一.ceph定义:分布式存储概述
1、分类;单机,商业、分布式存储
有状态集群数据读写特性

存储考虑:
单机:
单机存储的磁盘空间问题、 IO 问题、 扩容问题、 高可用问题:
商业:
商业解决方案-EMC、 NetAPP、 戴尔、 华为、 浪潮
2.分布式存储数据特性
数据分为数据和元数据
元数据是文件的属性信息(文件名,权限(属主,属组)大小、时间戳等)

块存储:需要格式化,将文件直接保存到磁盘上
文件存储:提供数据存储的接口,由操作系统针对块存储的应用
对象存储;基于对象的存储,文件被拆分多个部分并散布在多个存储服务器
二.ceph基础
1.Ceph 是一个开源的分布式存储系统,同时支持块设备,文件系统,对象存储
github.com/ceph/ceph 官网
ceph是一个对象式存储系统,把每一个待管理数据刘切分为一到多个固定大小的对象数据,对象数据的底层存储服务由多个存储主机host组成,该集群也称之为RADOS 存储集群 可靠的,自动化的,分布式的对象存储系统
librados 是RADOS存储集群的API 支持C java python ruby php. go等变成语言客户端
2.ceph 集群角色定义:
https://docs.ceph.com/en/latest/start/intro/
http://docs.ceph.org.cn/start/intro/
monitors (ceph-mon)ceph
在一个主机上运行的一个守护进程,用于维护集群状态映射
(比如ceph集群中有多少存储池,每个存储池有多少个PG以及存储池和PG的映射关系等
监视器 维护ceph集群的状态(映射图-map)以及客户端的访问认证) 通常需要3个 才能实现冗余和高可用性
ceph-mgr ceph集群的运行指标统计,可以通过
在一个主机上运行的一个守护进程, Ceph Manager 守护程序( ceph-mgr) 负责跟踪运
行时指标和 Ceph 集群的当前状态, 包括存储利用率, 当前性能指标和系统负载
**Ceph OSDs(**对象存储守护程序 ceph-osd)
提供存储数据, 操作系统上的一个磁盘就是一个 OSD 守护程序, OSD 用于处理 ceph 集
群数据复制, 恢复, 重新平衡, 并通过检查其他 Ceph OSD 守护程序的心跳来向 Ceph 监视
器和管理器提供一些监视信息。 通常至少需要 3 个 Ceph OSD 才能实现冗余和高可用性
MDS(ceph 元数据服务器 ceph-mds)
代表 ceph文件系统(NFS/CIFS)存储元数据, (即 Ceph块设备和 Ceph对象存储不使用 MDS
3.Ceph 的管理节点:
3.1. ceph 的常用管理接口是一组命令行工具程序, 例如 rados、 ceph、 rbd 等命令, ceph 管理
员可以从某个特定的 ceph-mon 节点执行管理操作
3.2. 推荐使用部署专用的管理节点对 ceph 进行配置管理、 升级与后期维护, 方便后期权限管
理, 管理节点的权限只对管理人员开放, 可以避免一些不必要的误操作的发生

4.ceph逻辑组织架构
pool:存储池,分区,存储池的大小取决于底层的存储空间
pg(placement group): 一个pool内部有多个PG 。都是抽象的逻辑概念 一个pool中有多少PG 通过公式计算
PG的作用
计算方法:一般是2的整次方
4.1、在PG内的磁盘宕机后,尽可能降低数据的同步到新的OSD开销
4.2、在PG内把数据进行逻辑拆分,写入到不同的PG,以降低单个PG的数据量
4.3、通过ceph吞吐
osd:(对象存储设备) 集群部署后 要先创建存储池才能向ceph写入数据,文件在向ceph保存之前要先进行一致性hash计算; 每一块磁盘都是一个OSD 一个主机由一个或多个OSD组成
ceph 集群部署好之后,要先创建存储池才能向 ceph 写入数据, 文件在向 ceph 保存之前要先
进行一致性 hash 计算, 计算后会把文件保存在某个对应的 PG 的,
此文件一定属于某个 pool的一个 PG, 在通过 PG 保存在 OSD 上。
数据对象在写到主 OSD 之后再同步对从 OSD 以实现数据的高可用。
5.ceph 元数据保存方式
ceph对象数据的元数据,以key-value的形式存在,在RADOS中 有两种实现方式; xattrs和omap
5.1.xattrs(扩展属性):
将元数据 保存在对象对应文件的扩展属性中 并保存到系统磁盘上,要求支持对象存储的本地文件系统 (一般是XFS)支持扩展属性
5.2.omap(object map 对象映射)
是 object map 的简称, 是将元数据保存在本地文件系统之外的独立 key-value 存储系统中, 在使用 filestore 时是 leveldb, 在使用 bluestore 时是 rocksdb, 由于 filestore 存在功能问题(需要将磁盘格式化为 XFS 格式)及元数据高可用问题等问题, 因此在目前 ceph主要使用 bluestore。
基础学习到这先,来看看如何部署
三、部署RADOS集群
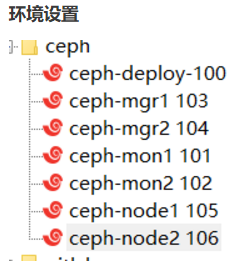
须知:除了deploy 其他都需要双网卡 ,集群正常需要3台,实验环境 我只用2台;
新增网卡 都设置 仅主机模式
要特别注意的是
nat 要网关
仅主机 不需要网关

仓库准备
https://mirrors.aliyun.com/ceph/ #阿里云镜像仓库
http://mirrors.163.com/ceph/ #网易镜像仓库
https://mirrors.tuna.tsinghua.edu.cn/ceph/ #清华大学镜像源
总结起来一句话:(先mon 再加mgr 最后加入OSD)
1,导入key:
Ubuntu
wget -q -O- 'https://mirrors.tuna.tsinghua.edu.cn/ceph/keys/release.asc' | sudo apt-key add - #所有都执行
相关网站链接
https://mirror.tuna.tsinghua.edu.cn/ceph/keys/release.asc
https://mirror.tuna.tsinghua.edu.cn/help/ceph/
https://mirror.tuna.tsinghua.edu.cn/ceph/keys/ 官方网站
2.更新源
#18.04 (所有服务器都需要)
sudo echo "deb https://mirrors.tuna.tsinghua.edu.cn/ceph/debian-pacific bionic main" >> /etc/apt/sources.list
#20.04
sudo echo "deb https://mirrors.tuna.tsinghua.edu.cn/ceph/debian-pacific focal main" >> /etc/apt/sources.list
更新后执行 apt update
这里要注意的是1804的版本 后面跟的是bionic 而2004后面跟的是 focal
3.创建ceph用户;
所有服务器都执行;
推荐使用指定的日常用户部署和运行 ceph,日常用户只要能以非交互方式执行 sudo 命令执行一些特权命令
不用ceph命名 在安装ceph包的时候 会自动创建一个
groupadd -r -g 2022 mali && useradd -r -m -s /bin/bash -u 2022 -g 2022 mali && echo mali:123456 | chpasswd
echo "mali ALL=(ALL) NOPASSWD: ALL" >> /etc/sudoers #授权
4.配置免密登录
在 ceph-deploy 节点配置允许以非交互的方式登录到各 ceph node/mon/mgr 节点,即在
ceph-deploy 节点生成秘诀,然后分发公钥到各个被管理节点
在ceph-deploy主机操作
ssh-keygen
ssh-copy-id (指定ip)
(为了避免后续出现 ssh的时候 要输入密码 我这里是 在root和mali账户下都操作了一下)
5.配置主机名解析;
在所有主机的root账户下 vim /etc/hosts
10.0.0.100 ceph-deploy ceph-deploy
10.0.0.101 ceph-mon1 ceph-mon1
10.0.0.102 ceph-mon2 ceph-mon2
10.0.0.103 ceph-mgr1 ceph-mgr1
10.0.0.104 ceph-mgr2 ceph-mgr2
10.0.0.105 ceph-node1 ceph-node1
10.0.0.106 ceph-node2 ceph-node2
6.安装ceph-deploy部署工具
Ubuntu:
在ceph-deploy100 安装ceph 磁盘必须要是空的;
Ubuntu环境
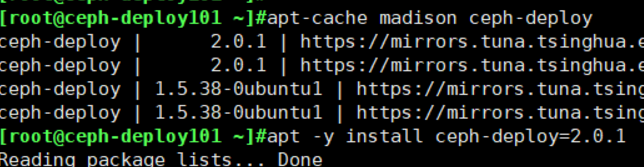
apt-cache madison ceph-deploy
apt -y install ceph-deploy=2.0.1
Centos环境:
[ceph@ceph-deploy ~]$ sudo yum install ceph-deploy python-setuptools python2-subprocess3
上图是为了像我一样的小白更快理解,嘿嘿
7.配置python;
apt install python2.7 -y #所有都安装;而ceph-deploy主机在安装ceph-deploy=2.0.1的时候 默认有安装;
ln -sv /usr/bin/python2.7 /usr/bin/python2 #所有机器设置软链接:
安装好后 执行python2测试 如果可以执行,说明安装好了’

8.运用ceph-deploy进行部署
切换到mali账户 创建目录
root@ceph-deploy101 ~]#su - mali
mali@ceph-deploy101:~$ pwd
/home/mali
mali@ceph-deploy101:~$ mkdir ceph-cluster
mali@ceph-deploy101:~$ cd ceph-cluster/
mali@ceph-deploy101:~/ceph-cluster$
查看的结果如下:

9.初始化mon节点
切换到普通用户 下 初始化 mon 生成配置文件
root@ceph-deploy:~ $su - mali
cd ceph-cluster$
sudo ceph-deploy new --public-network 10.0.0.0/24 --cluster-network 192.168.196.0/24 ceph-mon1 ceph-mon2
public是nat的网段 cluster是仅主机的网段
执行成功,会得到三个文件 结果: 如下:

ceph.conf # 配置文件
ceph-deploy-ceph.log #部署的日志
ceph.mon.keyring # mon.keyring
10.初始化node节点;
no-adjust-repos是不指定源 之前有配置好
在普通账户cd ceph-cluster$~$下操作:(在ceph-cluster下操作会有报错)
ceph-deploy install --no-adjust-repos --nogpgcheck ceph-node1 ceph-node2 (不指定版本)
ceph-deploy install --no-adjust-repos --nogpgcheck --release pacific ceph-node1 ceph-node2 (指定版本)


11.配置 mon 节点并生成及同步密钥
在所有mon节点操作;
apt -y install ceph-mon=16.2.5-1bionic 指定版本
apt -y install ceph-mon 随机安装最新版本


在deploy上执行
mali@ceph-deploy:~/ceph-cluster$ ceph-deploy mon create-initial 启动mon服务;执行结果

生成ceph.client.admin.keyring的配置文件 (在哪台ceph机器管理 集群,这个文件就放在哪里)

启动后 会有mon进程,在mon主机上查看


初始化后,mon就启动了
在安装mon的时候,自己创建的;生成的ceph账户


12.分发 admin 密码
保存好生成的ceph.client.admin.keyring文件
在deploy和node节点上安装 common
在ceph-cluster$目录下;
sudo apt install ceph-common -y
同步配置文件到node, (非必须)
ceph-deploy admin ceph-node1 ceph-node2

推送一份给本机
ceph-deploy admin ceph-deploy

执行命令 ceph -s
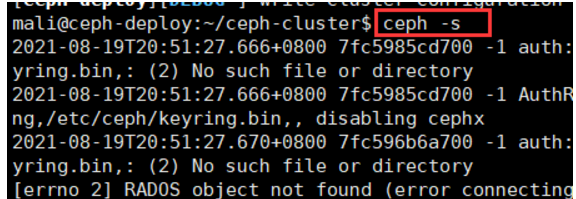
ceph节点验证密钥
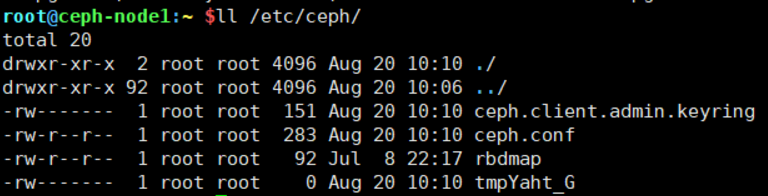

为了安全考虑,默认设置为root用户和组,如果需要ceph用户执行命令,需要对ceph用户进行授权
setfacl -m u:ceph:rw /etc/ceph/ceph.client.admin.keyring
在deploy主机执行
mali@ceph-deploy:~/ceph-cluster$ sudo setfacl -m u:mali:rw /etc/ceph/ceph.client.admin.keyring
执行ceph -s 查看

(总结 ,node节点要有权限读取,必须在deploy上 推送 和授权 两个步骤)
13.部署ceph-mgr节点
mgr节点需要读取ceph的配置文件,即/etc/ceph目录中的配置文件
安装mgr:
在ceph-mgr主机上操作 apt install ceph-mgr -y
在deploy上操作
ceph-deploy mgr create ceph-mgr1
ceph-deploy mgr create ceph-mgr2
在mgr上查看


在deploy上 查看 ceph -s

图中目前有这个健康警告 mons are allowing…
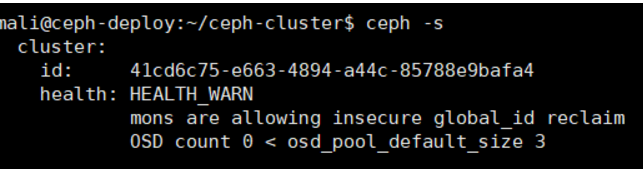
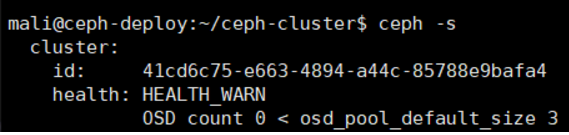
执行 ceph config set mon auth_allow_insecure_global_id_reclaim false
改完后没有该警告了:
14.准备OSD节点
在deploy主机执行
ceph-deploy install --release pacific ceph-node1 ceph-node2 (这步在初始化node节点已经做过)
#擦除之前通过部署节点对节点节点执行安装ceph基本运行环境
apt autoremove #node节点任选删除不需要的包,可操作可不操作;

在node主机 各添加了3块硬盘
ceph-deploy disk list ceph-node1 #列出远端存储node节点的磁盘信息


使用ceph-deploy disk zap 擦除各ceph节点的ceph数据磁盘
在deploy主机上操作;
mali@ceph-deploy:~/ceph-cluster$
ceph-node1
sudo ceph-deploy disk zap ceph-node1 /dev/sdb
sudo ceph-deploy disk zap ceph-node1 /dev/sdc
sudo ceph-deploy disk zap ceph-node1 /dev/sdd
ceph-node2
sudo ceph-deploy disk zap ceph-node2 /dev/sdb
sudo ceph-deploy disk zap ceph-node2 /dev/sdc
sudo ceph-deploy disk zap ceph-node2 /dev/sdd
擦除成功的提示是

添加OSD节点:
Data:即ceph保存的对象数据
block:rocks DB 数据即元数据
block-wal: 数据库的 wal 日志
目前是报警;
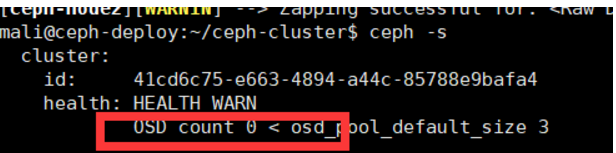
ceph-node1:
sudo ceph-deploy osd create ceph-node1 --data /dev/sdb
sudo ceph-deploy osd create ceph-node1 --data /dev/sdc
sudo ceph-deploy osd create ceph-node1 --data /dev/sdd
备注 特别要注意 添加一定要记录 每个硬盘对应的数字, 以免后续故障后排查
ceph-osd.0 node1 sdb
ceph-osd.1 node1 sdc
ceph-osd.2 node1 sdd
添加node1 查看ceph -s

继续添加node2
ceph-node2:
sudo ceph-deploy osd create ceph-node2 --data /dev/sdb
sudo ceph-deploy osd create ceph-node2 --data /dev/sdc
sudo ceph-deploy osd create ceph-node2 --data /dev/sdd
特别要注意 添加一定要记录 每个硬盘对应的数字, 以免后续故障后排查
ceph-osd.3 node2 sdb
ceph-osd.4 node2 sdc
ceph-osd.5 node2 sdd
添加node2 查看ceph -s

在node上查看
ps -ef | grep osd


另外 若擦除和添加ods遇到报错

需要重新初始化
重新擦除
而如果还是不行 将该磁盘 移除 重新添加才可以
15.验证 ceph 集群
设置 OSD 服务自启动:
默认就已经为自启动,节点节点添加完成后,开源测试节点服务器重启后,OSD是否会自动
启动。

16.从RADOS 移除OSD
(这个步骤做了解,一般不常用)
ceph集群中的一个OSD是一个node节点的服务进程且对应于一个物理磁盘设备,是一个专用的守护进程
在某OSD设备出现故障,或管理员处于管理之需确实要移除特定的OSD设备时,需要先停止相关的守护进程,而后再进行移除操作,对于linux以及以后的版本来说,停止和移除命令的格式分别如下:
停用设备: ceph osd out {
osd-num}
停止进程: sudo systemctl stop ceph-osd@{
osd-num}
移除设备: ceph osd purge {
id} --yes-i-really-mean-it
OSD 的配置信息存在于 ceph.conf 配置文件中, 管理员在删除 OSD 之后手动将其删除
于 CRUSH 运行图中移除设备: ceph osd crush remove {
name}
移除 OSD 的认证 key: ceph auth del osd.{
osd-num}
最后移除 OSD 设备: ceph osd rm {
osd-num}
17.测试上传和下载数据;
RADOS命令
存取数据时, 客户端必须首先连接至 RADOS 集群上某存储池, 然后根据对象名称由相关的CRUSH 规则完成数据对象寻址。 于是, 为了测试集群的数据存取功能, 这里首先创建一个用于测试的存储池 mypool, 并设定其 PG 数量为 32 个
创建pool:
mali@ceph-deploy:~/ceph-cluster$ ceph osd pool create mypool 32 32 #创建
mali@ceph-deploy:~/ceph-cluster$ ceph osd pool ls 或者rados lspools #验证
ceph pg ls-by-pool mypool | awk '{print $1,$2,$15}' #验证PG 与 PGP 组合
上传文件.
sudo rados put msg1 /var/log/syslog --pool=mypool
#把消息文件上传到 mypool 并指定对象 id 为 msg1
rados ls --pool=mypool #列出文件

ceph osd map 可以获取到存储池中数据对象的具体位置信息:
ceph osd map mypool msg1

表示文件放在了存储池id为2的c833d430的PG上,10为当前PG的id
2.10表示数据是在id为2的存储池当中 id为10的PG中存储
在线的OSD编号是 2.4 主OSD为2 活动的OSD是 2.4 两个OSD表示数据一共3个副本
PG中的OSD是ceph的crush算法,计算算出三分数据 保存在哪些OSD; 而由于我这里只用了两个node 所以 下面附上标准的解答
标准的解答;
ceph@ceph-deploy:/home/ceph/ceph-cluster$ ceph osd map mypool msg1
osdmap e114 pool'mypool' (2) object'msg1' -> pg 2.c833d430 (2.10) -> up ([15,13,0], p15) acting
([15,13,0], p15)
表示文件存储了存储池 id 为 2 的 c833d430 的 PG 上,10 为当前 PG 的 id, 2.10 表示数据是在
id 为 2 的存储池中 id 为 10 的 PG 中存储,在线的 OSD 编号 15,13,10,主 OSD 为 5,活动
的OSD 15,13,10,三个OSD表示数据放一共3个副本,PG中的OSD是ceph的crush算法计算
算出三份数据保存在哪些OSD
下载文件;
sudo rados get msg1 --pool=mypool /opt/my.txt
含义是:下载mypool里的msg1文件 放在本地目录的名字
修改文件:
sudo rados put msg1 /etc/passwd --pool=mypool #将/etc/passwd 上传到mypool下的 msg1文件中
sudo rados get msg1 --pool=mypool /opt/my3.txt #重新从mypool里下载msg1 并存放本地目录重命名为/opt/my3.txt
head /opt/my3.txt

删除文件
sudo rados rm msg1 --pool=mypool
rados ls --pool=mypool
18.扩展 ceph 实现高可用
主要是扩展ceph集群的mon节点以及mgr节点 以实现集群高可用
1.扩展 ceph-mon 节点:
在mon1上安装mon
Ceph-mon 是原生具备自噬以实现高可用机制的 ceph 服务,节点数量通常是奇数
apt -y install ceph-mon=16.2.5-1bionic #ubuntu上安装指定版本
yum install ceph-common ceph-mon #centos上安装指定版本
sudo ceph-deploy mon add ceph-mon3 在ceph-deploy操作将mon3添加
验证ceph-mon状态
ceph quorum_status --format json-pretty


2.扩展mgr节点
在mgr主机安装mgr
ceph-deploy admin ceph-mgr2 # 同步 配 置 文件 到ceph-mg2 节点
ceph-deploy mgr create ceph-mgr2
验证状态ceph -s

(扩展高可用总结;在远游集群的基础上添加mon和mgr服务器需要做的操作)
设置完成,谢谢观赏
