
“性能工程” (Performance engineering)是个日渐流行的概念。顾名思义“性能工程”是包含在系统开发生命周期中所应用的一个技术分支,其目的就是确保满足非功能性的性能需求,例如:性能、可靠性等。由于现代软件系统变得日益复杂,我们在对抗性能这个凸显的挑战的时候往往显得无措手足,或者照本宣科的尝试一些偏方,寄希望奇迹发生;要么无止境的升级一切资源,试图以海量的资源对抗不确定的技术需求。许多貌似强大的系统背后隐藏了太多的缺陷、资源浪费以及无效的努力。正如 Brendan Gergg 在《性能之巅》中写下的 “系统性能工程是一个充满挑战的领域…是主观的、复杂的、而且常常是多问题并存的”一样。
大约三年前,我曾经模仿 Marc Richards 的思路,尝试过 4 颗 vCPU EC2 实例在 JSON API 请求场景下的性能优化。时过境迁,当下主流 EC2 的硬件配置、操作系统、软件框架乃至编译器/JVM 等等都有了巨大的变化。那么,一个主流的 4 vCPU 的 EC2 实例在 JSON API 的 Benchmark 下极致的性能究竟能够达成怎样的结果?在开始测试之前,我预计响应处理的结果应该可以达到每秒百万以上,这个想法能够被证实吗?以下内容就是我的实验过程的一个记录。
背景
测试场景
TechEmPower 的 “Web Framework Benchmarks” 性能测试框架提供了许多 Web 应用程序框架的性能比较。这一次我选择了其中的“JSON 序列化”作为测试用例。这个测试框架涵盖的程序语言有 38 种之多,每种程序语言之下有包含了若干个框架,例如 Python 语言之下就有 43 种框架之多。显然我是没有精力办法实现如此之多的测试项目。只好依照自己的偏好以及熟悉程度选择了 6 种编程语言以及 12 个 Web 框架用来测试。测试的目的不仅仅是验证最好的性能表现,也希望能够看得出来各个语言、框架在不同优化方法下的差异。
测试中所用到的源码可以通过这个 GitHub 的项目获得:https://github.com/TechEmpower/FrameworkBenchmarks
不过为了满足 JSON 序列化的需要对部分程序进行了修改,以确保其运行的正确。对于这文章中涉及的 12 个框架的代码我有过仔细的研读,除了为保证正常运行之外的修改,尽量保持了原汁原味。如果需要再针对代码的细节进行分析、优化,显然不是这一篇文章能够承载的。同时,尽可能的将项目所用到的解释器、JVM、编译器以及依赖 Package 都升级为最新的版本。
JSON 序列化
至于这个“JSON 序列化” 解释起来非常简单。客户端向服务器 http://server:8080/json 发出请求,服务器端返回这样的结果:
{"message":"Hello, World!"}测试环境
测试环境完全构建于亚马逊云科技云计算的平台之下。
硬件环境
服务器:两种 4 vCPU 的 EC2 实例,分别是基于 Intel 第三代至强可扩展处理器(Ice Lake)的 c6in.xlarge 实例以及基于 Amazon Graviton2 处理器的 c6gn.xlarge。除了处理器不同以外,c6gn.xlarge 实例上的每个 vCPU 都是 Amzon Graviton 处理器的内核,即拥有 4 颗物理核心。与之不同,c6in.xlarge 实例只拥有 2 颗物理核心,通过 Hyper-Threading 技术表现为 4 颗 vCPU。另外一个值得一提的地方,在 Amazon EC2 的按需计划定价中,c6gn.xlarge 每小时的按需价格约为 c6in.xlarge 的 76%。
客户端:16 vCPU 实例,c6in.4xlarge 实例
网络:服务器和客户端 EC2 实例位于同一可用区的同一个集群置放群组(Placement groups)之下。
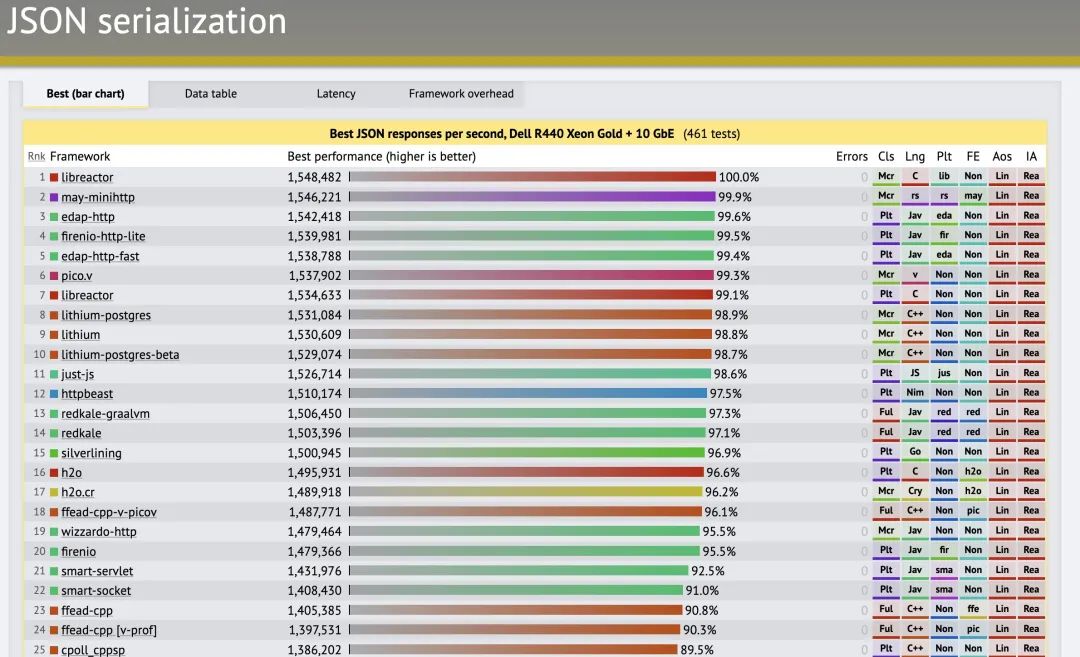
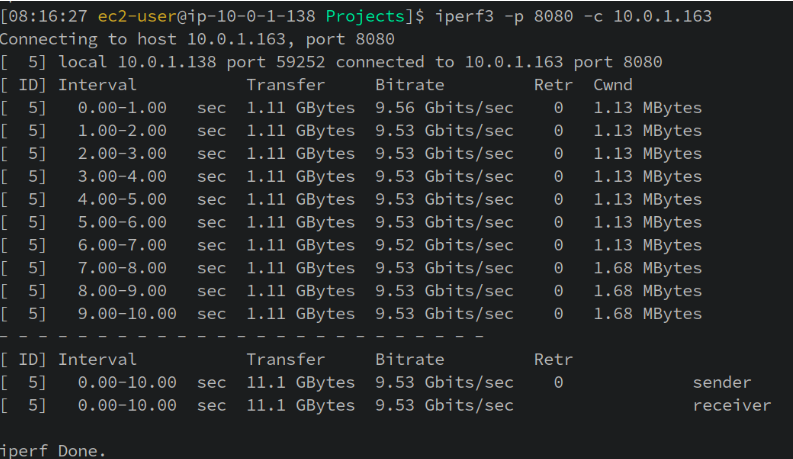
客户端在实例类型的选择上需要选择适合的规格。例如,规格较小的实例或许成为了测试的瓶颈,这就无法达到目标。服务器端的选择原则与此类似。实际测试中的服务器的网络开销峰值超过了 900 Mbit/s、490,000 pkts/s 这样的规模。在官网的介绍中,c6in.xlarge 提供了最高 30Gbps 的带宽,而 c6gn.xlarge 提供了 25Gbps 的带宽,这足以满足测试的要求了。在这个环境中,客户端-服务器的网络吞吐量使用 iperf3 得到的结果如下:
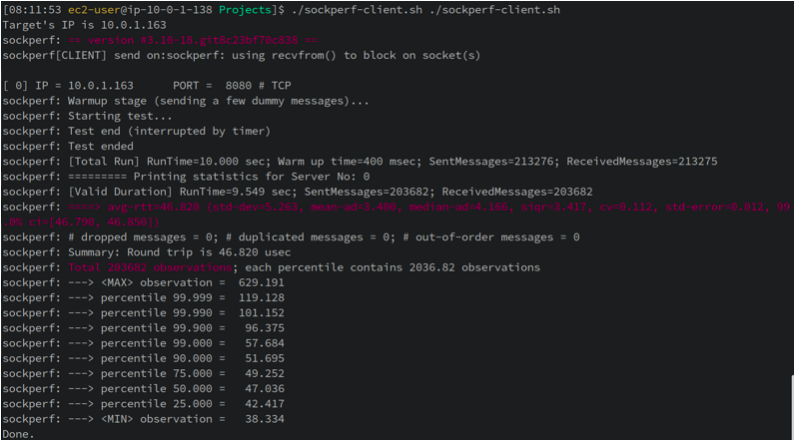
另外一个重要的技术指标,是网络的延迟。使用 sockperf 的测试结果如下(单位是微秒,μs):
软件环境
操作系统:Amazon Linux 2023 (内核:6.1.28-59.109)
Web 服务器:(对应链接请点击阅读原文查看)
C |
– nginx、libreator |
Rust |
– may-minihttp、hyper |
Go |
– silverlining、fasthttp、Gin |
Java |
– Netty |
JavaScript |
– Node.js |
Python |
– granian、uvicorn、fastapi |
客户端测试工具:采用流行的 HTTP 基准测试工具 wrk。用于对比分析的结果数据有两个,分别是每秒完成的请求处理的数量(Requests/sec)以及 90% 延迟的结果(单位为微秒,μs)。
客户端测试方法:每一轮测试分别在 c6in.4xlarge 与 c6gn.xlarge 两种实例上运行三次,取结果最好记录下来,避免 “吵闹的邻居”(Nosy Neighbours)等因素的影响。wrk 运行参数如下:
wrk -t ${threads} -c ${connections} -D ${warmup} -d ${duration} --latency --pin-cpus "http://${server_ip}:${port}/json" -H 'Host: benchmark_server' -H 'Accept: application/json,text/html;q=0.9,application/xhtml+xml;q=0.9,application/xml;q=0.8,*/*;q=0.7' -H 'Connection: keep-alive'左滑查看更多
thread |
– 线程数量,16 个线程(c6in.4xlarge 实例 每个 vCPU 一个线程) |
connections |
– 连接数,256 个连接 |
warmup |
– 预热的时间,2 秒 |
duration |
– 持续测试的时长,10 秒 |
server_ip |
– 目标服务器的 IP 地址,注意是 private IP 而不是 Public IP |
port |
– 端口号,设定为 8080,注意要在 Security Group 中开放测试端口 |
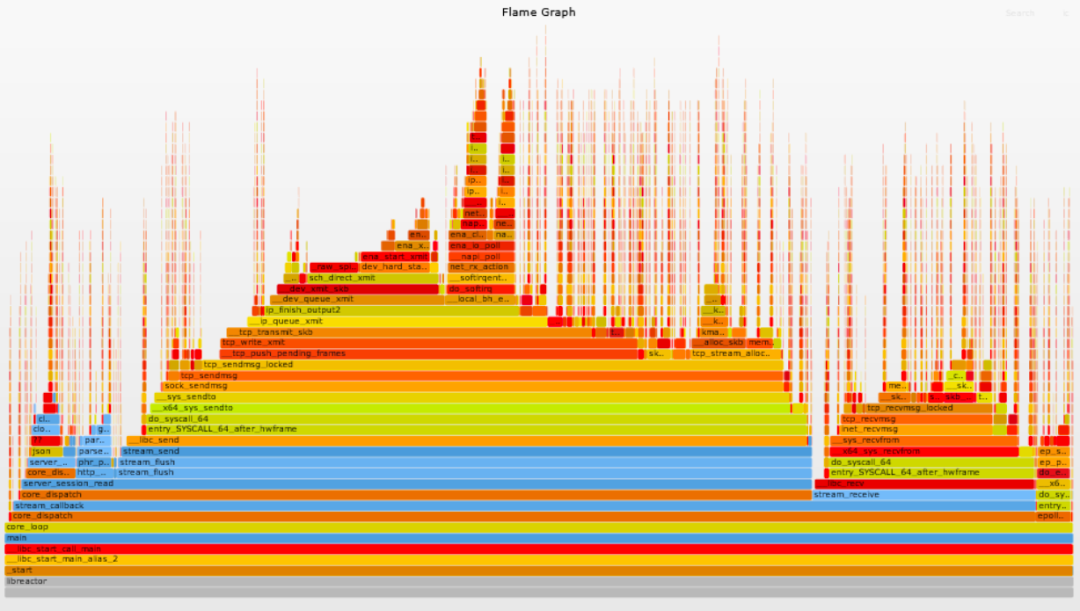
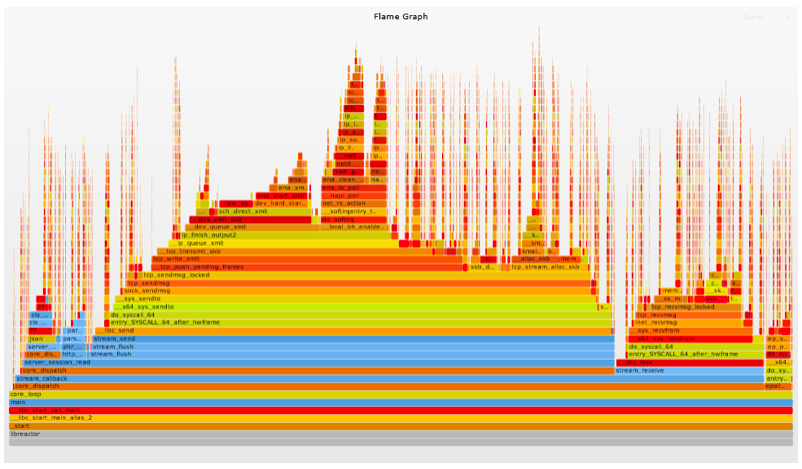
CPU 火焰图(Flame Graphs):火焰图是一个分层数据的可视化,用于可视化分析软件的堆栈跟踪,以便快速准确地识别最常见的代码路径。在这里我们使用火焰图,用来显示了正在消耗 CPU 周期的 libreator 应用的代码路径以及 CPU 的消耗量。
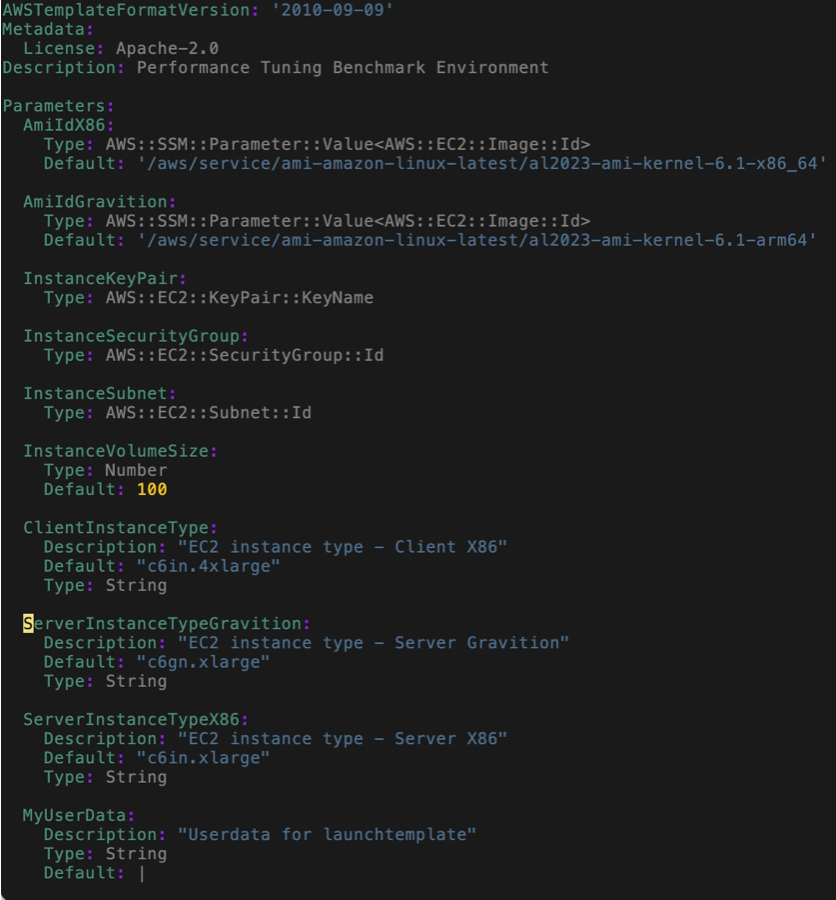
为了创建所需要的环境, 特准备了一个 CloudFormation 的脚本用来完成上述测试环境的准备。在 userdata 中仅安装所需的编译器、工具等软件而不对系统做任何修改。
性能基线
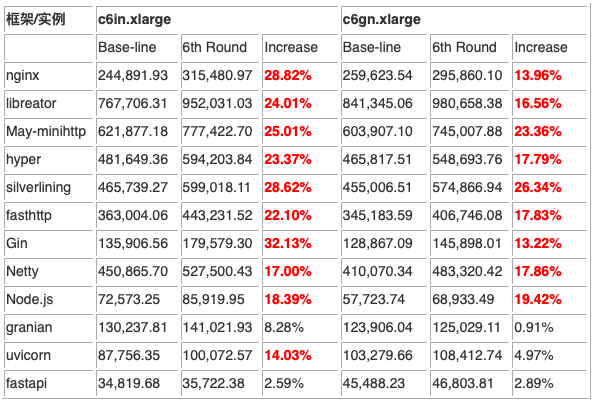
这里设定的性能基线特指在实例的在不改变任何参数的情况下运行 Web 服务器获得的测试结果。具体的测试数字见下表:
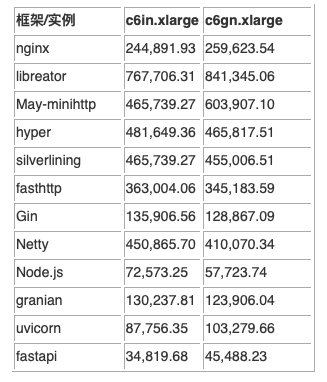
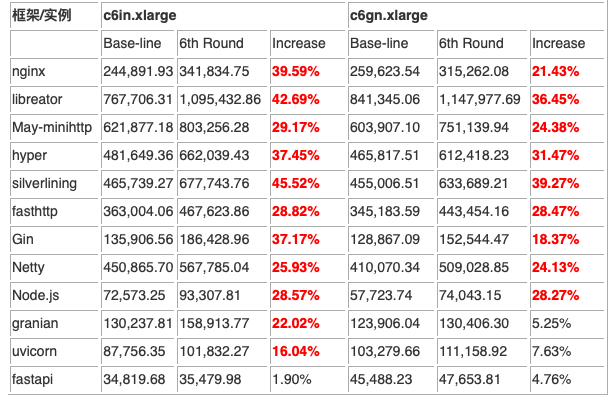
这一轮测试下来,成绩最好的当属 libreactor。分别在 c6in.xlarge 与 c6gn.xlarge 的环境下取得了 767,706.32 与 841,345.06 的成绩。对比起三年前我测试过的结果,这个数字有了巨大的提升。足以证明操作系统以及框架缺省的优化已经有了很大的提升。libreactor 表现出众的原因在于这是一个用 C 语言编写的事件驱动的 Web 框架。其特点就是为了追求高性能而普遍使了epoll、send 和 receive 等 Linux 网络原语。在这个 Web 服务的程序中 HTTP 解析由 picohttpparser 处理,libclo 负责 JSON 编码。Nginx 的版本是 1.25。这是自行编译优化的版本。为了支持 JSON 格式的输出编译配置了njs 模块。但是测试结果来看,Nginx+njs 的成绩并不显得突出。不出意外,May-minihttp 与 hyper 这两个基于 Rust 的框架表现良好。其中 May-minihttp 的成绩仅次于 libreactor。Rust 的版本为 1.71.1,编译的使用的优化参数为 RUSTFLAGS=”-Ctarget-cpu=native” cargo build –release。
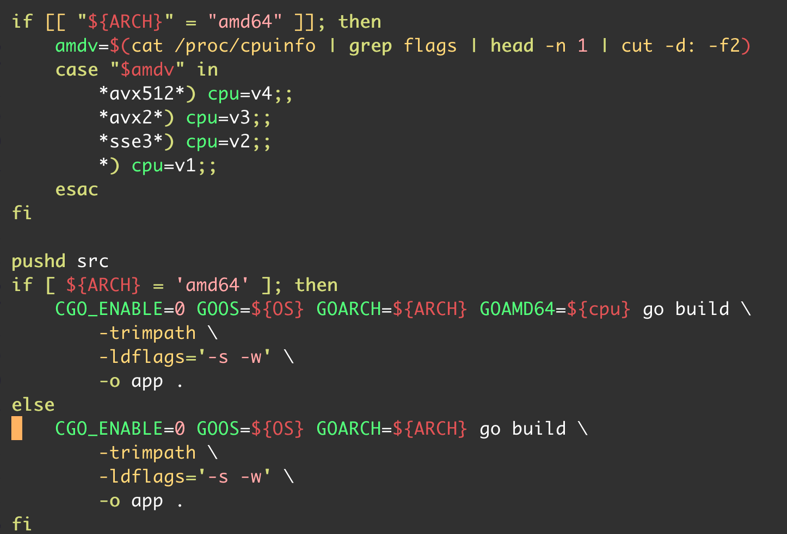
三款基于 Go 的框架表现出了较大的差异。其中成绩最好的 silverlining 与 fasthttp 的结果在意料之中。反倒是名气最大的 Gin 表现的不如人意。Go 的版本为 1.21.0, 编译的参数与方法如下:
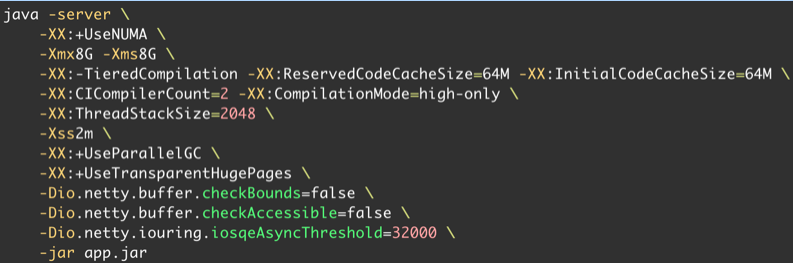
Netty 这款基于 Java 的 Web 框架的结果可以说是超出了我的预料,与 silverinling 在伯仲之间。在这里 JVM 选择的是 Amazon 出品的 Corretto-17.0.8.8.1。基于我的经验,Java 的启动参数做了如下设定:
至于 Node.js 与 Python 的一众框架的表现完全在意料之中,处于垫底的水平。略让我诧异的是 Granian 的成绩。毕竟其网络部分的实现是由 Rust 实现并通过 PyO3 与 Python 绑定。或许问题就出在是 Python 扩展模块与 Python 的交互上。在这里的 Python 指的是 CPython,版本是 3.11.2,而 Node 的版本则是 v18.17.1。至于各个框架的具体性能对比见下图:

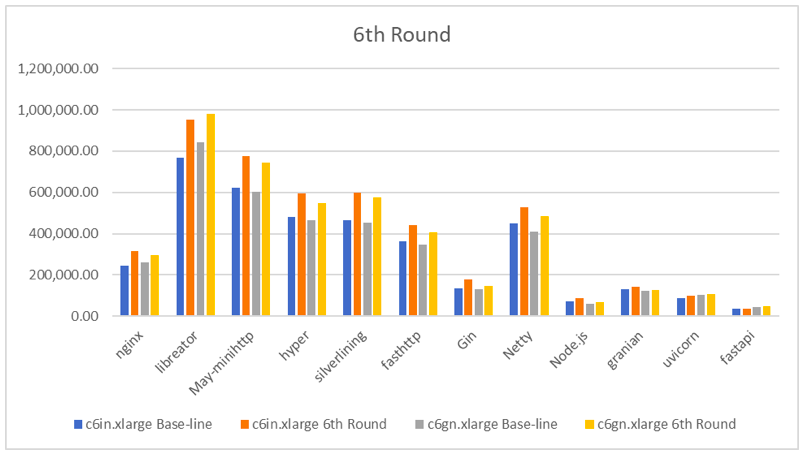
整体来看,现代的框架在多处理优化的方面已经较为完美了。并不需要做任何复杂的设置或者编码,都可以充分的利用全部的 vCPU。例如 Netty 与 uvicorn 在测试中使用 htop 观察到的效果,4 颗 vCPU 均处于满负荷的状态。很有意思的一点,Netty 的系统进程的比例远高于 uvicorn 。也许这也是 Netty 的性能好于 Python 框架的原因之一。

netty

uvicorn
为了与后续的优化步骤进行对比分析,附上 libreactor 在这一轮测试中的火焰图。这样更容易看出来优化带来的可视化的变化。
第一轮优化 :
Linux kernel 启动参数
优化思路
五年前 Spectre 和 Meltdown 这两个恶名昭著的安全漏洞被公之于众,随之而来的是一波又一波 CPU 安全漏洞的披露浪潮以及会带来极度影响性能的各种缓解措施。从最初的 Intel 处理器到后续的 AMD 处理器甚至 ARM 处理器无一幸免。如果我们执行 lscpu 命令就会看到各个处理器上的安全漏洞以及缓解状况,如下图:
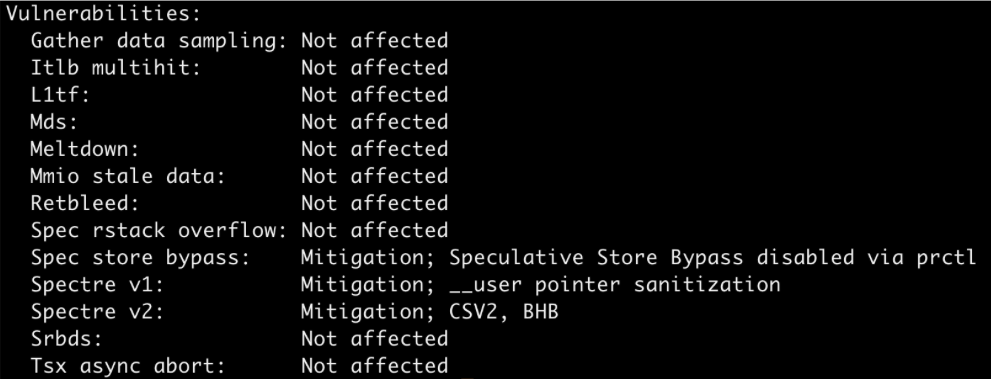
c6gn.xlarrge (Gravitation)
对于这一颗 Gravitation 2 的处理器目前仍存在着 Spec store bypass、Spectre v1、Spectre v2 这几个安全漏洞。
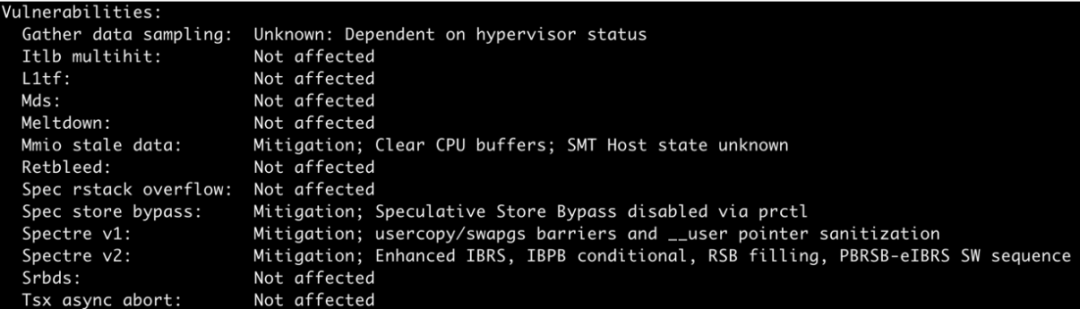
c6in.xlarge (Intel)
这一颗 Intel(R) Xeon(R) Platinum 8375C 处理器还存在 Mmio stale data、Spec store bypass、Spectre v1、Spectre v2 这样的安全漏洞。
于是一个关乎性能又充满争议的想法自然而生,在 Linux 内核中禁用缓解措施用以提升性能。撇开性能不谈,虽然这些缺陷的缓解措施是明智的且已成为默认设置,在大多数情况下应该不需要改变它们。当聚焦在在云计算的特定环境中,相信 EC2 的宿主机都已经进行了安全强化之下。在特定的条件下,尤其是在收益大于风险的情况下,我觉得即使是生产环境中这个关闭与否仍然存在思考的空间。你觉得呢?
优化具体的做法很简单,使用 grubby 在 Linux kernel 的启动参数中加入以下内容:
针对 x86 的处理器”processor.max_cstate=1 mitigations=off ipv6.disable=1 selinux=0″;而针对 ARM64 处理器则是”mitigations=off ipv6.disable=1 selinux=0″ 。
其中“mitigations=off” 用来关闭全部的缓解措施,当然也可以采用其它参数来单独关闭某一个特定的缓解措施。“processor.max_cstate=1” 可防止 CPU 进入更深的 C 状态(节能模式),用以保持性能。“ipv6.disable=1 selinux=0”用来关闭有可能影响性能的特性。需要说明一点,针对 x86_64 的 Amazon Linux 2023 中已经不再使用 intel_idle 驱动,而是改为 acpi_idle。关于这一点,可以通过这个命令加以验证:
cat /sys/devices/system/cpu/cpuidle/current_driver左滑查看更多
而在官方文档“您的 EC2 实例的处理器状态控制”仍然在介绍使用 intel_idel,但这个方法已经不再适用当前的操作系统(Amazon Linux 2023),需要留意。
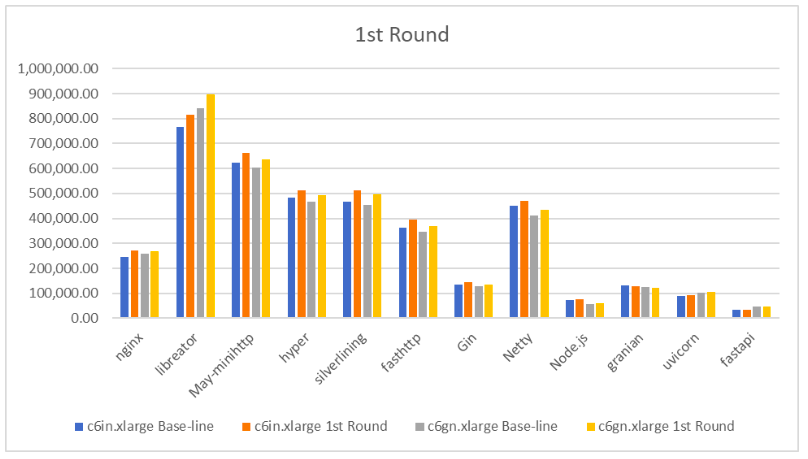
那么,第一轮结果表现如何?看下表:
官方文档链接:
https://docs.aws.amazon.com/zh_cn/AWSEC2/latest/UserGuide/processor_state_control.html
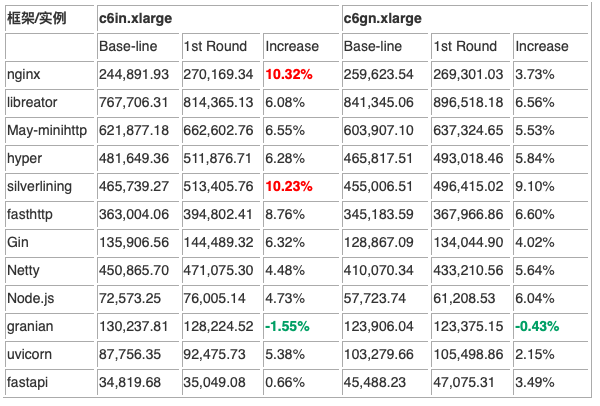
结果中有两个框架(nginx 与 silverlining)的性能提升超过了 10%。libreator 性能提升了超过 6%;May-minihttp 与 hyper 提升了 6% ~ 8%;siverlining 与 fasthttp 有 6% ~ 10% 提升;Gin 有 4% ~ 6% 提升;Netty 的提升~5%;Node.js 有 4% ~ 6% 提升;Python 的表现很复杂,Granian 有轻微的性能下降 -1.55% ~ -0.43%;uvicon 在 c6in.xlarge 有 5.38% 提升,但在 c6gn.xlarge 上仅有 2.15% 提升;fastapi 则与 uvicon 相反,在 c6gn.xlarge 表现更好。
第一轮 libreactor 的火焰图如下,仔细对比会发现细微的地方有所改善。
第二轮优化:
CPU 调度器
在 Linux 中,进程执行的最小单元称为线程,或者称作任务。系统调度器决定了哪个处理器运行线程,以及线程的运行时间。当前服务器端的缺省内置的调度器为 CFS(Completely Fair Scheduler)。正如其名字表达的那样,它的目标就是实现所谓的“完全公平”调度算法,将 CPU 资源均匀地分配给各线程。但是,因为调度器的主要关注是保持系统忙碌,因此可能无法为具体应用的实现最佳的性能。我们深究一下 CFS 的调度策略,可以看到主要的 3 种调度策略:
SCHED_OTHER:该调度策略用于普通任务,缺省的策略
SCHED_BATCH:抢占不像普通任务那样频繁,因此允许任务运行更长时间,更好地利用缓存,不过要以交互性为代价,很适合批处理工作场景
SCHED_FIFO:简单的调度算法,没有时间切分。优先级较高的线程抢占的运行中的线程,其优先级将保持在列表的首位
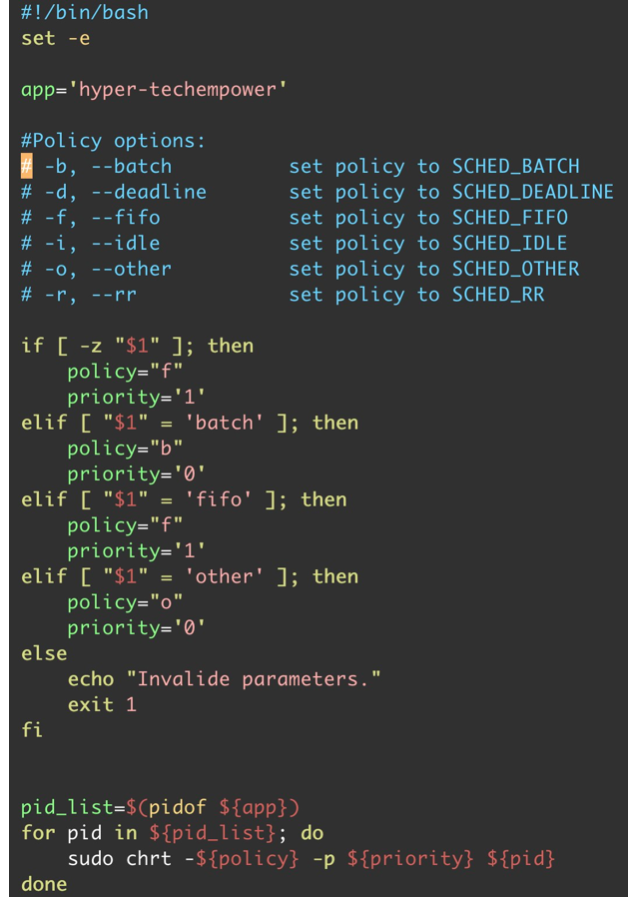
SCHED_OTHER 是 Amazon Linux 2023 中的默认调度策略。在 CFS 的调下,系统对使用缺省策略调度的所有线程进行公平处理器访问。当有大量线程或数据吞吐量是优先级时,此策略最有用,因为它可以更有效地调度线程。但是我的实验证明 SCHED_FIFO 在当前的测试场景中的性能表现最好。于是优化的思路可以简化为当 Web 服务器运行以后,使用 chrt 命令将缺省的 SCHED_OTHER 策略变更为 SCHED_FIFO。但是,Netty 与 Python 的框架的测试结果显示,其对这样的调度策略的变化并不敏感。我认为是 Python 解释器以及 JVM 的线程管理的特性所致。
多说几句感想,CFS 加入到 Linux Kernel 是 2007 年的事,距今已经是 16 年前了。过去的这十几年,CPU 调度器也出现了许多新的方案,例如:MuQSS、PDS、BMQ、BORE 等等。但这些新的调度器更多的关注于提升响应速度,通俗的解释就是“桌面”系统的调度器,而不是 CFS 的替代者。一个好的消息是就在 2023 年一个名为 Earliest Eligible Virtual Deadline First Scheduling(EEVDF)的全新的调度器出现了,并有望在 Kernel6.6 中正式取代 CFS。考虑到 EEVDF 的设计思想就是“当一个作业不断请求服务时,所获得的服务量始终在其有权获得的最大服务量范围内”,我们所测试的这个场景应该会有更好的性能表现。期待啊!
至于这一轮优化的的具体做法以 Hyper 框架为例,详见下图:
测试的结果如下:

从表中可以看到,共有五个框架的性能提升超过了 10%。libreactor 在 c6in.xlarge 上较基线性能提升了 10.42%,但在 c6gn.xlarge 上仅提升了 5.62%,这可以归结为在不同的 CPU 上调度策略差异所致。May-minihttp、hyper 较基线性能提升幅度在 6%~8% 之间。silverinling、fasthttp 与 Gin 较基线性能提升幅度在 4%~9% 之间。提升幅度最大的是 Node.js,较基线性能在 c6in.xlarge 上提升了 16.09%。

第 2 轮 libreactor 的火焰图如下,对比下来会发现较多的地方有所改善。

第三轮优化 :
网络驱动(ENA)
除了较为古老的 EC2 的实例(小于 m4.16xlarge 的 C4、D2 和 M4 实例),Amazon EC2 实例都是通过 Elastic Network Adapter(ENA)来提供增强联网功能。而这个 ENA 就是 Amazon 设计、实现的一种支持现代 CPU与系统架构的网络接口。ENA 的接口有许多特点,例如:
ENA 设备通过提供多个 Tx/Rx 队列对(最大数量由设备通过管理队列通告)、每个 Tx/Rx 队列对专用 MSI-X 中断向量、自适应中断来实现高速、低开销的网络流量处理节制和 CPU 缓存行优化的数据放置
ENA 驱动程序支持行业标准 TCP/IP offload 特性,例如校验和卸载。多核扩展支持接收端扩展(RSS)
ENA 驱动程序及其相应设备实现了健康监控机制(例如 watchdog),使设备和驱动程序能够以对应用程序透明的方式进行恢复以及调试日志
一些 ENA 设备支持一种称为低延迟队列(LLQ)的工作模式,这可以节省更多微秒的时间
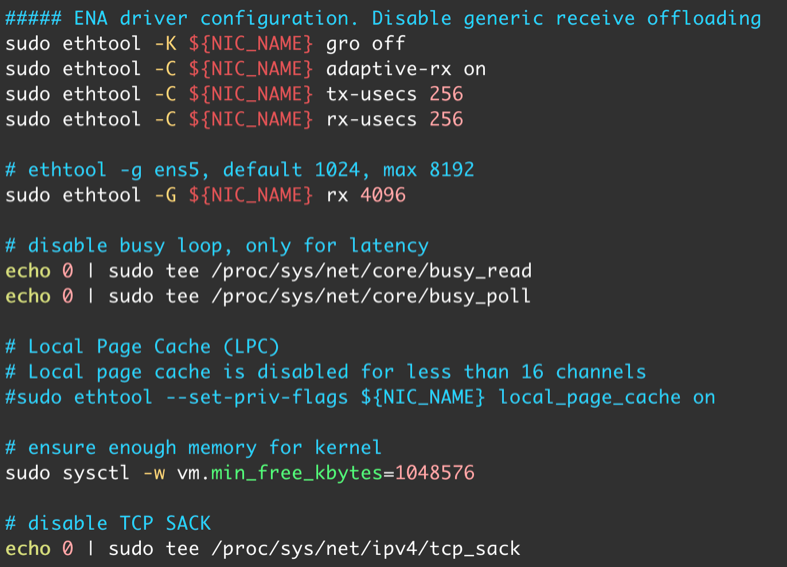
针对 ENA 进行优化的第一个步骤就是禁用通用接收卸载(GRO)。GRO 是一种网络功能,设计用于在内核级对传入数据包进行适时合并。重新组合后的数据段将作为单个数据块呈现给用户的应用。这样做的目的是为了在内核中更有效地进行重新组装,从而提高整体性能。一般来说,这是一个需要开启的设置,Amazon Linux 2023 默认开启了这一设置。不过,就我们的测试场景而言,我们已经知道所有请求和响应都可以在单个数据包内完成,因此没有必要进行重新组装。反而禁用 GRO 可以消除与用于检查是否需要重新组装的函数 dev_gro_receive 相关的开销。
此外,ENA 驱动和设备可在传统或自适应中断节制模式下运行。在传统模式下,驱动程序根据静态中断延迟值指示设备推迟发布中断。中断延迟值可通过 ethtool 命令进行配置。驱动程序支持以下 ethtool 参数 tx-usecs、rx-usecs 等等。在自适应中断节制模式(adaptive mode)下,中断延迟值由驱动程序动态更新,并根据流量性质在每个 NAPI 周期进行调整。默认情况下,rx-usecs 设置为 20,tx-usecs 设置为 64。这这里我们适当加大这个数值,例如 256。
Linux 内核有许多配置选项可能有助于减少网络延迟。其中启用“忙轮询模式”是较为常见的方法。忙轮询模式可减少网络接收路径上的延迟。启用忙轮询模式时,套接字层代码可以直接轮询网络设备的接收队列。繁忙轮询的缺点是,由于在紧密循环中轮询新数据,主机中的 CPU 使用率更高。有两种全局设置可以控制等待所有接口数据包的微秒数。这里面有两个关键的参数,busy_read 与 busy_poll。
busy_read – 套接字读取的低延迟繁忙轮询超时。这可以控制等待套接字层读取设备队列上的数据包的微秒数;busy_poll – 轮询和选择的低延迟繁忙轮询超时。这可以控制等待事件的微秒数。繁忙轮询的最大缺点是在紧密的循环中轮询新数据会带来额外的功耗和 CPU 开销。通常的最佳实践建议 net.core.busy_poll 的值介于 50μs 和 100μs 之间。但是实际测试下来,我发现启用忙轮询模式明显有助于于改善延迟,但对于处理请求的能力反倒有所影响。于是需要关闭忙轮询模式。
现在我们来进行优化设置,脚本的片段如下图:
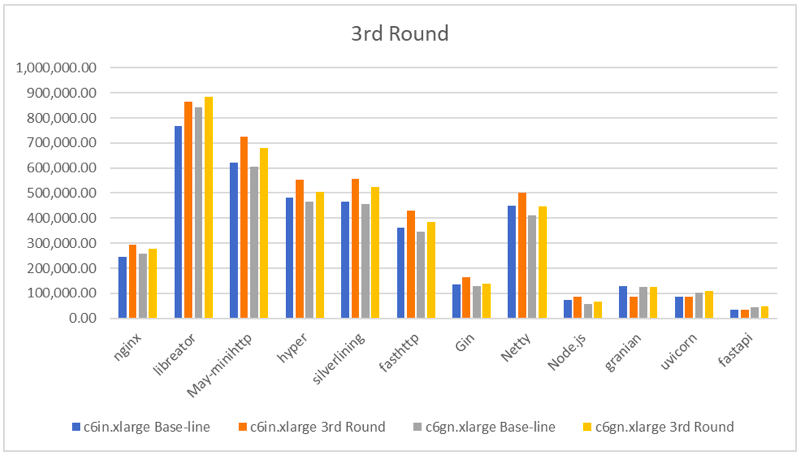
我们来看看这一轮的测试结果:

在这一轮,我们可以惊喜地看到共有 13 个结果的提升超过了10%!libreactor 在 c6in.xlarge 上较基线性能提升了 12.7%;在 c6gn.xlarge 上提升了 5.23%。May-minihttp、hyper 较基线性能提升幅度在 8.65% ~16.58% 之间。Silverinling、fasthttp、fasthttp 与 Gin 较基线性能提升幅度在 6% ~ 19% 之间。Netty 提升了 8.87%~11.49%;Node.js 较基线性能提升了 13% ~ 15.75%。不和谐的结果出在几个 Python 的框架上,granian 居然有了 32.51% 的性能衰退。其它框架的提升仅在 2% ~ 5% 之间。
第 3 轮 libreactor 的火焰图如下,是不是能够直观地看出来变化的幅度?
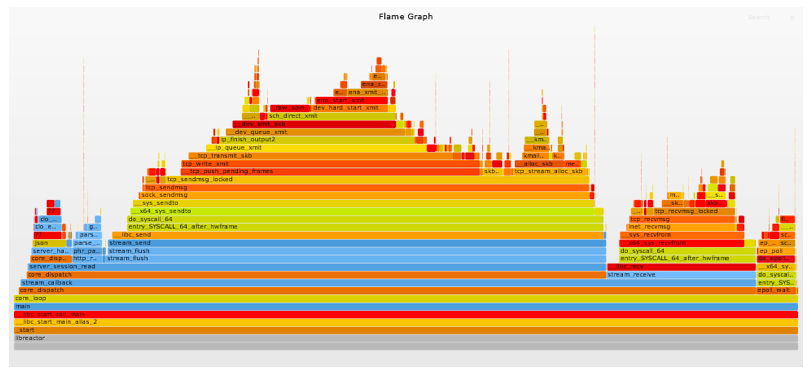
第四轮优化:
网络堆栈 RSS/XPS 的优化
Linux 操作系统一些网络性能增强功能。这一轮的优化就是利用这些功能,针对这个测试场景进行优化。这就涉及到了这样几个技术:
CPU 绑定
随着多队列/CPU 服务器的出现,出现了这样一种技术。每个网络队列与一个 CPU 配对,以便每个配对尽可能独立于其它配对运行。操作系统和应用程序都必须配置为确保一旦网络数据包到达任何给定队列,所有进一步的处理都由同一 vCPU/队列筒仓处理传入和传出数据。这种对数据包/数据局部性的关注通过维持 CPU 缓存热度、减少上下文/模式切换、最小化跨 CPU 通信以及消除锁争用来提高效率。
RSS:接收端缩放
这个 RSS 是在网络队列和 vCPU 之间为传入数据建立固定配对(传出数据必须单独处理)。接收端扩展是一种硬件辅助机制,用于以一致的方式跨多个接收队列分发网络数据包。好消息是 ENA 设备支持 RSS,并且默认情况下处于启用状态。哈希函数(Toeplitz)用于将固定哈希键(启动时自动生成)和连接的 src/dst/ip/port 转换为哈希值,然后组合该哈希的 7 个最低有效位使用 RSS 间接表来确定数据包将写入哪个接收队列。这就确保了来自给定连接的传入数据始终发送到同一个队列。例如在 c6in.xlarge 与 c6gn.xlarge 实例上,默认的 RSS 间接表将连接/数据分布在 4 个可用的接收队列中。需要注意的是,这个特性需要 ENA v2.2.11g 以后的版本。当前的 Amazon Linux 2023 ENA 的版本为 2.8.9g。
XPS:传输数据包引导
XPS 本质上是针对传出数据包执行的操作,就像 RSS 对传入数据包执行的操作一样;它允许我们通过确保当我们的应用程序准备好发送响应时使用相同的 vCPU/队列配对来维护这样的孤岛。具体方法是将 /sys/class/net/ens5/queues/tx-/xps_cpus(其中 n 为队列 ID)的值设置为包含相应 CPU 的十六进制位图。停用 irqbalance 与设置 IRQ affinity 的脚本片段见下图:
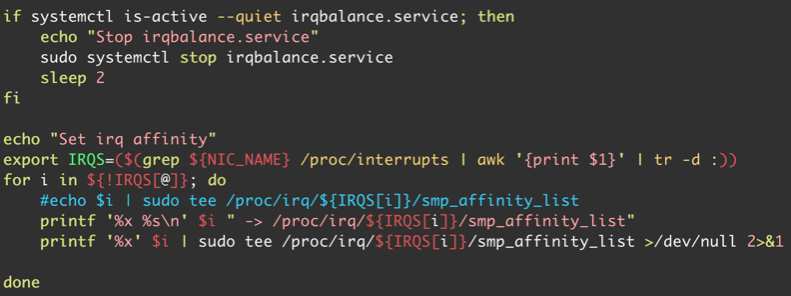
接下来就是设置 XPS,脚本片段如下:

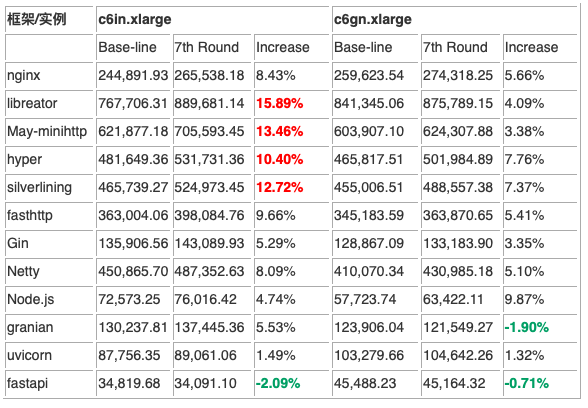
这一次的优化结果如何?见下表:
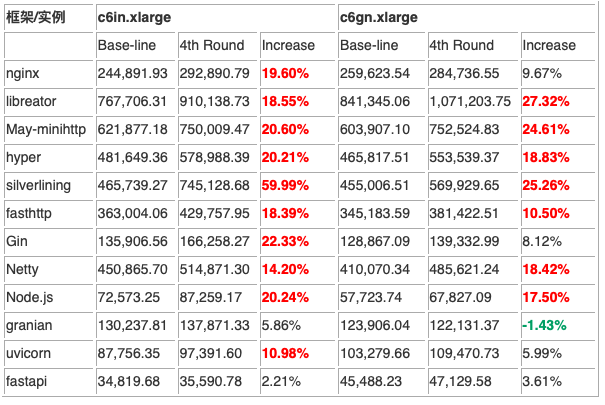
整体而言,这一轮的优化是大获成功的。共计 17 个测试项目的提升幅度超过了 10%。更有夸张的结果出现在 silverinling,升幅达到了 59.99%!出现负优化的结果出现在 granian 在 x6gn.xlarge 上,看来这种 Python 扩展的模式的遇到的问题还真是不少啊。就是在这一轮中,libreator 在 c6gn.xlarge 实例上跑出了 1,071,203.75 的结果,这也是第一次达成了 1 百万的测试目标。

这一轮 libreactor 的火焰图如下:

第五轮优化 :
Linux 内核参数的优化
Linux 核心对于应用性能的表现无疑是至关重要的。通常我们设定 Linux 核心参数有这样三种方法:
构建内核时—在内核的 config 文件中进行设置
启动内核时—使用命令行参数(通常通过引导加载程序),第一轮的优化使用的就是这个方法
系统运行时—通过/proc/sys/ 和/sys/来进行设置。直接对系统文件写入或者使用 sysctl 工具进行设置
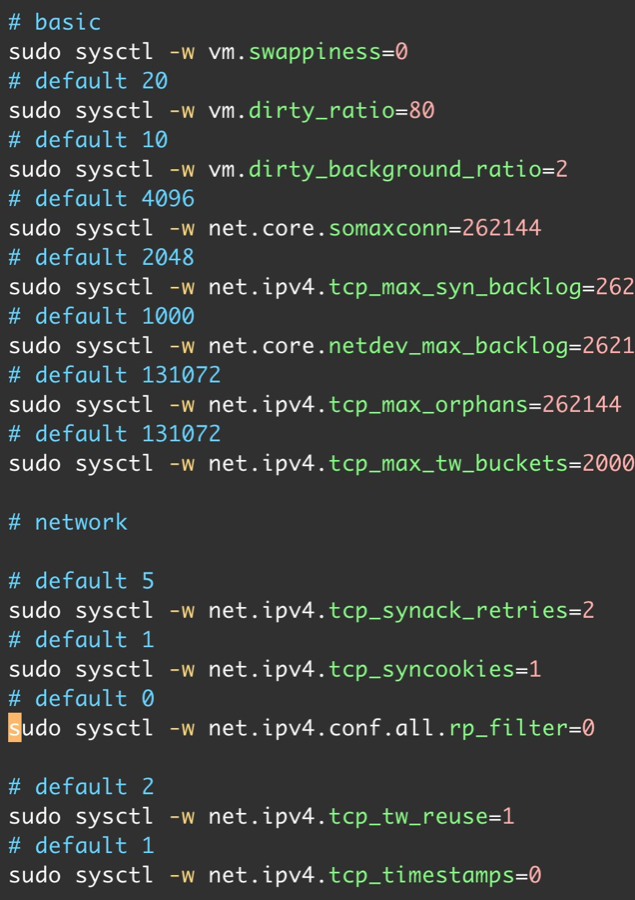
从以往的实践来看,我们已经总结出来许多经验,通过改变缺省的核心参数来提升应用的性能。这里主要列举一些我为了提升性能所采用的核心参数以及优化的参数加以说明。
关闭内存交换(Swappinessg),swappiness
Swappiness 是一个 Linux 内核属性,它设置了将页面从物理内存交换到交换空间以及从页面缓存中删除页面保持衡的参数。简单解释就是它基本上定义了系统使用交换空间的频率,但对性能会产生影响。于是通过 vm.swappiness=0 来关闭这个特性。
脏数据写入的最大内存上限,dirty_ratio
这个是系统的的一个阈值(以字节/可脏内存的百分比为单位),缺省值为 20。在低于该阈值的情况下,脏数据可以一直保存在内存中。超过这个值,就需要启动后台进程来清理。设定为 80 可以避免清理进程带来的性能开销。
调整挂起的连接处理,ipv4.tcp_max_syn_backlog
这个参数是用来设定待处理连接“等待确认”的最大队列长度,缺省值为 2048。为预防服务器在高峰时段出现过载需要调高这个数字,改为 262144。
增加接收队列的大小,core.netdev_max_backlog
接收到的帧从网卡上的环形缓冲区中取出后将存储在该队列中。系统的缺省设置为 1000,更改为 262144(256k)。
增加最大连接数,core.somaxconn
内核接受的连接数的上限。系统的缺省的设定为 4096, 更改为 262144(256k)。增加高速网卡的这个参数可能有助于防止丢失数据包。
设置内核参数的脚本片段见下图:
仅仅改变几个核心参数会对性能产生很大的影响吗?事实上,在测试结果出来之前我也有这样的顾虑。相比较而言,这一轮的优化的方法是最为简单的。结果是这样的:
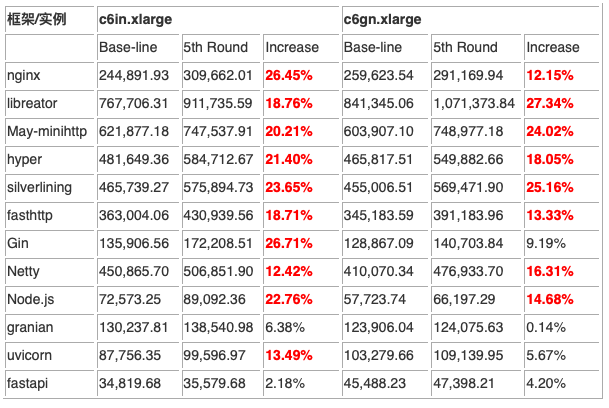
看似最简单的步骤却产生了最好的效果。在全部的测试结果中共有 18 个结果的提升超过了 10%,更有 9 个结果超过了 20%。与上一轮相似,libreator 在 c6gn.xlarge 实例上跑出了 1,071,373.84 的成绩,再一次超过了 1 百万的测试目标。
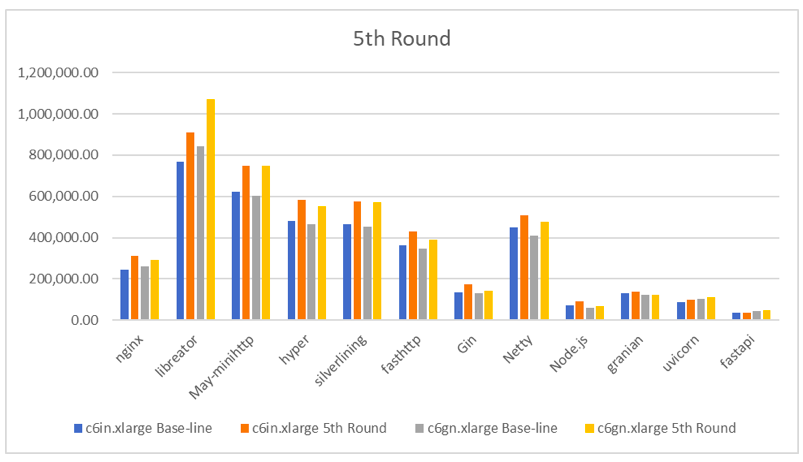
这一轮 libreactor 的火焰图如下:
第六轮优化 :
流量控制与拥塞算法的优化
流量控制(Traffic Control)是 Linux 内核提供的流量限速、整形和策略控制机制,它规定建立处理数据包的队列,并定义队列中的数据包的被发送的方式,从而实现对流量的控制。排队规则(queueing discipline,通常缩写为 qdisc)是 Linux 网络流量控制系统的核心,解释起来就是队列上面附加的排对规则。当流量控制系统(TC)处理网络包时,会将包入队到 qdisc 中,这些包会根据指定的规则被内核按照一定顺序取出。TC 中已经内置了很多不同的 qdisc,有些 qdisc 可以带参数,比如我们使用的 EC2 实例上面的 qdisc 参数是这样的:
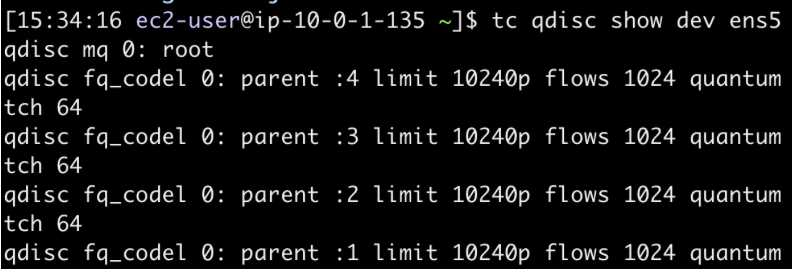
我们可以看到这里缺省的 qdisc 是 fq_codel。这个 fq_codel 又是什么意思呢?其实这是 The flow queue control delay(公平队列控制延迟)的缩写。从名字本身能够猜得出来,这是是将 Fair Queuing 与 CoDel AQM 方案相结合的队列规则。fq_codel 使用随机模型将传入数据包分类为不同的流,并为所有流提供公平的带宽份额。看到这里我们会不会有这样的想法,公平的策略能够带来极限的性能?是否有替代的 qdisc 呢?简短的回答是肯定的,可以用 noqueue 替换 fq_codel 作为默认 qdisc。为什么 noqueue 会有助于提升性能呢?这要看一下 noqueue 几个独特之处:无分类/无分类器;无调度器;无速率限制等等。这是不是有点无为而治的意思?在这个简单的测试环境中,这种无为而治的方式却能够减少不必要的网络开销从而提升性能。
我们再来看另外一个优化的方向,TCP 的拥塞算法。如我们所知,Linux 支持多种 TCP 拥塞控制算法。每个算法都采用略有不同的策略来优化网络中的数据流。考虑到 Linux 应用如此广泛,算法需要适配各种不同的网络环境,高速骨干网络、无线网络(WiFi、移动、卫星)等等。这就要求,算法会在检测到外部网络拥塞时尝试减慢速度,并在拥塞消失时加快速度。这对于性能变化很大的复杂的网络环境中尤其重要。于是大多数的 Linux 系统都会选择 CUBIC 作为系统缺省的 TCP 网络拥塞避免算法。与其它拥塞算法相比,在面对高延迟时,它可以更快、更可靠地在网络上实现高带宽连接,有助于优化长肥网络。与上面谈过的 qdisc 类似,在我们当前的环境中这不是最好的选择。这就引出了另一个拥塞算法 Reno。与 CUBIC 相比,Reno 要简单得多,许多其他算法只是在 Reno 之上提供附加功能。但是针对我们的这个测试环境,Reno 无疑会带来小幅但一致的性能提升。出于好奇心,我也尝试过大名鼎鼎的 BBR,但都比不上 Reno 的表现。这样简答的优化,会带来性能多大幅度的变化?
可以说仅以两条命令得到的提升真的是非常惊人的!超过 10% 性能提升的项目达到 19 个。更重要的一点,这个优化的方法对全部的 Web 框架的性能均有提升。可惜的是,没有一个测试结果超过百万这个心理预期。
这一轮 libreactor 的火焰图如下:
第七轮优化 :
优化的 Linux Kernel (cloudrock)
完成了 7 轮优化仅仅在第 4 轮与第 5 轮出现了超过 1 百万的成绩。这距离我的心里预期还是有一段距离。还有什么其它我忽略的优化的方法吗?
以下下是我尝试过但无明显效果的努力:
升级 GCC 版本(GCC 12、GCC 13)
透明大页内存(Transparent Huge Pages ,THP)的设置 always、never
停用系统调用审计(audit)
停用无关的系统服务 (atd、containerd、docker、rsyslog、postfix、crond、chronyd、amazon-ssm-agent、 libstoragemgmt、systemd-resolved.ser)
禁用 iptables/netfilter
网络堆栈 rfs/rps
…
难道优化的结果到此为止了吗?且慢,我还没有拿出那个压箱底的大杀器——亲手定制的 Linux Kernel。话说两年前,出于对于 Linux Kernel 的不满足,我开始研究 EC2 上的 Linux Kernel 的优化。这几年我一直在不断打磨这个优化、定制、剪裁过的 Linux kernel,我称其为 cloudrock。围绕着 cloudrock 逐渐优化形成了三个不同版本:
通用的 kernel – cloudrock
高性能的 kernel – cloudrock_performance
以及安全强化的 kernel -cloudrock_hardened
这一次我就先拿出来这个通用的 cloudrock kernel 来尝试一下。结果如下:
在相同的条件之下,没有对系统进行任何修改,共有 3 项测试的成绩提升超过了 10%,与基线性能测试的环境的差异仅在于替换了新的 Linux kernel。

与基线的性能对比,我们还是用直观的方法对比一下吧:
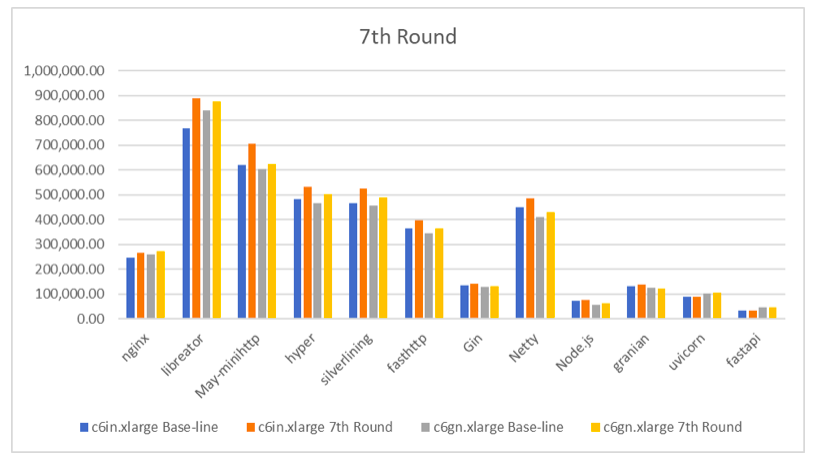
第八轮优化 :
优化的 Linux Kernel (cloudrock)
+全部优化措施
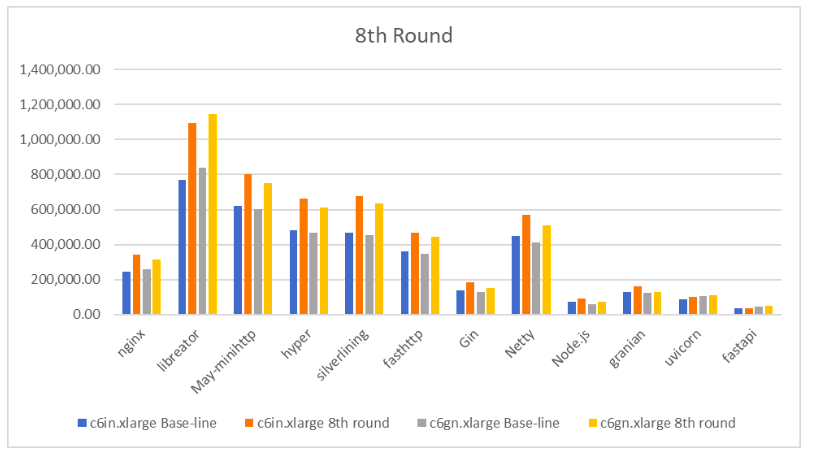
虽然由于使用了新的 Linux Kernel 使得性能有了大幅提升,但是还是没能达成突破百万的目标。那么一个新的念头油然而生,新的 Kernel 加上前六轮的各种优化组合起来会有什么样的效果?结果见下图:
直观的对比这个结果,我门可以在这张图中看到性能的巨大提升,最大升幅达到了 42%。libreator 在 c6in.xlarge 与 c6gn.xlarge 两种实例上均突破了百万的大关。不争气的只有 fastapi,以后不打算再用这个不争气的玩意。只是,这会是最终的定论吗?
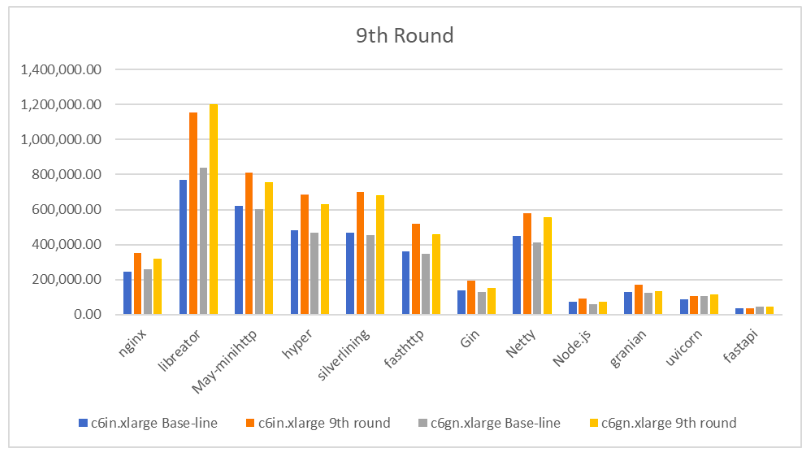
第九轮优化 :
高性能的 Linux Kernel (cloudrock-performance)+ 全部优化措施
还记得我们前面提到过一个高性能版本的定制 Linux kernel?我将这个版本的 Kernel 称为 cloudrock_performance。定制这个版本 Kernel 的初衷就是为了性能,可是 Kernel 性能的提升除了常规的优化之外,还能够来自哪里?答案是 Kernel 的安全特性。事实上我们所使用的各个版本的 Kernel 无一不是在性能、功能、安全这几个维度之间找到一个合适的平衡点。以 Amazon Linux 2023 最新的Kernel(6.1.49-70.116)为例,如果使用 kconfig-hardened-check 进行检查,你会发现通过检查的项目是 99 项,但 89 个项目没有通过安全检查,这就是现实。
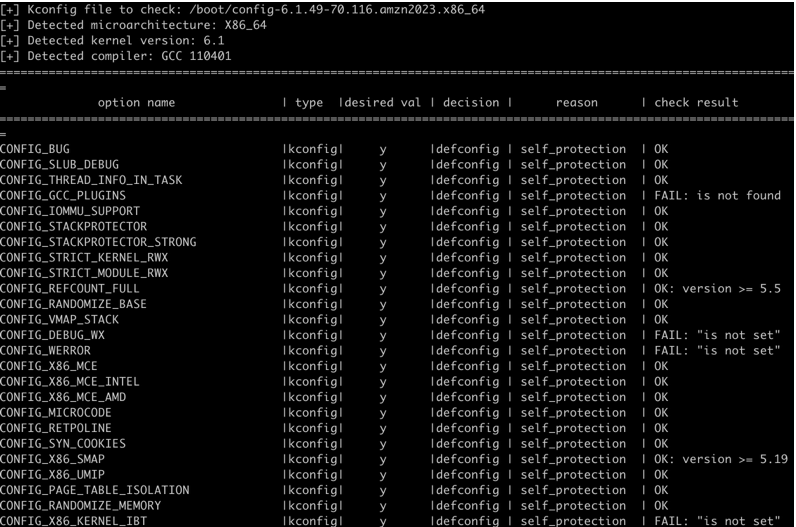
回到性能这个主线,我们追求极限的性能那就需要舍弃掉一些安全的特性。但是高性能≠不安全,保证一个 EC2 安全的方法多种多样,更何况安全的需求也不会是这有一种。那么说到底,成绩到底是多少呢?

总体而言,性能提升幅度最大的是 c6in.xlarge 实例上 libreator,达到了 50.16%;其次是 c6in.xlarge 与 c6gn.xlarge 实例上的 silverlining,分别是 50.77% 与 50.09%。性能指标最好的无疑是 libreator ,在 c6in.xlarge 与 c6gn.xlarge 实例上达成了 1,152,818.04 与 1,201,578.17 这样的成绩,可喜可贺!高兴之余,我们还可以继续分析这个结果:
最好的测试结果与最差的结果之间的差距有足足 33 倍之多!
以程序语言来看,性能由高到低的顺序是 C > Rust > Go >= Java > Python、js
但即使是同一种程序语言,表现最好的框架与最低的框架之间的性能差距有约 4.5 倍
从优化幅度而言,提升幅度最大的超过了 50%;同样的优化方法最低的提升幅度只有区区的 2.09%
从系统优化的体验来看,越接近操作系统的程序语言与框架与系统优化几乎是正相关;相反,高级语言与框架有其自己的调度策略与管理机制,呈现出系统优化的“钝感”
系统优化的方法几乎不存在1+1>=2 的效果。不同的优化方法存在着冲突的可能,甚者在极端的情况下表现出“负优化”的效果
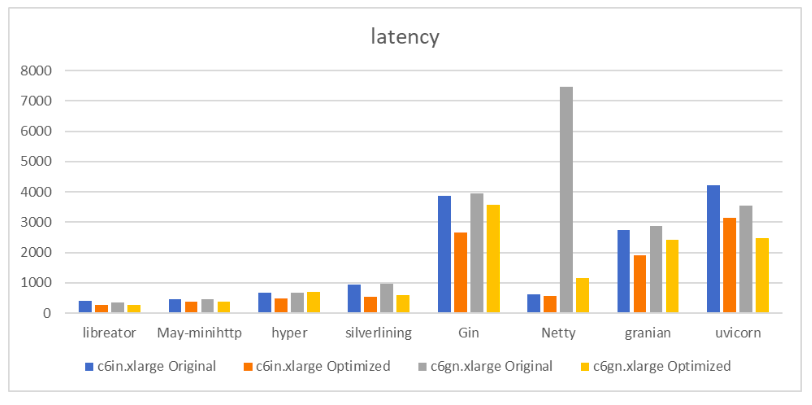
看到这里我们可以为这个实验画上句号了吗?如果你还记得开篇的内容,一定能想得起来我们测试获得的另外一组关键数据——延迟。不错,延迟也是一个关键的性能指标。但是就延迟测试的数据而言我注意到了一些异常值,出现在 Node.js、nginx、Gin、uvicorn、fasthttp 等框架上。此外,其它的几个框架在延迟上的表现也较前面提到的性能数字有许多的复杂、难以解释之处。也许这是接下来需要研究的一个全新的话题。
写到这里,我想总结一下这个完成这个测试的一点点心得:
系统优化不是解决性能问题的“银子弹”。与其事后的补救,提前引入“性能工程”的思想,是更有效的方法。事前的选择往往比事后的努力更重要,切记!
性能优化并不是玄学,凡事有果必有因。优化需要建立在扎实的基础知识以及丰富的经验之上。
考虑到日趋复杂的技术发展趋势,“性能工程”将是未来的一个重要的方向
一代处理器的性能提升或许只有 15%,但系统优化可以将性能提升 50% 以上。难道这不就是最朴素的降本增效的不二法门吗?
与 X86 架构相比,ARM64 架构的优化远远没有尽如人意。在操作系统、驱动、编译器、框架等许多领域仍需完善。
EC2 一个特殊的软件运行环境。需要针对性的优化而不是仅仅套用旧有的经验,时代变了!
正如 Brenda Gregg 在《BPF 之巅 – 洞悉 Linux 系统和应用性能》中写过的那一句话,“系统中的盲点是性能瓶颈和软件 Bug 的藏身之处”。就就意味着,无轮是应用程序开发人员、SRE 工程师、DBA、性能工程师、架构师、安全工程师、运维工程师都需要成为“系统性能”这个挑战且充满乐趣的领域的弄潮儿。在云计算的时代,让我们一起步入“性能工程”的技术之旅!
能力有限,斗胆献丑于前。系统优化之路远无止境,还需与各位同好探讨、精进。如有任何建议或批评指正,还望不理赐教。我的邮箱是 [email protected],谢谢。
参考资料
Red Hat Enterprise Linux 9 “Monitoring and managing system status and performance”
Marc Richards,Extreme HTTP Performance Tuning: 1.2M API req/s on a 4 vCPU EC2 Instance
ENA Linux Driver Best Practices and Performance Optimization Guide
Brendan Gregg’s blog
Amazon EC2 User Guide for Linux Instances
https://github.com/TechEmpower/FrameworkBenchmarks
Scaling in the Linux Networking Stack
Amazon re:Invent 2014 | (PFC306) Performance Tuning Amazon EC2 Instances
Amazon re:Invent 2018: Amazon EC2 Instances & Performance Optimization Best Practices
本篇作者

费良宏
费良宏,亚马逊云科技首席开发者布道师。在过去的 20 多年一直从事软件架构、程序开发以及技术推广等领域的工作。他经常在各类技术会议上发表演讲进行分享,他还是多个技术社区的热心参与者。他擅长 Web 领域应用、移动应用以及机器学习等的开发,也从事过多个大型软件项目的设计、开发与项目管理。目前他专注与云计算以及互联网等技术领域,致力于帮助中国的开发者构建基于云计算的新一代的互联网应用。

星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」

听说,点完下面4个按钮
就不会碰到bug了!
