说明:飞书是在线文档平台,本文介绍如何使用Python程序批量将飞书文档转为MD文档,并下载到本地;
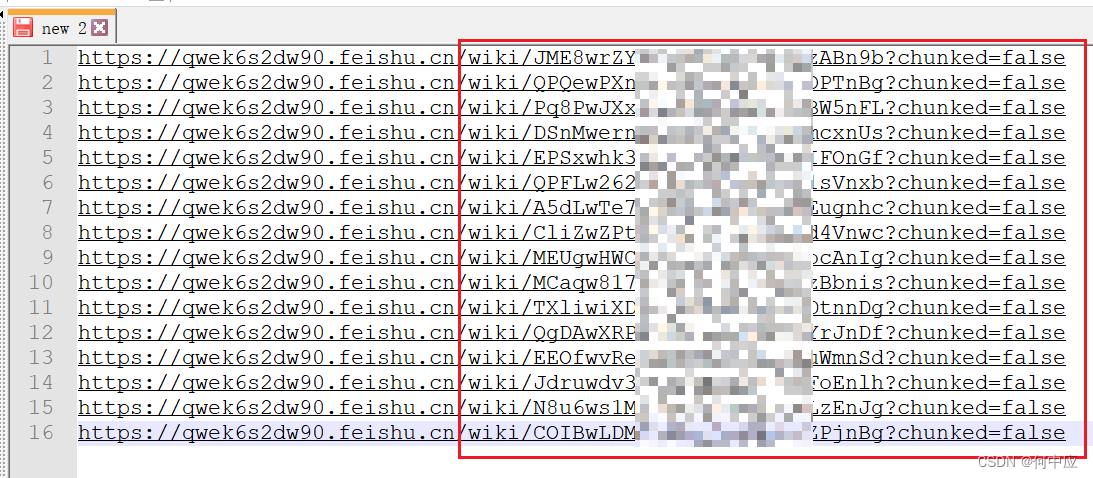
复制地址
首先,把文档的URL都复制下来,这个需要一个一个点,并复制拷贝,但却是工作量最大的一步;

如下:
转换
飞书转为Markdown,在GitHub上有一个工具,可以在线将飞书的文档转为Markdown,并生成一个压缩包(.zip)到本地。
该工具,提供了一个在线版;
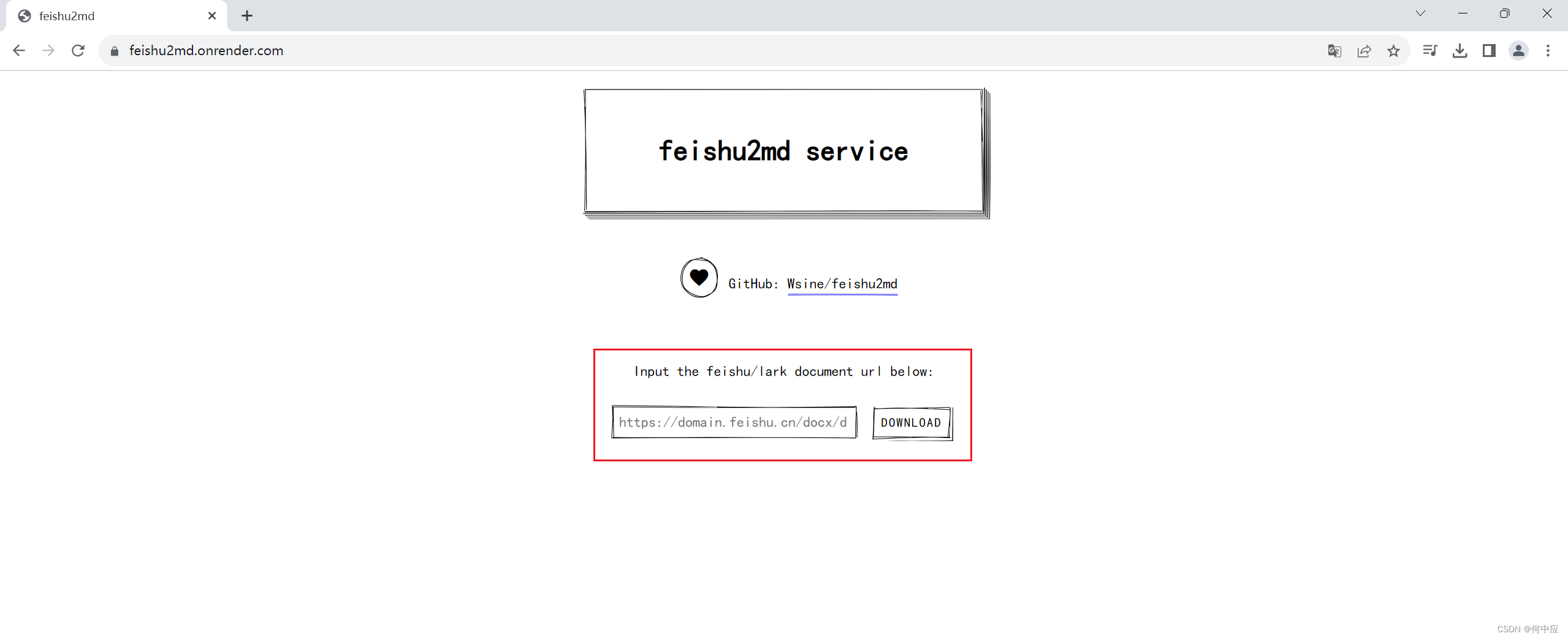
把前面飞书中的文档地址拷贝到这里,点DOWNLOAD就可以了。
分析
我们可以通过Python程序,将需要转为MarkDown的飞书文档,使用Python程序循环去访问这个地址就好了。
首先,分析前面转换攻击,点击DOWNLOAD后发送的请求链接,如下:

通过分析,可知,地址的格式是这样的;
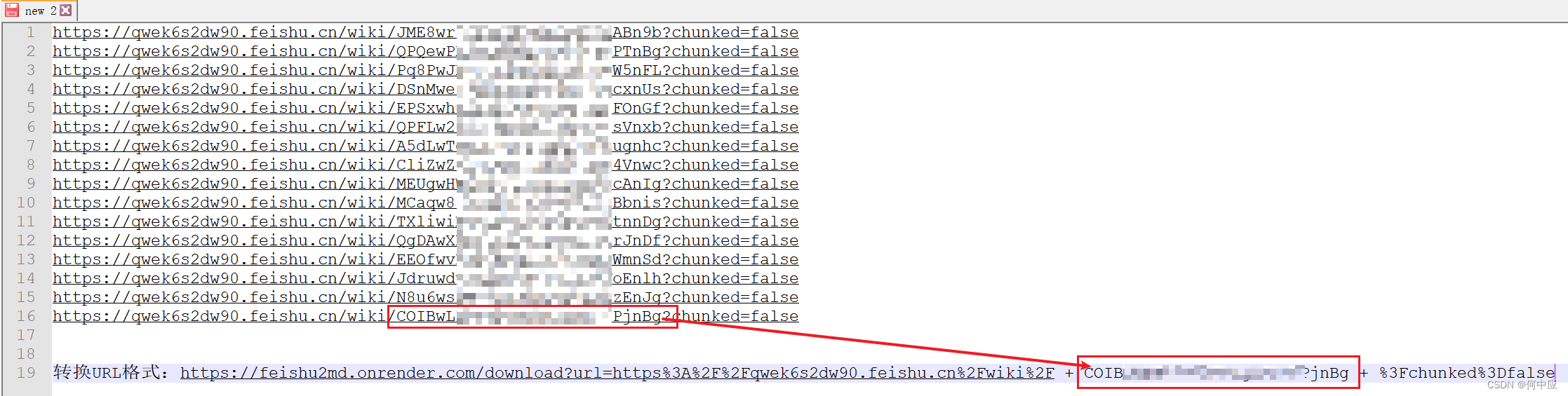
格式:
https://feishu2md.onrender.com/download?url=https%3A%2F%2Fqwek6s2dw90.feishu.cn%2Fwiki%2F + 文档地址码 + %3Fchunked%3Dfalse
编码
这就好办了,开始编码,如下:
import requests
# 飞书中的文档地址码
doc_list = [
"XXXXXXXXXXXXXXXXXXBn9b",
"XXXXXXXXXXXXXXXXXXTnBg",
"XXXXXXXXXXXXXXXXXX5nFL",
"XXXXXXXXXXXXXXXXXXxnUs",
"XXXXXXXXXXXXXXXXXXOnGf",
"XXXXXXXXXXXXXXXXXXVnxb",
"XXXXXXXXXXXXXXXXXXgnhc",
"XXXXXXXXXXXXXXXXXXVnwc",
"XXXXXXXXXXXXXXXXXXAnIg",
"XXXXXXXXXXXXXXXXXXbnis",
"XXXXXXXXXXXXXXXXXXnnDg",
"XXXXXXXXXXXXXXXXXXJnDf",
"XXXXXXXXXXXXXXXXXXmnSd",
"XXXXXXXXXXXXXXXXXXEnlh",
"XXXXXXXXXXXXXXXXXXEnJg",
"XXXXXXXXXXXXXXXXXXjnBg",
]
# 遍历文档并转换
for index, value in enumerate(doc_list):
# 拼接URL
url = (
"https://feishu2md.onrender.com/download?url=https%3A%2F%2Fqwek6s2dw90.feishu.cn%2Fwiki%2F"
+ value
+ "%3Fchunked%3Dfalse"
)
# 发送请求
response = requests.get(url, stream=True)
# 写入到本地
if response.status_code == 200:
with open(r'C:\Users\10765\Desktop\markdown'+ '\\' + str(index) + ".zip", "wb") as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
print("文件下载完成!")
else:
print("文件下载失败,状态码:", response.status_code)
设置路径为桌面,文件名为索引,启动程序,测试,下载速度取决于飞鸽文档的大小,我这十几个文档,十分钟左右都下载完成了;
压缩包中包含文档和静态资源(图片);
这样,批量将飞书文档转为MD文档的步骤就完成了;