一、预处理
1.数据无量纲化
数据的无量纲化包括中心化、缩放处理。
1.1 归一化
normalization :数据减去最小值除以最大差异
sklearn: preprocessing.MinMaxScaler
代码如下:
from sklearn.preprocessing import MinMaxScaler as ms
scaler=ms()
scaler=scaler.fit(data)
result=scaler.transform(data)
print(result)
// result_=scaler.fit_transform(data)
// print(result_)
//训练并且导出结果
scaler.inverse_transform(result)//将归一化后的结果逆转
参数:
- feature_range=[5,10]
归一化范围[5,10]
如何用numpy实现归一化?

1.2 数据标准化
preprocessing.StandardScaler
数据标准化
代码如下:(3种方式)
from sklearn.preprocessing import StandardScaler as ss
scaler=ss()
scaler.fit(data)
scaler.mean_ //查看均值
scaler.var_ //查看方差
from sklearn.preprocessing import StandardScaler as ss
scaler=ss()
x_std=scaler.transform(data) //采用接口的方法查看
x_std.mean()
x_std.std()
scaler.inver_transform(x_std)
from sklearn.preprocessing import StandardScaler as ss
scaler=ss()
scaler.fit_transform(data)
2.缺失值的处理
sklearn.impute.SimpleImputer(missing_values=nan,strategy=‘mean’)
sklearn.impute.SimpleImputer(missing_values=nan,strategy=‘constant’,fill_value=0)
strategy:
- mean:平均值
- median:中值
- most_frequent:众数
- constant:参考fill_value的值
或者使用pandas来填补:

上述只能处理数值类型,怎么办?
3.处理分类型特征
将文字转化成数值型:
from sklearn.preprocessing import LabelEncoder as le
y=data.iloc[:,-1]
le=le()
le=le.fit()
label=le.transform()
或者
from sklearn.preprocessing import LabelEncoder as le
data.iloc[:,-1]=le.fit_transform(data.iloc[:,-1])
不止最后一列可以改变,其他非数字都可以改变。
from sklearn.preprocessing import LabelEncoder as le
data.iloc[:,1:-1]=le.fit_transform(data.iloc[:,1:-1])
独热编码
多分类时
例如数据集:

from sklearn.preprocessing import OneHotEncoder as oe
x_train=oe(catagories='aoto').fit_transform(data.iloc[:,1:-1]).toarray()
//得知属性名称
print(x_train.get_feature_names())
print(x_train.shape)
new_data=pd.concat([data,pd.DataFrame(x_train)],axis=1)//左右相连
new_data.head()
new _data 的print结果: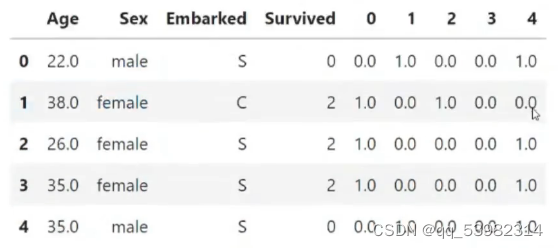
new_data.drop(["Sex","Embarked",],axis=1,inplace=True)//去除sex和embarked列
new_data.columns=["Age","Survived","Male","Female","C","Q","S"]//给colomns重命名
new_data.head()
结果如下:
4.处理连续型特征
例如,老人小孩0,中年人1
40岁以上是1,40以下是0
- sklearn.prepocessing.Binarizer
from sklearn.prepocessing import Binarizer as br
x_train=data.iloc[:,0].values.reshape(-1,1)//类为分类所用,不能用做1维数据
transformer=br(threshold=30).fit_transform(x_train)
print(transformer)
分为多个
- KBinsDiscretizer(n_bins= ,encoder=’ ‘,strategy=’ ')


set()会去重复
ravel()是一个函数,用于将多维数组展平为一维数组。它是NumPy库中的一个函数