【MATLAB第76期】基于MATLAB的代表性样本筛选方法合集(针对多输入单输出数据)
前有筛选变量方法,如局部敏感性分析和全局敏感性分析方法介绍 。
今天提出另外一种思路,去对样本进行筛选。
使用场景:
场景1:对抽样方法生成的数据合理性进行对比分析。
场景2:对多样本数据进行筛选精简,且精度影响幅度不大。
场景3:对多输入单输出数据异常/较差样本检测。
本文使用Kennard-Stone、cluster聚类算法、局部线性重构(LLR)算法选择代表性样本
一、分类预测(多输入单输出)
数据设置:
案例数据选用12输入,1输出,357个样本的分类预测数据,评价指标为正确率。正确率越大代表效果越好。
为了提高结果稳定性,使用libsvm算法进行分类。
训练样本编号: 1:240
测试样本编号: 300:357
筛选样本编号:1:299 (除去测试样本剩余的样本)
筛选的样本数: 210
trainIdx = 1:240; % 训练样本 1:240
testIdx = 300:357; %测试样本 300:357
testIdx2= setdiff(1:size(X,1),testIdx); % 筛选样本,除去测试样本剩余的样本 1:299
nSel = 210;%筛选的样本数 210个
libsvm参数设置:
c = 10.0; % 惩罚因子
g = 0.01; % 径向基函数参数
cmd = ['-t 2', '-c', num2str(c), '-g', num2str(g)];
1、Kennard-Stone算法
参考文献:
R. W. Kennard, and L. A. Stone, “Computer aided design of experiments,” Technometrics, vol. 11, no. 1, pp. 137-148, Feb. 1969.
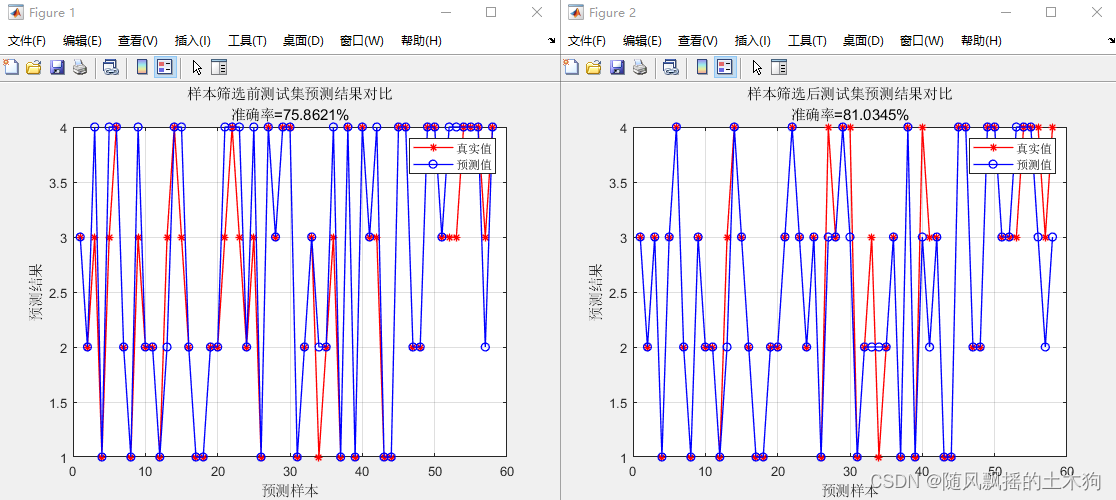
筛选前正确率: 75.86%
筛选后正确率:81.03% (效果提升)
筛选后的编号:2,3,5,6,8,9,10,14,15,17,19,20,22,24,25,26,27,28,29,33,37,39,41,42,43,44,45,47,48,50,51,52,53,55,56,57,58,61,63,64,65,66,67,68,69,70,73,74,77,78,79,80,81,83,84,86,89,90,91,92,93,94,95,97,98,99,100,101,103,106,107,109,110,111,113,114,115,116,117,118,119,120,121,122,124,125,126,128,129,130,132,133,134,135,136,138,139,140,141,142,143,145,146,147,148,151,153,154,156,157,158,160,161,165,166,167,168,169,170,171,172,173,174,175,176,179,181,182,183,184,185,187,188,190,191,193,195,196,197,198,201,202,203,204,207,209,210,211,212,213,214,219,220,221,223,225,226,227,229,230,231,232,233,235,236,237,239,240,241,242,243,245,246,248,249,250,251,253,254,257,259,260,261,262,263,264,265,266,267,270,275,276,278,281,282,283,284,285,286,287,288,289,290,291,292,293,295,296,297,299
2、cluster聚类算法
IDX = clusterdata(X,'maxclust',nSel,'linkage','average');%聚集性集群
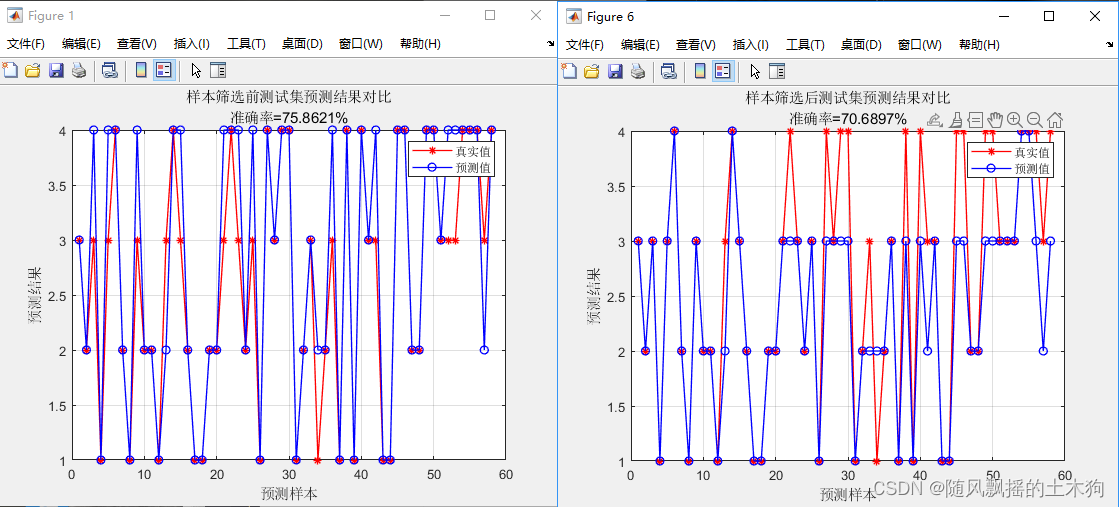
筛选前正确率: 75.86%
筛选后正确率:70.68% (效果减弱)
筛选后的编号:
2 3 5 6 9 10 11 14 15 17 20 21 22 24 25 28 29 31 33 37 38 39 41 42 43 44 45 47 48 51 52 53 54 55 56 58 61 62 63 64 65 66 67 68 70 73 75 77 78 79 80 81 83 84 85 88 89 90 91 93 94 95 96 97 98 99 100 101 103 109 110 112 114 116 117 119 120 121 122 123 124 125 128 129 130 131 132 133 134 135 136 137 138 139 141 142 143 144 146 147 148 149 151 153 154 156 157 158 160 161 162 164 165 166 167 169 170 171 172 173 174 175 176 179 181 182 183 184 185 186 187 188 190 191 193 195 196 198 201 202 203 204 207 208 209 210 212 213 214 216 218 219 220 221 222 224 225 226 227 229 230 233 234 235 236 237 238 239 240 242 243 245 246 248 249 250 251 253 254 256 257 258 259 260 263 264 265 266 267 268 270 275 276 278 280 281 282 283 284 285 286 287 288 289 290 291 293 295 297 299
3、局部线性重构(LLR)
参考文献:
L. Zhang, C. Chen, J. Bu, D. Cai, X. He, and T. S. Huang, “Active Learning Based on Locally Linear Reconstruction,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 33, no. 10, pp. 2026-2038, Oct. 2011.
Nonlinear Dimensionality Reduction by Locally Linear Embedding, Science, 2000
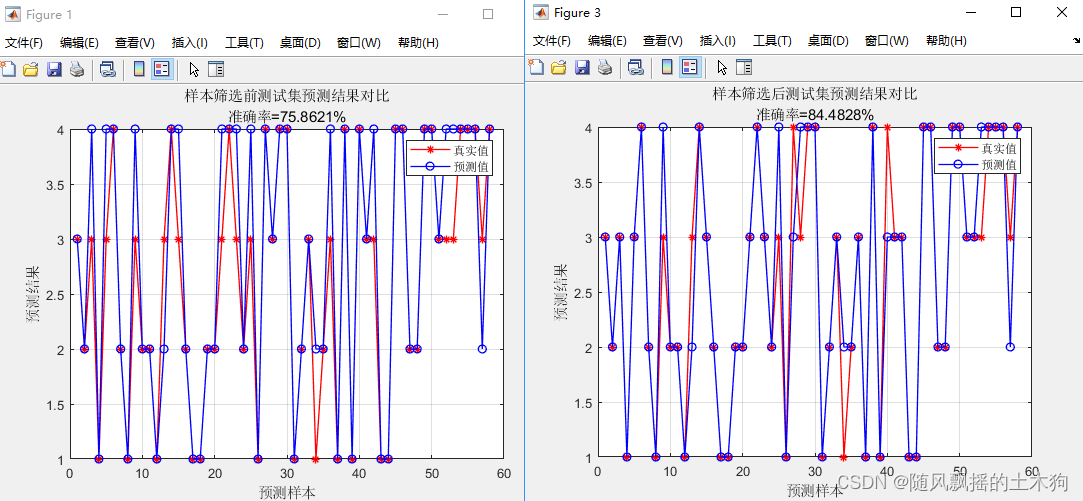
筛选前正确率: 75.86%
筛选后正确率:84.48% (效果提升)
筛选后的编号:
3 5 6 7 9 10 14 15 16 17 18 20 21 22 23 25 26 27 29 30 31 32 33 34 35 36 38 39 41 42 43 46 47 48 49 51 52 53 54 55 56 57 59 60 62 64 65 66 67 68 70 72 75 78 79 81 82 83 85 87 88 89 92 93 94 95 96 98 99 100 101 102 104 105 107 108 109 110 111 112 113 116 117 118 124 125 126 128 130 131 132 134 135 136 137 140 141 144 145 148 149 150 152 154 155 157 158 159 160 162 163 164 166 167 170 172 174 177 178 179 181 182 183 184 186 187 188 189 190 192 193 194 195 196 197 198 199 200 201 202 203 204 205 207 208 210 212 213 214 215 216 220 221 222 223 225 226 229 230 231 232 233 234 235 236 237 238 240 242 244 245 246 247 248 249 251 253 254 256 257 258 259 261 262 263 264 265 267 269 271 272 273 276 277 278 279 280 281 282 283 284 285 286 288 291 292 294 295 296 297
二、回归预测(多输入单输出)
数据设置:
案例数据选用7输入,1输出,103个样本的回归预测数据,评价指标为正确率。RMSE均方根误差越小代表效果越好。
为了提高结果稳定性,使用libsvm算法进行回归。
训练样本编号: 1:80
测试样本编号: 90:103
筛选样本编号:1:89 (除去测试样本剩余的样本)
筛选的样本数: 70
XN=1:103;
trainIdx = 1:80;
testIdx = 90:103;
testIdx2= setdiff(1:size(p_train,1),testIdx);
mtds = {
@myks};
nMtd = length(mtds);
nSel =70;
N2=size(testIdx ,2);
libsvm参数设置:
c = 4.0; % 惩罚因子
g = 0.8; % 径向基函数参数
cmd = [' -t 2',' -c ',num2str(c),' -g ',num2str(g),' -s 3 -p 0.01'];
1、Kennard-Stone算法
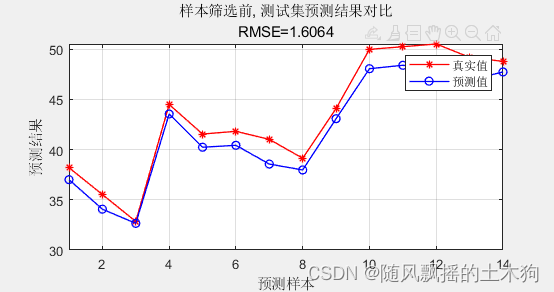
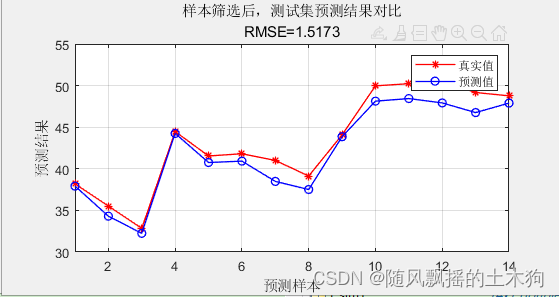
Mean squared error = 0.00150997 (regression)
Squared correlation coefficient = 0.990571 (regression)
样本筛选前, 测试集数据的RMSE为:1.6064
样本筛选前, 测试集数据的R2为:0.91688
样本筛选前, 测试集数据的MAE为:1.4789
样本筛选前,测试集数据的MBE为:-1.4789
1,2,3,5,6,7,8,9,11,12,13,14,15,16,18,19,20,21,22,24,25,27,29,30,32,33,34,35,36,37,38,39,41,42,43,44,45,46,48,49,51,52,53,54,55,56,57,59,60,61,62,63,64,67,68,69,70,71,72,73,74,75,77,78,80,82,85,87,88,89,
Mean squared error = 0.00134714 (regression)
Squared correlation coefficient = 0.980441 (regression)
样本筛选后, 测试集数据的RMSE为:1.5173
样本筛选后, 测试集数据的R2为:0.92585
样本筛选后, 测试集数据的MAE为:1.2746
样本筛选后,测试集数据的MBE为:-1.2746
2、cluster聚类算法
IDX = clusterdata(X,'maxclust',nSel,'linkage','average');%聚集性集群
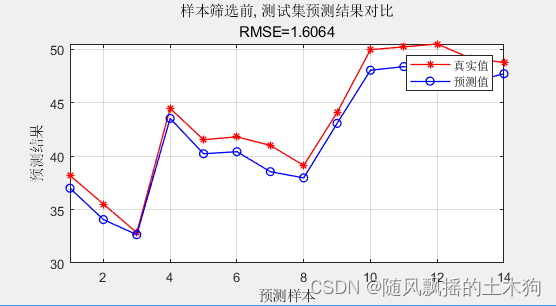
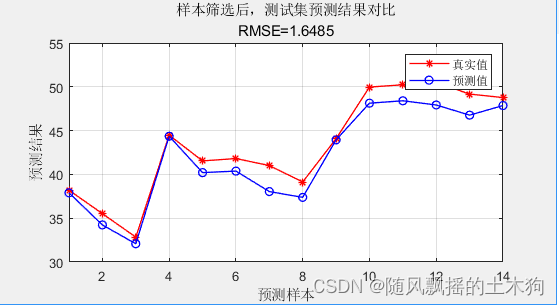
Mean squared error = 0.00150997 (regression)
Squared correlation coefficient = 0.990571 (regression)
样本筛选前, 测试集数据的RMSE为:1.6064
样本筛选前, 测试集数据的R2为:0.91688
样本筛选前, 测试集数据的MAE为:1.4789
样本筛选前,测试集数据的MBE为:-1.4789
4,5,6,7,8,9,10,11,12,13,14,15,16,18,19,20,21,22,23,26,27,28,31,32,33,34,35,36,38,39,41,42,43,44,45,46,47,48,50,51,52,53,54,55,56,57,58,59,60,61,62,64,65,66,68,69,70,71,72,74,75,77,78,80,82,84,86,87,88,89
Mean squared error = 0.00159015 (regression)
Squared correlation coefficient = 0.976864 (regression)
样本筛选后, 测试集数据的RMSE为:1.6485
样本筛选后, 测试集数据的R2为:0.91247
样本筛选后, 测试集数据的MAE为:1.4034
样本筛选后,测试集数据的MBE为:-1.4034
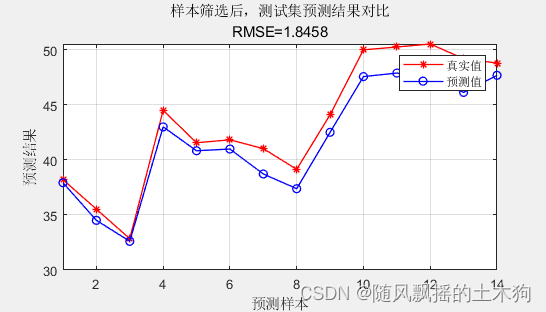
3、局部线性重构(LLR)
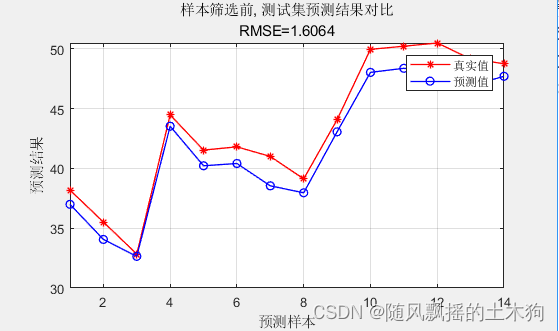
Mean squared error = 0.00150997 (regression)
Squared correlation coefficient = 0.990571 (regression)
样本筛选前, 测试集数据的RMSE为:1.6064
样本筛选前, 测试集数据的R2为:0.91688
样本筛选前, 测试集数据的MAE为:1.4789
样本筛选前,测试集数据的MBE为:-1.4789
1,2,5,6,7,8,9,10,12,13,14,15,17,18,20,21,22,24,25,27,28,29,30,32,33,34,35,36,37,38,39,40,41,44,45,46,47,48,49,52,53,54,56,57,58,59,60,63,64,65,66,67,68,69,70,71,72,73,74,77,78,79,80,81,82,84,85,86,87,89
Mean squared error = 0.00199346 (regression)
Squared correlation coefficient = 0.984489 (regression)
样本筛选后, 测试集数据的RMSE为:1.8458
样本筛选后, 测试集数据的R2为:0.89027
样本筛选后, 测试集数据的MAE为:1.5979
样本筛选后,测试集数据的MBE为:-1.5979
三、代码获取
CSDN私信回复“76期”即可获取下载方式。