By是selenium中定位元素的一个类,在使用之前需要引入
from selenium.webdriver.common.by import By
下面是定位元素8个不同的方式
| 策略 | 语法 | 描述 |
|---|---|---|
| By id | driver.find_element(By.ID,’id’) driver.find_element_by_id(‘id’) |
通过id属性定位元素 |
| By name | driver.find_element(By.NAME,’name’) driver.find_element_by_name(’name’) |
通过name属性定位元素 |
| By class name | driver.find_element(By.CLASS_NAME,’class’) driver.find_element_by_class_name(‘class’) |
通过class属性定位元素 |
| By tag name | driver.find_element(By.TAG_NAME,'tag_name’) driver.find_element_by_tag_name(‘tag_name’) |
通过HTML标签名定位元素 |
| By link text | driver.find_element(By.LINK_TEXT,‘link_text’) driver.find_element_by_link_text(‘link_text’) |
通过链接内容定位元素 |
| By partial link text | driver.find_element(By.PARTIAL_LINK_TEXT,‘partial_link_text’) driver.find_element_by_partial_link_text(‘partial_link_text’) |
通过部分链接内容定位元素 |
| By css | driver.find_element(By.CSS_SELECTOR,‘css’) driver.find_element_by_css_selector(‘css’) |
通过css选择器定位元素 |
| By xpath | driver.find_element(By.XPATH,‘xpath’) driver.find_element_by_xpath(‘xpath’) |
通过xpath定位元素 |
**注意:**上述的语法在定位元素时,如果定位语句不唯一,能够查到多个函数的话,默认值返回页面中出现的第一个。
也就是说定位不唯一,那得到的元素可能就不是你想要的。
要想返回所有匹配元素的集合,需要在find_element后面加上s,以id定位的语句为例:
driver.find_elements(By.ID,'id')
driver.find_elements_by_id('id')
以百度搜索的输入框为例:
<input type="text" class="s_ipt" name="wd" id="kw" maxlength="100" autocomplete="off”></input>
通过id定位:
console:(用于调试)
document.getElementById("kw")
Selenium:
driver.find_element(By.ID,'kw')
driver.find_element_by_id('kw')
通过name定位:
console:
document.getElementsByName("wd")
Selenium:
driver.find_element(By.NAME,'wd')
driver.find_element_by_name('wd')
通过class定位:
console:
document.getElementsByClassName("s_ipt")
Selenium:
driver.find_element(By.CLASS_NAME,'s_ipt')
driver.find_element_by_class_name('s_ipt')
通过标签名定位:
console:
document.getElementsByTagName("input")
Selenium:
driver.find_element(By.TAG_NAME,'input')
driver.find_element_by_tag_name('input')
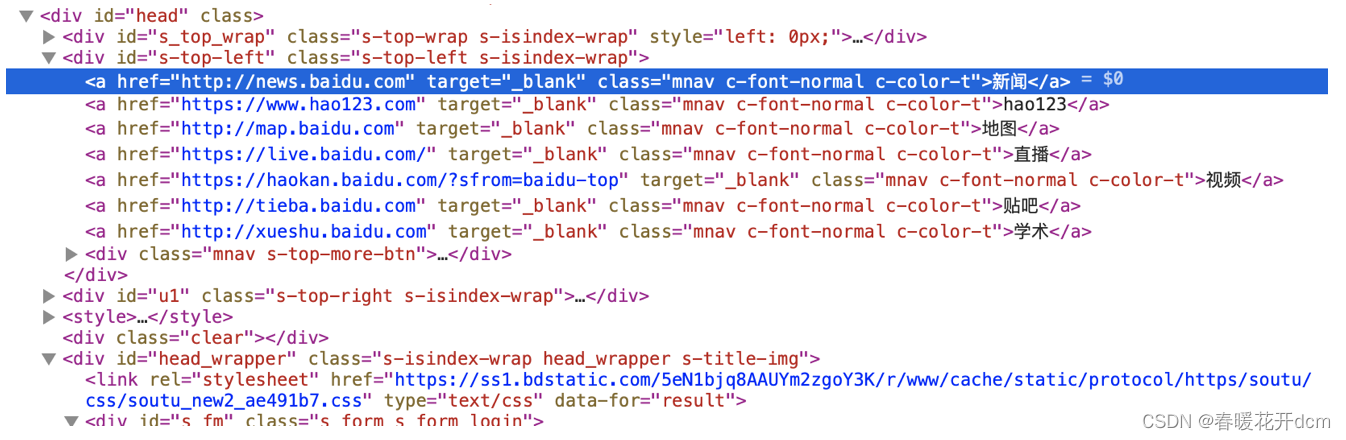
通过链接内容定位:
driver.find_element(By.LINK_TEXT,'新闻')
driver.find_element_by_link_text('新闻')
**注意:**这种方法是全匹配,如果前后有空格,都是需要匹配的
通过部分链接内容定位:
driver.find_element(By.PARTIAL_LINK_TEXT,'123')
driver.find_element_by_partial_link_text('123')
**注意:**通过链接内容进行识别的这两种方法,只对<a>标签有用
通过XPath定位:
如果没有适合要查找的元素的id或name属性,则始终建议使用XPath属性。
什么是XPath
xpath 是XML Path的简称, 由于HTML文档本身就是一个标准的XML页面,所以我们可以使用Xpath 的用法来定位页面元素。
XPath特点:
XML和HTML类似,也是⼀种多层标签嵌套形式的路径语⾔,XPath就是⼀种路径选择表达式。
它还提供了超过 100 个内建函数,⽤于字符串、数值、时间的匹配以及 节点、序列的处理等,⼏乎所有想要定位的节点都可以⽤ XPath 来选 择。
XPath定位的缺点
xpath 这种定位方式, webdriver会将整个页面的所有元素进行扫描以定位我们所需要的元素, 这是个非常费时的操作, 如果脚本中大量使用xpath做元素定位的话, 脚本的执行速度可能会稍慢
XPath常用规则:
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点 |
| / | 从当前节点选取直接子节点,绝对路径,从根节点进行解析 |
| // | 从当前节点选取子孙节点,相对路径,从任何元素节点开始解析 |
| . | 选取当前节点 |
| … | 选取当前节点的父节点 |
| @ | 选取属性 |
XPath表达式形式:
这⾥列出了 XPath 的常⽤匹配规则,示例如下:
//title[@lang='eng']
以上就是⼀个 XPath 规则,代表的是选择所有标签名称为 title,同时属性 lang 的值为 eng 的节点
举例:(以百度搜索框为例)
XPath的一个获取方式:
打开浏览器调试工具,点击想要获取的元素,右键->拷贝->XPath
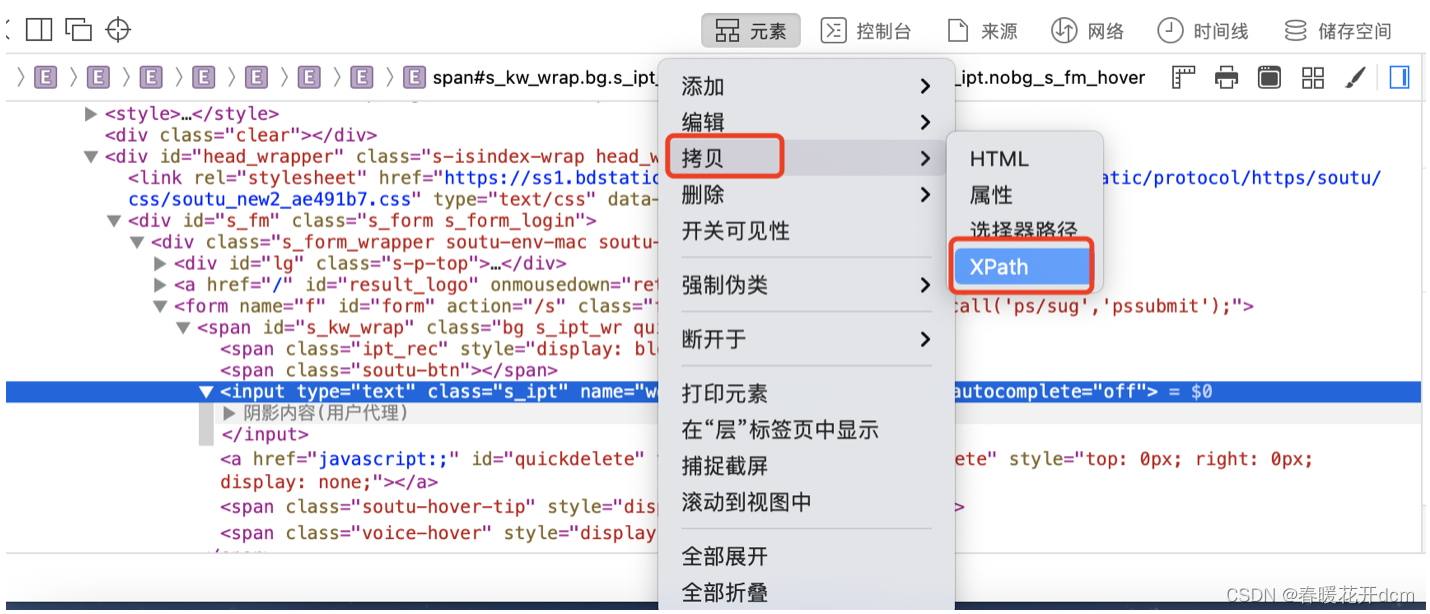
1.绝对路径
缺点:
一旦页面结构发生改变,路径也会随之失效,必须重新写。
所以一般不推荐使用绝对路径的写法,除非别的方法实在定位不到。
XPath:/html/body/div[1]/div[1]/div[5]/div/div/form/span[1]/input
2.相对路径
XPath://form/span/input
3.利用元素属性定位
XPath:
//input[@id=‘kw’]
//*[@id='kw’]
4.属性与层级结合
XPath://span[@class='bg s_ipt_wr quickdelete-wrap']/input
查找所有class属性为bg s_ipt_wr quickdelete-wrap的span元素下的input子元素
5.使用逻辑运算符
XPath://input[@class='s_ipt' and @id='kw’] 查找class属性为s_ipt且id属性为kw的所有input元素
6.使用部分属性值匹配
XPath:
//input[starts-with(@class,'s_')] 查找class属性中开始位置包含’s_’关键字的所有input元素
//input[contains(@class,'_i')] 查找class属性中包含’_i’关键字的所有input元素
//input[ends-with(@class,'pt')] 查找class属性中以关键字’pt’结尾的所有input元素 注意:ends-with是xpath2.0的语法,可能现在的浏览器还只支持1.0的语法
替换成://input[substring(@class, string-length(@class) - string-length('pt') +1) = 'pt']
//input[contains(@class,'_i') and contains(@name,'wd')] 查找class属性中包含关键字’_i’并且name属性中包含关键字’wd’的所有input元素
//input[contains(@class,'_i') and @name='wd'] 查找class属性中包含关键字’_i‘并且name属性为wd的所有input元素
//input[contains(@class,'_i') or contains(@name,'wd')] 查找class属性中包含关键字'_i'或者name属性中包含关键字'wd'的所有input元素
还有一种text()匹配的是显示的文本信息
例如:<a href="http://news.baidu.com" target="_blank" class="mnav c-font-normal c-color-t">新闻</a>
Xpath:
//a[text()='新闻'] 查找文本信息为“新闻”的所有a元素
//a[contains(text(),'新')] 查找文本信息包含“新”的所有a元素
通过CSS定位:
参考文档:https://www.runoob.com/cssref/css-selectors.html
1.通过class属性定位
driver.find_element_by_css_selector('.s_ipt') # 英文的.表示class定位器,后面紧跟class属性值
2.通过id属性定位
driver.find_element_by_css_selector('#kw') # 表示id属性选择器,后面紧跟id属性值
3.通过标签名定位
driver.find_element_by_css_selector('input') # 标签选择器,直接传入要定位元素的标签,可直接定位到该元素
4.通过父子关系定位
driver.find_element_by_css_selector('span>input') # 子代选择器用>表示,可以获得span元素子代的所有input标签(仅可获得span下一层级,跨层级获取不到)
5.通过属性定位
driver.find_element_by_css_selector('*[id=kw]') # 属性选择器,可以通过任意属性值过滤
6.通配符
driver.find_element_by_css_selector('[class$=_ipt]') # 选择每一个class属性的值以"_ipt"结尾的元素
7.组合定位
driver.find_element_by_css_selector('form.fm>span>input.s_ipt')
这只是几种常用的方式,还有别的如后代元素选择器、相邻元素选择器等,有兴趣的可以下来研究
注意:
- 使用id,name,class属性是定位元素的首选方法。其中,用元素的id是最首选的方法,是最快速的策略。
- 当发生下列情况时,无法使用id属性:
- 不是所有的页面元素都拥有id属性
- id属性的值是动态生成的
- find_element方法定位元素时,会查询整个DOM,然后返回第一个匹配的元素
- 假设页面上有一些重复的元素,它们有不同的父元素。我们可以先定位其父元素,然后定位其子元素,方法如下:
driver.find_element_by_id('father').find_element_by_link_text('xxx')
- find_elements方法,可以得到指定规则的集合,适用于需要在一组相似的元素上进行操作的情况