欢迎来到袋鼠云07期产品功能更新报告!在瞬息万变的市场环境中,袋鼠云始终将客户需求和反馈置于优化工作的核心位置,本期也针对性地推出了一系列实用性强的功能优化,以满足客户日益增长的业务需求。
以下为袋鼠云产品功能更新报告07期内容,更多探索,请继续阅读。
离线开发平台
新增功能更新
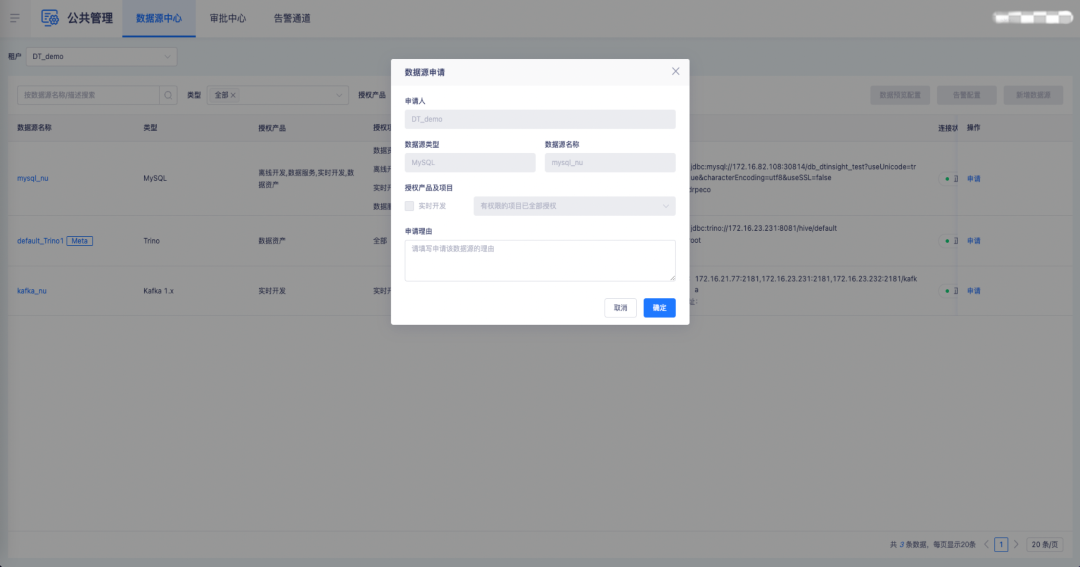
1.数据源引入支持对接审批中心
背景:数据源的使用让用户走审批流程,而非只是由管理员分配,方便进行审计记录。
新增功能说明:项目管理员、项目所有者角色可在数据源中心进行数据源的申请,数据源权限经超级管理员、租户所有者、租户管理员审批通过后,引入数据源弹窗才会出现审批通过的数据源,项目管理员和项目所有者可以在项目中引入。
2.计算引擎功能完善
• Trino 支持 explain
• Trino、Inceptor、Oracle、SQLServer、MySQL 支持语法提示
• Inceptor、Oracle、SQLServer、MySQL 支持表联想、支持血缘解析
• Oracle、SQLServer、MySQL 支持界面创建存储过程、自定义函数、系统函数,支持任务依赖推荐,支持元数据同步和整库同步
• 所有 SQL 的子查询生效
3.所有 SQL 任务支持异步运行
背景:目前我们的 RDB SQL 任务大部分采用的是同步运行,同步运行很可能会导致任务运行超时还未返回结果,考虑和 GP 一样全部调整为异步运行,优化用户体验。
新增功能说明:Spark SQL、Hive SQL、Trino SQL、Impala SQL、Inceptor SQL、GaussDB SQL、Oracle SQL、TiDB SQL、Greenplum SQL、MySQL、SQL Server、Hana SQL、ADB SQL、StarRocks SQL、HashData SQL,所有 SQL 类任务支持异步运行。
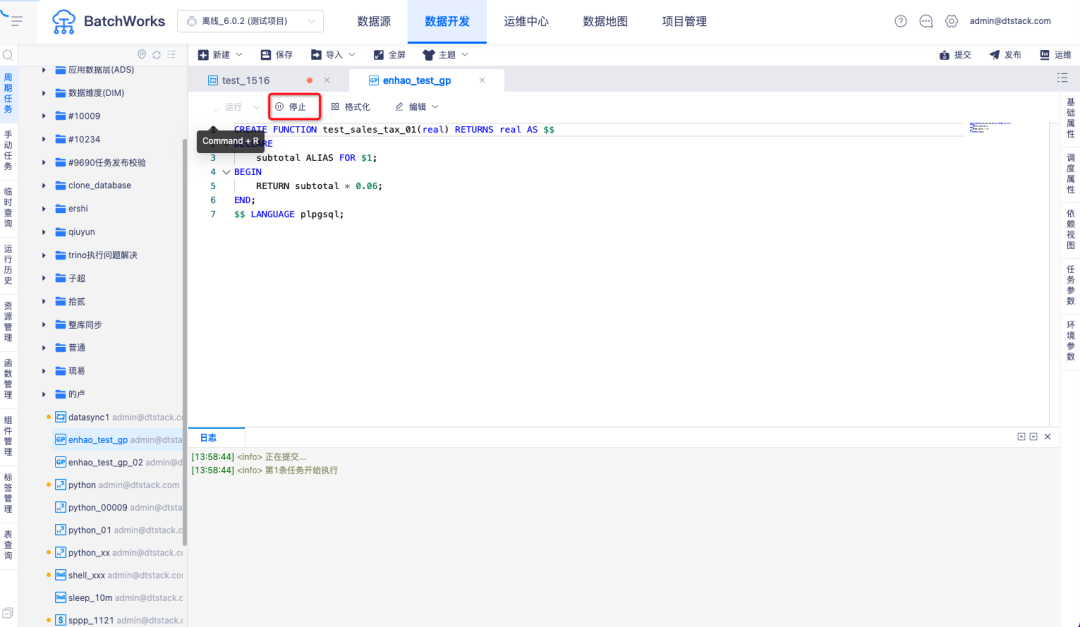
4.支持临时运行停止,临时运行停止和杀任务时支持从数据库底层停止任务运行
背景:运维中心 RDB 类型杀任务,只是在界面上停止运行任务,并没有在数据库底层让 SQL 停止运行,治标不治本。
新增功能说明:Spark SQL、Hive SQL、Trino SQL、Impala SQL、Inceptor SQL、GaussDB SQL、Oracle SQL、TiDB SQL、Greenplum SQL、MySQL、SQL Server、Hana SQL、ADB SQL、StarRocks SQL、HashData SQL,运维中心杀任务时,数据库底层也停止运行。
5.on yarn 任务日志实时打印
• 运维中心任务日志实时打印
范围:周期任务实例、手动任务实例、补数据任务实例
任务类型:Spark SQL、Hive SQL、数据同步任务、HadoopMR、PySpark、Spark、Flink
• 临时运行任务日志实时打印
范围:周期任务、手动任务、临时查询
任务类型:FileCopy、数据同步任务、Spark SQL、Hive SQL
• 原数据同步中的「错误记录数」「读取字节数」等信息打印位置调整
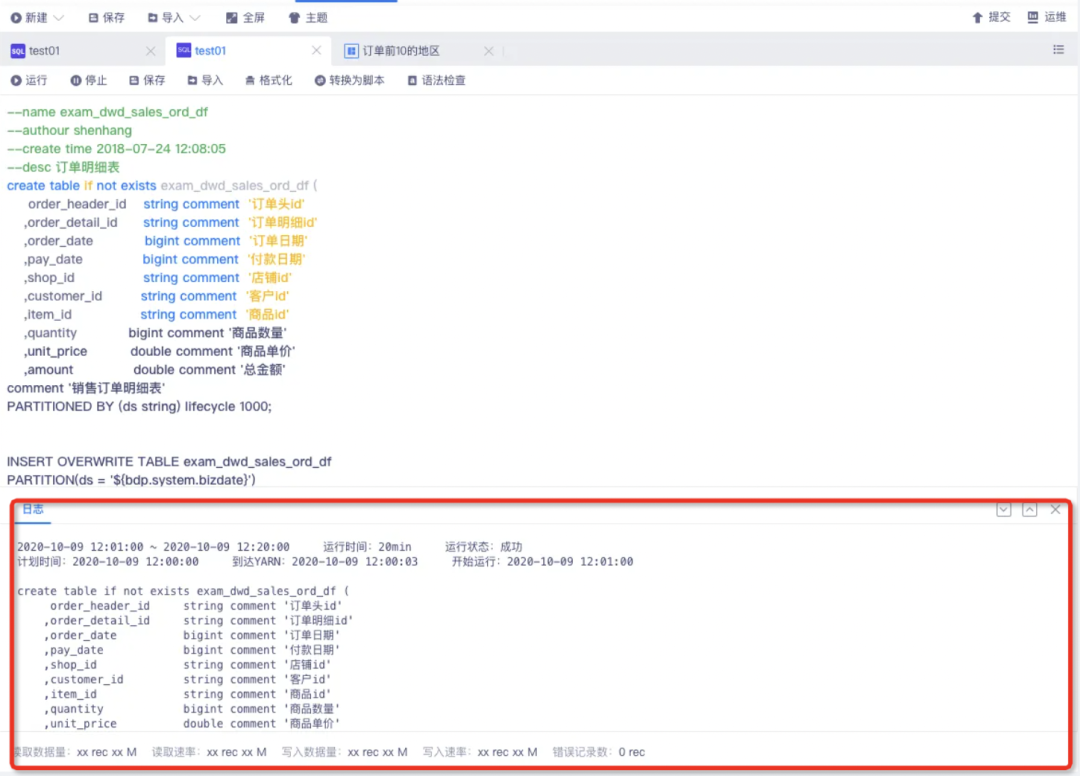
6.分段运行时,展示每段 SQL 的执行进度,并展示当前执行的 SQL 内容
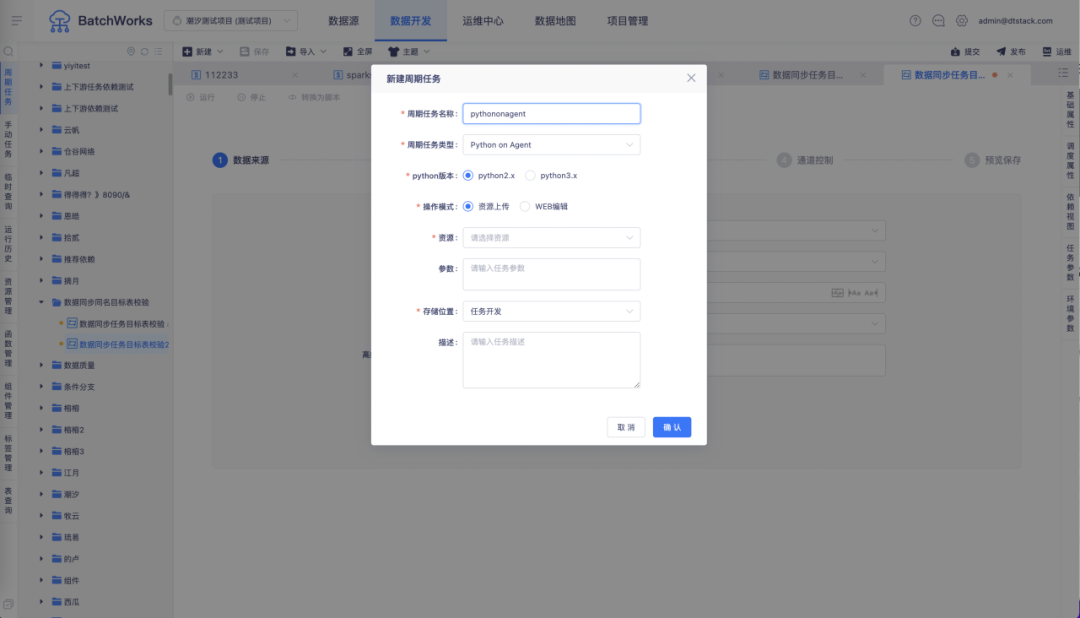
7.新增 Python on Agent 任务
背景:支持 Python on Agent 任务的原因主要有以下三点:
• agent 能跑的任务更多
• on yarn 查询速率太慢了
• yarn 上跑 python 需要手动上传很多包,影响效率
新增功能说明:支持新建 Python on Agent 任务,Python on Agent 任务将独立在控制台配置的节点上运行,不会占用 yarn 的资源。
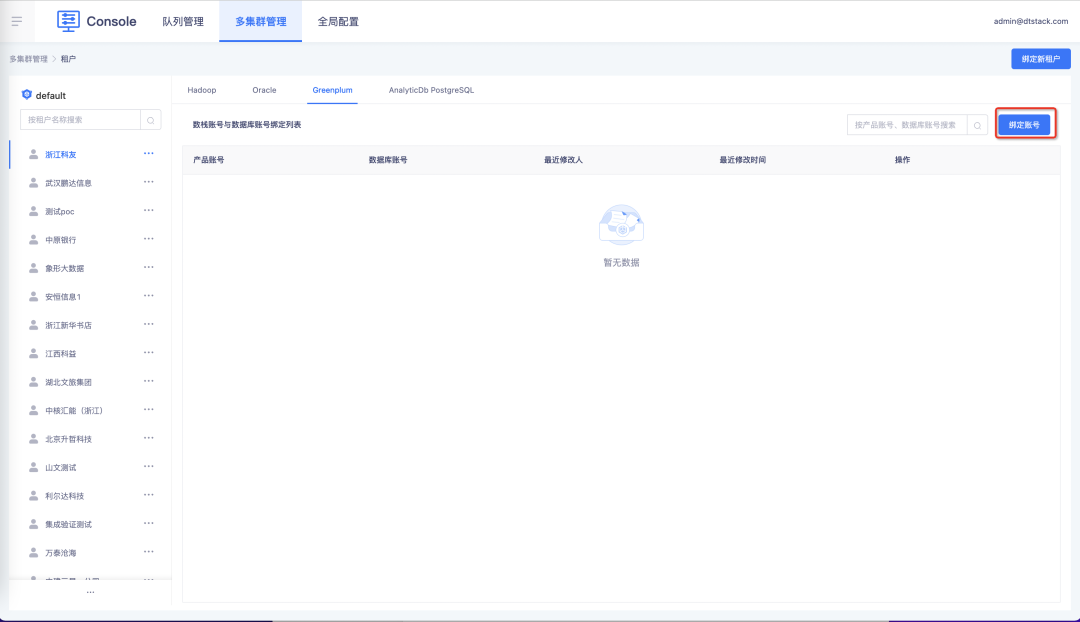
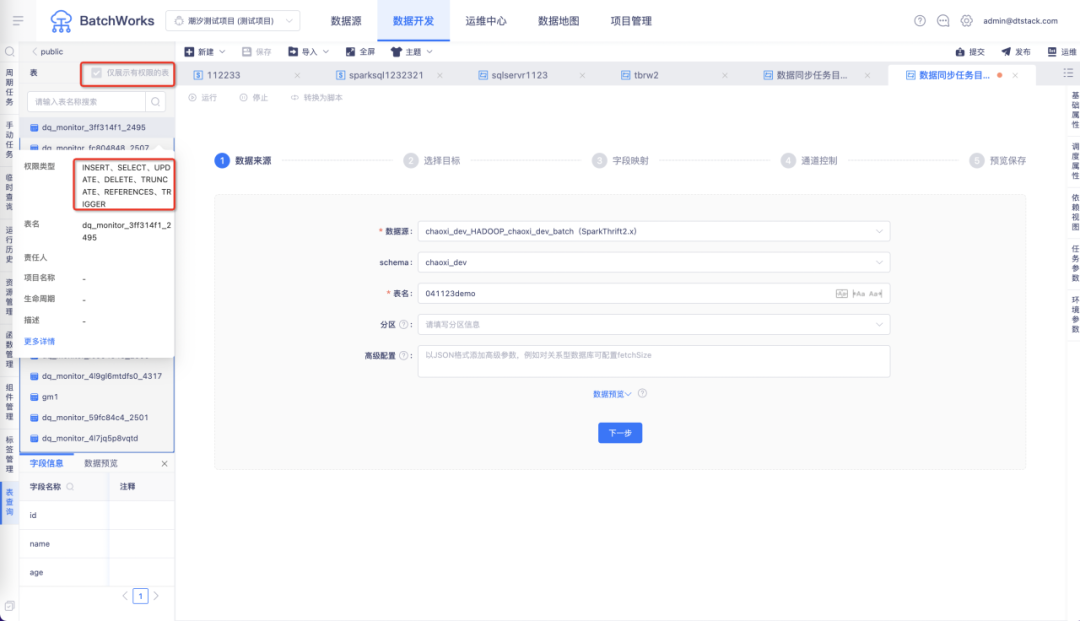
8.表查询中的 GP 数据源,除了显示集群下所有表,还支持仅显示当前用户有权限的表
背景:目前 RDB 数据源,在离线项目中的表权限是通过控制台绑定的集群数据库地址控制的,所有角色和用户拥有的权限都一样,无法做区分。
新增功能说明:
• 控制台支持按用户去绑定 GP 数据库账号
• 离线新增「仅展示有权限的表」按钮,用户可查看绑定的数据库账号下有权限的表
• 表查询中支持查看权限范围,例如 Select、Insert 等
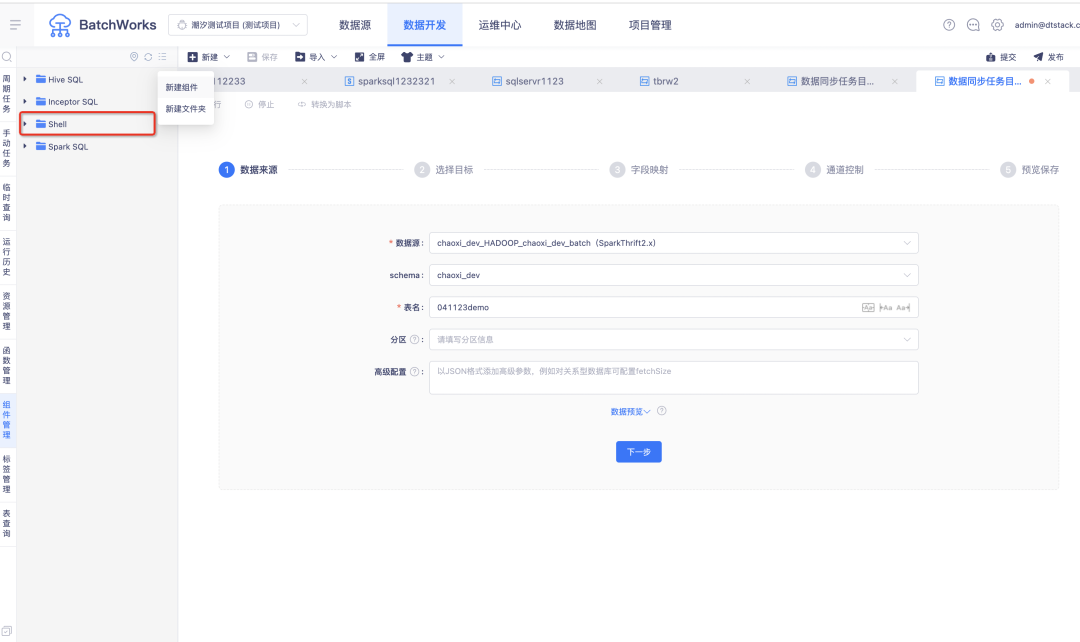
9.新增 Shell 组件模版
10.开启严格模式下的数据同步问题解决
背景:如果平台单独开启了严格模式,平台的 HiveSQL 中会要求指定分区,否则运行会报错。但是,如果当前集群已经对接了数据安全,并且平台的数据同步任务是通过 explain 语句来评估当前查询用户的权限,如果实际用户没有分区字段的查询条件,数据同步任务也会因为没有分区字段的查询条件而报错。
Hive SQL 报错客户可以理解,因为自己开启了严格模式,但是当对接数据安全后的数据同步任务报错,这个其实是不符合逻辑的。
新增功能说明:新增了一个配置项。如果客户是严格模式且关闭了 web 层权限管控(对接数据安全/ranger),可以将这个配置项打开,则不会报错。
11.数据同步支持源表为空校验
背景:数据同步过程中,如果源表为空,则会向目标表写入空数据。在某些客户的场景下,这样可能是合理的;但是在另一些客户的场景下,源表可能是业务方的表,数据同步过程中并不清楚源表为空,也不希望源表的空数据去向目标表写入。
新增功能说明:
数据来源高级配置中新增高级参数「checkTableEmpty」。
若为“true”,数据同步任务的临时运行/周期实例运行/补数据实例运行/手动实例运行前检查源表是否为空,如果为空则实例状态为提交失败(临时运行为运行失败)。若任务配置了告警,则告警中会包含失败原因“任务已开启源表为空不运行的校验,源表${表名称}为空”。
若为“false”,数据同步任务的临时运行/周期实例运行/补数据实例运行/手动实例运行前源表为空时,任务正常运行。
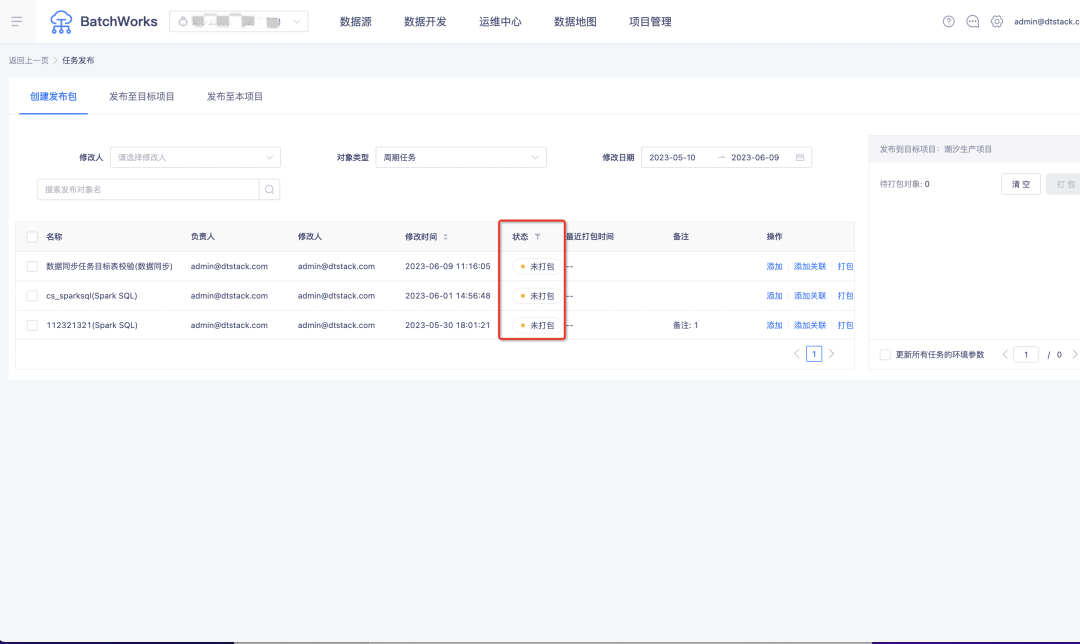
12.新增发布状态
背景:用户无法区分发布页面的对象是否已经打包发布过,可能会造成部分任务重复发布,导致数据覆盖。
新增功能说明:发布页面增加了「状态」字段,包含「已打包」和「未打包」两种状态,重新提交的「周期任务」「手动任务」等对象,状态会变为「未打包」状态。
13.支持 OushuDB 计算引擎
支持SQL开发、版本回滚、表查询、语法提示、函数管理、存储过程管理、血缘解析、组件等功能。
14.支持 GitLab 代码仓库同步
背景:许多客户存在很多存量的代码,但是没有一种方便快捷的方式进行迁移。离线支持了 GitLab 代码仓库的拉取和推送后,客户可以基于 GitLab 进行代码迁移和代码管理。
新增功能说明:支持通过账号密码或是个人访问令牌的方式访问远端 GIt 仓库,可以从项目层面或任务层面进行代码的拉取和推送。
功能优化
1.数据预览全局管控优化
背景:之前在数据源中心做了数据预览管控的功能,可以针对单个数据源或全局进行数据预览功能的管控。但之前仅管控到数据同步的数据预览,离线产品需要进行优化,实现管控到表查询和数据地图的数据预览。
体验优化说明:meta 数据源根据数据源中心的预览功能,实现了管控到离线产品的数据同步、表查询、数据地图的数据预览等功能。
2.所有 SQL 任务的默认运行方式调整为整段运行
Hive SQL、Spark SQL、Greenplum SQL、GaussDB SQL、Oracle SQL、TiDB SQL、Trino SQL、MySQL、SQL Server、Hana SQL、ADB SQL、HashData SQL、StarRocks SQL、Inceptor SQL、Impala SQL 所有 SQL 默认运行方式调整为整段运行。
3.临时运行时记录脏数据
临时运行产生的脏数据表也需要记录在脏数据管理中,并且对各种情况的脏数据表分区命名进行了优化:
• 脏数据临时运行分区的命名规则:task_name=任务ID_test_instance/time=时间戳
• 脏数据周期实例分区的命名规则:task_name=任务ID_scheduled_instance/time=时间戳
• 脏数据手动实例分区的命名规则:task_name=任务ID_manual_instance/time=时间戳
脏数据补数据实例分区的命名规则:task_name=任务ID_temporary_instance/time=时间戳
4.表查询和语法提示范围优化
离线开发中的表查询和语法提示范围优化为资产元数据管理中所有的表(包含底层同步到资产的非 meta schema 的表)。
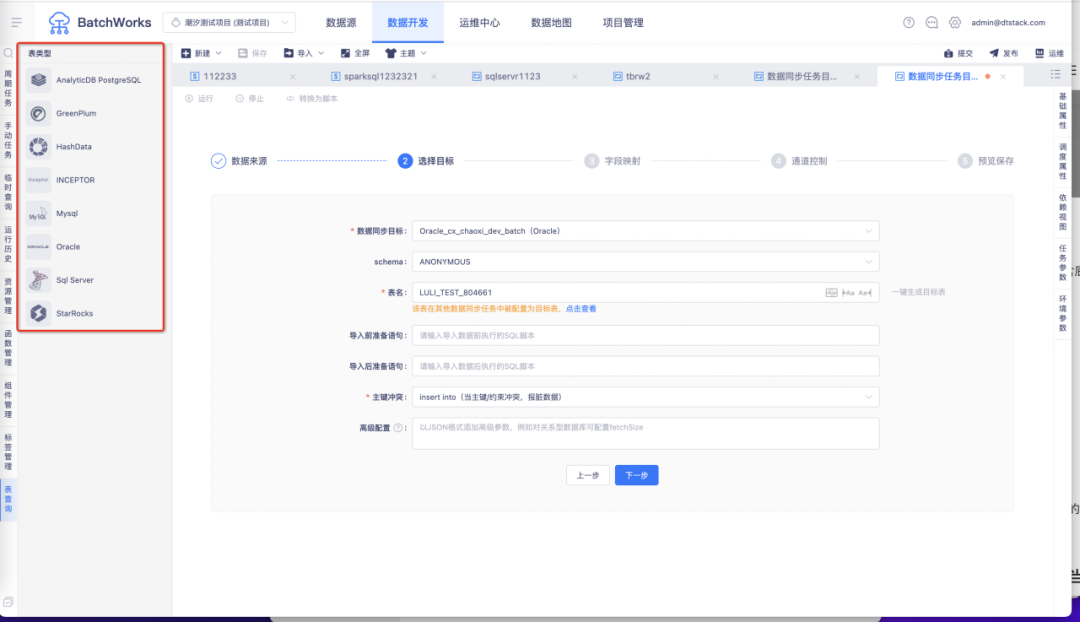
5.一键生成目标表功能优化
背景:目前我们在进行一键建表功能需求设计的时候,通常使用 varchar、string 等通用类型来覆盖所有字段类型,如果客户有需求自行调整。但是实际上客户的场景是复杂的,还涉及到数据精度等问题。因此我们在这个版本对常用数据源之间的字段映射关系做了梳理修改,尽量让客户使用一键建表功能时能直接使用,无需再进行调整。
体验优化说明:RDB->Hive,Hive->RDB,RDB->HANA,HANA->RDB,RDB->ADB,RDB->Doris 等数据同步中的一键生成目标表功能,支持字段根据映射关系匹配。
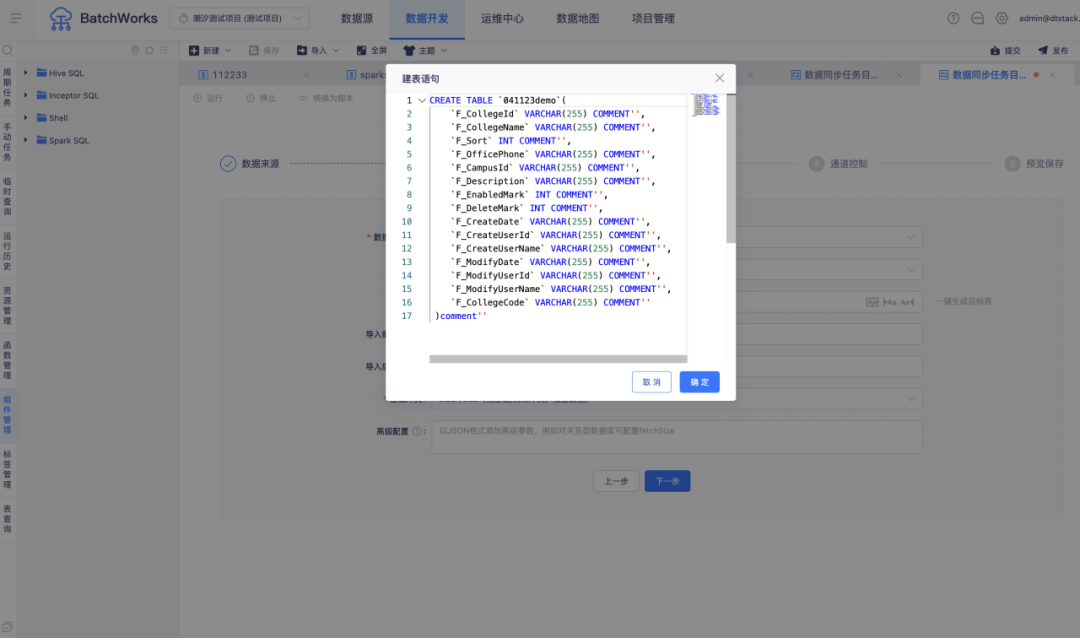
6.切分键填写优化
背景:「源表切分键」的填写入口在「数据来源」时,客户经常会漏填,并在「通道控制」页面选择了大于1的并发数,在执行任务后才报错,客户需要再去添加切分键,产品体验差,效率低。
体验优化说明:将「源表切分键」填写入口从「数据来源」移至「通道控制」页面;新增「开启并发」按钮,开启后支持填写源表切分键。
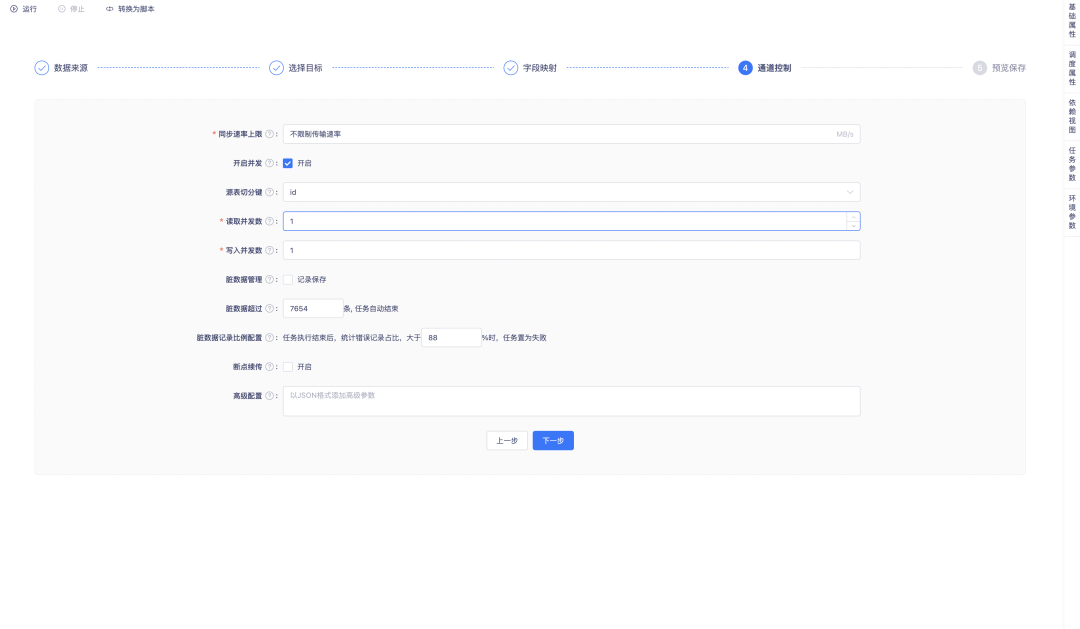
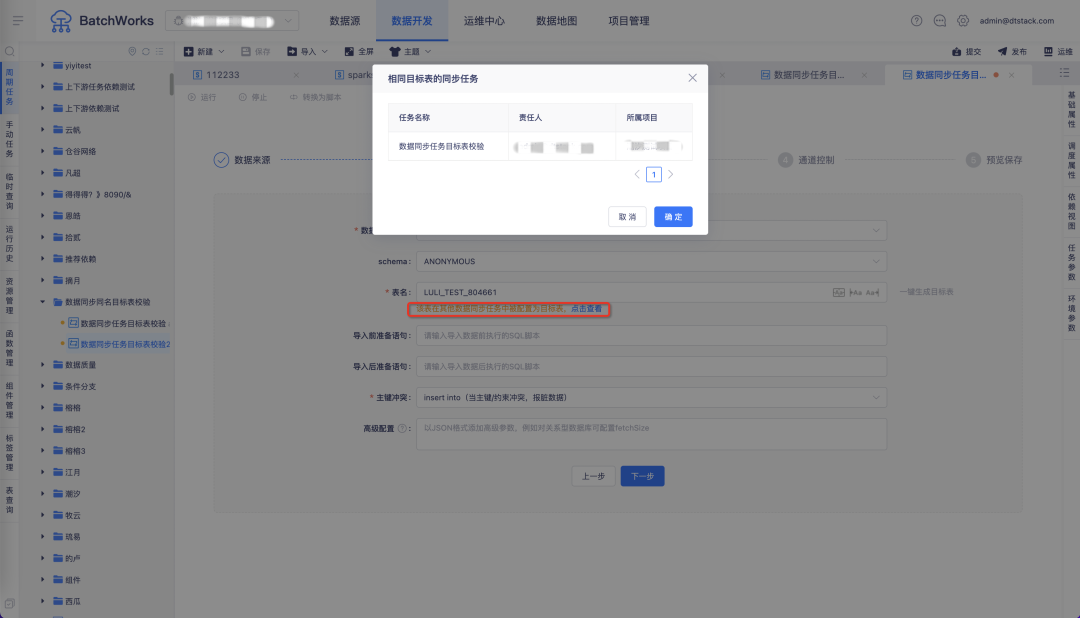
7.同步任务中选择和其他同步任务相同的目标表时,会进行提示
背景:在一般的 ETL 场景中,一张表只会在一个数据同步中作为目标表存在,如果在多个同步任务中配置了同一个目标表,很有可能会造成数据丢失、数据覆盖等问题。
体验优化说明:在数据同步选择目标表时,若选择的目标表在当前租户下的某些数据同步任务中已经作为目标表存在,则会进行提示,并告知任务名称、任务责任人和所属项目。
8.置成功、重跑、杀任务生效范围调整
背景:目前置成功限制了特定状态下的实例才可操作,实际置成功的主要目的是当依赖链路中出现了暂时无法快速修复的阻塞实例时,在某些情况下其下游实例如果对这个或这些实例不是强依赖并且不能延迟时,希望平台提供一种强制或者临时处理方式从而让下游可以继续跑起来。
导致这种阻塞的情况不止现在的失败、取消,而是包含除“成功”外的所有状态,因此,能够支持置成功的实例为除“成功”状态之外的所有状态的实例;重跑同理,更加不用关心实例状态。
体验优化说明:
• 所有状态的实例支持「置成功」
• 除运行中外所有状态的实例支持「重跑」
• 等待提交、提交中、等待运行、正在运行、冻结状态的实例支持「杀任务」
9.跨租户/项目/产品的实例支持在离线运维中心运维
背景:补数据链路中若存在指标实例,指标实例出现失败的情况,目前无法实现重跑操作。因为离线内暂不支持对其他产品实例的运维,导致修复处理非常麻烦。
体验优化说明:跨租户/项目/产品的实例支持在离线运维中心展示,支持「紧急去依赖」「终止」「置成功」「重跑」等操作。
10.实例置成功操作时,若绑定有质量任务,质量任务实例不执行
背景:置成功一般发生在当前任务暂时无法运行成功,但是下游要正常执行下去的情况。这种情况下当前任务一定存在问题,如果继续走质量校验没有意义。
体验优化说明:当对离线任务实例置成功时,如果有质量任务绑定,质量任务实例不执行。
11.实例依赖视图优化
背景:任务依赖视图和实例依赖视图应该有所区分。任务依赖视图展示任务间依赖关系;实例依赖视图应该展示当前实例的依赖视图,包含实例间依赖和跨周期依赖。这样有助于用户全链路查看实例依赖关系,理解运行流程。
体验优化说明:运维中心实例依赖视图,展示当前实例的跨周期依赖实例视图。
实时开发平台
新增功能更新
1.FlinkSQL 开发,Kafka ChunJun-json 支持自动映射
上个迭代已经支持了 OGG-JSON 的自动映射,本次迭代支持了实时平台自身采集工具打到 Kafka 的格式(ChunJun-json)。
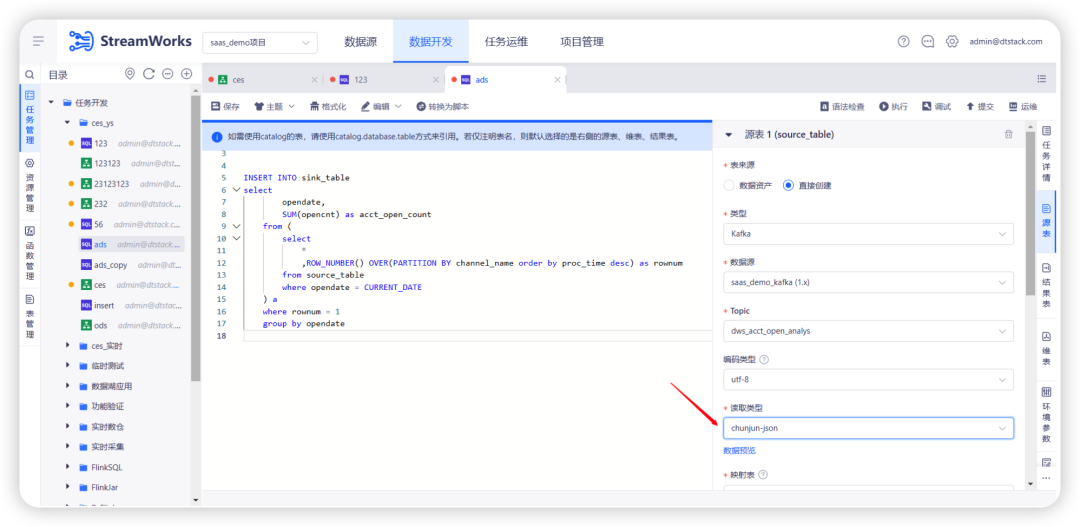
2.Kafka 读取类型新增 Raw Format
如果你的 Kafka 中具有原始日志数据,并希望使用 Flink SQL 读取和分析此类数据时,需要用到 raw format。如:
47.29.201.179 - - [28/Feb/2019:13:17:10 +0000] "GET /?p=1 HTTP/2.0" 200 5316 "https://domain.com/?p=1" "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36" "2.75"
如果读取类型使用 raw format,请避免使用 upsert-kafka。因为 raw format 会将 null 值编码成 byte[ ] 类型的 null,而在 upsert-kafka 中会将 null 视为删除值的操作。
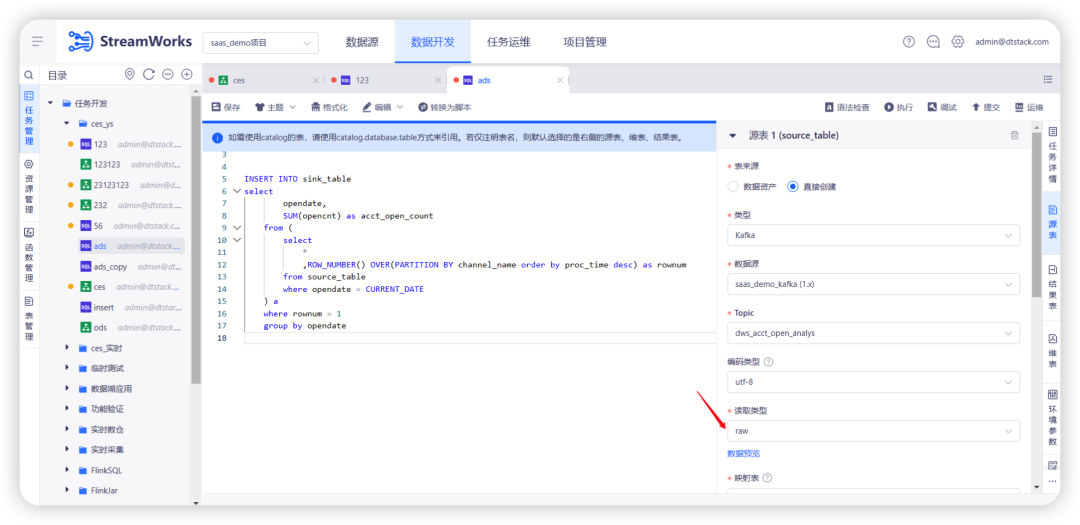
3.FlinkSQL 维表、结果表新增 Hyperbase 数据源
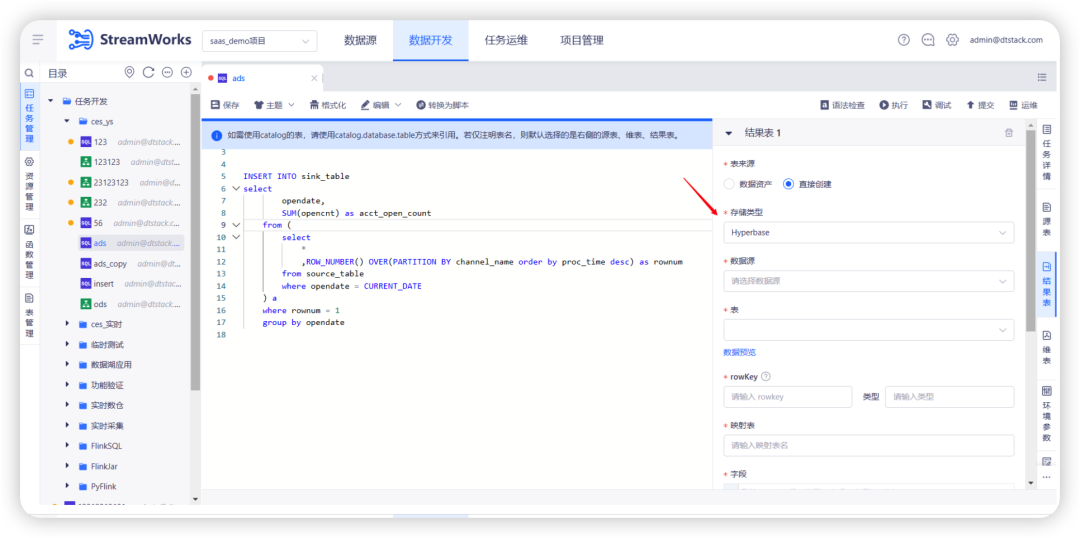
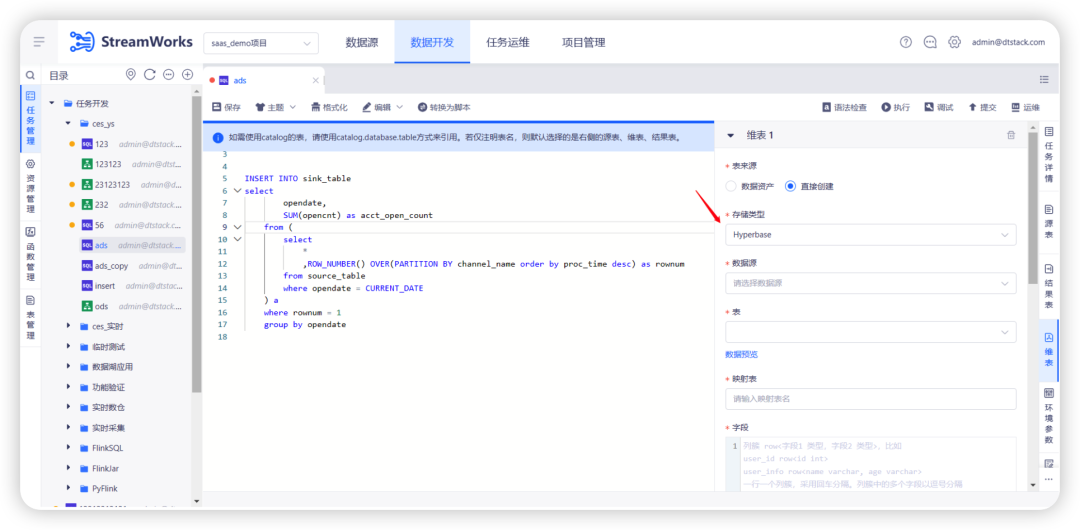
4.Flink1.12 中重构 PGWAL 插件
背景:Flink1.10 已支持过 PGWal 插件,之前插件迁移1.12的时候,漏测了 PGWal,目前在 Flink1.12 上测试发现存在比较大的问题。
新增功能说明:
5.Hive Catalog 支持开启 keberos 认证;DT Catalog 中的 Flink 映射表,源表支持开启 keberos 认证
表管理处的 Kerberos 认证,分为两种程度:
• Catalog 的认证:此处是通过控制台的 Flink 组件维护 krb 文件。(如果 hive catalog 的 hms 也自带 krb 认证文件,平台不做校验)
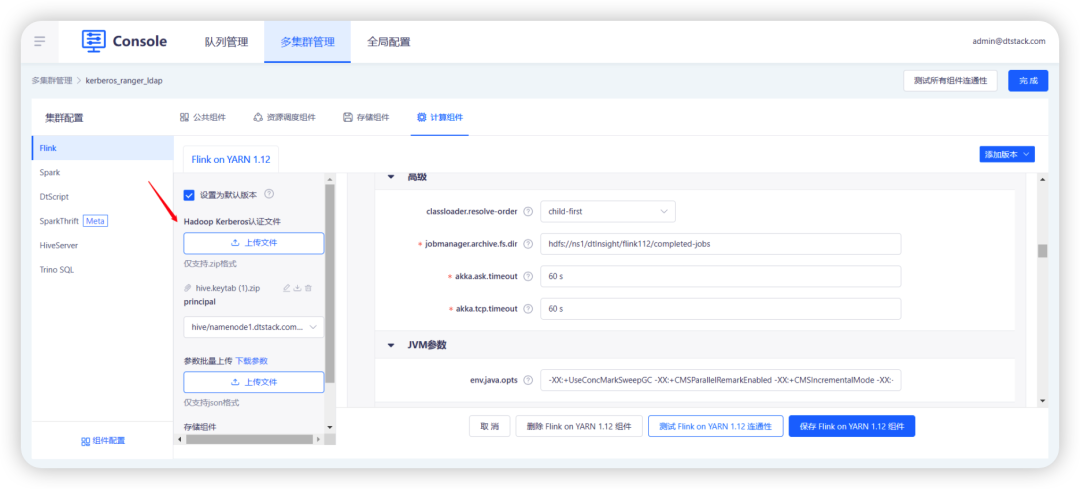
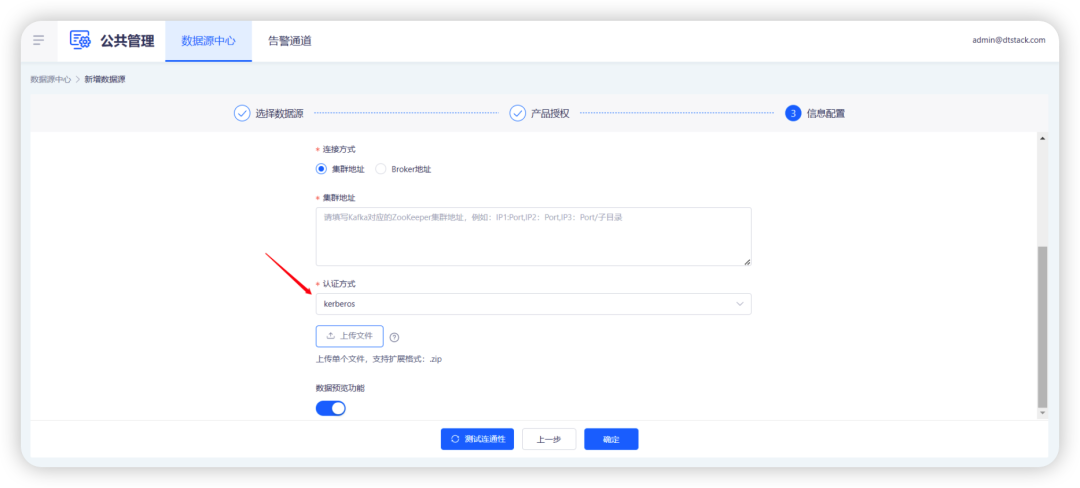
• Flink 映射表的认证:支持 Flink 映射表的源头,如 kafka/hbase 数据源开启 krb 认证。(用户需要保障 Flink 开启的 krb 认证和表数据源的 krb 一致,不然任务可能会运行失败)
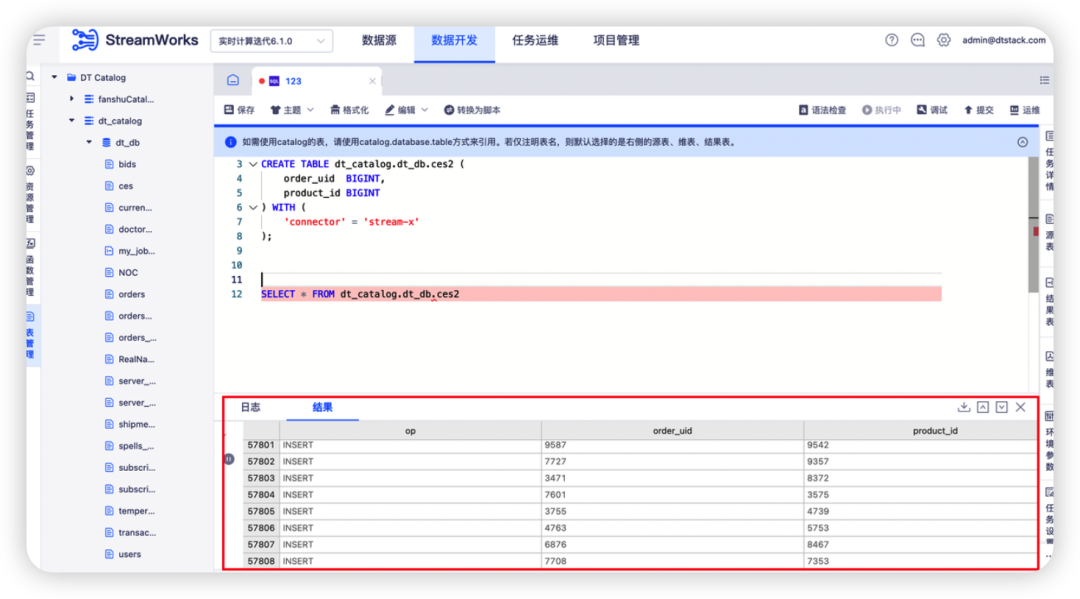
6.IDE 执行新增 Select 在线查询能力
背景:之前数开人员排错想要查看代码逻辑,需要将结果打印到日志中查看,操作成本较高。
新增功能说明:在 IDE 中可以对平台中的 DT+hive catalog 表进行 select 查询、执行 DDL 语句,结果在控制台进行查看,对于已停止的任务可以下载导出 csv 文件数据。
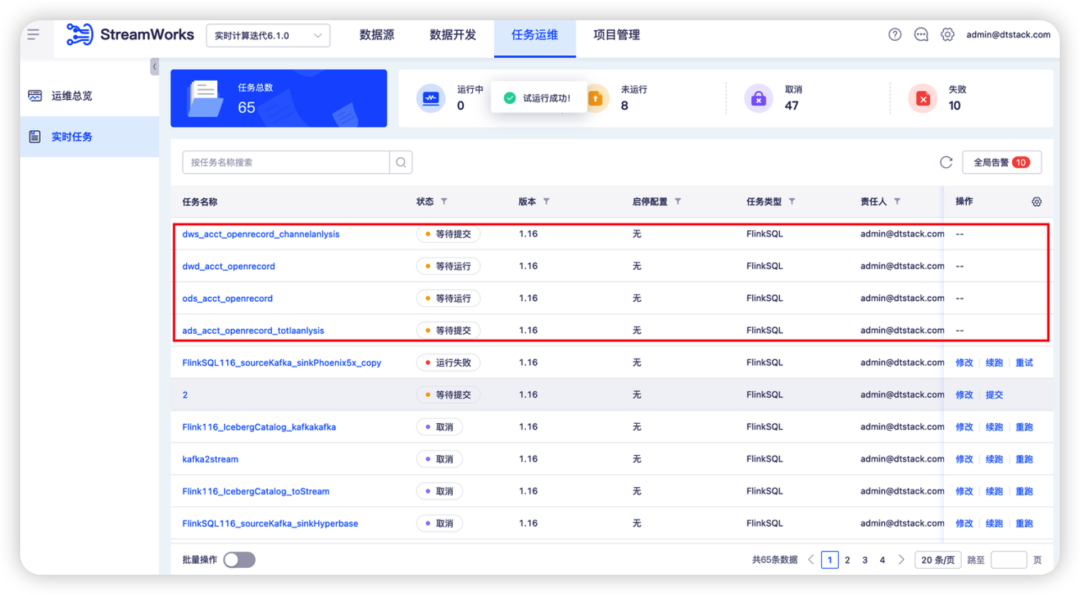
7.新增实时数仓 demo,支持自动造数据,运行全链路任务
背景:给客户演示产品时需要配置数据源等信息,门槛较高。
新增功能说明:在演示产品时点一点按钮就能自动造数据,并运行起全链路任务。点击试运行后平台将在任务运维自动生成并提交四个任务,在一小时后自动下线(点击取消试运行直接删除下线),这些任务不支持在任务运维界面进行操作。
8.新增代码模板中心,支持使用系统内置模板以及创建自定义模板
实时平台内置各种 FlinkSQL 场景的开发模版,方便开发理解、上手,也可以根据业务自己创建自定义模版,提高开发效率,模版支持直接引用到自己的任务上做调整。
9.其他新增功能
• 引擎版本:实时采集、FlinkSQL、Flink 和 PyFlink 任务的引擎选择支持 Flink1.16 版本
• 产品 logo:产品 logo 和名称从控制台的配置内容读取,不再固定写死
功能优化
1.Flink 版本查询接口直接获取控制台信息,平台不维护
实时平台几个 Flink 版本选择的地方,直接查询控制台维护的数据,平台自身不再写死版本号。(如果控制台只添加了1.12,实时平台只显示1.12;如果控制台添加了1.12和1.10,实时平台则显示两种)
2.【实时采集】向导模式中将前端的配置项抽象化
背景:如果要支持向导模式,每新增一个数据源,前端都需要开发一套配置项。用户/定开团队开发的自定义 connector,如果不进行前端定开,只能在脚本模式中使用。
体验优化说明:在向导模式中将前端配置项抽象化,后端开发完自定义 connector+SQL 刷入前端配置项+少量/甚至没有前端开发工作,完成一个自定义 connector 的开发应用。
3.其他功能优化
• Phoenix5.x:Flink1.12 版本支持 phoenix5.x sink 的选择
• Kafka 集群:移除集群管理功能模块,kafka 管理模块后续的定位就是做 Topic 的增删改查,不会提供集群管理相关的能力
• SDK 接口:新增根据任务查询 sqltext 的接口;新增根据项目标识获取项目信息的接口
数据资产平台
新增功能更新
1.告警通道中的自定义告警通道支持显示多通道
背景:业务中心配置多个自定义告警通道时资产平台只展示一个,但实际发送告警时将对每个自定义告警通道进行告警信息发送,存在告警信息发送冗余,且与其他子产品的逻辑不一致。
新增功能说明:对于自定义告警通道像其他子产品一样显示所有告警通道,且可选择一个或多个进行告警信息的发送,修改范围包括元数据订阅、质量规则等所有涉及告警配置的位置。
2.数据模型支持 inceptor 建表
当前租户的资产中存在自动引入的 inceptor meta 数据源时,可在数据模型--规范建表模块进行 Inceptor 建表,支持配置表的基础信息和表结构,其中配置表结构时新增支持对分桶字段、分桶数配置。
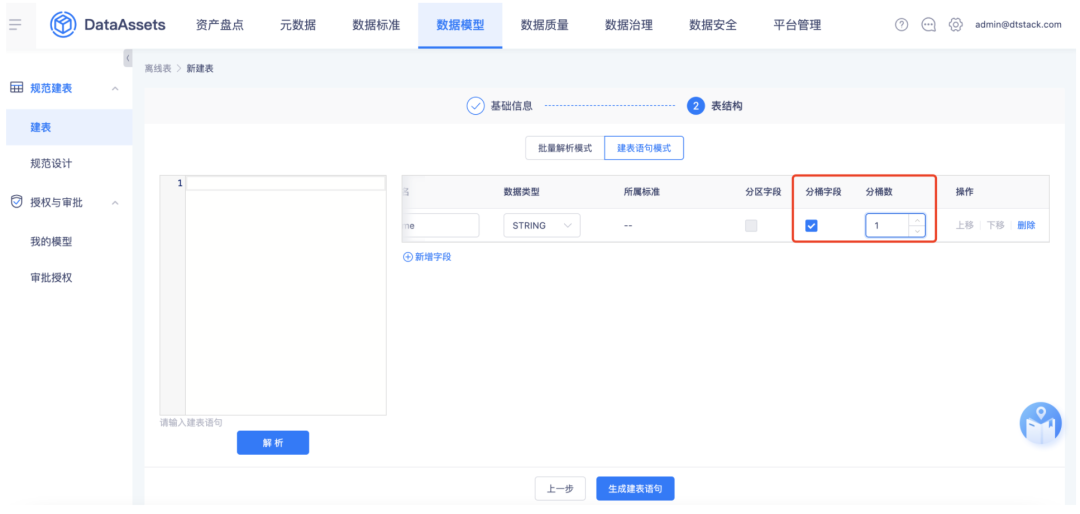
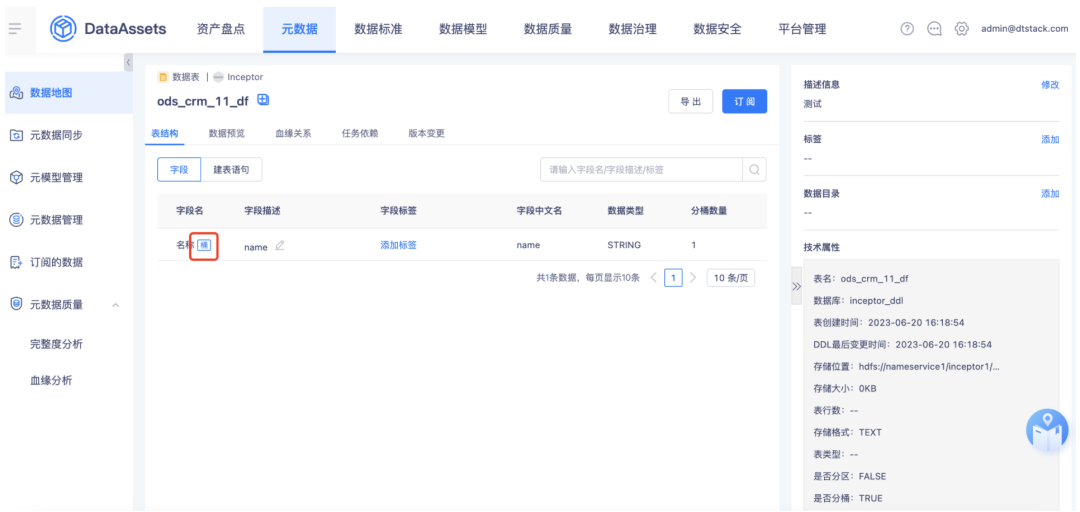
若新建表已完成审批,在元数据查看时针对分桶字段增加分桶标识展示。
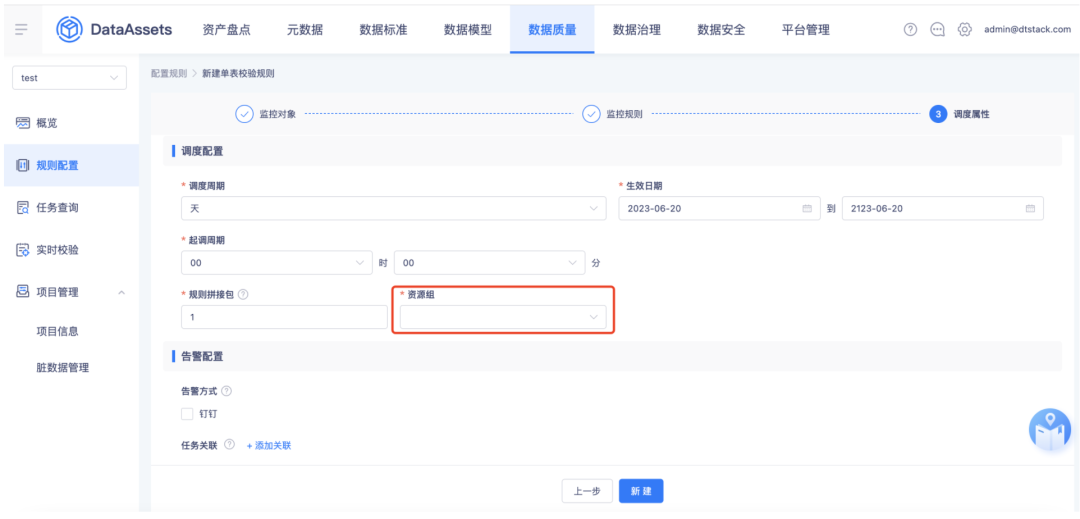
3.【数据质量】质量规则对接资源组
在质量规则中,单表校验和多表校验中跑在 yarn 上的任务,以及实时校验任务的调度属性弹窗中新增资源组的必选项。
4.其他新增功能
• OushuDB 支持元数据同步和查看:离线对接了 OushuDB 引擎生成的 meta schema,资产支持自动引入,并支持元数据的同步和查看。
• 数据源:新增数据源支持 Hive_MRS、Trin
• 规范建表支持 AnalyticDB PostgreSQL 表
功能优化
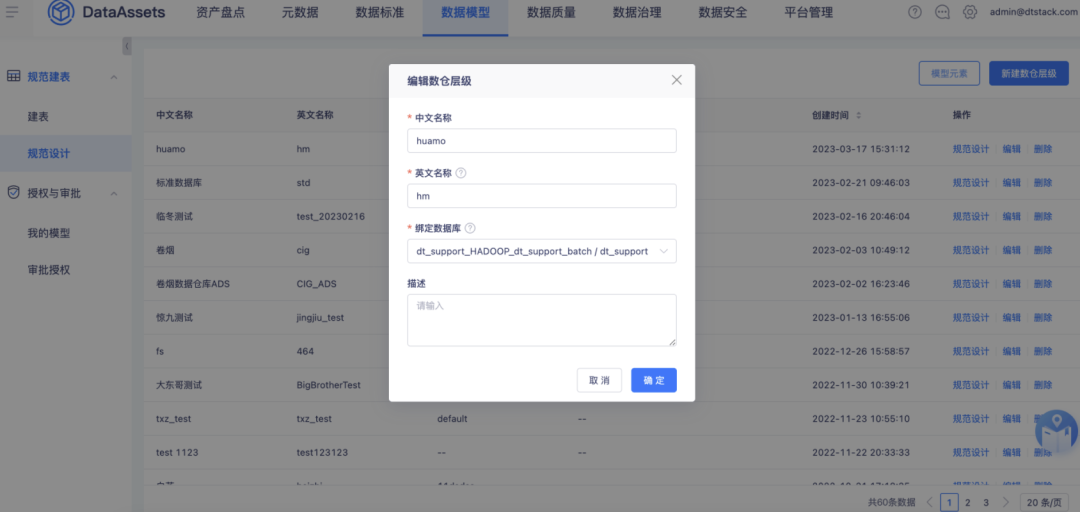
1.规范建表数仓层级绑定数据库逻辑优化
背景:一个数仓层级只能绑一个库,实际用户在数仓时可能存在跨库多主题或者多主题单库,需要数仓层级与库的绑定关系更为灵活。
体验优化说明:数仓层级与库不再与数据库配置绑定关系,规范建表时可在选择数仓层级后另外选择数据源。
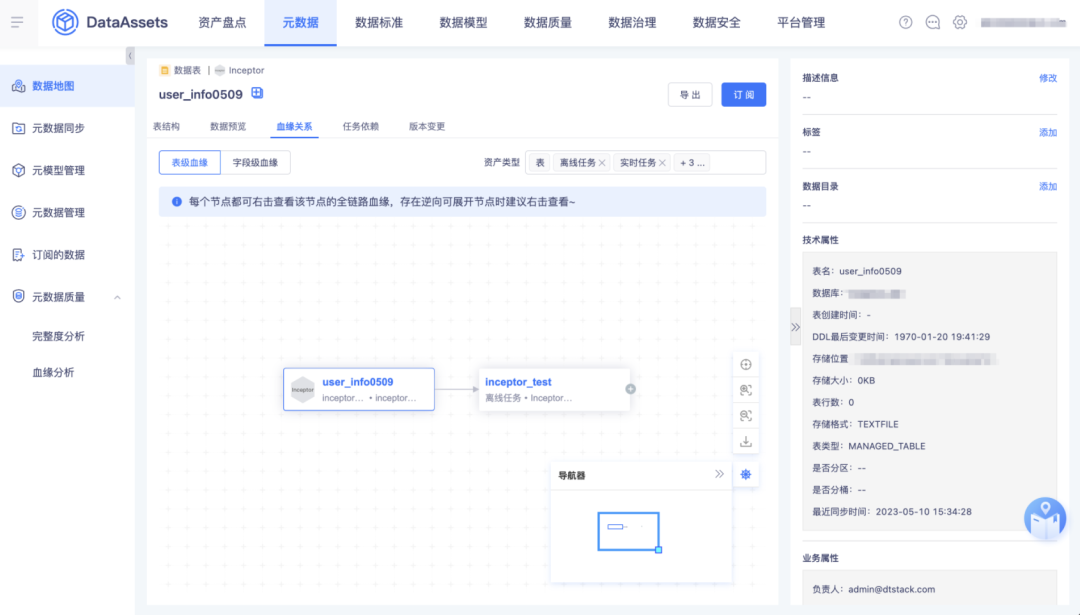
2.Inceptor 表支持表血缘
3.表生命周期到期后处理方式调整
背景:资产数据模型和质量的脏数据表生命周期到期逻辑不一致,资产数据模型在表生命周期到期后将保存元数据信息,导致无用元数据信息不断累积,元数据查询性能受到影响;质量的脏数据表在生命周期到期后则会删除元数据信息,仅 Hive 表支持了生命周期。
体验优化说明:
资产数据模型中的表生命周期到期后也删除元数据信息,即最后统一为:
例如将表生命周期设置为10天,则:
• 对于非分区表,当前日期 - 最后一次数据修改日期 > 10天后,平台将自动删除该表
• 对于分区表,当前日期 - 某分区最后一次数据修改日期 > 10天后,平台将自动删除该分区,分区全部删除后表将被删除
另外 Inceptor 表也支持了生命周期设置。
4.资产监听离线 IDE 的 DDL 语句,SQL 解析后元数据变更实时更新在资产数据地图
目前支持的 meta 数据源范围:Hive、AnalyticDB PostgreSQL、TiDB、Inceptor、Hashdata、StarRocks
5.数据地图优化
数据地图查询性能优化:每张表200个字段,200w张表的元数据存储,在数据地图页面查询响应达到5s以内
血缘显示内容优化:血缘中各节点内容包含表名、schema 名称等显示完整
6.其他体验优化
• 离线删除项目后资产自动引入的 meta 数据源将同步删除
• Hive 元数据技术属性增加表类型说明,可标识其为 Iceberg 表或者其他格式的表
• 数据脱敏优化:脱敏方式除覆盖外另支持转义和算法加密,支持对指定人群脱敏/指定人群不脱敏,并支持按用户组进行用户范围选择
• 数据地图迁移后,所有租户下拥有离线产品权限的用户都自动增加资产平台的访客权限
• 支持离线创建项目生成的 Oracle、SQL Server meta 数据源在资产平台的自动授权
• 产品 Logo 可在业务中心统一配置
• 所有下拉框增加 loading 效果,质量校验规则、任务、数据源管理、元数据管理、文件治理的列表筛选框增加模糊搜索
• 数据质量告警的告警top20增加告警时间的显示
• 元数据同步优化:元数据模块中的数据同步功能,在点击列表中的立即同步操作后,在按钮旁边加状态标识,避免重复操作
数据服务平台
新增功能更新
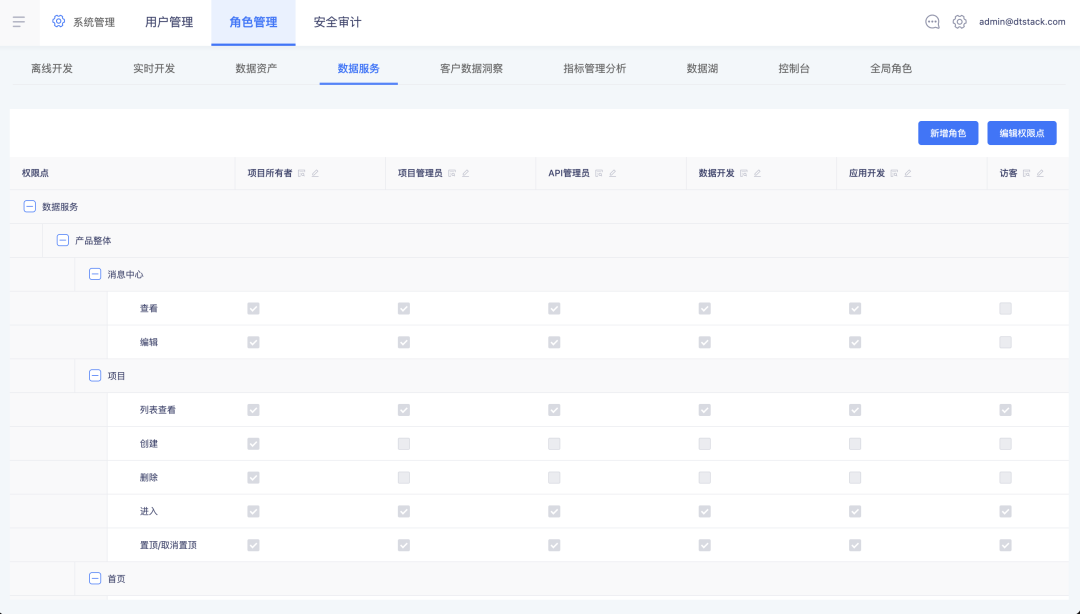
1.支持对接自定义角色
平台角色管理中,admin、租户所有者和租户管理员可在租户层为 API 创建自定义角色(可自由配置角色权限点),此角色创建后会在该租户的每个项目中存在。此外还可修改固定角色,如项目管理员、数据开发等的权限点。
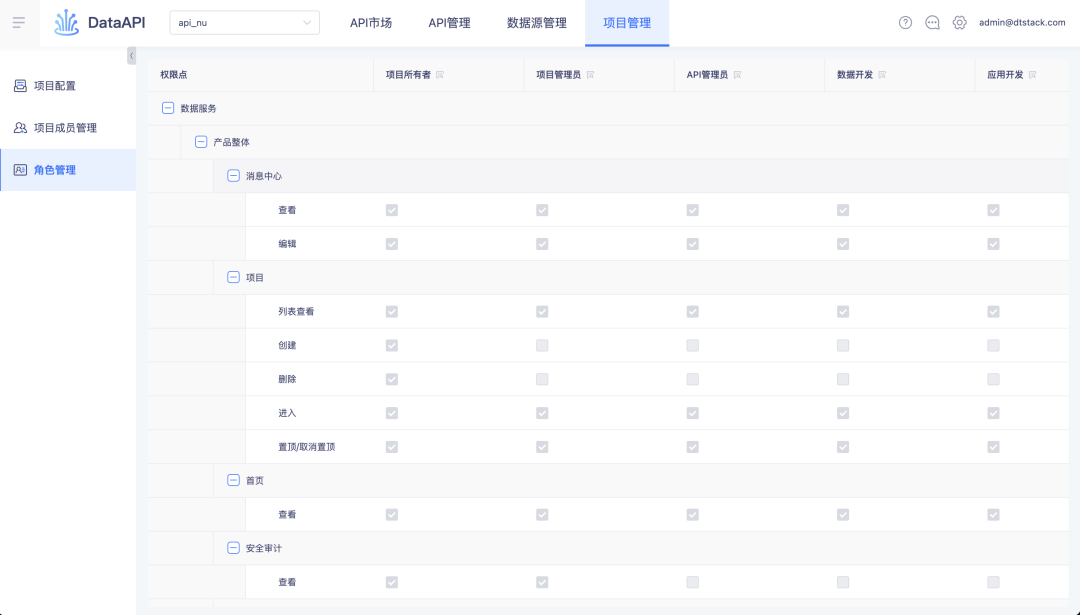
API 内的项目管理-角色管理中展示当前项目中的所有固定角色和自定义角色(仅查看不可编辑)。
2.Python 函数增加支持3.9版本
背景:python 主流版本分为2.x和3.x,数据服务之前仅支持 python2.7 是因为 Jython 执行框架仅支持到2.7版本且无法进行包含c语言的三方库拓展。但是 python2.7 版本较老,大部分客户用 python3.x 较多,且有拓展三方库的需求。
新增功能说明:后续运维部署时默认增加3.9版本,2.7和3.9并存,2.7仍用 Jython 框架,3.9改为 Runtime 框架。通过 Runtime 调用 Python 程序与直接执行 Python 程序的效果是一样的,所以其天然支持任意三方库的依赖,同时可以在 Python 中读取传递的参数,也可以在 Java 中读取到 Python 的执行结果。
另外 api-server 服务增加了一个配置项,这里我们提供的默认环境是没有三方库依赖的,客户可替换为客户环境的 python 可执行文件。
python3.exe.path = /opt/dtstack/DTGateway/Apiserver/python3/bin/python3.9
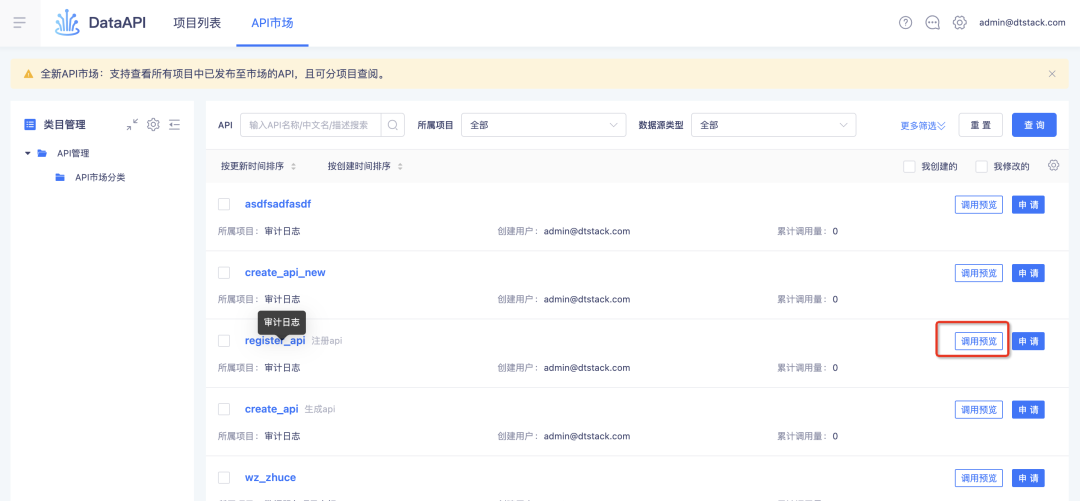
3.API 市场的调用预览增加支持服务编排、注册 API
功能优化
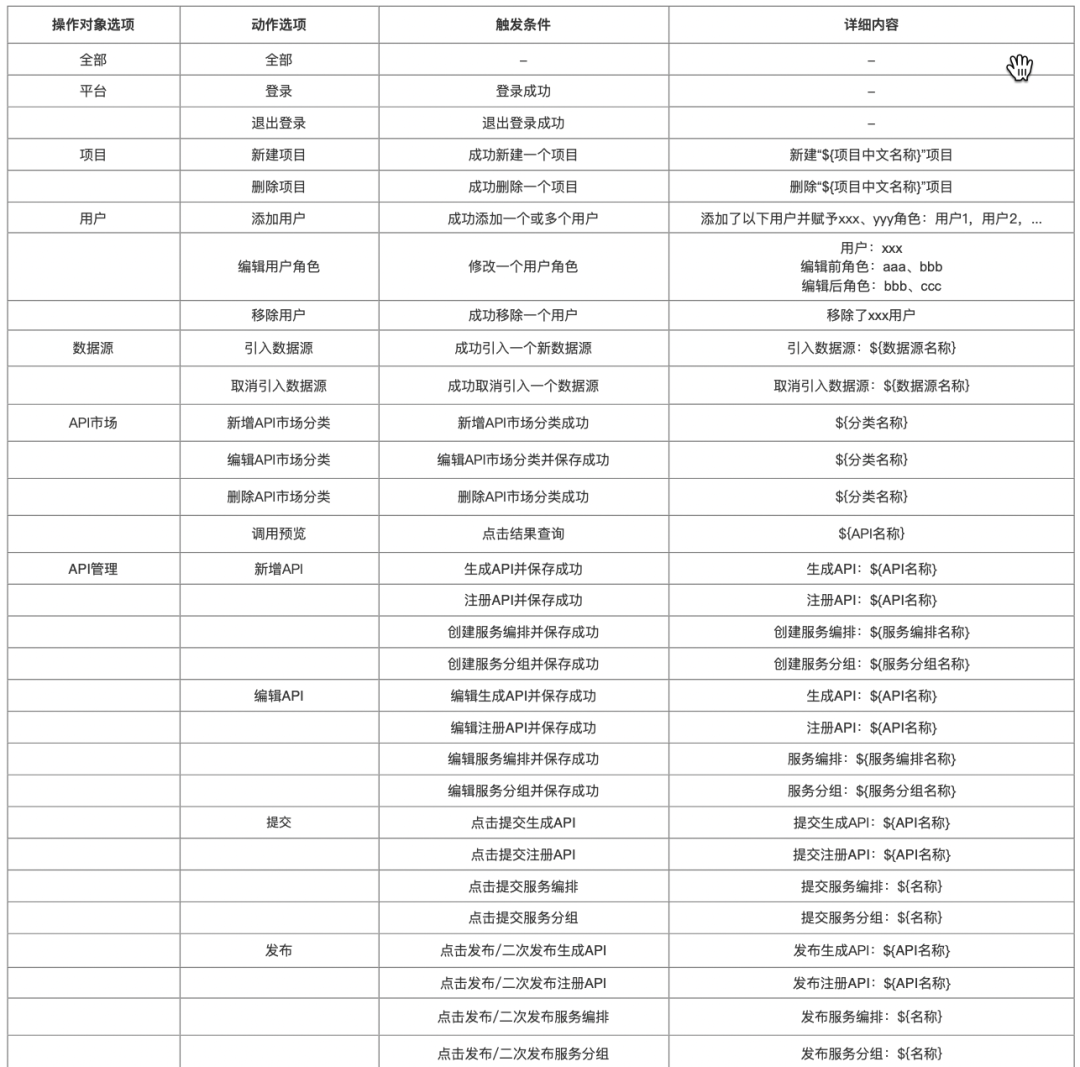
1.审计内容完善
支持了更加完善的关键操作审计,以下为部分:
2.安全组中的ip地址黑白名单校验
背景:同一 API 所选的安全组黑白名单没有做校验,导致同一ip同时出现在一个 API 的安全组白名单和黑名单中。
体验优化说明:API 在配置安全组时会对所选黑白名单进行ip地址是否冲突的校验,如果冲突则无法添加成功;历史已经存在冲突的情况,黑名单将生效。
3.注册 API 返回结果是否带平台默认结构支持配置
背景:目前在数据服务注册的 API 会外面包一层内容,导致注册以后的返回结果与原生 API 不一致。
体验优化说明:后端增加一个配置项,可配置返回结果是否加上我们自己的内容,默认加上。
客户数据洞察平台
新增功能更新
1.产品名称对接业务中心
背景:当前标签产品名称、logo 等信息是系统内置的,不可更改,但客户根据自己实际需求会有需要变更的情况,此时需要我们配合做调整。为提高变更效率,将信息的配置统一对接到业务中心,客户有需要时通过业务中心修改即可。
新增功能说明:
• 通过数栈首页进入「页面配置」界面,更新「客户数据洞察设置」内的配置内容,配置页面见下图:
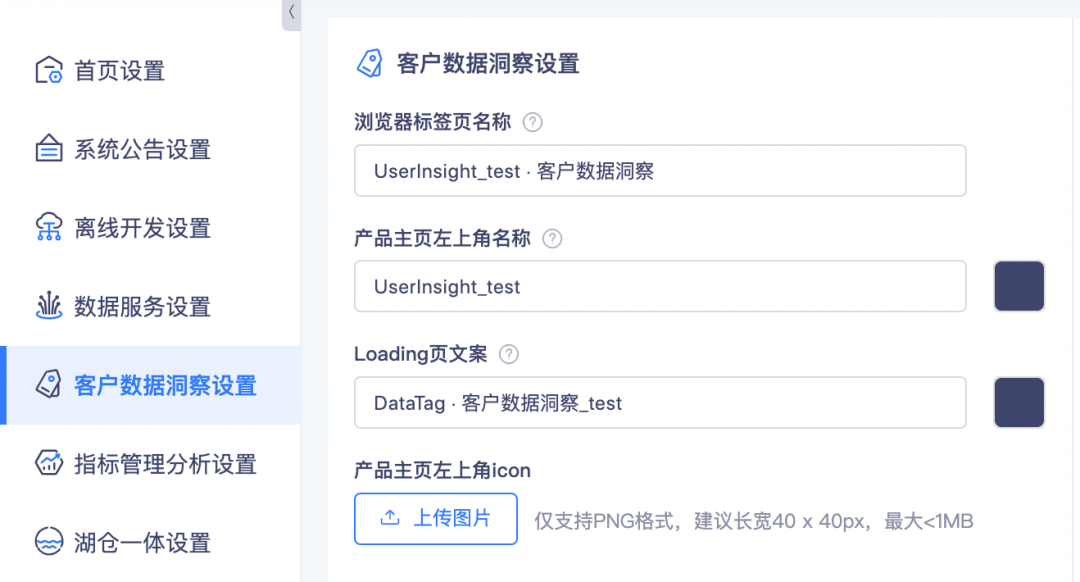
配置生效后,下述页面内容将分别引用上方的特定设置。
(1)产品 loading 页:使用「Loading 页文案」的输入文字、颜色

(2)标签产品项目列表页、系统内所有页面左上角:使用「产品主页左上角名称」的输入文字、颜色,「产品主页左上角 icon」设置的图片

(3)浏览器标签栏:使用「浏览器标签页名称」的输入文字、「产品主页左上角 icon」设置的图片
• 通过数栈首页进入「页面配置」界面,更新「首页设置」内的各功能模块的名称配置内容后,标签内部关于子产品名称的引用,将引用此处设置内容。首页设置内容如下:
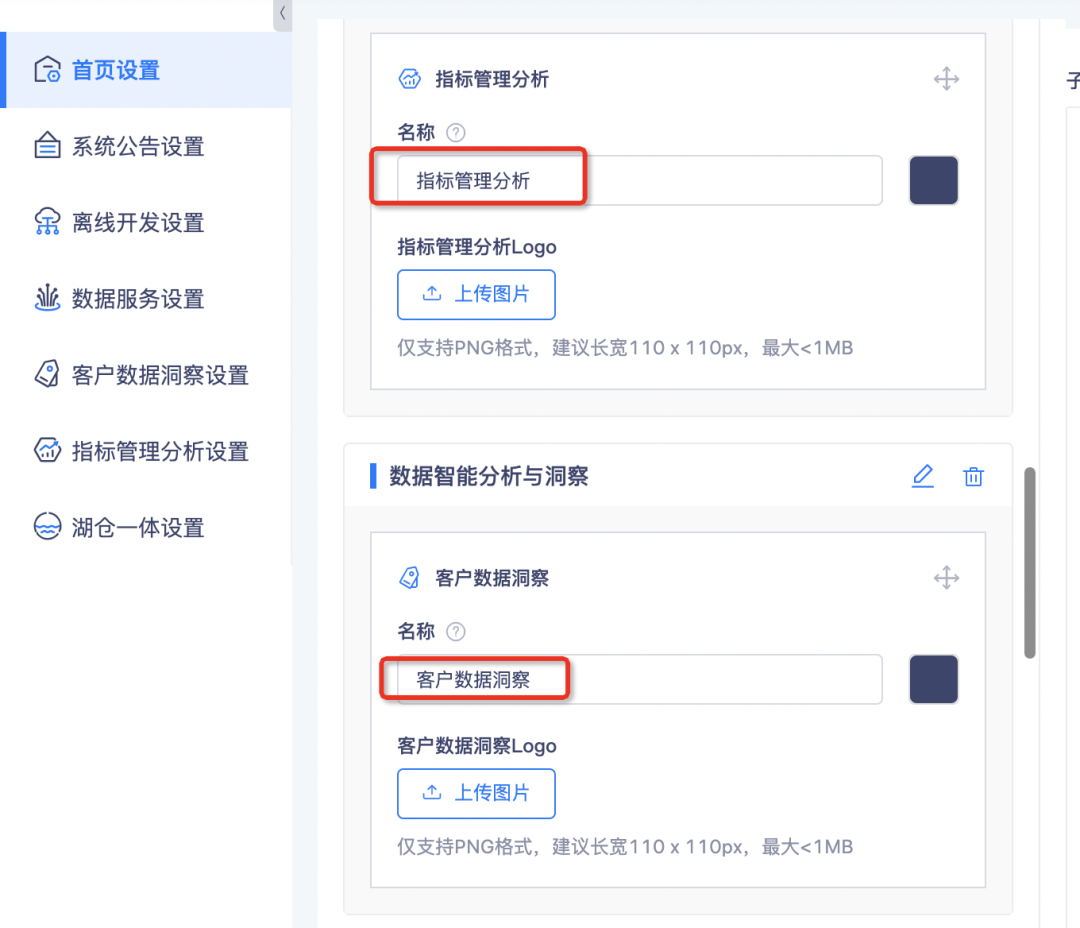
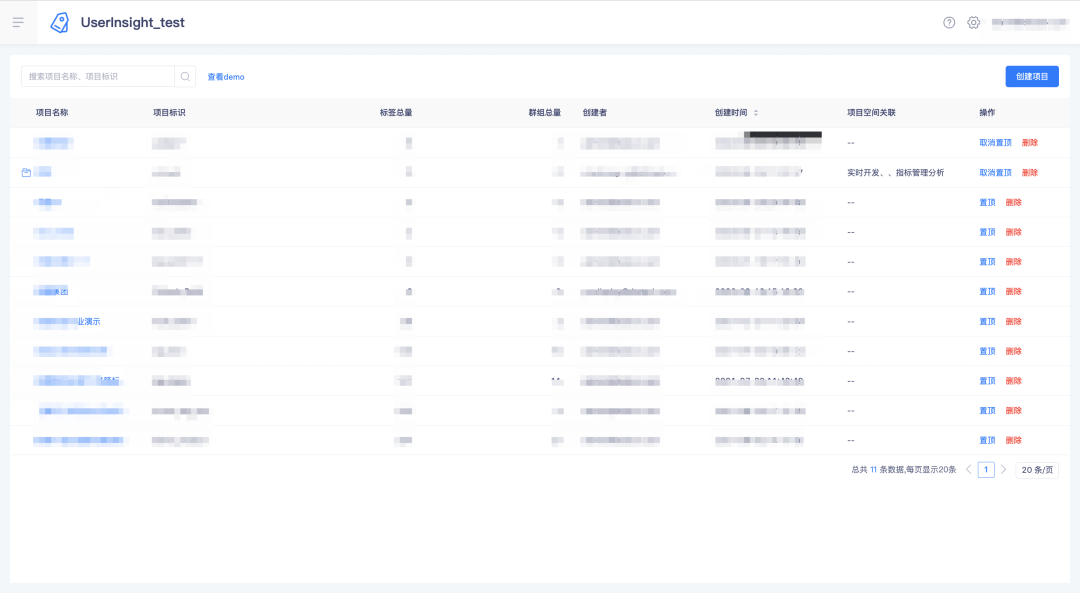
配置生效后,标签产品内部引用位置,如项目列表中的项目空间关联子产品,如下:
2.个体画像支持文件导出
背景:根据标签数据洞察用户特点,需要将数据分享给其他业务人员做报告输出。
新增功能说明:进入个体画像页面,通过模糊/精确匹配显示搜索结果,点击「画像导出」可导出所有搜索结果。
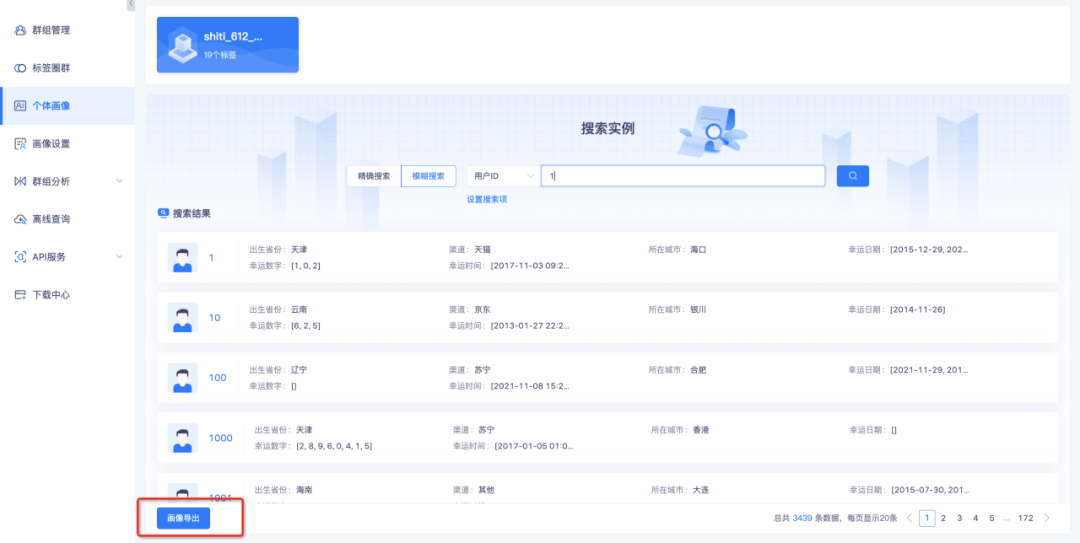
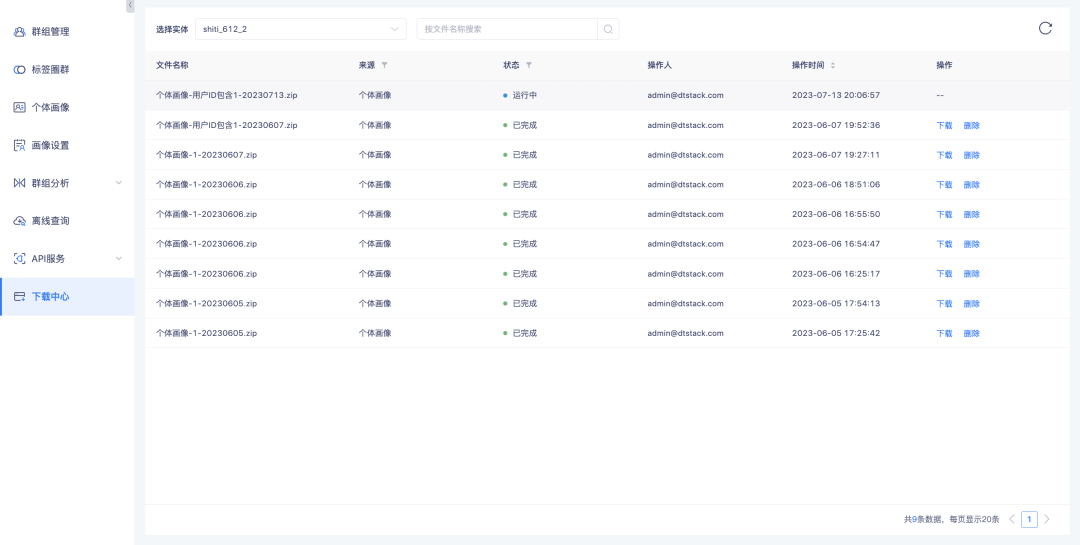
导出结果将以PDF格式放至下载中心,可前往下载中心进行文件下载。若搜索结果大于2万个,将根据用户输入的单文件存储数量将数据分别存于多个PDF文件中,并压缩成zip文件供用户下载。
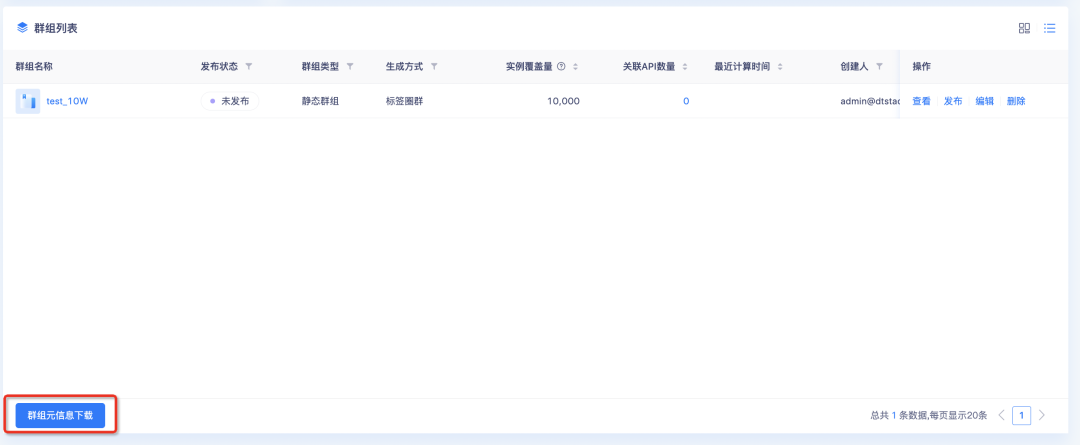
3.群组列表支持导出元数据信息
背景:梳理群组数量状态,将数据分享给其他业务人员做报告输出。
新增功能说明:进入群组管理页面,点击「群组元信息下载」可导出所有筛选后结果。导出结果将以CSV格式放至下载中心,可前往下载中心进行文件下载。
功能优化
1.【SQL优化】提升查询效率
背景:Hive 表创建 SQL 中,涉及到 $partitions 参数引用,Trino 会进行全表扫描,从而占用大量内存空间。在现有功能上,需要缩短实体表的生命周期才能保证任务正常运行,需要对 SQL 进行优化从而实现在表生命周期长的情况下,任务依然可以正常运行。
体验优化说明:
Trino SQL 中涉及 $partitions 的地方调整为子查询,包括标签加工任务、标签圈群、群组任务。
2.支持查询项目所在 schema 下的所有表、视图
背景:客户数据存在一个表被不同的项目使用的情况(不同项目使用不同的 schema),需要在创建实体的时候可以选到需要的表,当前因查不到视图类的数据导致业务阻塞。
体验优化说明:创建/编辑实体的第一步中的主表、辅表支持选择当前项目数据源 schema 下的所有表、视图。
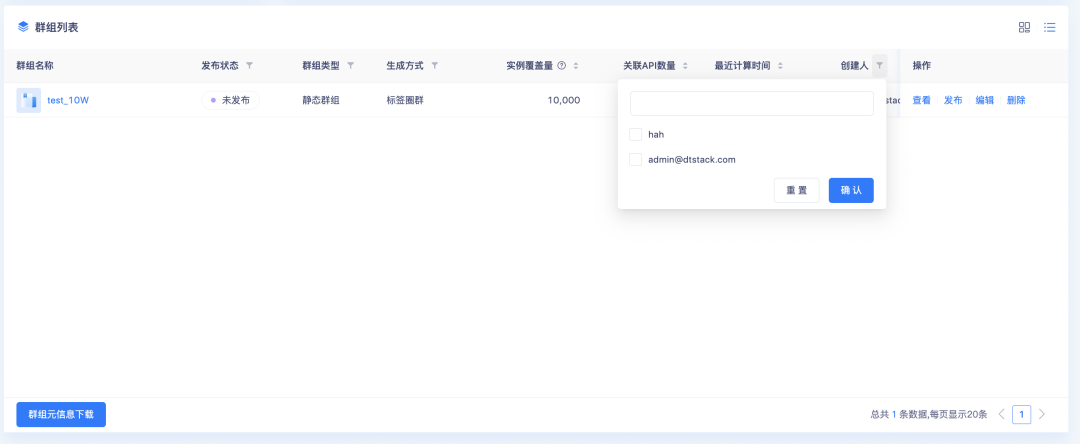
3.群组列表中,创建人支持筛选
下拉框默认展示前20个创建人,其余内容需通过搜索查询。
4.项目管理页成员管理支持对角色做筛选

指标管理平台
新增功能更新
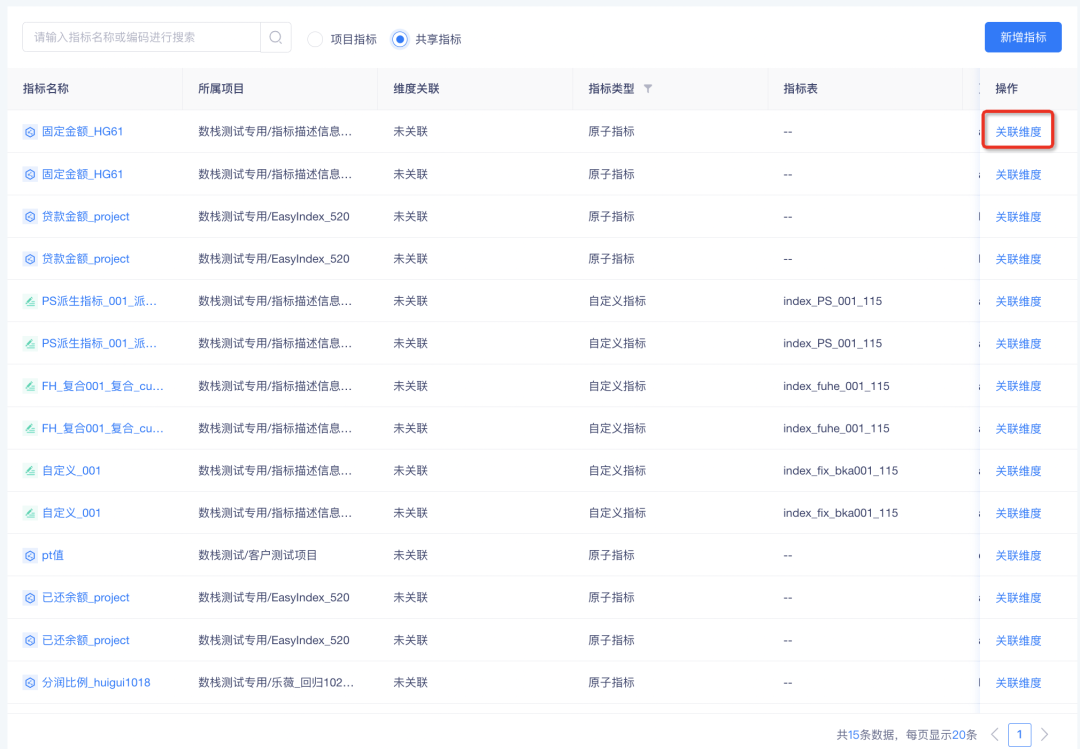
1.共享指标支持绑定维度对象、维度属性
背景:上一版本新增了维度管理功能,后续指标加工将依赖绑定的维度内容识别维度一致性,共享指标需绑定已有维度才能与自有指标做复合指标加工。
新增功能说明:「指标中心」-「指标开发」-「指标定义」-「共享指标」中显示了共享给当前项目的指标,点击「关联维度」即可与自有维度绑定。
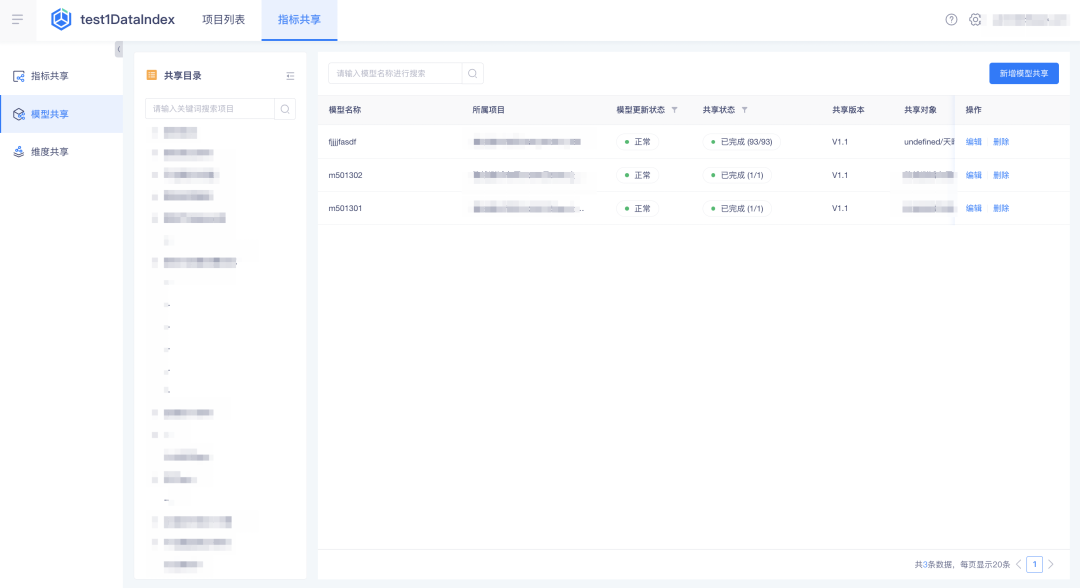
2.模型支持共享给其他项目使用
背景:原指标共享使用过程中,客户会有根据自己项目的业务需求基于源表做指标加工的需要,因源表无法获取导致数据无法正常加工。
新增功能说明:
• 「指标共享」-「模型共享」新增模型共享
• 点击「新增模型共享」可将指定项目的模型共享给其他项目。整体设置内容与指标共享类似,特殊地方为模型共享粒度当前支持表级别共享,即根据共享规则设置的条件分别针对模型中的每张表设置过滤条件,将过滤结果以视图形式共享到目标项目
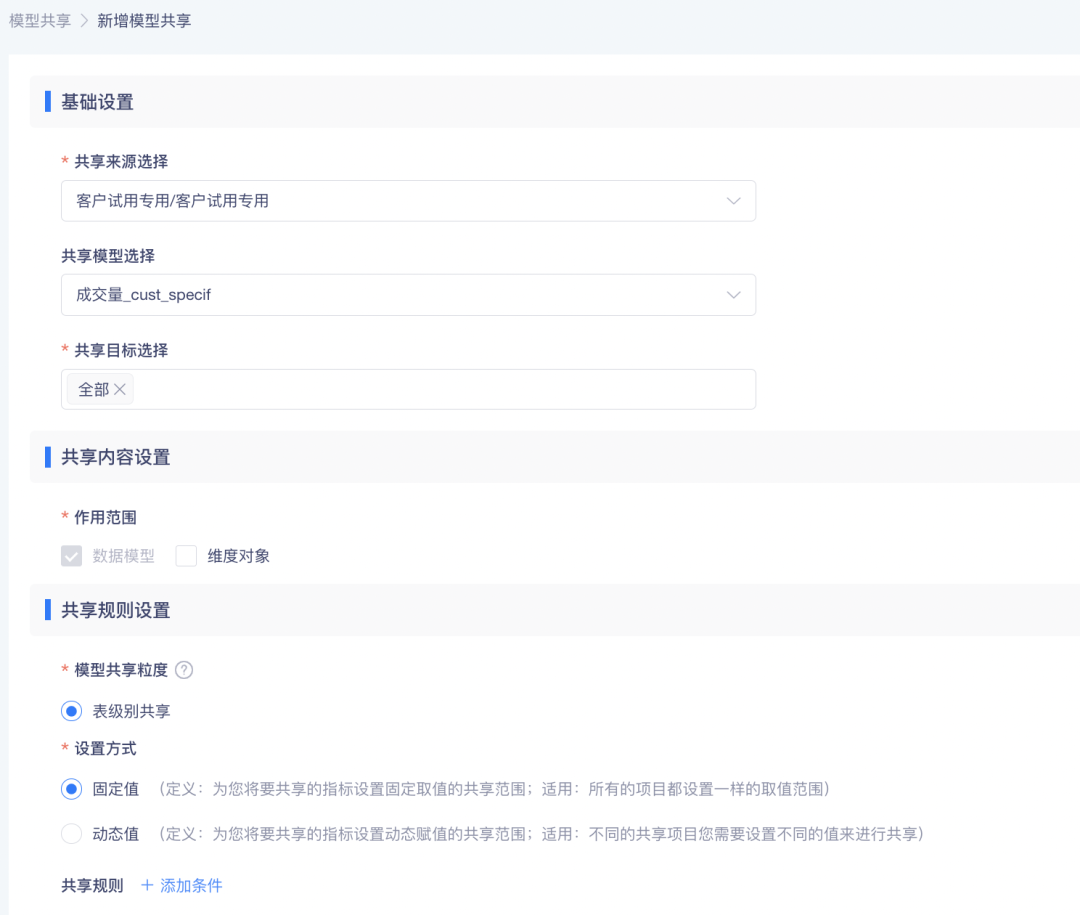
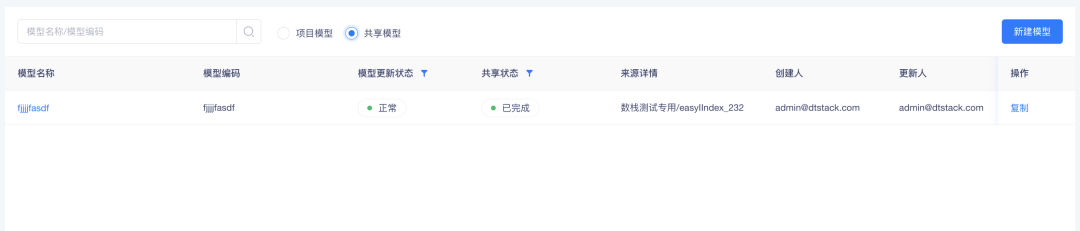
• 共享的模型可在项目内的「指标中心」-「数据管理」-「数据模型」中的「共享模型」tab 查看,对于需要在原模型基础上增加自有表形成新模型的需求场景,可通过复制功能实现。点击复制,填写模型名称、编码等信息,生成新模型后,编辑模型,设置对应的维度信息、模型存储信息后即可发布,发布后的模型可正常用于后续指标加工
3.维度支持共享给其他项目使用
背景:在指标管理过程中,会有对维度做全平台统一管理的需要,当进行指标共享时,便于理解指标维度的含义。
新增功能说明:
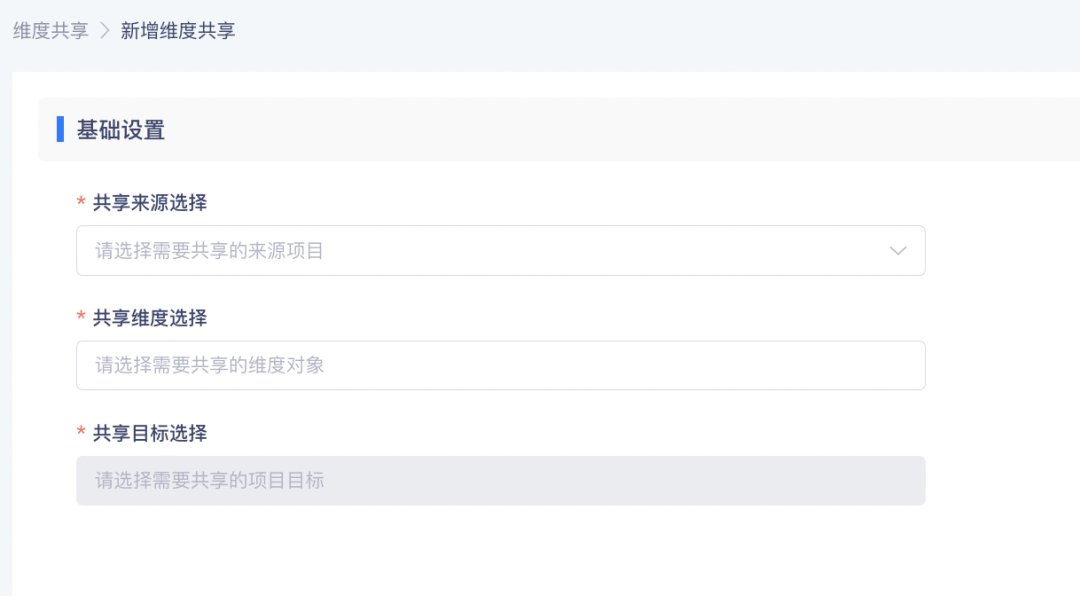
• 「指标共享」-「维度共享」新增维度共享

• 点击「新增维度共享」可将指定项目的维度共享给其他项目,整体设置内容与指标共享类似,只需设置基础共享内容即可
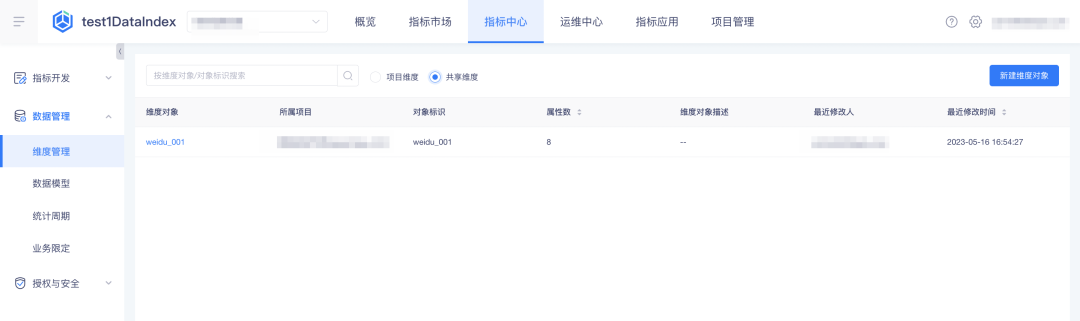
• 共享的维度可在项目内的「指标中心」-「数据管理」-「维度管理」中的「共享维度」tab 查看,模型、自定义指标加工时选择的维度信息可引用共享来的维度
4.指标共享时支持同步共享血缘上游指标、数据模型、维度对象
新增功能说明:
新建指标共享时,【第一步:设置通用共享信息】中的作用范围可增加血缘上游指标、数据模型、维度对象。
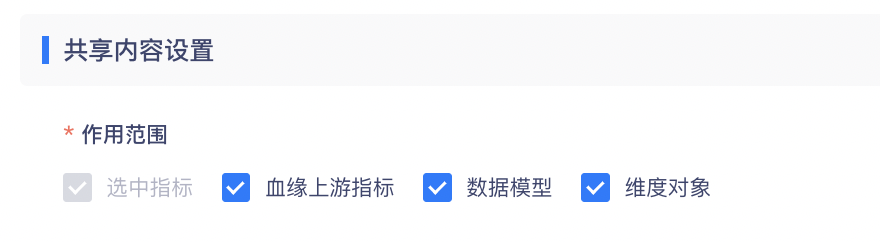
增加后,【第二步:设置共享条件】将针对每个单独的指标、模型设置共享条件,对于其中存在的共同的条件,可在第一步的公共维度共享规则中进行批量设置,最终共享规则将以第二步设置的内容为准。

5.上游内容更新后,下游内容支持联动更新
• 统计周期变更后,引用该统计周期的派生指标的自动更新版本,变更统计周期相关的 SQL 片段
• 数据模型的维度增加并发布时,原子指标维度自动更新,增加新维度;减少时,所有使用到该维度的指标均更新,去除引用维度
• 原子指标技术信息变更并发布后(计算逻辑、精度、为空默认值),引用该原子指标的派生指标自动更新计算公式
• 派生指标、复合指标、自定义指标的维度减少并发布时,下游指标自动更新,去除引用维度
功能优化
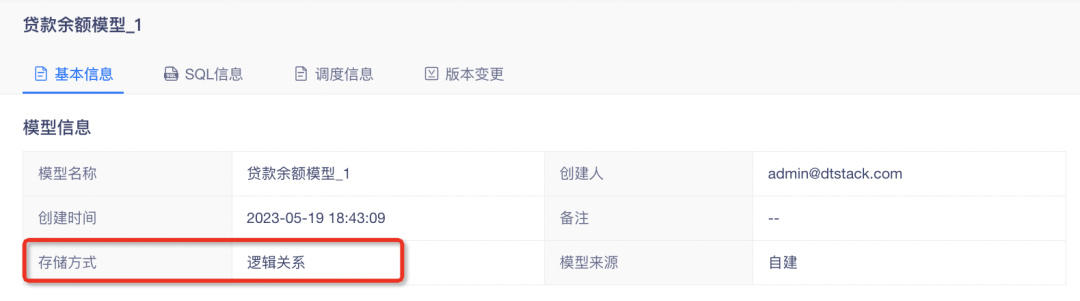
1.模型详情中显示存储方式、维度管理信息、调度信息
• 模型详情中的「基本信息」中的【模型信息】模块增加存储方式显示
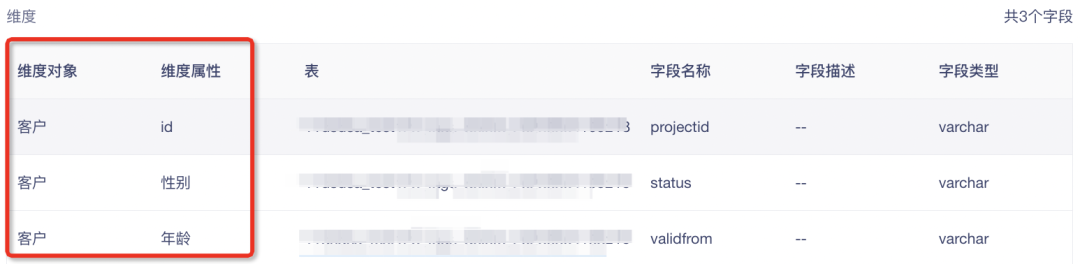
• 模型详情中的「基本信息」中的【数据信息】模块中的维度增加维度对象、维度属性信息显示
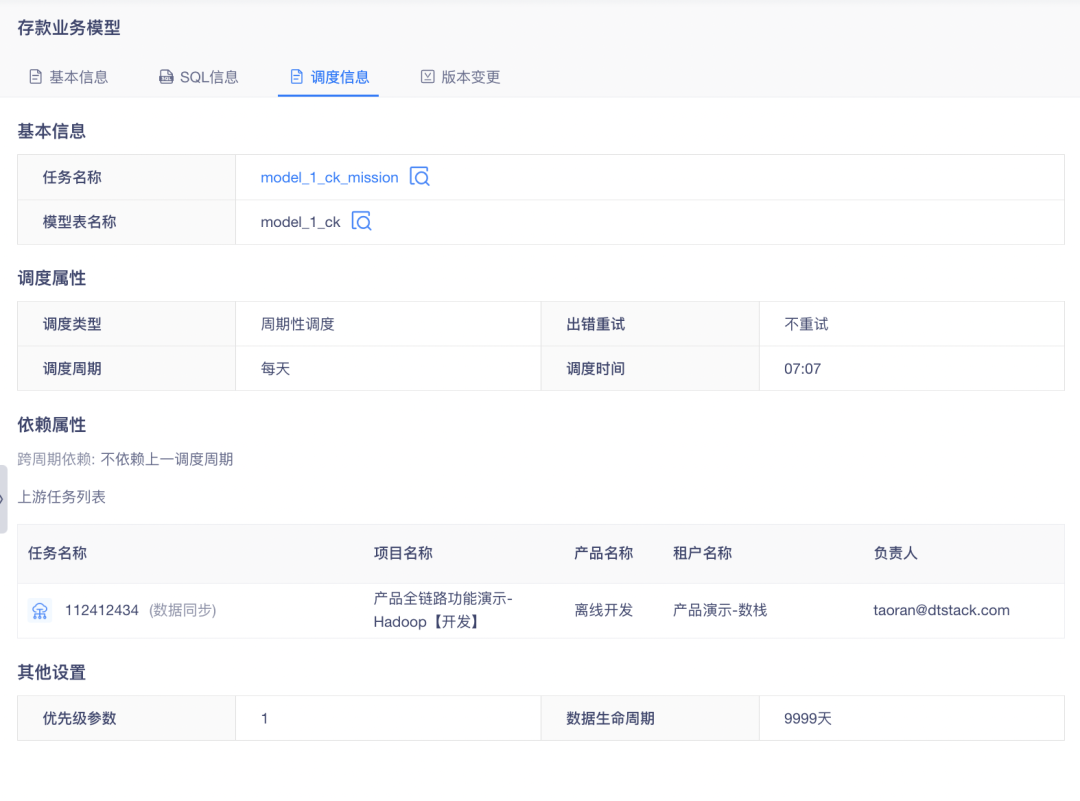
• 模型详情中的「调度信息」显示调度相关信息,包括表/任务信息、调度信息、数据生命周期等
2.任务选择中支持选择落表模型对应的模型任务
模型、指标调度信息设置中,选择上游任务时,可选择落表模型生成的任务。
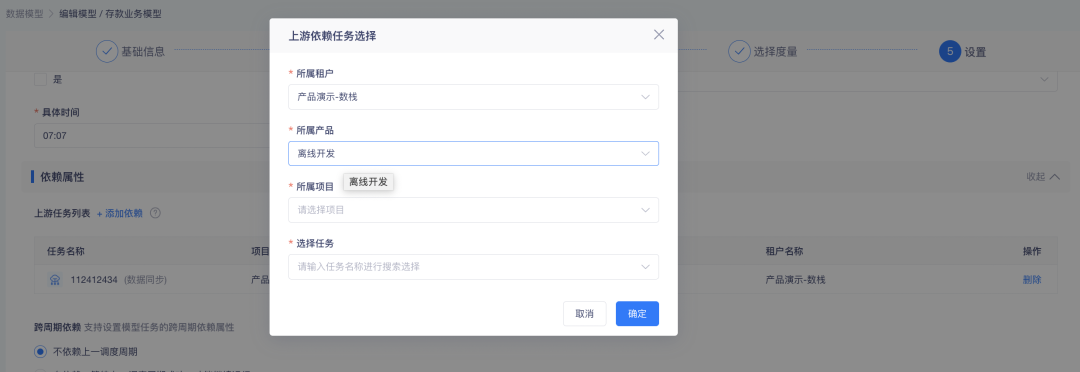
3.模型 SQL 显示内容优化
当前模型 SQL 显示页面较多,不同页面显示内容不完全一致,有些增加了调度信息、有些只展示选中的维度、度量信息,增加理解难度,本次优化统一 SQL 显示内容。
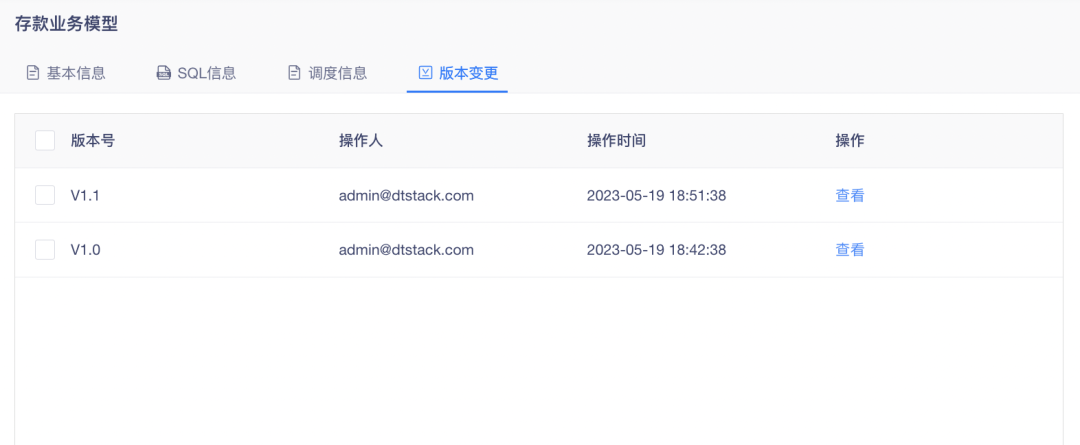
4.模型详情中的「版本变更」中去除「恢复」功能
背景:增加维度管理后,因后续指标是依赖最新维度信息生成的指标维度,若对版本进行恢复,将导致模型与指标的维度信息不一致的情况。
体验优化说明:页面去除恢复功能,仅支持查看功能。
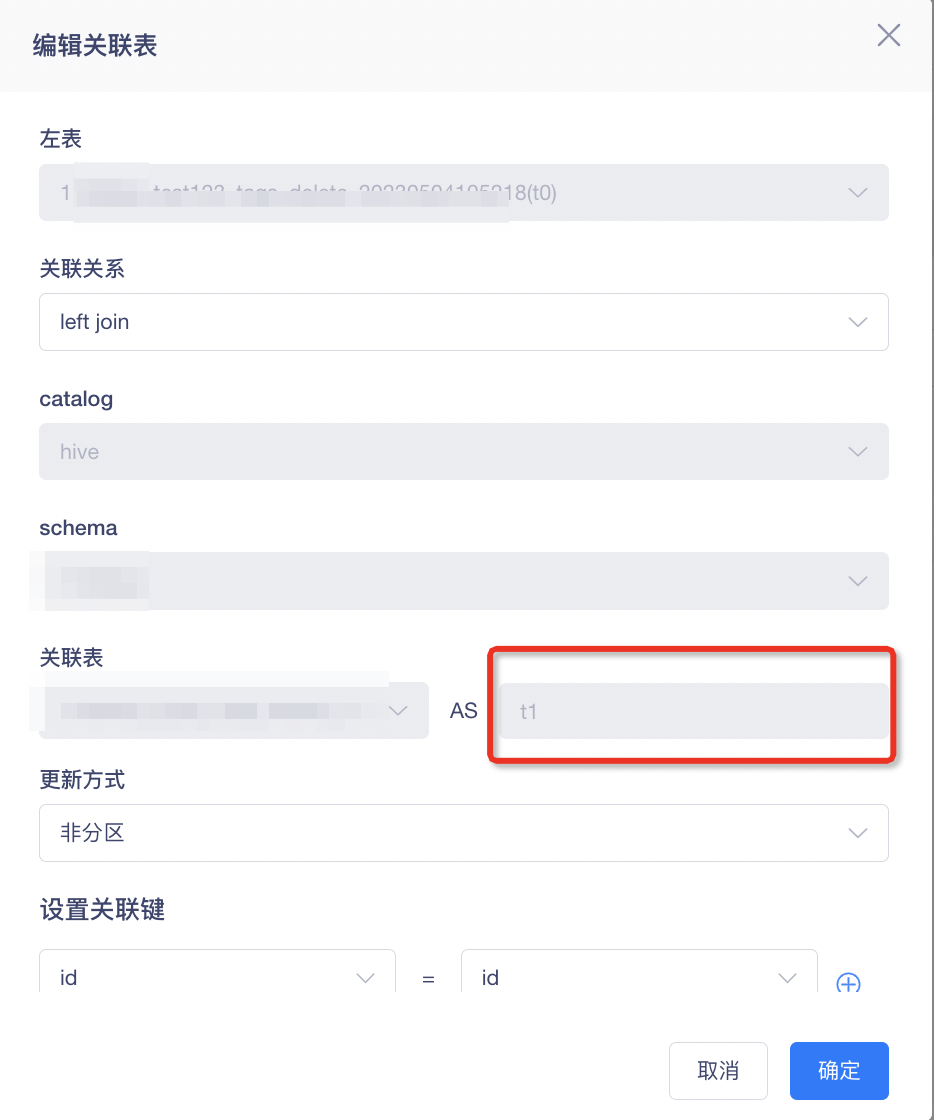
5.编辑模型时,不支持修改表别名
背景:模型落表后,将根据表别名生成模型表字段,修改表别名后,模型表字段将发生变更,导致后续计算时查询不到历史字段。
体验优化说明:编辑关联表时,表别名不可修改。
6.模型支持源表字段类型变更或字段减少
源表字段类型变更或字段减少时,系统将弹出受影响的业务限定、指标、权限设置、API,用户需手动编辑后生效。
7.其他功能优化
· 数据权限、API 的公共维度判断调整为基于维度对象、维度属性判断
· 指标市场的原子指标结果查询将返回根据公式计算的结果
《数栈产品白皮书》:https://www.dtstack.com/resources/1004?src=szsm
《数据治理行业实践白皮书》下载地址:https://www.dtstack.com/resources/1001?src=szsm 想了解或咨询更多有关袋鼠云大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szkyzg
同时,欢迎对大数据开源项目有兴趣的同学加入「袋鼠云开源框架钉钉技术qun」,交流最新开源技术信息,qun号码:30537511,项目地址:https://github.com/DTStack
罚款 200 元,没收 100 多万 尤雨溪:高质量中文文档的重要性 马斯克硬核迁移服务器 TCP 拥塞控制拯救了互联网 Apache OpenOffice 是事实上的“无人维护”项目 Google 庆祝成立 25 周年 微软开源 windows-drivers-rs,用 Rust 开发 Windows 驱动程序 Raspberry Pi 5 将于 10 月底发布,60 美元起售 macOS Containers:在 macOS 用 Docker 运行 macOS 镜像 IntelliJ IDEA 2023.3 EAP 发布