目录
1,字符编码
数字计算机中的存储器唯一可以存储的是比特(bit),因此如果要想在计算机上处理信息,就必须把它们按位存储。为了将文本表示为数字形式,我们需要构建一种系统来为每一个字母赋予一个唯一的编码。数字和标点符号也算做文本的一种形式,所以它们也必须拥有自己的编码。
所有由符号所表示的字母和数字(Alphanumeric)都需要编码。具有这种功能的系统被称为字符编码集(Coded Character Set),系统内的每个独立编码称为字符编码(Character Codes)。1
2,三大字符集及编码方式
2.1,ASCII字符集及编码方式
ASCII码就是一种被广泛使用的字符编码标准,它被称为美国信息交换标准码(American Standard Code for Information Interchange),简称为ASCII码,发音很像ASS-key。从1967年正式公布至今,它一直是计算机产业中最重要的标准。
ASCII码字符集只包含对英文字母,数字,标点符号和特殊字符的映射关系,并不包含汉字,对字符的编号称作码点,将对应的码点进行编码(十进制转为二进制——ASCII码的编码方式),使用一个字节对二进制码进行存储,ASCII码的首位都是0。如下图:
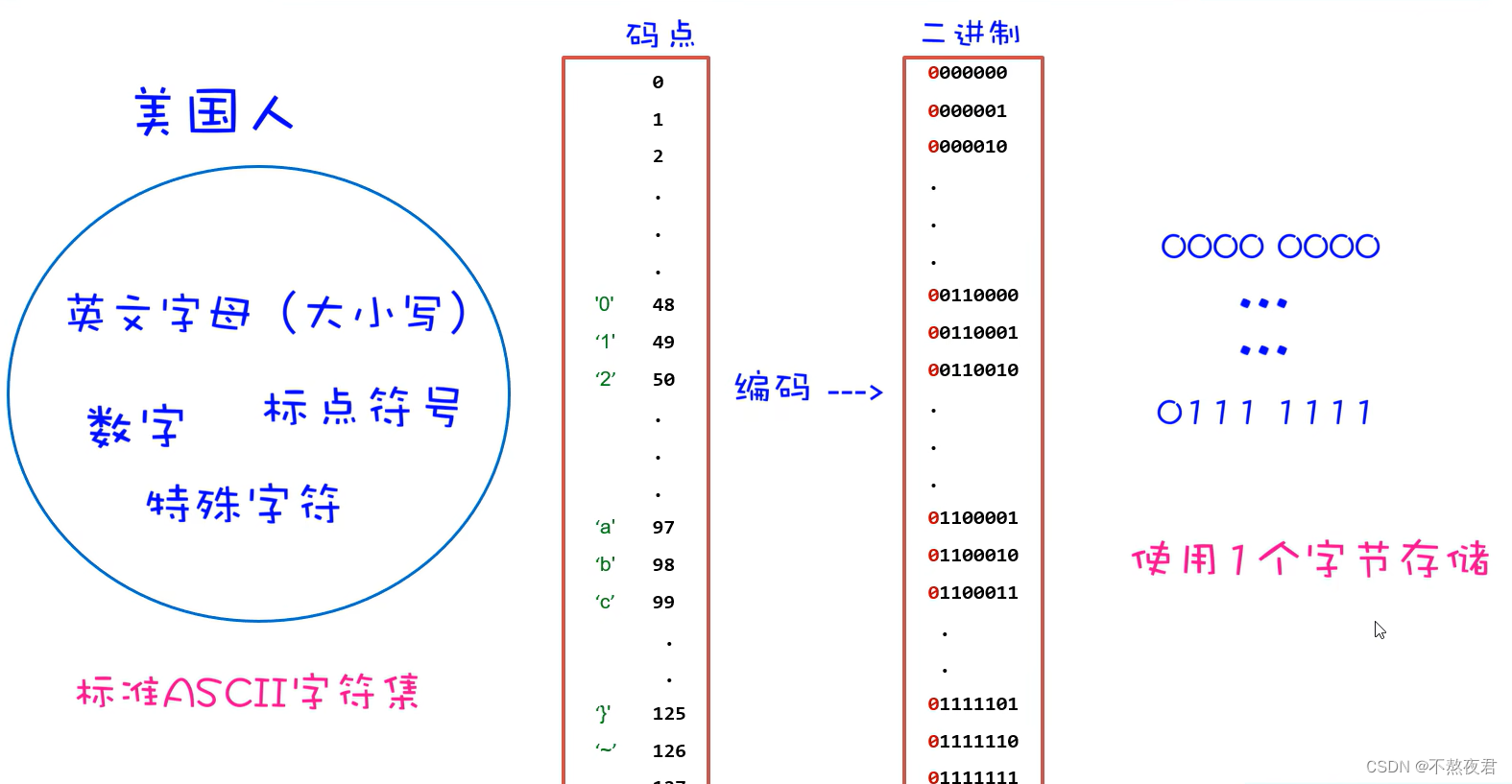
注意:这里有一个小细节,由于美国人将其所有的字符进行映射之后,最大的码点就是127,那么它对应的二进制编码就是1111111只有7位,但是我们知道计算机底层的最小存储单元是一个字节,所以美国人在不满八位的编码前面进行补零所以127对应的编码就是01111111。
2.2,GBK字符集及编码方式
如下图:这里要注意的是,在GBK编码中,一个中文字符是由两个字节存储,对于字母和数字等还是使用一个字节进行存储,也就是说GBK字符集是兼容ASCII字符集的。

2.3,Unicode字符集及编码方式
Unicode,统一码,也叫万国码,学名是"Universal Multiple-Octet Coded Character Set",简称为UCS。现在用的是UCS-2,即2个字节编码,而UCS-4是为了防止将来2个字节不够用才开发的。
相对于ASCII的7位编码,目前Unicode采用了16位编码,每一个字符需要2个字节。也就是说Unicode的字符编码范围为0000h~FFFFh,总共可以表示65,536个不同字符。全世界所有的人类语言,尤其是经常出现在计算机通信过程中的语言,都可以使用同一个编码系统,而且这种系统还具备很高的扩展性。
基于Unicode字符集的的编码方式有utf-8,utf-16和utf-32,这里来略微地讲一些utf-32和utf-8.
utf-32:这种编码方式是国际组织最早提出来的编码方式,但是比较鸡肋,因为他对每一个Unicode字符集的编号的存储都是使用四个字节进行存储,这种存储方式既浪费存储空间,又影响寻址速度。如下图,对01100001进行编码。

utf-8:

3.程序乱码问题
出现乱码的问题,是因为编码方式和解码方式不一样。
Java对String类对字符串的解码和编码提供了方法。

在这里我们对“a我b”这个字符串进行编码和解码,但是在最后,我们在对bytes1进行解码的时候,发现出现了中文乱码,这是因为使用GBK进行的编码,使用的是utf-8进行的解码,平台默认提供的是utf-8进行的解码,所以出现了乱码。那么我只需要将代码改为String s2 = new String(bytes1,"GBK");就不会再出现乱码。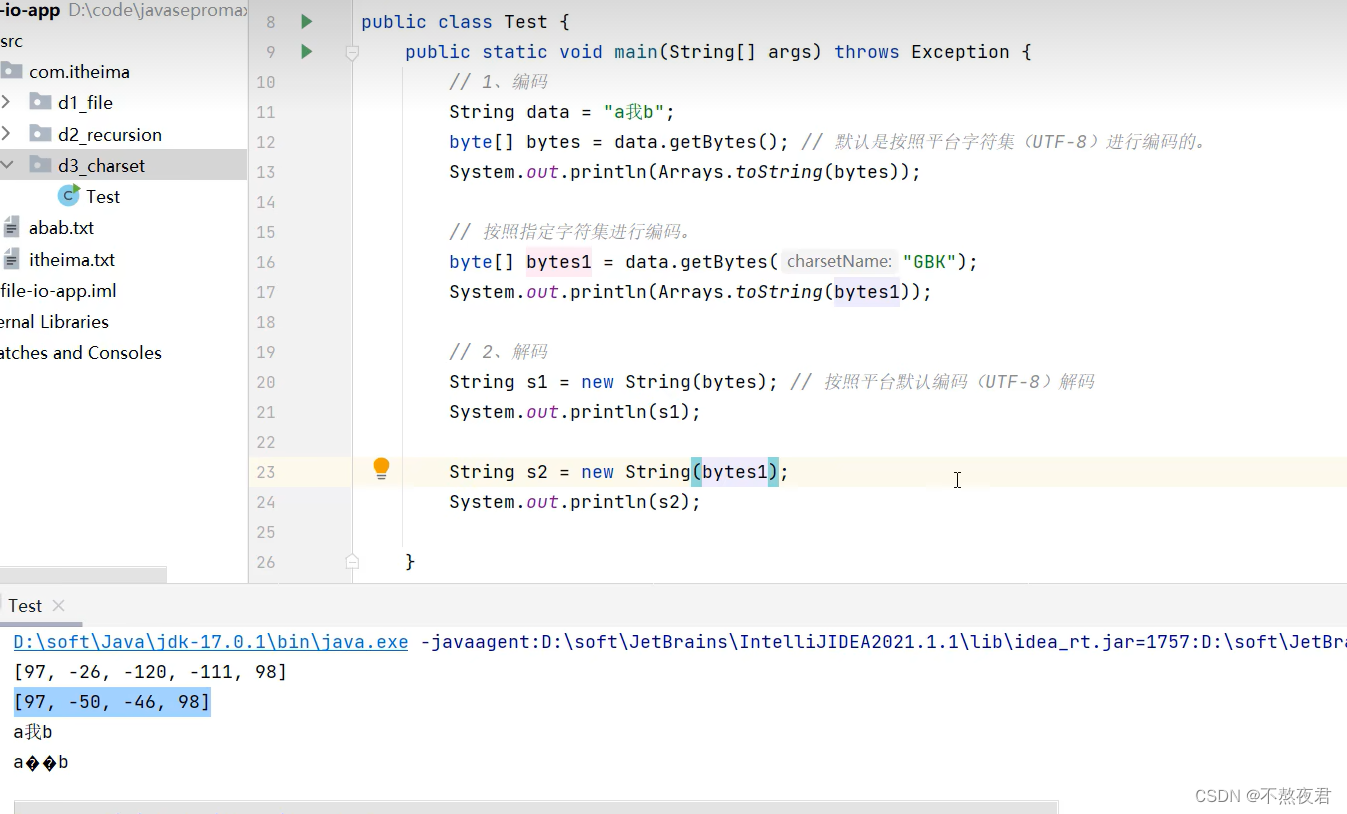
本篇博客对字符集和编码方式的介绍就到这里,如果本篇博客对你有帮助的话,请点一个小赞支持一下,感谢!我们下篇博客再见!