为什么选 KV server 来实操呢?因为它是一个足够简单又足够复杂的服务。参考工作中用到的 Redis / Memcached 等服务,来梳理它的需求。
最核心的功能是根据不同的命令进行诸如数据存贮、读取、监听等操作;
而客户端要能通过网络访问 KV server,发送包含命令的请求,得到结果;
数据要能根据需要,存储在内存中或者持久化到磁盘上。
先来一个短平糙的实现如果是为了完成任务构建 KV server,其实最初的版本两三百行代码就可以搞定,但是这样的代码以后维护起来就是灾难。我们看一个省却了不少细节的意大利面条式的版本,你可以随着我的注释重点看流程:
use anyhow::Result;
use async_prost::AsyncProstStream;
use dashmap::DashMap;
use futures::prelude::*;
use kv::{
command_request::RequestData, CommandRequest, CommandResponse, Hset, KvError, Kvpair, Value,
};
use std::sync::Arc;
use tokio::net::TcpListener;
use tracing::info;
#[tokio::main]
async fn main() -> Result<()> {
// 初始化日志
tracing_subscriber::fmt::init();
let addr = "127.0.0.1:9527";
let listener = TcpListener::bind(addr).await?;
info!("Start listening on {}", addr);
// 使用 DashMap 创建放在内存中的 kv store
(DashMap试图使用起来非常简单,并且可以直接替代RwLock<HashMap<K, V>>。
为了完成这些,所有的方法都使用&self,而不是修改采用&mut self的方法。
这允许您将DashMap放在Arc<T>中,并在线程之间共享它,同时可以修改它。)
let table: Arc<DashMap<String, Value>> = Arc::new(DashMap::new());
loop {
// 得到一个客户端请求
let (stream, addr) = listener.accept().await?;
info!("Client {:?} connected", addr);
// 复制 db,让它在 tokio 任务中可以使用
let db = table.clone();
// 创建一个 tokio 任务处理这个客户端
tokio::spawn(async move {
// 使用 AsyncProstStream 来处理 TCP Frame
// Frame: 两字节 frame 长度,后面是 protobuf 二进制
let mut stream =
AsyncProstStream::<_, CommandRequest, CommandResponse, _>::from(stream).for_async();
// 从 stream 里取下一个消息(拿出来后已经自动 decode 了)
while let Some(Ok(msg)) = stream.next().await {
info!("Got a new command: {:?}", msg);
let resp: CommandResponse = match msg.request_data {
// 为演示我们就处理 HSET
Some(RequestData::Hset(cmd)) => hset(cmd, &db),
// 其它暂不处理
_ => unimplemented!(),
};
info!("Got response: {:?}", resp);
// 把 CommandResponse 发送给客户端
stream.send(resp).await.unwrap();
}
});
}
}
// 处理 hset 命令
fn hset(cmd: Hset, db: &DashMap<String, Value>) -> CommandResponse {
match cmd.pair {
Some(Kvpair {
key,
value: Some(v),
}) => {
// 往 db 里写入
let old = db.insert(key, v).unwrap_or_default();
// 把 value 转换成 CommandResponse
old.into()
}
v => KvError::InvalidCommand(format!("hset: {:?}", v)).into(),
}
}
这段代码非常地平铺直叙,从输入到输出,一蹴而就,如果这样写,任务确实能很快完成,但是它有种“完成之后,哪管洪水滔天”的感觉。你复制代码后,打开两个窗口,分别运行 “cargo run --example naive_server” 和 “cargo run --example client”,就可以看到运行 server 的窗口有如下打印:
Sep 19 22:25:34.016 INFO naive_server: Start listening on 127.0.0.1:9527
Sep 19 22:25:38.401 INFO naive_server: Client 127.0.0.1:51650 connected
Sep 19 22:25:38.401 INFO naive_server: Got a new command: CommandRequest {
request_data: Some(Hset(Hset {
table: "table1", pair: Some(Kvpair {
key: "hello", value: Some(Value {
value: Some(String("world")) }) }) })) }
Sep 19 22:25:38.401 INFO naive_server: Got response: CommandResponse {
status: 200, message: "", values: [Value {
value: None }], pairs: [] }
虽然整体功能算是搞定了,不过以后想继续为这个 KV server 增加新的功能,就需要来来回回改这段代码。此外,也不好做单元测试,因为所有的逻辑都被压缩在一起了,没有“单元”可言。虽然未来可以逐步把不同的逻辑分离到不同的函数,使主流程尽可能简单一些。但是,它们依旧是耦合在一起的,如果不做大的重构,还是解决不了实质的问题。
所以不管用什么语言开发,这样的代码都是我们要极力避免的,不光自己不要这么写,code review 遇到别人这么写也要严格地揪出来。
架构和设计那么,怎样才算是好的实现呢?好的实现应该是在分析完需求后,首先从系统的主流程开始,搞清楚从客户端的请求到最终客户端收到响应,都会经过哪些主要的步骤;然后根据这些步骤,思考哪些东西需要延迟绑定,构建主要的接口和 trait;等这些东西深思熟虑之后,最后再考虑实现。也就是所谓的“谋定而后动”。开头已经分析 KV server 这个需求,现在我们来梳理主流程。你可以先自己想想,再参考示意图看看有没有缺漏:
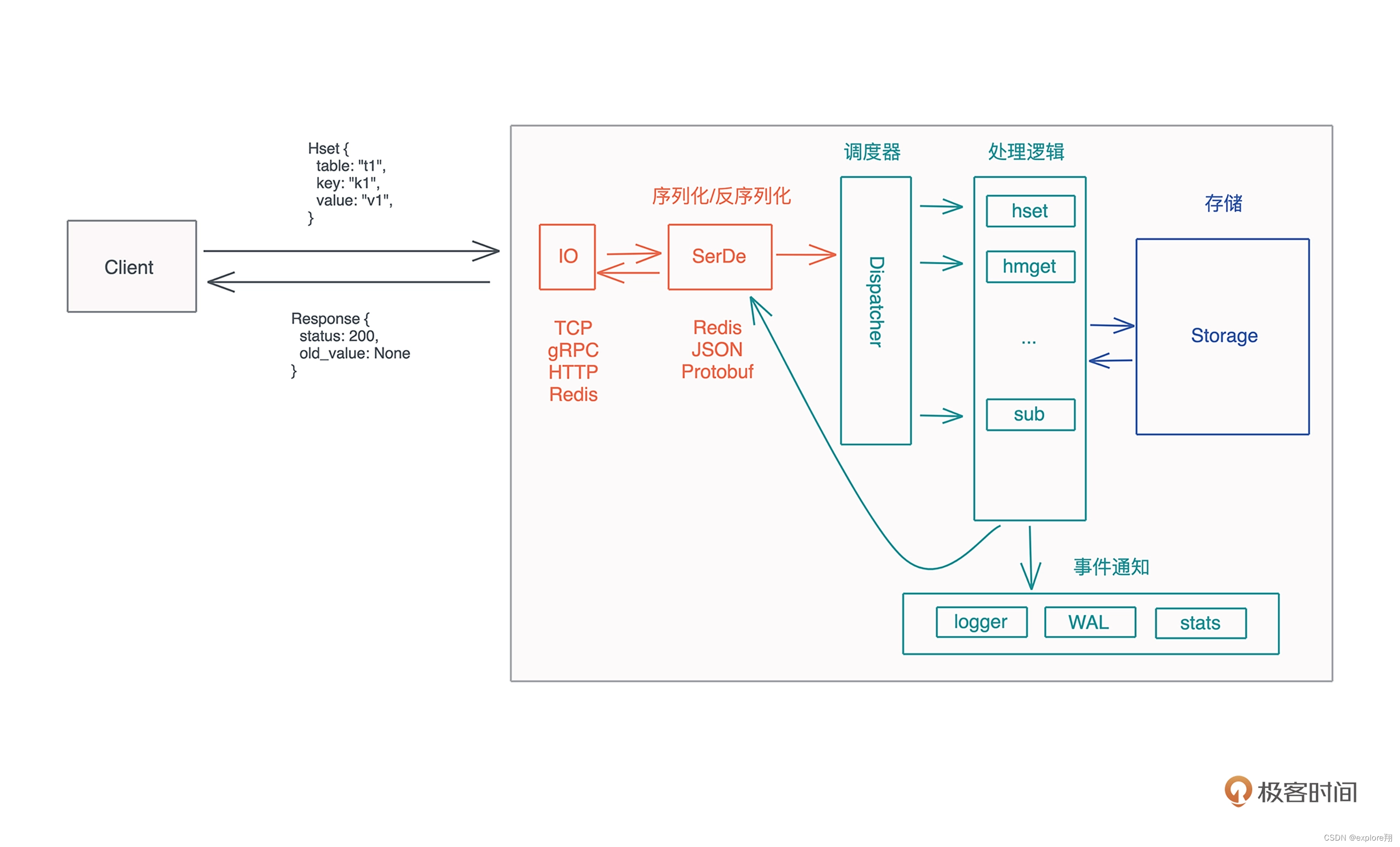
这个流程中有一些关键问题需要进一步探索:
客户端和服务器用什么协议通信?TCP?gRPC?HTTP?支持一种还是多种?
客户端和服务器之间交互的应用层协议如何定义?怎么做序列化 / 反序列化?是用 Protobuf、JSON 还是 Redis RESP?或者也可以支持多种?
服务器都支持哪些命令?第一版优先支持哪些?具体的处理逻辑中,需不需要加 hook,在处理过程中发布一些事件,让其他流程可以得到通知,进行额外的处理?
这些 hook 可不可以提前终止整个流程的处理?对于存储,要支持不同的存储引擎么?比如 MemDB(内存)、RocksDB(磁盘)、SledDB(磁盘)等。对于 MemDB,我们考虑支持 WAL(Write-Ahead Log) 和 snapshot 么?
整个系统可以配置么?比如服务使用哪个端口、哪个存储引擎?…
如果你想做好架构,那么,问出这些问题,并且找到这些问题的答案就很重要。
值得注意的是,这里面很多问题产品经理并不能帮你回答,或者 TA 的回答会将你带入歧路。作为一个架构师,我们需要对系统未来如何应对变化负责。
下面是我的思考,你可以参考:
- 像 KV server 这样需要高性能的场景,通信应该优先考虑 TCP 协议。所以我们暂时只支持 TCP,未来可以根据需要支持更多的协议,如 HTTP2/gRPC。还有,未来可能对安全性有额外的要求,所以我们要保证 TLS 这样的安全协议可以即插即用。总之,网络层需要灵活。
- 应用层协议我们可以用 protobuf 定义。protobuf 直接解决了协议的定义以及如何序列化和反序列化。Redis 的 RESP 固然不错,但它的短板也显而易见,命令需要额外的解析,而且大量的 \r\n 来分隔命令或者数据,也有些浪费带宽。使用 JSON 的话更加浪费带宽,且 JSON 的解析效率不高,尤其是数据量很大的时候。protobuf 就很适合 KV server 这样的场景,灵活、可向后兼容式升级、解析效率很高、生成的二进制非常省带宽,唯一的缺点是需要额外的工具 protoc 来编译成不同的语言。虽然 protobuf 是首选,但也许未来为了和 Redis 客户端互通,还是要支持 RESP。
- 服务器支持的命令我们可以参考Redis 的命令集。第一版先来支持 HXXX 命令,比如 HSET、HMSET、HGET、HMGET 等。从命令到命令的响应,可以做个 trait 来抽象。
- 处理流程中计划加这些 hook:收到客户端的命令后 OnRequestReceived、处理完客户端的命令后 OnRequestExecuted、发送响应之前 BeforeResponseSend、发送响应之后 AfterResponseSend。这样,处理过程中的主要步骤都有事件暴露出去,让我们的 KV server 可以非常灵活,方便调用者在初始化服务的时候注入额外的处理逻辑。
- 存储必然需要足够灵活。可以对存储做个 trait 来抽象其基本的行为,一开始可以就只做 MemDB,未来肯定需要有支持持久化的存储。
- 需要支持配置,但优先级不高。等基本流程搞定,使用过程中发现足够的痛点,就可以考虑配置文件如何处理了。
当这些问题都敲定下来,系统的基本思路就有了。我们可以先把几个重要的接口定义出来,然后仔细审视这些接口。最重要的几个接口就是三个主体交互的接口:客户端和服务器的接口或者说协议、服务器和命令处理流程的接口、服务器和存储的接口。
(总结就是网络层要灵活可以使用不同的网络协议,信息定义可以用protobuf,服务器处理流程可以加hook保持灵活性,存储可以用trait抽象基本行为保持灵活性。最后还有配置的灵活性)总之就是协议灵活,处理流程灵活,存储行为灵活)
客户端和服务器间的协议
考虑客户端和服务器之间的消息怎么定义的(protobuf)
关于protobuf协议的一些补充知识
(原理,与json,xml优缺点比较,优化方法,如何安装使用)
如何安装:
先下载源码;
再解压 tar -xzf protobuf-2.1.0.tar.gz
再编译安装
./configure
make
make install
protobuf是谷歌开发的一款数据交换格式的工具。可用于序列化反序列化,数据存储,通信协议。
接下来看看proto文件里面主要包含什么?
有关键字message: 代表了实体结构,由多个消息字段(field)组成。
消息字段(field): 包括数据类型、字段名、字段规则(必须初始化,可选初始化,可重复)、字段唯一标识、默认值
message xxx {
// 字段规则:required -> 字段只能也必须出现 1 次
// 字段规则:optional -> 字段可出现 0 次或1次
// 字段规则:repeated -> 字段可出现任意多次(包括 0)相当于数组
// 类型:int32、int64、sint32、sint64、string、32-bit ....
// 字段编号:0 ~ 536870911(除去 19000 到 19999 之间的数字)
字段规则 类型 名称 = 字段编号;
}
字段规则字段规则可以省略,默认是required。
写完这些之后,它是面向开发人员和业务的,想要用于存储或者运输,必须进行序列化和反序列化。
这些谷歌早就包装好了,用protoc编译器。执行下面一行命令;
protoc -I= S R C D I R − − c p p o u t = SRC_DIR --cpp_out= SRCDIR−−cppout=DST_DIR $SRC_DIR/xxx.proto
protoc --cpp_out=. test.proto # 真实执行
cpp_out代表生成C++代码,.代表代码放在当前目录。
执行完后就会生成pb.h pb.c两个桩文件。定义的每一个message都会生成一个类,以及服务的桩类,桩类会绑定一个channel指针,调用calllmethod方法,客户端只要利用stub调用方法就会完成传输参数一系列操作。对于服务类还需要重写一下业务方法。
关于protobuf优点:
空间几倍到十倍,时间优势几十倍:
空间优势 数据量小是因为,Protobuf 序列化后所生成的二进制消息非常紧凑,这得益于 Protobuf
采用的非常巧妙的little-endian编码方法。
时间优势是:xml解析需要把字符串转换成文档对象结构模型,再从模型中读指定节点的字符串,再转成相应类型的变量。其中将 XML 文件转换为文档对象结构模型的过程通常需要完成词法文法分析等大量消耗 CPU 的复杂计算。protobuf序列化与反序列化不需要解析相应的节点属性{},:等符号,和多余的描述信息字段信息描述,所以序列化和反序列化时间效率较高。
跨平台跨语言;兼容性很好,万一消息格式变更,不需要重新写解析代码,在proto文件直接增加减少就可以。
代码生成机制很好:比如发送方序列化直接order.SerailzeToString(&sOrder);
接收方反序列化直接order.ParseFromString(sOrder)。不用自己写解析代码,吃力不讨好,非常好。获取代码,只要调用get,set。
关于protobuf缺点
可读性差,因为是二进制编码的;缺乏自描述,不配合proto文件圈圈不知道消息意义。所以在配置文件方面还是xml比较清楚;
所以protobuf重点在于数据序列化传输或者存储,为xml,json在于结构化数据作为开发和业务的接口;
编码解码的原理介绍
前面说了proto编码节省空间,解码很方便。具体是什么样的?
关于编码原理:采用tag-value形成一个字节流,使用字段号(field`s number和wire_type)作为key,key的后3位位表示的是wire_type,一般type整数时是Varints编码.Varints是一种紧凑型数字表示法,它是用一个或多个字节序列化整数的方法,是一种变长编码,解析的时候也很方遍,位运算可以实现。
varints 编码 使用每个字节的 最高有效位 作为标志位,而剩余的 7位 以二进制补码的 形式 来存储数字值本身, 当最高位有效位 为 1 时,代表其后还跟有字节, 最高有效位为0 时,代表 是 该数字的最后一个字节。还有别的编码比如zigzang等
再加上protobuf比json和XML少了{、}、:这些符号,体积会减少一些。protobuf是tag-value(TLV)的编码方式实现,减少了分隔符的使用,数据存储的更加紧凑。
这三点加在一起使proto节省空间。(二进制,采用tag-value结构紧凑,没有分隔符啥的;采用可变长度varints编码,zigzang)
解码的话也简单了,直接根据字节流,按照proto文件定义来读取。不需要解析分隔符,描述信息,结构信息等
xml实例
用XML表示中国部分省市数据如下:
可以看到,xml是有空格的,有描述信息,结构信息的,解析很麻烦的。
json如下
{
name: “中国”,
provinces: [
{
name: “黑龙江”,
citys: {
city: [“哈尔滨”, “大庆”]
}
},
{
name: “广东”,
citys: {
city: [“广州”, “深圳”, “珠海”]
}
},
]
}
也是类似的结构信息,只不过分隔符不同,用{}表示单个元素,[]表示元素集合
并且xml看起来描述信息更多,因此时间空间最差的。描述性也最好。
首先是客户端和服务器之间的协议。来试着用 protobuf 定义一下我们第一版支持的客户端命令:
syntax = "proto3";
package abi;
// 来自客户端的命令请求
message CommandRequest {
oneof request_data {
Hget hget = 1;
Hgetall hgetall = 2;
Hmget hmget = 3;
Hset hset = 4;
Hmset hmset = 5;
Hdel hdel = 6;
Hmdel hmdel = 7;
Hexist hexist = 8;
Hmexist hmexist = 9;
}
}
// 服务器的响应
message CommandResponse {
// 状态码;复用 HTTP 2xx/4xx/5xx 状态码
uint32 status = 1;
// 如果不是 2xx,message 里包含详细的信息
string message = 2;
// 成功返回的 values
repeated Value values = 3;
// 成功返回的 kv pairs
repeated Kvpair pairs = 4;
}
// 从 table 中获取一个 key,返回 value
message Hget {
string table = 1;
string key = 2;
}
// 从 table 中获取所有的 Kvpair
message Hgetall {
string table = 1; }
// 从 table 中获取一组 key,返回它们的 value
message Hmget {
string table = 1;
repeated string keys = 2;
}
// 返回的值
message Value {
oneof value {
string string = 1;
bytes binary = 2;
int64 integer = 3;
double float = 4;
bool bool = 5;
}
}
// 返回的 kvpair
message Kvpair {
string key = 1;
Value value = 2;
}
// 往 table 里存一个 kvpair,
// 如果 table 不存在就创建这个 table
message Hset {
string table = 1;
Kvpair pair = 2;
}
// 往 table 中存一组 kvpair,
// 如果 table 不存在就创建这个 table
message Hmset {
string table = 1;
repeated Kvpair pairs = 2;
}
// 从 table 中删除一个 key,返回它之前的值
message Hdel {
string table = 1;
string key = 2;
}
// 从 table 中删除一组 key,返回它们之前的值
message Hmdel {
string table = 1;
repeated string keys = 2;
}
// 查看 key 是否存在
message Hexist {
string table = 1;
string key = 2;
}
// 查看一组 key 是否存在
message Hmexist {
string table = 1;
repeated string keys = 2;
}
通过 prost,这个 protobuf 文件可以被编译成 Rust 代码(主要是 struct 和 enum),供我们使用。你应该还记得,之前在第 5 讲谈到 thumbor 的开发时,已经见识到了 prost 处理 protobuf 的方式了。(这里类比一下rpc中C++自动编译proto文件的异同)
CommandService trait
客户端和服务器间的协议敲定之后,就要思考如何处理请求的命令,返回响应。我们目前打算支持 9 种命令,未来可能支持更多命令。所以最好定义一个 trait 来统一处理所有的命令,返回处理结果。在处理命令的时候,需要和存储发生关系,这样才能根据请求中携带的参数读取数据,或者把请求中的数据存入存储系统中。所以,这个 trait 可以这么定义:
/// 对 Command 的处理的抽象
pub trait CommandService {
/// 处理 Command,返回 Response
fn execute(self, store: &impl Storage) -> CommandResponse;
}
有了这个 trait,并且每一个命令都实现了这个 trait 后,dispatch 方法就可以是类似这样的代码:
// 从 Request 中得到 Response,目前处理 HGET/HGETALL/HSET
pub fn dispatch(cmd: CommandRequest, store: &impl Storage) -> CommandResponse {
match cmd.request_data {
Some(RequestData::Hget(param)) => param.execute(store),
Some(RequestData::Hgetall(param)) => param.execute(store),
Some(RequestData::Hset(param)) => param.execute(store),
None => KvError::InvalidCommand("Request has no data".into()).into(),
_ => KvError::Internal("Not implemented".into()).into(),
}
}
这样,未来我们支持新命令时,只需要做两件事:为命令实现 CommandService、在 dispatch 方法中添加新命令的支持。
基本的trait抽象让系统扩展变得简单。
Storage trait
再来看为不同的存储而设计的 Storage trait,它提供 KV store 的主要接口:
/// 对存储的抽象,我们不关心数据存在哪儿,但需要定义外界如何和存储打交道
pub trait Storage {
/// 从一个 HashTable 里获取一个 key 的 value
fn get(&self, table: &str, key: &str) -> Result<Option<Value>, KvError>;
/// 从一个 HashTable 里设置一个 key 的 value,返回旧的 value
fn set(&self, table: &str, key: String, value: Value) -> Result<Option<Value>, KvError>;
/// 查看 HashTable 中是否有 key
fn contains(&self, table: &str, key: &str) -> Result<bool, KvError>;
/// 从 HashTable 中删除一个 key
fn del(&self, table: &str, key: &str) -> Result<Option<Value>, KvError>;
/// 遍历 HashTable,返回所有 kv pair(这个接口不好)
fn get_all(&self, table: &str) -> Result<Vec<Kvpair>, KvError>;
/// 遍历 HashTable,返回 kv pair 的 Iterator
fn get_iter(&self, table: &str) -> Result<Box<dyn Iterator<Item = Kvpair>>, KvError>;
}
在 CommandService trait 中已经看到,在处理客户端请求的时候,与之打交道的是 Storage trait,而非具体的某个 store。这样做的好处是,未来根据业务的需要,在不同的场景下添加不同的 store,只需要为其实现 Storage trait 即可,不必修改 CommandService 有关的代码。
比如在 HGET 命令的实现时,我们使用 Storage::get 方法,从 table 中获取数据,它跟某个具体的存储方案无关:
(这一点可以看出来rust中的trait可以实现更加高级的抽象,这和设计模式中的一个原则(依赖倒置原则也就是交互最好和上层的抽象交互,这样可扩展性更好)
impl CommandService for Hget {
fn execute(self, store: &impl Storage) -> CommandResponse {
match store.get(&self.table, &self.key) {
Ok(Some(v)) => v.into(),
Ok(None) => KvError::NotFound(self.table, self.key).into(),
Err(e) => e.into(),
}
}
}
Storage trait 里面的绝大多数方法相信你可以定义出来,但 get_iter() 这个接口可能你会比较困惑,因为它返回了一个 Box,为什么?之前(第 13 讲)讲过这是 trait object。
这里我们想返回一个 iterator,调用者不关心它具体是什么类型,只要可以不停地调用 next() 方法取到下一个值就可以了。不同的实现,可能返回不同的 iterator,如果要用同一个接口承载,我们需要使用 trait object。在使用 trait object 时,因为 Iterator 是个带有关联类型的 trait,所以这里需要指明关联类型 Item 是什么类型,这样调用者才好拿到这个类型进行处理。
小结
到现在,我们梳理了 KV server 的主要需求和主流程,思考了流程中可能出现的问题,也敲定了三个重要的接口:客户端和服务器的协议、CommandService trait、Storage trait。下一讲继续实现 KV server,在看讲解之前,你可以先想一想自己平时是怎么开发的。
思考题
想一想,对于 Storage trait,为什么返回值都用了 Result?在实现 MemTable 的时候,似乎所有返回都是 Ok(T) 啊?
(我觉得Storage作为trait,需要关注IO操作失败的错误情况,而MemTable实现,都是内存操作,几乎不会失败,所以返回Ok(T)就可以了)
上篇我们的 KV store 刚开了个头,写好了基本的接口。你是不是摩拳擦掌准备开始写具体实现的代码了?别着急,当定义好接口后,先不忙实现,在撰写更多代码前,我们可以从一个使用者的角度来体验接口如何使用、是否好用,反观设计有哪些地方有待完善。还是按照上一讲定义接口的顺序来一个一个测试:首先我们来构建协议层。
实现并验证协议层
先创建一个项目:cargo new kv --lib。进入到项目目录,在 Cargo.toml 中添加依赖:
[package]
name = "kv"
version = "0.1.0"
edition = "2018"
[dependencies]
bytes = "1" # 高效处理网络 buffer 的库
prost = "0.8" # 处理 protobuf 的代码
tracing = "0.1" # 日志处理
[dev-dependencies]
anyhow = "1" # 错误处理
async-prost = "0.2.1" # 支持把 protobuf 封装成 TCP frame
futures = "0.3" # 提供 Stream trait
tokio = {
version = "1", features = ["rt", "rt-multi-thread", "io-util", "macros", "net" ] } # 异步网络库
tracing-subscriber = "0.2" # 日志处理
[build-dependencies]
prost-build = "0.8" # 编译 protobuf
然后在项目根目录下创建 abi.proto,把上文中 protobuf 的代码放进去。在根目录下,再创建 build.rs:
fn main() {
let mut config = prost_build::Config::new();
config.bytes(&["."]);
config.type_attribute(".", "#[derive(PartialOrd)]");
config
.out_dir("src/pb")
.compile_protos(&["abi.proto"], &["."])
.unwrap();
}
这个代码在第 5 讲已经见过了,build.rs 在编译期运行来进行额外的处理。
这里我们为编译出来的代码额外添加了一些属性。比如为 protobuf 的 bytes 类型生成 Bytes 而非缺省的 Vec,为所有类型加入 PartialOrd 派生宏。关于 prost-build 的扩展,你可以看文档。
记得创建 src/pb 目录,否则编不过。现在,在项目根目录下做 cargo build 会生成 src/pb/abi.rs 文件,里面包含所有 protobuf 定义的消息的 Rust 数据结构。我们创建 src/pb/mod.rs,引入 abi.rs,并做一些基本的类型转换:
pub mod abi;
use abi::{
command_request::RequestData, *};
impl CommandRequest {
/// 创建 HSET 命令
pub fn new_hset(table: impl Into<String>, key: impl Into<String>, value: Value) -> Self {
Self {
request_data: Some(RequestData::Hset(Hset {
table: table.into(),
pair: Some(Kvpair::new(key, value)),
})),
}
}
}
impl Kvpair {
/// 创建一个新的 kv pair
pub fn new(key: impl Into<String>, value: Value) -> Self {
Self {
key: key.into(),
value: Some(value),
}
}
}
/// 从 String 转换成 Value
impl From<String> for Value {
fn from(s: String) -> Self {
Self {
value: Some(value::Value::String(s)),
}
}
}
/// 从 &str 转换成 Value
impl From<&str> for Value {
fn from(s: &str) -> Self {
Self {
value: Some(value::Value::String(s.into())),
}
}
}
最后,在 src/lib.rs 中,引入 pb 模块:
mod pb;
pub use pb::abi::*;
这样,我们就有了能把 KV server 最基本的 protobuf 接口运转起来的代码。在根目录下创建 examples,这样可以写一些代码测试客户端和服务器之间的协议。我们可以先创建一个 examples/client.rs 文件,写入如下代码:
use anyhow::Result;
use async_prost::AsyncProstStream;
use futures::prelude::*;
use kv::{
CommandRequest, CommandResponse};
use tokio::net::TcpStream;
use tracing::info;
#[tokio::main]
async fn main() -> Result<()> {
tracing_subscriber::fmt::init();
let addr = "127.0.0.1:9527";
// 连接服务器
let stream = TcpStream::connect(addr).await?;
// 使用 AsyncProstStream 来处理 TCP Frame
let mut client =
AsyncProstStream::<_, CommandResponse, CommandRequest, _>::from(stream).for_async();
// 生成一个 HSET 命令
let cmd = CommandRequest::new_hset("table1", "hello", "world".into());
// 发送 HSET 命令
client.send(cmd).await?;
if let Some(Ok(data)) = client.next().await {
info!("Got response {:?}", data);
}
Ok(())
}
这段代码连接服务器的 9527 端口,发送一个 HSET 命令出去,然后等待服务器的响应。
同样的,我们创建一个 examples/dummy_server.rs 文件,写入代码:
use anyhow::Result;
use async_prost::AsyncProstStream;
use futures::prelude::*;
use kv::{
CommandRequest, CommandResponse};
use tokio::net::TcpListener;
use tracing::info;
#[tokio::main]
async fn main() -> Result<()> {
tracing_subscriber::fmt::init();
let addr = "127.0.0.1:9527";
let listener = TcpListener::bind(addr).await?;
info!("Start listening on {}", addr);
loop {
let (stream, addr) = listener.accept().await?;
info!("Client {:?} connected", addr);
tokio::spawn(async move {
let mut stream =
AsyncProstStream::<_, CommandRequest, CommandResponse, _>::from(stream).for_async();
while let Some(Ok(msg)) = stream.next().await {
info!("Got a new command: {:?}", msg);
// 创建一个 404 response 返回给客户端
let mut resp = CommandResponse::default();
resp.status = 404;
resp.message = "Not found".to_string();
stream.send(resp).await.unwrap();
}
info!("Client {:?} disconnected", addr);
});
}
}
在这段代码里,服务器监听 9527 端口,对任何客户端的请求,一律返回 status = 404,message 是 “Not found” 的响应。
如果你对这两段代码中的异步和网络处理半懂不懂,没关系,你先把代码抄下来运行。今天的内容跟网络无关,你重点看处理流程就行。未来会讲到网络和异步处理的。
我们可以打开一个命令行窗口,运行:RUST_LOG=info cargo run --example dummy_server --quiet。然后在另一个命令行窗口,运行:RUST_LOG=info cargo run --example client --quiet。
此时,服务器和客户端都收到了彼此的请求和响应,协议层看上去运作良好。一旦验证通过,就你可以进入下一步,因为协议层的其它代码都只是工作量而已,在之后需要的时候可以慢慢实现。
总结**:写好protobuf文件后用protos编译成rust代码,主要是rust结构体信息。然后实现其中一个命令比如hset:**
pub fn new_hset(table: impl Into, key: impl Into, value: Value) -> Self 并做一些类型转换。
然后写客户端: // 生成一个 HSET 命令
let cmd = CommandRequest::new_hset(“table1”, “hello”, “world”.into());
// 发送 HSET 命令
client.send(cmd).await?;
客户端收到信息后回复一个404,收到就说明这部分没问题了。
实现并验证 Storage trait
接下来构建 Storage trait。
我们上一讲谈到了如何使用嵌套的支持并发的 im-memory HashMap 来实现 storage trait。由于 Arc>> 这样的支持并发的 HashMap 是一个刚需,Rust 生态有很多相关的 crate 支持,这里我们可以使用 dashmap 创建一个 MemTable 结构,来实现 Storage trait。
先创建 src/storage 目录,然后创建 src/storage/mod.rs,把刚才讨论的 trait 代码放进去后,在 src/lib.rs 中引入 “mod storage”。此时会发现一个错误:并未定义 KvError。
所以来定义 KvError。第 18 讲讨论错误处理时简单演示了,如何使用 thiserror 的派生宏来定义错误类型,今天就用它来定义 KvError。创建 src/error.rs,然后填入:
use crate::Value;
use thiserror::Error;
#[derive(Error, Debug, PartialEq)]
pub enum KvError {
#[error("Not found for table: {0}, key: {1}")]
NotFound(String, String),
#[error("Cannot parse command: `{0}`")]
InvalidCommand(String),
#[error("Cannot convert value {:0} to {1}")]
ConvertError(Value, &'static str),
#[error("Cannot process command {0} with table: {1}, key: {2}. Error: {}")]
StorageError(&'static str, String, String, String),
#[error("Failed to encode protobuf message")]
EncodeError(#[from] prost::EncodeError),
#[error("Failed to decode protobuf message")]
DecodeError(#[from] prost::DecodeError),
#[error("Internal error: {0}")]
Internal(String),
}
这些 error 的定义其实是在实现过程中逐步添加的,但为了讲解方便,先一次性添加。对于 Storage 的实现,我们只关心 StorageError,其它的 error 定义未来会用到。
同样,在 src/lib.rs 下引入 mod error,现在 src/lib.rs 是这个样子的:
mod error;
mod pb;
mod storage;
pub use error::KvError;
pub use pb::abi::*;
pub use storage::*;
src/storage/mod.rs 是这个样子的:
use crate::{
KvError, Kvpair, Value};
/// 对存储的抽象,我们不关心数据存在哪儿,但需要定义外界如何和存储打交道
pub trait Storage {
/// 从一个 HashTable 里获取一个 key 的 value
fn get(&self, table: &str, key: &str) -> Result<Option<Value>, KvError>;
/// 从一个 HashTable 里设置一个 key 的 value,返回旧的 value
fn set(&self, table: &str, key: String, value: Value) -> Result<Option<Value>, KvError>;
/// 查看 HashTable 中是否有 key
fn contains(&self, table: &str, key: &str) -> Result<bool, KvError>;
/// 从 HashTable 中删除一个 key
fn del(&self, table: &str, key: &str) -> Result<Option<Value>, KvError>;
/// 遍历 HashTable,返回所有 kv pair(这个接口不好)
fn get_all(&self, table: &str) -> Result<Vec<Kvpair>, KvError>;
/// 遍历 HashTable,返回 kv pair 的 Iterator
fn get_iter(&self, table: &str) -> Result<Box<dyn Iterator<Item = Kvpair>>, KvError>;
}
代码目前没有编译错误,可以在这个文件末尾添加测试代码,尝试使用这些接口了,当然,我们还没有构建 MemTable,但通过 Storage trait 已经大概知道 MemTable 怎么用,所以可以先写段测试体验一下:
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn memtable_basic_interface_should_work() {
let store = MemTable::new();
test_basi_interface(store);
}
#[test]
fn memtable_get_all_should_work() {
let store = MemTable::new();
test_get_all(store);
}
fn test_basi_interface(store: impl Storage) {
// 第一次 set 会创建 table,插入 key 并返回 None(之前没值)
let v = store.set("t1", "hello".into(), "world".into());
assert!(v.unwrap().is_none());
// 再次 set 同样的 key 会更新,并返回之前的值
let v1 = store.set("t1", "hello".into(), "world1".into());
assert_eq!(v1, Ok(Some("world".into())));
// get 存在的 key 会得到最新的值
let v = store.get("t1", "hello");
assert_eq!(v, Ok(Some("world1".into())));
// get 不存在的 key 或者 table 会得到 None
assert_eq!(Ok(None), store.get("t1", "hello1"));
assert!(store.get("t2", "hello1").unwrap().is_none());
// contains 纯在的 key 返回 true,否则 false
assert_eq!(store.contains("t1", "hello"), Ok(true));
assert_eq!(store.contains("t1", "hello1"), Ok(false));
assert_eq!(store.contains("t2", "hello"), Ok(false));
// del 存在的 key 返回之前的值
let v = store.del("t1", "hello");
assert_eq!(v, Ok(Some("world1".into())));
// del 不存在的 key 或 table 返回 None
assert_eq!(Ok(None), store.del("t1", "hello1"));
assert_eq!(Ok(None), store.del("t2", "hello"));
}
fn test_get_all(store: impl Storage) {
store.set("t2", "k1".into(), "v1".into()).unwrap();
store.set("t2", "k2".into(), "v2".into()).unwrap();
let mut data = store.get_all("t2").unwrap();
data.sort_by(|a, b| a.partial_cmp(b).unwrap());
assert_eq!(
data,
vec![
Kvpair::new("k1", "v1".into()),
Kvpair::new("k2", "v2".into())
]
)
}
fn test_get_iter(store: impl Storage) {
store.set("t2", "k1".into(), "v1".into()).unwrap();
store.set("t2", "k2".into(), "v2".into()).unwrap();
let mut data: Vec<_> = store.get_iter("t2").unwrap().collect();
data.sort_by(|a, b| a.partial_cmp(b).unwrap());
assert_eq!(
data,
vec![
Kvpair::new("k1", "v1".into()),
Kvpair::new("k2", "v2".into())
]
)
}
}
这种在写实现之前写单元测试,是标准的 TDD(Test-Driven Development)方式。
我个人不是 TDD 的狂热粉丝,但会在构建完 trait 后,为这个 trait 撰写测试代码,因为写测试代码是个很好的验证接口是否好用的时机。毕竟我们不希望实现 trait 之后,才发现 trait 的定义有瑕疵,需要修改,这个时候改动的代价就比较大了。
所以,当 trait 推敲完毕,就可以开始写使用 trait 的测试代码了。在使用过程中仔细感受,如果写测试用例时用得不舒服,或者为了使用它需要做很多繁琐的操作,那么可以重新审视 trait 的设计。
你如果仔细看单元测试的代码,就会发现我始终秉持测试 trait 接口的思想。尽管在测试中需要一个实际的数据结构进行 trait 方法的测试,但核心的测试代码都用的泛型函数,让这些代码只跟 trait 相关。
这样,一来可以避免某个具体 trait 实现的干扰,二来在之后想加入更多 trait 实现时,可以共享测试代码。比如未来想支持 DiskTable,那么只消加几个测试例,调用已有的泛型函数即可。
好,搞定测试,确认 trait 设计没有什么问题之后,我们来写具体实现。可以创建 src/storage/memory.rs 来构建 MemTable:
use crate::{
KvError, Kvpair, Storage, Value};
use dashmap::{
mapref::one::Ref, DashMap};
/// 使用 DashMap 构建的 MemTable,实现了 Storage trait
#[derive(Clone, Debug, Default)]
pub struct MemTable {
tables: DashMap<String, DashMap<String, Value>>,
}
impl MemTable {
/// 创建一个缺省的 MemTable
pub fn new() -> Self {
Self::default()
}
/// 如果名为 name 的 hash table 不存在,则创建,否则返回
fn get_or_create_table(&self, name: &str) -> Ref<String, DashMap<String, Value>> {
match self.tables.get(name) {
Some(table) => table,
None => {
let entry = self.tables.entry(name.into()).or_default();
entry.downgrade()
}
}
}
}
impl Storage for MemTable {
fn get(&self, table: &str, key: &str) -> Result<Option<Value>, KvError> {
let table = self.get_or_create_table(table);
Ok(table.get(key).map(|v| v.value().clone()))
}
fn set(&self, table: &str, key: String, value: Value) -> Result<Option<Value>, KvError> {
let table = self.get_or_create_table(table);
Ok(table.insert(key, value))
}
fn contains(&self, table: &str, key: &str) -> Result<bool, KvError> {
let table = self.get_or_create_table(table);
Ok(table.contains_key(key))
}
fn del(&self, table: &str, key: &str) -> Result<Option<Value>, KvError> {
let table = self.get_or_create_table(table);
Ok(table.remove(key).map(|(_k, v)| v))
}
fn get_all(&self, table: &str) -> Result<Vec<Kvpair>, KvError> {
let table = self.get_or_create_table(table);
Ok(table
.iter()
.map(|v| Kvpair::new(v.key(), v.value().clone()))
.collect())
}
fn get_iter(&self, _table: &str) -> Result<Box<dyn Iterator<Item = Kvpair>>, KvError> {
todo!()
}
}
除了 get_iter() 外,这个实现代码非常简单,相信你看一下 dashmap 的文档,也能很快写出来。get_iter() 写起来稍微有些难度,我们先放下不表,会在下一篇 KV server 讲。如果你对此感兴趣,想挑战一下,欢迎尝试
。实现完成之后,我们可以测试它是否符合预期。注意现在 src/storage/memory.rs 还没有被添加,所以 cargo 并不会编译它。要在 src/storage/mod.rs 开头添加代码:
mod memory;
pub use memory::MemTable;
这样代码就可以编译通过了。因为还没有实现 get_iter 方法,所以这个测试需要被注释掉:
// #[test]
// fn memtable_iter_should_work() {
// let store = MemTable::new();
// test_get_iter(store);
// }
如果你运行 cargo test ,可以看到测试都通过了:
> cargo test
Compiling kv v0.1.0 (/Users/tchen/projects/mycode/rust/geek-time-rust-resources/21/kv)
Finished test [unoptimized + debuginfo] target(s) in 1.95s
Running unittests (/Users/tchen/.target/debug/deps/kv-8d746b0f387a5271)
running 2 tests
test storage::tests::memtable_basic_interface_should_work ... ok
test storage::tests::memtable_get_all_should_work ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests kv
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
store测试总结:
存储trait有一些方法,比如get,set等。我们先不急着实现它,我们先写测试代码。当然,我们还没有构建 MemTable,但通过 Storage trait 已经大概知道 MemTable 怎么用:
比如
fn memtable_basic_interface_should_work() {
let store = MemTable::new();
test_set(store);
}
fn test_set(store: impl Storage) {
// 第一次 set 会创建 table,插入 key 并返回 None(之前没值)
let v = store.set("t1", "hello".into(), "world".into());
assert!(v.unwrap().is_none());
// 再次 set 同样的 key 会更新,并返回之前的值
let v1 = store.set("t1", "hello".into(), "world1".into());
assert_eq!(v1, Ok(Some("world".into())));
可以看到,测试代码中,先新建一个内存表(具体实现后面再说),然后测试set接口。如果测试成功,说明接口没问题。
这里体现了测试代码稳定的TDD思想,对具体fn测试,对trait参数进行测试 store: impl Storage,这种泛型可以在以后增加新的存储类型比如磁盘存储,可以复用测试代码。另外不会因为一个trait的具体实现影响其他实现方法。
另外测试代码也能让你感觉拟设计trait中的方法好不好用,不好就赶紧改,不要等trait方法实现好以后再改,麻烦了。
测试代码写好以后,感觉定义的fn都合适,就开始实现,首先要定义memtable,他其实是dashmap,适合并发的哈希表,分别代表
表名,表的键和值。
pub struct MemTable {
tables: DashMap<String, DashMap<String, Value>>,
}
为表实现new函数和get_or_create_table()函数
然后具体为memtable实现trait定义的fn.
impl Storage for MemTable {
fn get(&self, table: &str, key: &str) -> Result<Option<Value>, KvError> {
let table = self.get_or_create_table(table);//判断表是否存在,不存在创建,存在的话返回这个表
Ok(table.get(key).map(|v| v.value().clone()))
}
}
实现并验证 CommandService trait
Storage trait 我们就算基本验证通过了,现在再来验证 CommandService。我们创建 src/service 目录,以及 src/service/mod.rs 和 src/service/command_service.rs 文件,并在 src/service/mod.rs 写入:
use crate::*;
mod command_service;
/// 对 Command 的处理的抽象
pub trait CommandService {
/// 处理 Command,返回 Response
fn execute(self, store: &impl Storage) -> CommandResponse;
}
不要忘记在 src/lib.rs 中加入 service:
mod error;
mod pb;
mod service;
mod storage;
pub use error::KvError;
pub use pb::abi::*;
pub use service::*;
pub use storage::*;
然后,在 src/service/command_service.rs 中,我们可以先写一些测试。为了简单起见,就列 HSET、HGET、HGETALL 三个命令:
use crate::*;
#[cfg(test)]
mod tests {
use super::*;
use crate::command_request::RequestData;
#[test]
fn hset_should_work() {
let store = MemTable::new();
let cmd = CommandRequest::new_hset("t1", "hello", "world".into());
let res = dispatch(cmd.clone(), &store);
assert_res_ok(res, &[Value::default()], &[]);
let res = dispatch(cmd, &store);
assert_res_ok(res, &["world".into()], &[]);
}
#[test]
fn hget_should_work() {
let store = MemTable::new();
let cmd = CommandRequest::new_hset("score", "u1", 10.into());
dispatch(cmd, &store);
let cmd = CommandRequest::new_hget("score", "u1");
let res = dispatch(cmd, &store);
assert_res_ok(res, &[10.into()], &[]);
}
#[test]
fn hget_with_non_exist_key_should_return_404() {
let store = MemTable::new();
let cmd = CommandRequest::new_hget("score", "u1");
let res = dispatch(cmd, &store);
assert_res_error(res, 404, "Not found");
}
#[test]
fn hgetall_should_work() {
let store = MemTable::new();
let cmds = vec![
CommandRequest::new_hset("score", "u1", 10.into()),
CommandRequest::new_hset("score", "u2", 8.into()),
CommandRequest::new_hset("score", "u3", 11.into()),
CommandRequest::new_hset("score", "u1", 6.into()),
];
for cmd in cmds {
dispatch(cmd, &store);
}
let cmd = CommandRequest::new_hgetall("score");
let res = dispatch(cmd, &store);
let pairs = &[
Kvpair::new("u1", 6.into()),
Kvpair::new("u2", 8.into()),
Kvpair::new("u3", 11.into()),
];
assert_res_ok(res, &[], pairs);
}
// 从 Request 中得到 Response,目前处理 HGET/HGETALL/HSET
fn dispatch(cmd: CommandRequest, store: &impl Storage) -> CommandResponse {
match cmd.request_data.unwrap() {
RequestData::Hget(v) => v.execute(store),
RequestData::Hgetall(v) => v.execute(store),
RequestData::Hset(v) => v.execute(store),
_ => todo!(),
}
}
// 测试成功返回的结果
fn assert_res_ok(mut res: CommandResponse, values: &[Value], pairs: &[Kvpair]) {
res.pairs.sort_by(|a, b| a.partial_cmp(b).unwrap());
assert_eq!(res.status, 200);
assert_eq!(res.message, "");
assert_eq!(res.values, values);
assert_eq!(res.pairs, pairs);
}
// 测试失败返回的结果
fn assert_res_error(res: CommandResponse, code: u32, msg: &str) {
assert_eq!(res.status, code);
assert!(res.message.contains(msg));
assert_eq!(res.values, &[]);
assert_eq!(res.pairs, &[]);
}
}
这些测试的作用就是验证产品需求,
比如:HSET 成功返回上一次的值(这和 Redis 略有不同,Redis 返回表示多少 key 受影响的一个整数)
HGET 返回 Value
HGETALL 返回一组无序的 Kvpair
目前这些测试是无法编译通过的,因为里面使用了一些未定义的方法,比如 10.into():想把整数 10 转换成一个 Value、CommandRequest::new_hgetall(“score”):想生成一个 HGETALL 命令。
为什么要这么写?因为如果是 CommandService 接口的使用者,自然希望使用这个接口的时候,调用的整体感觉非常简单明了。
如果接口期待一个 Value,但在上下文中拿到的是 10、“hello” 这样的值,那我们作为设计者就要考虑为 Value 实现 From,这样调用的时候最方便。同样的,对于生成 CommandRequest 这个数据结构,也可以添加一些辅助函数,来让调用更清晰。到现在为止我们写了两轮测试了,相信你对测试代码的作用有大概理解。我们来总结一下:
验证并帮助接口迭代
验证产品需求
通过使用核心逻辑,帮助我们更好地思考外围逻辑并反推其实现
前两点是最基本的,也是很多人对 TDD 的理解,其实还有更重要的也就是第三点。除了前面的辅助函数外,我们在测试代码中还看到了 dispatch 函数,它目前用来辅助测试。但紧接着你会发现,这样的辅助函数,可以合并到核心代码中。这才是“测试驱动开发”的实质。
好,根据测试,我们需要在 src/pb/mod.rs 中添加相关的外围逻辑,首先是 CommandRequest 的一些方法,之前写了 new_hset,现在再加入 new_hget 和 new_hgetall:
impl CommandRequest {
/// 创建 HGET 命令
pub fn new_hget(table: impl Into<String>, key: impl Into<String>) -> Self {
Self {
request_data: Some(RequestData::Hget(Hget {
table: table.into(),
key: key.into(),
})),
}
}
/// 创建 HGETALL 命令
pub fn new_hgetall(table: impl Into<String>) -> Self {
Self {
request_data: Some(RequestData::Hgetall(Hgetall {
table: table.into(),
})),
}
}
/// 创建 HSET 命令
pub fn new_hset(table: impl Into<String>, key: impl Into<String>, value: Value) -> Self {
Self {
request_data: Some(RequestData::Hset(Hset {
table: table.into(),
pair: Some(Kvpair::new(key, value)),
})),
}
}
}
然后写对 Value 的 From 的实现:
/// 从 i64转换成 Value
impl From<i64> for Value {
fn from(i: i64) -> Self {
Self {
value: Some(value::Value::Integer(i)),
}
}
}
测试代码目前就可以编译通过了,然而测试显然会失败,因为还没有做具体的实现。我们在 src/service/command_service.rs 下添加 trait 的实现代码:
impl CommandService for Hget {
fn execute(self, store: &impl Storage) -> CommandResponse {
match store.get(&self.table, &self.key) {
Ok(Some(v)) => v.into(),
Ok(None) => KvError::NotFound(self.table, self.key).into(),
Err(e) => e.into(),
}
}
}
impl CommandService for Hgetall {
fn execute(self, store: &impl Storage) -> CommandResponse {
match store.get_all(&self.table) {
Ok(v) => v.into(),
Err(e) => e.into(),
}
}
}
impl CommandService for Hset {
fn execute(self, store: &impl Storage) -> CommandResponse {
match self.pair {
Some(v) => match store.set(&self.table, v.key, v.value.unwrap_or_default()) {
Ok(Some(v)) => v.into(),
Ok(None) => Value::default().into(),
Err(e) => e.into(),
},
None => Value::default().into(),
}
}
}
这自然会引发更多的编译错误,因为我们很多地方都是用了 into() 方法,却没有实现相应的转换,比如,Value 到 CommandResponse 的转换、KvError 到 CommandResponse 的转换、Vec 到 CommandResponse 的转换等等。
所以在 src/pb/mod.rs 里继续补上相应的外围逻辑:
/// 从 Value 转换成 CommandResponse
impl From<Value> for CommandResponse {
fn from(v: Value) -> Self {
Self {
status: StatusCode::OK.as_u16() as _,
values: vec![v],
..Default::default()
}
}
}
/// 从 Vec<Kvpair> 转换成 CommandResponse
impl From<Vec<Kvpair>> for CommandResponse {
fn from(v: Vec<Kvpair>) -> Self {
Self {
status: StatusCode::OK.as_u16() as _,
pairs: v,
..Default::default()
}
}
}
/// 从 KvError 转换成 CommandResponse
impl From<KvError> for CommandResponse {
fn from(e: KvError) -> Self {
let mut result = Self {
status: StatusCode::INTERNAL_SERVER_ERROR.as_u16() as _,
message: e.to_string(),
values: vec![],
pairs: vec![],
};
match e {
KvError::NotFound(_, _) => result.status = StatusCode::NOT_FOUND.as_u16() as _,
KvError::InvalidCommand(_) => result.status = StatusCode::BAD_REQUEST.as_u16() as _,
_ => {
}
}
result
}
}
从前面写接口到这里具体实现,不知道你是否感受到了这样一种模式:在 Rust 下,但凡出现两个数据结构 v1 到 v2 的转换,你都可以先以 v1.into() 来表示这个逻辑,继续往下写代码,之后再去补 From 的实现。如果 v1 和 v2 都不是你定义的数据结构,那么你需要把其中之一用 struct 包装一下,来绕过(第 14 讲)之前提到的孤儿规则。
你学完这节课可以再去回顾一下第 6 讲,仔细思考一下当时说的“绝大多数处理逻辑都是把数据从一个接口转换成另一个接口”。
现在代码应该可以编译通过并测试通过了,你可以 cargo test 测试一下。
最后的拼图:Service 结构的实现
好,所有的接口,包括客户端 / 服务器的协议接口、Storage trait 和 CommandService trait 都验证好了,接下来就是考虑如何用一个数据结构把所有这些东西串联起来。
依旧从使用者的角度来看如何调用它。为此,我们在 src/service/mod.rs 里添加如下的测试代码:
#[cfg(test)]
mod tests {
use super::*;
use crate::{
MemTable, Value};
#[test]
fn service_should_works() {
// 我们需要一个 service 结构至少包含 Storage
let service = Service::new(MemTable::default());
// service 可以运行在多线程环境下,它的 clone 应该是轻量级的
let cloned = service.clone();
// 创建一个线程,在 table t1 中写入 k1, v1
let handle = thread::spawn(move || {
let res = cloned.execute(CommandRequest::new_hset("t1", "k1", "v1".into()));
assert_res_ok(res, &[Value::default()], &[]);
});
handle.join().unwrap();
// 在当前线程下读取 table t1 的 k1,应该返回 v1
let res = service.execute(CommandRequest::new_hget("t1", "k1"));
assert_res_ok(res, &["v1".into()], &[]);
}
}
#[cfg(test)]
use crate::{
Kvpair, Value};
// 测试成功返回的结果
#[cfg(test)]
pub fn assert_res_ok(mut res: CommandResponse, values: &[Value], pairs: &[Kvpair]) {
res.pairs.sort_by(|a, b| a.partial_cmp(b).unwrap());
assert_eq!(res.status, 200);
assert_eq!(res.message, "");
assert_eq!(res.values, values);
assert_eq!(res.pairs, pairs);
}
// 测试失败返回的结果
#[cfg(test)]
pub fn assert_res_error(res: CommandResponse, code: u32, msg: &str) {
assert_eq!(res.status, code);
assert!(res.message.contains(msg));
assert_eq!(res.values, &[]);
assert_eq!(res.pairs, &[]);
}
注意,这里的 assert_res_ok() 和 assert_res_error() 是从 src/service/command_service.rs 中挪过来的。在开发的过程中,不光产品代码需要不断重构,测试代码也需要重构来贯彻 DRY 思想。
我见过很多生产环境的代码,产品功能部分还说得过去,但测试代码像是个粪坑,经年累月地 copy/paste 使其臭气熏天,每个开发者在添加新功能的时候,都掩着鼻子往里扔一坨走人,使得维护难度越来越高,每次需求变动,都涉及一大坨测试代码的变动,这样非常不好。
测试代码的质量也要和产品代码的质量同等要求。好的开发者写的测试代码的可读性也是非常强的。你可以对比上面写的三段测试代码多多感受。
在撰写测试的时候,我们要特别注意:测试代码要围绕着系统稳定的部分,也就是接口,来测试,而尽可能少地测试实现。这是我对这么多年工作中血淋淋的教训的深刻总结。
因为产品代码和测试代码,两者总需要一个是相对稳定的,既然产品代码会不断地根据需求变动,测试代码就必然需要稳定一些。
那什么样的测试代码是稳定的?测试接口的代码是稳定的。只要接口不变,无论具体实现如何变化,哪怕今天引入一个新的算法,明天重写实现,测试代码依旧能够凛然不动,做好产品质量的看门狗。
好,我们回来写代码。在这段测试中,已经敲定了 Service 这个数据结构的使用蓝图,它可以跨线程,可以调用 execute 来执行某个 CommandRequest 命令,返回 CommandResponse。
根据这些想法,在 src/service/mod.rs 里添加 Service 的声明和实现:
/// Service 数据结构
pub struct Service<Store = MemTable> {
inner: Arc<ServiceInner<Store>>,
}
impl<Store> Clone for Service<Store> {
fn clone(&self) -> Self {
Self {
inner: Arc::clone(&self.inner),
}
}
}
/// Service 内部数据结构
pub struct ServiceInner<Store> {
store: Store,
}
impl<Store: Storage> Service<Store> {
pub fn new(store: Store) -> Self {
Self {
inner: Arc::new(ServiceInner {
store }),
}
}
pub fn execute(&self, cmd: CommandRequest) -> CommandResponse {
debug!("Got request: {:?}", cmd);
// TODO: 发送 on_received 事件
let res = dispatch(cmd, &self.inner.store);
debug!("Executed response: {:?}", res);
// TODO: 发送 on_executed 事件
res
}
}
// 从 Request 中得到 Response,目前处理 HGET/HGETALL/HSET
pub fn dispatch(cmd: CommandRequest, store: &impl Storage) -> CommandResponse {
match cmd.request_data {
Some(RequestData::Hget(param)) => param.execute(store),
Some(RequestData::Hgetall(param)) => param.execute(store),
Some(RequestData::Hset(param)) => param.execute(store),
None => KvError::InvalidCommand("Request has no data".into()).into(),
_ => KvError::Internal("Not implemented".into()).into(),
}
}
这段代码有几个地方值得注意:
首先 Service 结构内部有一个 ServiceInner 存放实际的数据结构,Service 只是用 Arc 包裹了 ServiceInner。这也是 Rust 的一个惯例,把需要在多线程下 clone 的主体和其内部结构分开,这样代码逻辑更加清晰。
execute() 方法目前就是调用了 dispatch,但它未来潜在可以做一些事件分发。这样处理体现了 SRP(Single Responsibility Principle)原则。
dispatch 其实就是把测试代码的 dispatch 逻辑移动过来改动了一下。
再一次,我们重构了测试代码,把它的辅助函数变成了产品代码的一部分。现在,你可以运行 cargo test 测试一下,如果代码无法编译,可能是缺一些 use 代码,比如
use crate::{
command_request::RequestData, CommandRequest, CommandResponse, KvError, MemTable, Storage,
};
use std::sync::Arc;
use tracing::debug;
新的 server
现在处理逻辑已经都完成了,可以写个新的 example 测试服务器代码。
把之前的 examples/dummy_server.rs 复制一份,成为 examples/server.rs,然后引入 Service,主要的改动就三句:
// main 函数开头,初始化 service
let service: Service = Service::new(MemTable::new());
// tokio::spawn 之前,复制一份 service
let svc = service.clone();
// while loop 中,使用 svc 来执行 cmd
let res = svc.execute(cmd);
你可以试着自己修改。完整的代码如下:
use anyhow::Result;
use async_prost::AsyncProstStream;
use futures::prelude::*;
use kv::{
CommandRequest, CommandResponse, MemTable, Service};
use tokio::net::TcpListener;
use tracing::info;
#[tokio::main]
async fn main() -> Result<()> {
tracing_subscriber::fmt::init();
let service: Service = Service::new(MemTable::new());
let addr = "127.0.0.1:9527";
let listener = TcpListener::bind(addr).await?;
info!("Start listening on {}", addr);
loop {
let (stream, addr) = listener.accept().await?;
info!("Client {:?} connected", addr);
let svc = service.clone();
tokio::spawn(async move {
let mut stream =
AsyncProstStream::<_, CommandRequest, CommandResponse, _>::from(stream).for_async();
while let Some(Ok(cmd)) = stream.next().await {
let res = svc.execute(cmd);
stream.send(res).await.unwrap();
}
info!("Client {:?} disconnected", addr);
});
}
}
完成之后,打开一个命令行窗口,运行:RUST_LOG=info cargo run --example server --quiet,然后在另一个命令行窗口,运行:RUST_LOG=info cargo run --example client --quiet。此时,服务器和客户端都收到了彼此的请求和响应,并且处理正常。我们的 KV server 第一版的基本功能就完工了!当然,目前还只处理了 3 个命令,剩下 6 个需要你自己完成。
小结
KV server 并不是一个很难的项目,但想要把它写好,并不简单。如果你跟着讲解一步步走下来,可以感受到一个有潜在生产环境质量的 Rust 项目应该如何开发。在这上下两讲内容中,有两点我们一定要认真领会。
第一点,你要对需求有一个清晰的把握,找出其中不稳定的部分(variant)和比较稳定的部分(invariant)。在 KV server 中,不稳定的部分是,对各种新的命令的支持,以及对不同的 storage 的支持。所以需要构建接口来消弭不稳定的因素,让不稳定的部分可以用一种稳定的方式来管理。
第二点,代码和测试可以围绕着接口螺旋前进,使用 TDD 可以帮助我们进行这种螺旋式的迭代。在一个设计良好的系统中:接口是稳定的,测试接口的代码是稳定的,实现可以是不稳定的。在迭代开发的过程中,我们要不断地重构,让测试代码和产品代码都往最优的方向发展。
纵观我们写的 KV server,包括测试在内,你很难发现有函数或者方法超过 50 行,代码可读性非常强,几乎不需要注释,就可以理解。另外因为都是用接口做的交互,未来维护和添加新的功能,也基本上满足 OCP 原则,除了 dispatch 函数需要很小的修改外,其它新的代码都是在实现一些接口而已。
相信你能初步感受到在 Rust 下撰写代码的最佳实践。如果你之前用其他语言,已经采用了类似的最佳实践,那么可以感受一下同样的实践在 Rust 下使用的那种优雅;如果你之前由于种种原因,写的是类似之前意大利面条似的代码,那在开发 Rust 程序时,你可以试着接纳这种更优雅的开发方式。
毕竟,现在我们手中有了更先进的武器,就可以用更先进的打法。
第一部分总结:
谋定后动:确定几个主要接口。网络层,存储层,处理层。网络层需要灵活适应不同协议,protobuf作为信息传输格式,处理层需要哪些hook,处理过程中的主要步骤都有事件暴露出去,让我们的 KV server 可以非常灵活,方便调用者在初始化服务的时候注入额外的处理逻辑。
先确定几个主要的接口:协议接口protobuf协议, 处理逻辑接口,存储接口。体会用trait的优点,可以实现更高层的抽象,我们只跟抽象接口交互可扩展性更强。
比如未来我们支持新命令时,只需要做两件事:为命令实现 CommandService、在 dispatch 方法中添加新命令的支持。比如处理函数参数的存储trait只用最高层的,不是具体的store类型,这样的话面对不同存储类型就不用改代码execute的参数,只需要为具体类型实现存储trait,调用具体函数比如hget就会实现该具体类型的hget方法。相当于一种函数重载。
体现了开闭原则,对扩展加代码开放,对修改改代码关闭。
第二部分总结:
实现并测试protobuf协议能够正常客户端服务端传输信息;
实现测试其余两个接口。代码和测试可以围绕着接口螺旋前进,使用 TDD 可以帮助我们进行这种螺旋式的迭代。在一个设计良好的系统中:接口是稳定的,测试接口的代码是稳定的,实现可以是不稳定的。在迭代开发的过程中,我们要不断地重构,让测试代码和产品代码都往最优的方向发展。
纵观我们写的 KV server,包括测试在内,你很难发现有函数或者方法超过 50 行,代码可读性非常强,几乎不需要注释,就可以理解。另外因为都是用接口做的交互,未来维护和添加新的功能,也基本上满足 开闭 原则
*类比一下C++如果实现这个和rust相比(思考一下,说出几个点,不用具体实现)
接口的话在c++就要用抽象类实现了,比如声明存储纯虚函数,子类重写实现具体的存储方式。
而rust优秀的地方在于trait更强大, 比如execute可以把存储的trait作为参数,代表,只要具体的类型实现了这个trait就可以作为参数,这样不用为之后新增的存储类型而改变参数了,只要具体类型实现存储trait,符合开闭原则。而且trait还体现了特征约束的功能,必须是实现了trait的具体类型才可以作为参数。
而C++的话,要实现这种抽象,必须把抽象类作为参数传给execute函数,不过抽象类是不能作为函数参数的,所以必须是具体的实现存储类才可以作为函数参数,这样的话有新的存储类型就需要实现新的存储子类,并且为execute修改参数。或者基类不作为抽象类作为参数传给execute,调用时是作为具体类型的子类,这就是利用多态了,子类对象可以转换为基类的指针,调用虚函数时调用实际子类的函数实现,实现多态需要额外的开销的,比如vptr,虚函数表,起码找到函数需要两次。
**rust实现类似的功能是零成本的吗?零成本抽象?**
rust的零成本抽象通过**定义实现trait**。懂了。下面是自己的思考。
就是说C**++要实现运行时多态必须是虚函数表等,有运行时开销。而rust通过trait把公用的函数功能从struct或者说class剥离出来,放在trait,该trait作为函数参数时,后续使用对应的struct必须实现了该trait才可以使用该函数。**
两个优点,第一是实现**泛型约束**,保证你只需要引入你需要的东西,不会因为抽象而引入其他用不到的函数方法,这一点在C++继承体系中就做不到,因为基类肯定有子类用不到的方法,除非完全适配,体现**最小接口原则,避免方法被污染**了。如果说需要实现多个trait就组合一下很方便用+号,而不是多重继承,体现了**组合大于继承**的思想。
第二是基于trait的泛型在rust中,是**编译时静态分发**的,编译是就会替换成相应的类型,不是在运行时判断,所以运行时是零成本的。,但是不可避免编译速度就会慢一点了。*
再次总结:最重要的就是trait的使用了:想要支持新命令,只要commandservice实现方法,然后在disptch加一项。并且相对于C++还有独特的优势
两点优势:特征约束,实现开闭原则,组合大于继承;而且是零成本抽象。
1、比如我们现在只是用dashmap(其实就是线程安全的hahsmap)。如果要实现新的存储类型,那么execute方法并不需要修改参数,参数是实现store trait的类型就可以了,trait特征约束的优势。想一想,如果是C++的话,肯定是把新的存储类作为参数传进去,要修改代码;还有一个优点就是最小接口原则,避免方法被污染不会因为抽象而引入其他用不到的函数方法,这一点在C++继承体系中就做不到,因为基类肯定有子类用不到的方法,除非完全适配,体现了组合大于继承的思想。
2、如果C++想要不修改参数的话。就要用到多态了,子类对象可以转换为基类的指针,调用虚函数时调用实际子类的函数实现,实现多态需要额外的开销的,比如vptr,虚函数表,起码找到函数需要两次。是基于trait的泛型在rust中,是编译时静态分发的,编译是就会替换成相应的类型,不是在运行时判断,所以运行时是零成本的。,但是不可避免编译速度就会慢一点了。
复盘一下:
先要确定基本的接口,接下来不是具体实现整个功能,而是写测试,单元测试,测试每个接口是不是能用?体现TDD思想。确保每个接口都可用,再写整体的服务。
tdd: TDD 只是通过单元测试来推动代码的编写,然后通过重构来优化程序的内部结构。这很容易被理解成只需要先写单元测试就可以驱动出高质量的代码,直到我精读 Kent Beck 的著作《测试驱动开发》和不断实践思考之后才总算窥探到 TDD 藏在冰山下的面貌:Kent Beck:“测试驱动开发不是一种测试技术。它是一种分析技术、设计技术,更是一种组织所有开发活动的技术”。
TDD 的规则
在 TDD 的过程中,需要遵循两条简单的规则:
仅在自动测试失败时才编写新代码。
消除重复设计(去除不必要的依赖关系),优化设计结构(逐渐使代码一般化)。
第一条规则的言下之意是每次只编写刚刚好使测试通过的代码,并且只在测试运行失败的时候才编写新的代码,因为每次增加的代码少,即使有问题定位起来也非常快,确保我们可以遵循小步快跑的节奏;第二条规则就是让小步快跑更加踏实,在自动化测试的支撑下,通过重构环节消除代码的坏味道来避免代码日渐腐烂,为接下来编码打造一个舒适的环境。
关注点分离是这两条规则隐含的另一个非常重要的原则。其表达的含义指在编码阶段先达到代码“可用”的目标,在重构阶段再追求“简洁”目标,每次只关注一件事!!!
简单来说,不可运行/可运行/重构——这正是测试驱动开发的口号,也是 TDD 的核心
总结一下第二部分接口测试的具体方法和过程:
协议接口测试
写好protobuf文件后用protos编译成rust代码,主要是rust结构体信息。然后实现其中一个命令比如hset:**
pub fn new_hset(table: impl Into, key: impl Into, value: Value) -> Self 并做一些类型转换。
然后写客户端: // 生成一个 HSET 命令
let cmd = CommandRequest::new_hset(“table1”, “hello”, “world”.into());
// 发送 HSET 命令
client.send(cmd).await?;
客户端收到信息后回复一个404,收到就说明这部分没问题了。
存储接口测试
store测试总结:
存储trait有一些方法,比如get,set等。我们先不急着实现它,我们先写测试代码。当然,我们还没有构建 MemTable,但通过 Storage trait 已经大概知道 MemTable 怎么用:
比如
fn memtable_basic_interface_should_work() {
let store = MemTable::new();
test_set(store);
}
fn test_set(store: impl Storage) {
// 第一次 set 会创建 table,插入 key 并返回 None(之前没值)
let v = store.set("t1", "hello".into(), "world".into());
assert!(v.unwrap().is_none());
// 再次 set 同样的 key 会更新,并返回之前的值
let v1 = store.set("t1", "hello".into(), "world1".into());
assert_eq!(v1, Ok(Some("world".into())));
可以看到,测试代码中,先新建一个内存表(具体实现后面再说),然后测试set接口。如果测试成功,说明接口没问题。
这里体现了测试代码稳定的TDD思想,对具体fn测试,对trait参数进行测试 store: impl Storage,这种泛型可以在以后增加新的存储类型比如磁盘存储,可以复用测试代码。另外不会因为一个trait的具体实现影响其他实现方法。
另外测试代码也能让你感觉拟设计trait中的方法好不好用,不好就赶紧改,不要等trait方法实现好以后再改,麻烦了。
测试代码写好以后,感觉定义的fn都合适,就开始实现,首先要定义memtable,他其实是dashmap,适合并发的哈希表,分别代表
表名,表的键和值。
pub struct MemTable {
tables: DashMap<String, DashMap<String, Value>>,
}
为表实现new函数和get_or_create_table()函数
然后具体为memtable实现trait定义的fn.
impl Storage for MemTable {
fn get(&self, table: &str, key: &str) -> Result<Option<Value>, KvError> {
let table = self.get_or_create_table(table);//判断表是否存在,不存在创建,存在的话返回这个表
Ok(table.get(key).map(|v| v.value().clone()))
}
}
回想一下,如果是直接写实现,再测试的话。就是先定义出memtable,为它实现具体set方法,然后写测试代码新建memtable,set方法调用一下。这里出现两个问题:
1.如果你后期测试发现trait设计的方法不合理时,或者说有些方法根本没必要,那就要修改之前已经写好的实现,比较麻烦。
2、如果后期想要增加其他的存储类型比如磁盘存储,那么就要修改测试代码,之前的memtable测试代码就不嗯能够用了。
所以先写测试可以解决这个问题,测试只对trait进行测试,利用泛型约束参数,只需要修改let store = MemTable::new()这一句,对于set get等测试接口函数都是可以复用的。所以说,测试接口代码是稳定的,具体测试实现可以不稳定。
处理过程接口测试
同样也是先写测试,创建memtable,创建一个命令,给dispatch,调用execute方法得到回应。
** fn hset_should_work() {
let store = MemTable::new();
let cmd = CommandRequest::new_hset("t1", "hello", "world".into());
let res = dispatch(cmd.clone(), &store);
assert_res_ok(res, &[Value::default()], &[]);
let res = dispatch(cmd, &store);
assert_res_ok(res, &["world".into()], &[]);
}**
fn dispatch(cmd: CommandRequest, store: &impl Storage) -> CommandResponse {
match cmd.request_data.unwrap() {
RequestData::Hget(v) => v.execute(store),
RequestData::Hgetall(v) => v.execute(store),
RequestData::Hset(v) => v.execute(store),
_ => todo!(),
}
}
接下来再完善前面new_hset,new_hget等。再实现具体的execute
impl CommandService for Hget {
fn execute(self, store: &impl Storage) -> CommandResponse {
match store.get(&self.table, &self.key) {
Ok(Some(v)) => v.into(),
Ok(None) => KvError::NotFound(self.table, self.key).into(),
Err(e) => e.into(),
}
}
}
当然还涉及到更多的类型转换 from ,因为有很多into。在 Rust 下,但凡出现两个数据结构 v1 到 v2 的转换,你都可以先以 v1.into() 来表示这个逻辑,继续往下写代码,之后再去补 From 的实现 (from into是用于类型转换的trait)
整体测试