= result )
break;
++i;
a1[v5] = a1[result];
if ( i >= result )
break;
while ( a1[i] <= v6 )
{
if ( ++i >= result )
goto LABEL_13;
}
if ( i >= result )
break;
v5 = i;
a1[result] = a1[i];
}
--result;
}
while ( i < result );
}
LABEL_13:
a1[result] = v6;
sub_4010F0(a1, a2, i - 1);
result = a3;
++i;
}
}
int main(){
char str[]="ZJSECaNH3ng";
sub_4010F0(str,0,10);
printf("%s\n",str);
return 0;
}
Q:原始IDA中的4*i为什么要变为i?
A:i可以当作是一个index,这些奇奇怪怪的玩意都是数组的变形
得到flag
flag{UJWP1jMp}