一、hadoop 1.x结构
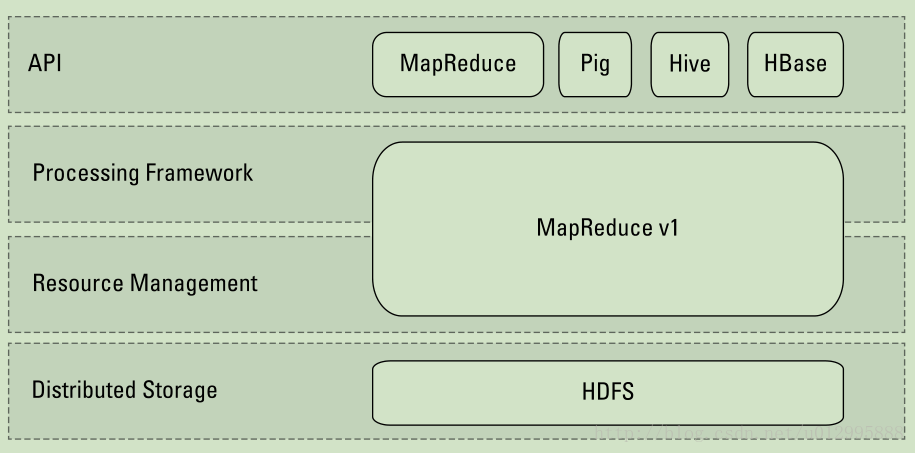
- HDFS:hadoop分布式存储系统。
- MapReduce:分布式计算框架,包含资源管理和任务调度等(hadoop 2.x中被分离到Yarn组件)。
- API:用户与系统交互的入口,有原生的MapReduce API,也有对Map Reduce进行封装抽象的Pig、Hive和HBase等。
二、hadoop 1.x运行原理
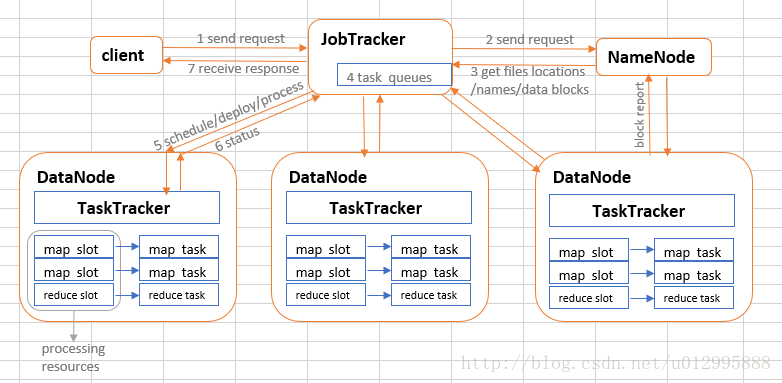
1:客户端首先向Master节点的JobTracker发送请求,JobTracker会解析请求信息判断要处理的是什么文件。
2–>3:JobTracker向hdfs中的NameNode发送请求,获取文件所在的位置、名称以及文件所对应的所有data block信息。
4:JobTracker计算处理这些data block所需要的map task和reduce task的数量,并且把这些任务加入任务队列。
5–>6: JobTracker查看组成文件的data block所在的DataNode节点的状态,检查是否有空闲的map
slot或者reduce slot。如果有空闲的slot,JobTracker向DataNode的TaskTracker发起请求处理数据任务,然后TaskTracker把slot所对应的处理资源调度给map task或者reduce task,MapReduce job数据处理阶段开始。TaskTracker监视任务的状态,并把状态发送JobTracker。7: TaskTracker了解到所有的task都完成时,把处理响应反馈给客户端。
小贴士:
1、TaskTracker是以slot的形式处理本地资源,把本地资源逻辑上拆分为一个个slot,每一个slot对应每一个task。
2、DataNode会周期性的向NameNode发送block report和节点运行状态,因此NameNode能够准实时的掌握hdfs集群的的信息。
学习资料:
1、《Hadoop For Dummies》