一个不知名大学生,江湖人称菜狗
original author: jacky Li
Email : [email protected]
Time of completion:2022.12.15
Last edited: 2022.12.17

目录
《微信机器人》程序使用说明
首先启动Flask项目,然后启动小米球内网穿透工具,最后配置好微信公众平台。准备就绪,进入微信公众平台。
在微信公众平台输入“笑话”,将获取一条笑话信息,运行效果如图1所示。输入“城市天气”,将获取城市天气信息,运行结果如图2所示。输入其他文字,将对字符串进行反转,运行效果如图3所示 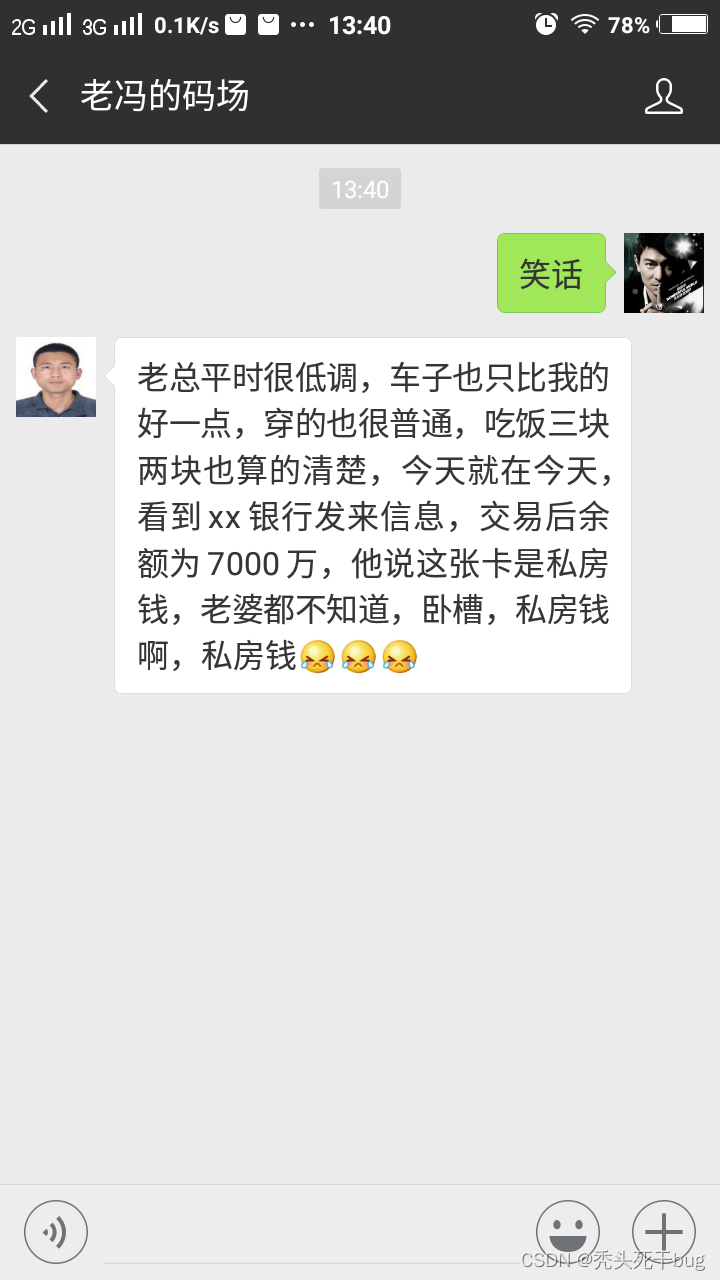
图1 笑话功能
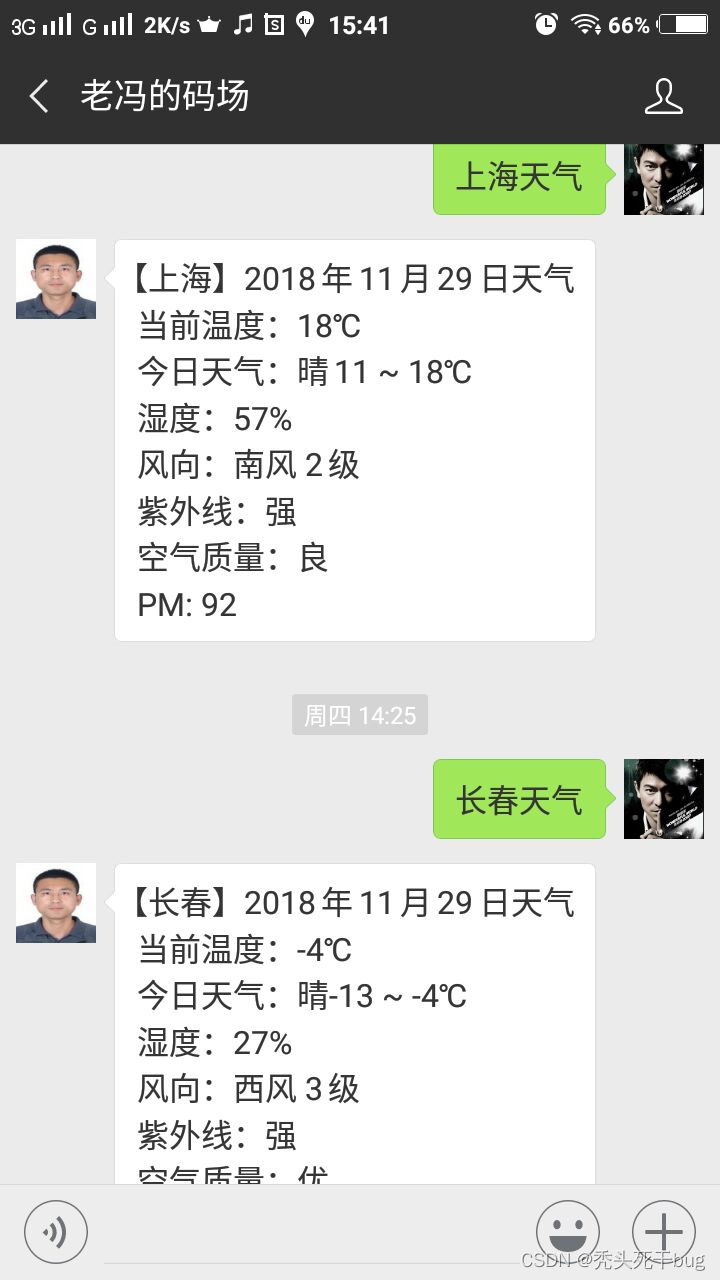
图2 查天气功能
微信机器人使用说明
说明:本配置说明,需要保证他人可以按照步骤完整操作,并运行起来!不限于以下4个步骤,需要根据语言、程序实际情况进行删减!!!
1.项目说明
- 项目名称:微信机器人
- 作者:Jacky Li
- 项目版本:V 1.0
- 版本变化:无
- 完成日期:2022.12.15
2. 系统环境
Windows 7 及以上/Linux/MacOS
MySQL5.5以上
Python3.6以上版本
其他Python库:
requests==2.18.4
lxml==4.2.5
flask==0.12.2
3.准备条件
运行本项目,需要如下前提条件:
◆ 微信公众平台订阅号
◆ 小米球ngrok内网穿透工具(下载安装步骤参见正文)
4.操作步骤
1)启动虚拟,步骤如下:
a. 安装虚拟环境,使用如下命令:
pip install virtualenv
b. 创建虚拟环境
在wechat_rebot目录下,创建venv虚拟环境,命令如下:
virtualenv venv
c.启动venv虚拟环境,命令如下:
venv\script\activate
部分代码:
def get_weather(keyword):
url = 'https://www.tianqi.com/tianqi/search?keyword=' + keyword
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'
}
response = requests.get(url,headers=headers)
tree = etree.HTML(response.text)
# 检测城市天气是否存在
try:
city_name = tree.xpath('//dd[@class="name"]/h2/text()')[0]
except:
content = '没有该城市天气信息,请确认查询格式'
return content
week = tree.xpath('//dd[@class="week"]/text()')[0]
now = tree.xpath('//p[@class="now"]')[0].xpath('string(.)')
temp = tree.xpath('//dd[@class="weather"]/span')[0].xpath('string(.)')
shidu = tree.xpath('//dd[@class="shidu"]/b/text()')
kongqi = tree.xpath('//dd[@class="kongqi"]/h5/text()')[0]
pm = tree.xpath('//dd[@class="kongqi"]/h6/text()')[0]
content = "【{0}】{1}天气\n当前温度:{2}\n今日天气:{3}\n{4}\n{5}\n{6}".format(city_name, week.split('\u3000')[0], now, temp, '\n'.join(shidu),kongqi,pm)
return content通过api获得要查询地区的天气。
def get_joke():
url="http://www.qiushibaike.com/text/page/"+ str(randint(1,5))
r = requests.get(url)
tree = etree.HTML(r.text)
contentlist = tree.xpath('//div[@class="content"]/span')
jokes = []
for content in contentlist:
content = content.xpath('string(.)') # string() 函数将所有子文本串联起来,# 必须传递单个节点,而不是节点集。
if '查看全文' in content: # 忽略包含“查看原文”笑话
continue
jokes.append(content)
joke = jokes[randint(1, len(jokes))].strip()
return joke同理,通过api获得笑话,并通过微信公众号进行对用户的展示。
作者有言
如果感觉博主讲的对您有用,请点个关注支持一下吧,将会对此类问题持续更新……
如果需要源码请找博主私聊一下叭