前言
本博客将介绍在云耀云服务器L实例服务器下如何部署Docker容器Hadoop。Hadoop是一个开源的分布式计算框架,用于处理大规模数据集。通过使用Docker,我们可以轻松地在任何环境中部署Hadoop,而无需担心依赖性和配置问题。本博客将详细介绍如何在Docker中安装和配置Hadoop。无论您是初学者还是有经验的开发人员,本博客都将为您提供有关在Docker中部署Hadoop的详细指南。
这是Maynor创作的华为云云耀云服务器L实例测评的第三篇,华为云评测系列传送门:
华为云云耀云服务器L实例评测|单节点环境下部署ClickHouse21.1.9.41数据库
华为云云耀云服务器L实例评测|伪分布式环境下部署hadoop2.10.1
云耀云服务器L实例简介
云耀云服务器L实例是新一代的轻量应用云服务器,专门为中小企业和开发者打造,提供开箱即用的便利性。云耀云服务器L实例提供丰富且经过严格挑选的应用镜像,可以一键部署应用,极大地简化了客户在云端构建电商网站、Web应用、小程序、学习环境以及各类开发测试等任务的过程。
Docker简介
Docker是一种开源的容器化平台,它可以帮助开发者将应用程序及其依赖项打包成一个独立的容器,以实现快速、可靠和可移植的应用部署。Docker的核心概念是容器,它是一个轻量级的、可移植的、自包含的软件单元,包含了运行应用程序所需的所有组件,如代码、运行时环境、系统工具和系统库。
一、配置环境
购买云耀云服务器L实例
在云耀云服务器L实例详情页,点击购买。

- 检查配置,确认购买。
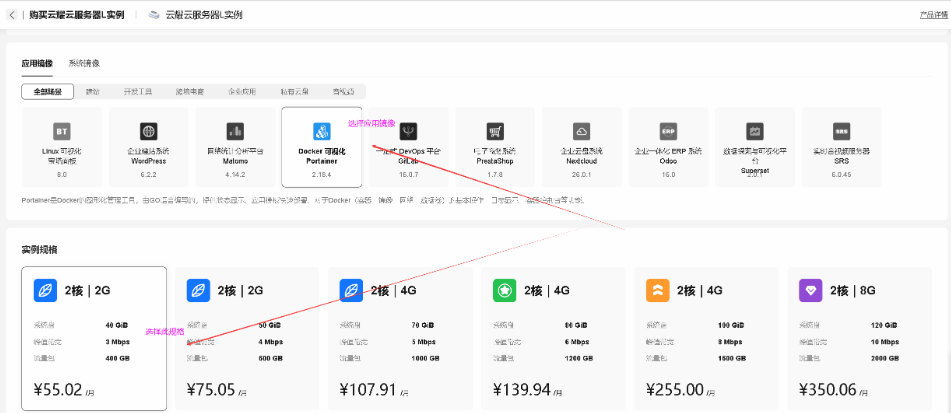

查看云耀云服务器L实例状态
查看购买的云耀云服务器L实例状态,处在正常运行中。
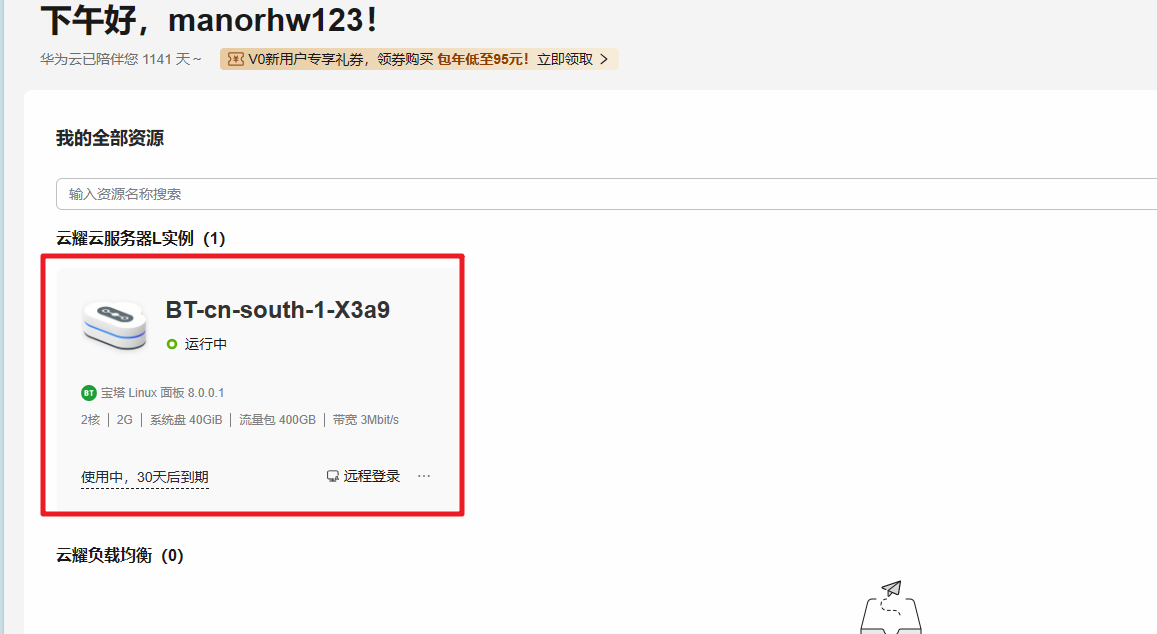
重置密码
重置密码,点击重置密码选项,需要进行身份验证,选择手机验证后,即可重置密码成功。
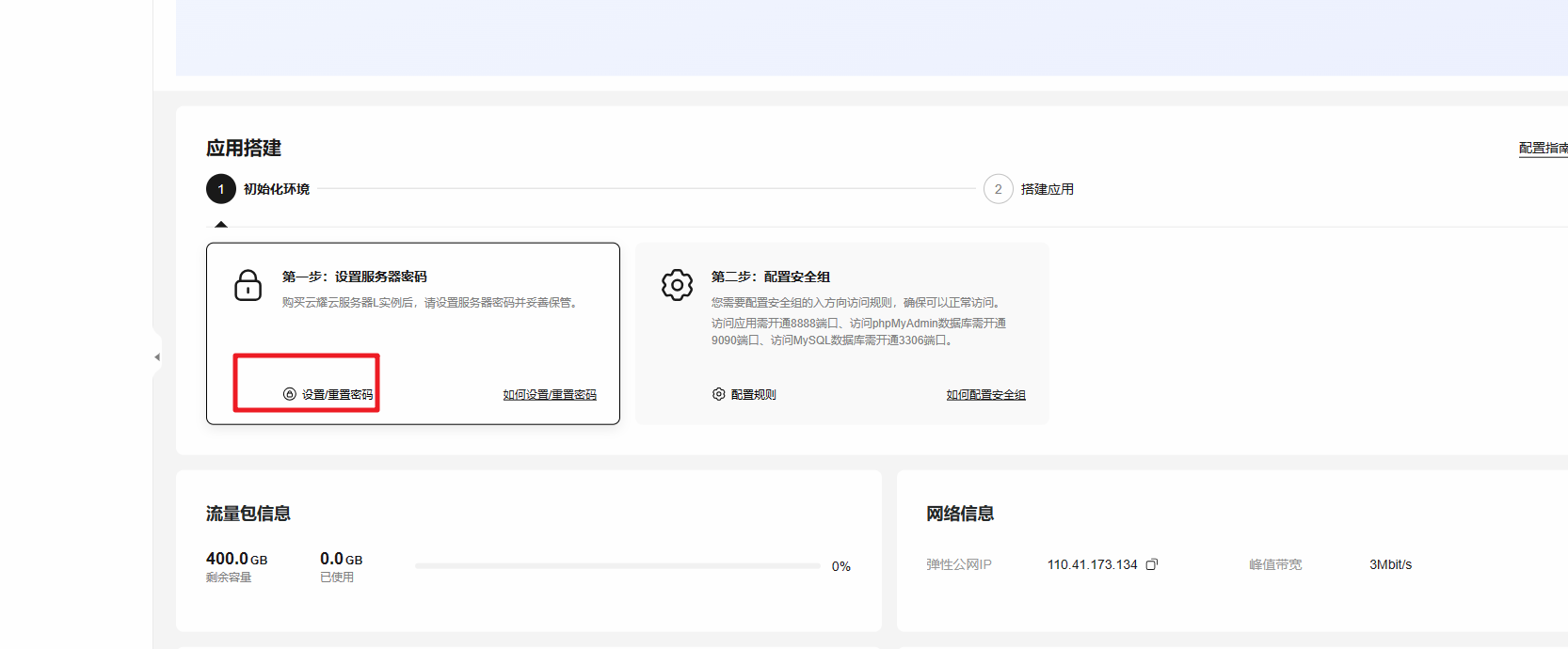
查看弹性公网IP地址
- 复制弹性公网IP地址,远程连接服务器时使用。
FinalShell连接服务器
在FinalShell工具中,填写服务器弹性公网IP地址、账号密码信息,ssh连接远程服务器。
二、docker安装
配置CentOS7阿里云yum源
cd /etc/yum.repos.d/
mv CentOS-Base.repo CentOS-Base.repo.bak
wget -O CentOs-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
yum源更新
yum clean all
yum makecache
安装Docker所需依赖包
yum install -y yum-utils device-mapper-persistent-data lvm2
配置阿里云Docker yum源
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
查看Docker版本
yum list docker-ce --showduplicates
安装Docker 18.03.0版本
yum install docker-ce-18.03.0.ce
启动Docker服务
systemctl enable docker
systemctl start docker
systemctl status docker
三、创建hadoop容器
宿主机环境准备
拉取镜像
docker pull centos:7
进入存放安装包目录
cd /mnt/docker_share
上传jdk和hadoop
- 前提:安装上传软件工具(yum install lrzsz)
rz jdk*.tar.gz;rz hadoop*.tar.gz
解压软件包
-
解压到opt目录,后续我们将映射该目录下的软件包到docker容器
tar -xvzf jdk-8u141-linux-x64.tar.gz -C /opt tar -xvzf hadoop-2.7.0.tar.gz -C /opt
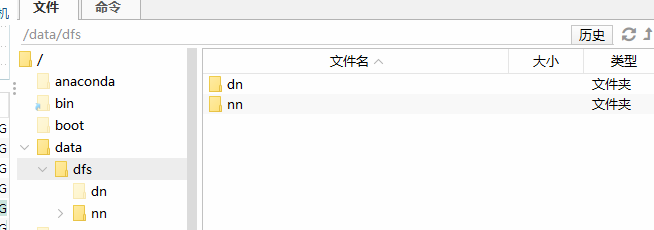
创建用于保存数据的文件夹
mkdir -p /data/dfs/nn
mkdir -p /data/dfs/dn
容器环境准备
启动hadoop容器
- 注意一定要添加 --privileged=true,否则无法使用系统服务
docker run \
--net docker-bd0 --ip 172.33.0.121 \
-p 50070:50070 -p 8088:8088 -p 19888:19888 \
-v /mnt/docker_share:/mnt/docker_share \
-v /etc/hosts:/etc/hosts \
-v /opt/hadoop-2.7.0:/opt/hadoop-2.7.0 \
-v /opt/jdk1.8.0_141:/opt/jdk1.8.0_141 \
-v /data/dfs:/data/dfs \
--privileged=true \
-d -it --name hadoop centos:7 \
/usr/sbin/init
注意:确保在主机上禁用SELinux
进入hadoop容器
docker exec -it hadoop bash

安装vim
-
为了后续方便编辑配置文件,安装一个vim
yum install -y vim
安装ssh
- 因为启动Hadoop集群需要进行免密登录,Centos7容器需要安装ssh
yum install -y openssl openssh-server
yum install -y openssh-client*
-
修改ssh配置文件
vim /etc/ssh/sshd_config # 在文件最后添加 PermitRootLogin yes RSAAuthentication yes PubkeyAuthentication yes -
启动ssh服务
systemctl start sshd.service # 设置开机自动启动ssh服务 systemctl enable sshd.service # 查看服务状态 systemctl status sshd.service
配置免密登录
生成秘钥
ssh-keygen
设置密码
-
设置root用户的密码为123456
passwd
拷贝公钥
ssh-copy-id hadoop.bigdata.cn
测试免密登录
ssh hadoop.bigdata.cn
配置JDK
vim /etc/profile
# 配置jdk的环境变量
export JAVA_HOME=/opt/jdk1.8.0_141
export CLASSPATH=${JAVA_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
# 让上一步配置生效
source /etc/profile

配置Hadoop
-
core-site.xml
<property> <name>fs.defaultFS</name> <value>hdfs://hadoop.bigdata.cn:9000</value> </property> <property> <name>hadoop.proxyuser.root.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.root.groups</name> <value>*</value> </property> <property> <name>hadoop.http.staticuser.user</name> <value>root</value> </property> -
hdfs-site.xml
<property> <name>dfs.namenode.http-address</name> <value>hadoop.bigdata.cn:50070</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop.bigdata.cn:50090</value> </property> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:///data/dfs/nn</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:///data/dfs/dn</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> -
yarn-site.xml
<property> <name>yarn.resourcemanager.hostname</name> <value>hadoop-yarn</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop.bigdata.cn</value> </property> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <property> <name>yarn.nodemanager.remote-app-log-dir</name> <value>/user/container/logs</value> </property> -
mapred-site.xml
<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>hadoop.bigdata.cn:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>hadoop.bigdata.cn:19888</value> </property> <property> <name>mapreduce.jobhistory.intermediate-done-dir</name> <value>/tmp/mr-history</value> </property> <property> <name>mapreduce.jobhistory.done-dir</name> <value>/tmp/mr-done</value> </property> -
hadoop-env.sh
export JAVA_HOME=/opt/jdk1.8.0_141 -
slaves
hadoop.bigdata.cn -
配置环境变量
- vim /etc/profile
- source /etc/profile
export HADOOP_HOME=/opt/hadoop-2.7.0 export PATH=${HADOOP_HOME}/sbin:${HADOOP_HOME}/bin:$PATH
四、初始化并启动Hadoop
格式化hdfs
hdfs namenode -format
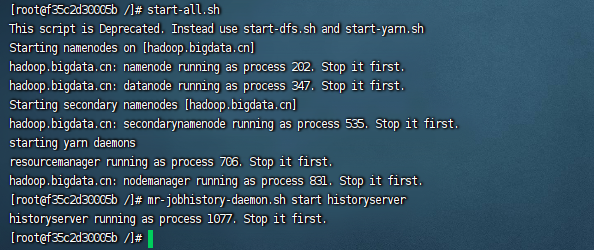
启动hadoop
start-all.sh
# 启动history server
mr-jobhistory-daemon.sh start historyserver
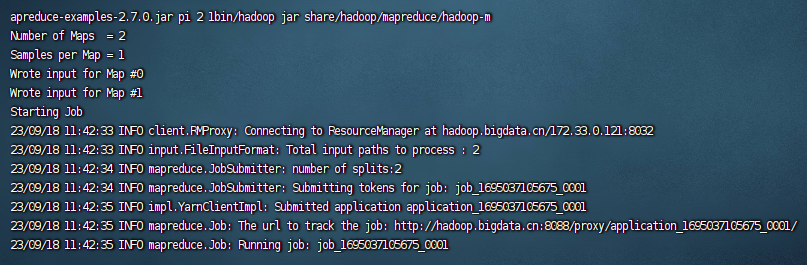
测试hadoop
cd $HADOOP_HOME
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.0.jar pi 2 1
查看进程
bash-4.1# jps
561 ResourceManager
659 NodeManager
2019 Jps
1559 NameNode
1752 SecondaryNameNode
249 DataNode

五、配置开启容器启动Hadoop
创建启动脚本
-
创建新文件存放启动脚本
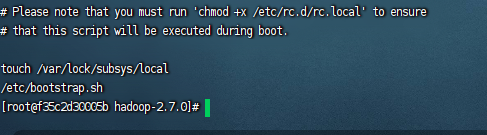
touch /etc/bootstrap.sh chmod a+x /etc/bootstrap.sh vim /etc/bootstrap.sh -
文件内容
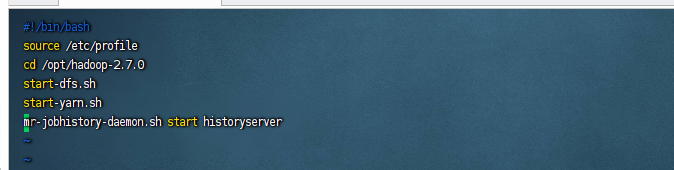
#!/bin/bash source /etc/profile cd /opt/hadoop-2.7.0 start-dfs.sh start-yarn.sh mr-jobhistory-daemon.sh start historyserver
加入自动启动服务
vim /etc/rc.d/rc.local
/etc/bootstrap.sh
# 开启执行权限
chmod 755 /etc/rc.d/rc.local
为宿主机配置域名映射
-
为了方便将来访问,在window上配置宿主机域名映射,C:\Windows\System32\drivers\etc目录下的hosts文件
-
添加以下映射(此处可以把规划好的域名映射都加进来)
192.168.88.100 hadoop.bigdata.cn
六、查看web ui
-
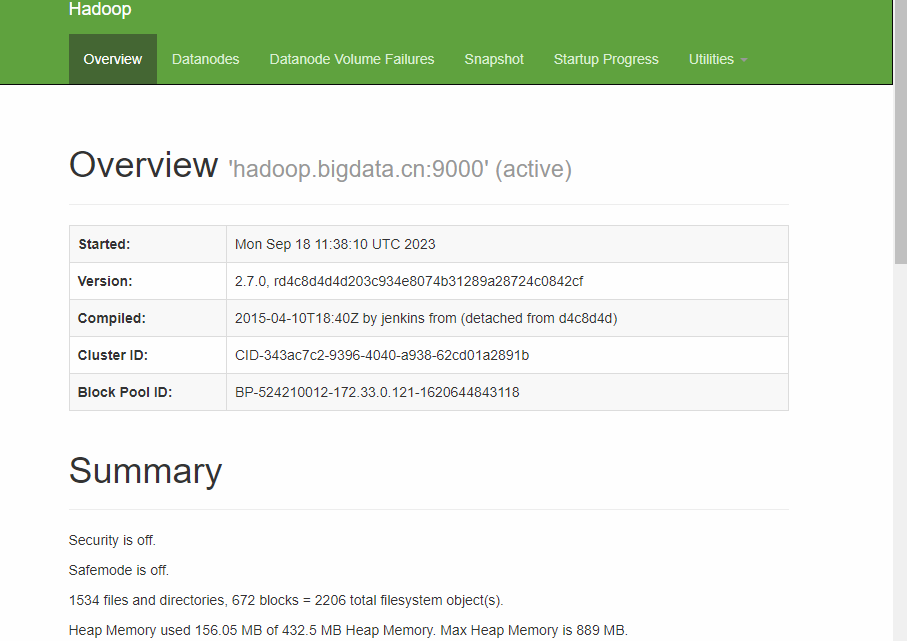
HDFS
- http://192.168.88.100:50070
-
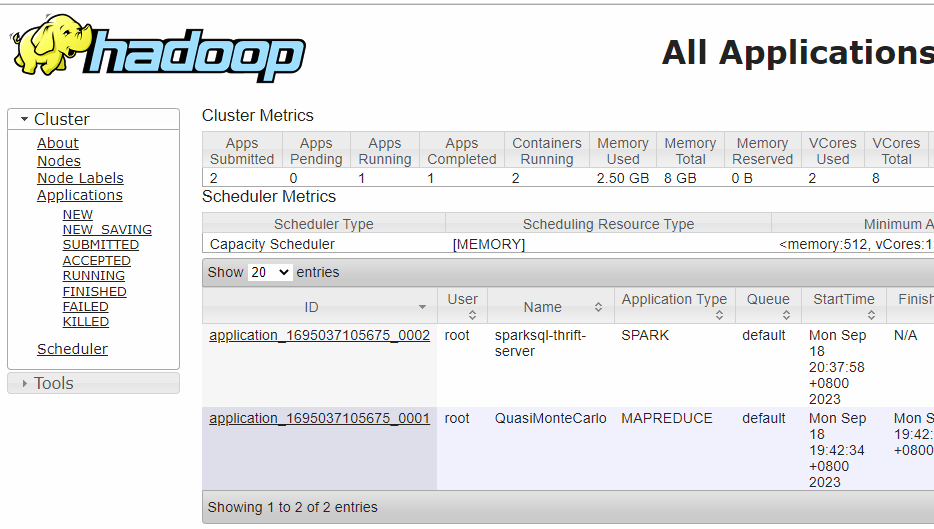
YARN
- http://192.168.88.100:8088
-
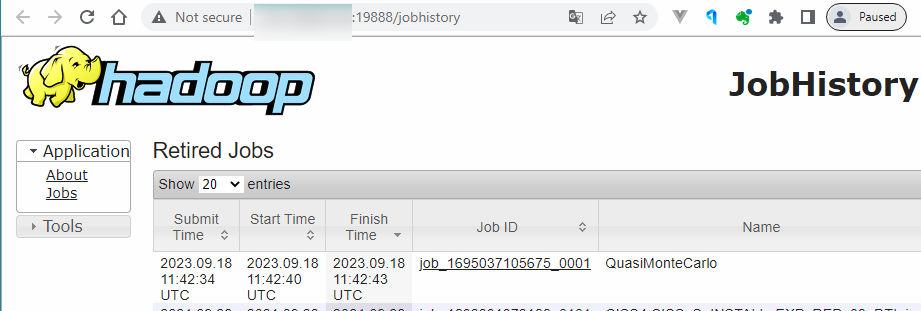
Job History Server
- http://192.168.88.100:19888
总结
本博客介绍了在云耀云服务器L实例上使用Docker部署Hadoop的步骤。通过购买云服务器L实例并配置环境,我们可以轻松地安装和配置Docker,并创建Hadoop容器。在容器中,我们可以上传和解压所需的软件包,并创建用于保存数据的文件夹。最后,我们可以通过访问相应的Web UI来验证Hadoop的安装和配置。通过使用Docker,我们可以避免依赖性和配置问题,轻松地在任何环境中部署Hadoop。