类型系统其实就是,对类型(int ,float,vec,enum等)进行定义、检查和处理(转换)的系统。
类型系统的作用就是:减小编程心智负担允许开发者在更高层面进行思考比如类的抽象、排查错误保证内存安全。
一些简单分类
强类型/弱类型
按是否可以隐式转换,可以分为强类型和弱类型。Rust 不同类型间不能自动转换,所以是强类型语言,而 C / C++ / JavaScript 会自动转换,是弱类型语言。
静态类型系统/动态类型系统
按类型检查的时机,可以分为静态类型系统(编译时检查)和动态类型系统(运行时检查,比如python,js)。
为什么说rust内存安全?
所有权系统是一点,类型系统是另一个重要一点。
而rust就是静态的强类型。是错误编译时就能发现,而且不能随意隐式转换,避免了很多意外的错误。
而且,为了做到严格的类型安全,Rust除了let/fn/static/const 定性语句外,都是表达式,表达式总有值,语句不一定有值,有值就有类型。所以可以说,Rust中一切皆类型。
除了一些基本的原生类型和复合类型,Rust把作用域也纳入了类型系统,这就是第4章将要学到的生命周期标记。还有一些表达式,有时有返回值,有时没有返回值(也就是只返回单元值),或者有时返回正确的值,有时返回错误的值,Rust 将这类情况也纳入了类型系统,也就是Option<T>和Result<T,E>这样的可选类型,从而强制开发人员必须分别处理这两种情况。一些根本无法返回值的情况,比如线程崩溃、break或continue等行为,也都被纳入了类型系统,这种类型叫作never类型。可以说,Rust的类型系统基本囊括了编程中会遇到的各种情况,一般情况下不会有未定义的行为出现,所以说,Rust是类型安全的语言。只要定义了类型,就能对这些类型进行处理,不会出现未定义的行为。
多态
在类型系统中,多态是一个非常重要的思想,它是指在使用相同的接口时,不同类型的对象,会采用不同的实现。
对于静态类型系统(C++,JAVA,RUST等),多态可以通过参数多态也就是泛型来实现(parametric polymorphism)、特设多态(adhoc polymorphism)trait实现,在C++中一般指函数重载,和子类型多态(subtype polymorphism)实现(就是C++中子类父类虚函数实现,rust用trait object 来支持)。
类型推导
在一个作用域之内,Rust可以根据上下文,推导出变量的类型。这一点让rust变的和python一样方便。
但是不在统一作用域就不行了,得自己写。
rust的泛型(参数多态)
包括泛型数据结构和泛型函数。
enum Option {
Some(T),
None,
}
这代表T是任意类型, 当Option 有值的时候,就是Some(T),没值的时候就是None。
定义这个泛型结构的过程有点像在定义函数:
函数,是把重复代码中的参数抽取出来,使其更加通用,调用函数的时候,根据参数的不同,我们得到不同的结果;
而泛型,是把重复数据结构中的参数抽取出来,在使用泛型类型时,根据不同的参数,我们会得到不同的具体类型。
泛型函数
现在知道泛型数据结构如何定义和使用了,再来看下泛型函数,它们的思想是类似的。在声明一个函数的时候,我们还可以不指定具体的参数或返回值的类型,而是由泛型参数来代替。
fn id(x: T) -> T {
return x;
}
fn main() {
let int = id(10);
let string = id(“Tyr”);
println!(“{}, {}”, int, string);
}
Rust对于泛型函数,会进行单态化处理。
所谓单态化处理就是在编译的时候,把泛型函数的泛型参数,展开成一系列函数。
单态化的优缺点都比较明显:
优点:泛型函数的调用是**静态分发,在编译时就做到一一对应,既有多态的灵活性,又没有任何执行效率的损失。**是零成本的抽象
缺点:编译速度很慢。一个泛型函数,编译器需要找到所有用到的不同类型,一个个编译。所以 Rust 编译代码的速度总被人吐槽
trait和特设多态。
特设多态:包括运算符重载,是指同一种行为有很多不同的实现;
如果我们想定义一个文件系统,那么把该系统跟底层存储解耦是很重要的。文件操作主要包含四个:open 、write、read、close,这些操作可以发生在硬盘,可以发生在内存,还可以发生在网络IO。总之如果你要为每一种情况都单独实现一套代码,那这种实现将过于繁杂,而且也没那个必要。
如果不同的类型具有相同的行为,那么我们就可以定义一个特征,然后为这些类型实现该特征trait
#![allow(unused)]
fn main() {
pub trait Summary {
fn summarize(&self) -> String;
}
pub struct Post {
pub title: String, // 标题
pub author: String, // 作者
pub content: String, // 内容
}
impl Summary for Post {
fn summarize(&self) -> String {
format!("文章{}, 作者是{}", self.title, self.author)
}
}
pub struct Weibo {
pub username: String,
pub content: String
}
impl Summary for Weibo {
fn summarize(&self) -> String {
format!("{}发表了微博{}", self.username, self.content)
}
}
}
孤儿规则
如果你想要为类型 A 实现特征 T,那么 A 或者 T 至少有一个是在当前作用域中定义的!可以确保其它人编写的代码不会破坏你的代码,也确保了你不会莫名其妙就破坏了风马牛不相及的代码。
默认实现
你可以在特征中定义具有默认实现的方法,这样其它类型无需再实现该方法,或者也可以选择重载该方法:
(首先trait是实现特设多态的,优点类似于C++的函数重载。就是如果不同类型有相同的特征,就把共同的特征提取trait。每个类型有不同的实现。这时静态分发编译确定属于零成本抽象,运行时不用判断。
下面是trait更厉害的方面,那就是trait可以作为参数和约束,C++函数重载不行,这一点可以让我们代码的扩展性更强,比如C++想要加新的重载就要在接口重新加一个定义,而trait不需要修改 )
使用特征作为函数参数
说实话,如果特征仅仅如此,你可能会觉得花里胡哨没啥用,接下来就让你见识下 trait 真正的威力。特征如果仅仅是用来实现方法,那真的有些大材小用。
pub fn notify(item: &impl Summary) {
println!("Breaking news! {}", item.summarize());
}
impl Summary,只能说想出这个类型的人真的是起名鬼才,简直太贴切了,故名思义,它的意思是 实现了Summary特征 的 item 参数。
你可以使用任何实现了 Summary 特征的类型作为该函数的参数,同时在函数体内,还可以调用该特征的方法,例如 summarize 方法。具体的说,可以传递 Post 或 Weibo 的实例来作为参数,而其它类如 String 或者 i32 的类型则不能用做该函数的参数,因为它们没有实现 Summary 特征。
特征约束(trait bound)
虽然 impl Trait 这种语法非常好理解,但是实际上它只是一个语法糖:
pub fn notify<T: Summary>(item: &T) {
println!("Breaking news! {}", item.summarize());
}
真正的完整书写形式如上所述,形如 T: Summary 被称为特征约束。
在简单的场景下 impl Trait 这种语法糖就足够使用,但是对于复杂的场景**,特征约束可以让我们拥有更大的灵活性和语法表现能力,例如一个函数接受两个 impl Summary 的参数:**
pub fn notify(item1: &impl Summary, item2: &impl Summary) {}
如果函数两个参数是不同的类型,那么上面的方法很好,只要这两个类型都实现了 Summary 特征即可。但是如果我们**想要强制函数的两个参数是同一类型呢?**上面的语法就无法做到这种限制,此时我们只能使特征约束来实现:
pub fn notify<T: Summary>(item1: &T, item2: &T) {}
泛型类型 T 说明了 item1 和 item2 必须拥有同样的类型,同时 T: Summary 说明了 T 必须实现 Summary 特征。
多重约束
除了单个约束条件,我们还可以指定多个约束条件,例如除了让参数实现 Summary 特征外,还可以让参数实现 Display 特征以控制它的格式化输出:
pub fn notify(item: &(impl Summary + Display)) {}
除了上述的语法糖形式,还能使用特征约束的形式:
pub fn notify<T: Summary + Display>(item: &T) {}
通过这两个特征,就可以使用 item.summarize 方法,以及通过 println!(“{}”, item) 来格式化输出 item。
Where 约束
当特征约束变得很多时,函数的签名将变得很复杂:
fn some_function<T: Display + Clone, U: Clone + Debug>(t: &T, u: &U) -> i32 {}
严格来说,上面的例子还是不够复杂,但是我们还是能对其做一些形式上的改进,通过 where:
fn some_function<T, U>(t: &T, u: &U) -> i32
where T: Display + Clone,
U: Clone + Debug
{
}
特征和特征约束是很重要的概念,实现了ad-hoc多态也就是函数重载。特征就是定义一个共同的行为集合,做接口类,不同的类型可以具体实现这些行为,这就实现了ad-hoc,同一个函数签名,不同类型的参数使用,具体实现不一样。
而特征约束让trait可以作为函数的参数,让这种多态更灵活,只有实现了trait的类型才可以作为函数的参数。
特征对象与子类型多态
如果我们想要实现一个UI组件,有不同的元素(按钮,文本框等等)。都存在一个表里,需要使用同一个方法逐一渲染在屏幕上!
在拥有继承的语言中,可以定义一个名为 Component 的类,该类上有一个 draw 方法。其他的类比如 Button、Image 和 SelectBox 会从 Component 派生并因此继承 draw 方法。它们各自都可以覆盖 draw 方法来定义自己的行为,但是框架会把所有这些类型当作是 Component 的实例,并在其上调用 draw。不过 Rust 并没有继承,我们得另寻出路。
这也是C++动态多态存在的意义。
如果用泛型特征约束的话,那么列表中必须都是同一种类型。所以不行
#![allow(unused)]
fn main() {
pub struct Screen<T: Draw> {
pub components: Vec<T>,
}
impl<T> Screen<T>
where T: Draw {
pub fn run(&self) {
for component in self.components.iter() {
component.draw();
}
}
}
}
为了解决上面的所有问题,Rust 引入了一个概念 —— 特征对象。Box实现。
pub struct Screen {
pub components: Vec<Box>,
}
其中存储了一个动态数组,里面元素的类型是 Draw 特征对象:Box,任何实现了 Draw 特征的类型,都可以存放其中。
再来为 Screen 定义 run 方法,用于将列表中的 UI 组件渲染在屏幕上:
impl Screen {
pub fn run(&self) {
for component in self.components.iter() {
component.draw();
}
}
}
Screen 在 run 的时候,我们并不需要知道各个组件的具体类型是什么。它也不检查组件到底是 Button 还是 SelectBox 的实例,只要它实现了 Draw 特征,就能通过 Box::new 包装成 Box 特征对象,然后被渲染在屏幕上。
使用特征对象和 Rust 类型系统来进行类似鸭子类型操作的优势是,无需在运行时检查一个值是否实现了特定方法或者担心在调用时因为值没有实现方法而产生错误。
特征对象的动态分发 dyn 正是在强调这一“动态”的特点。
当使用特征对象时,Rust 必须使用动态分发。编译器无法知晓所有可能用于特征对象代码的类型,所以它也不知道应该调用哪个类型的哪个方法实现。为此**,Rust 在运行时使用特征对象中的指针来知晓需要调用哪个方法**
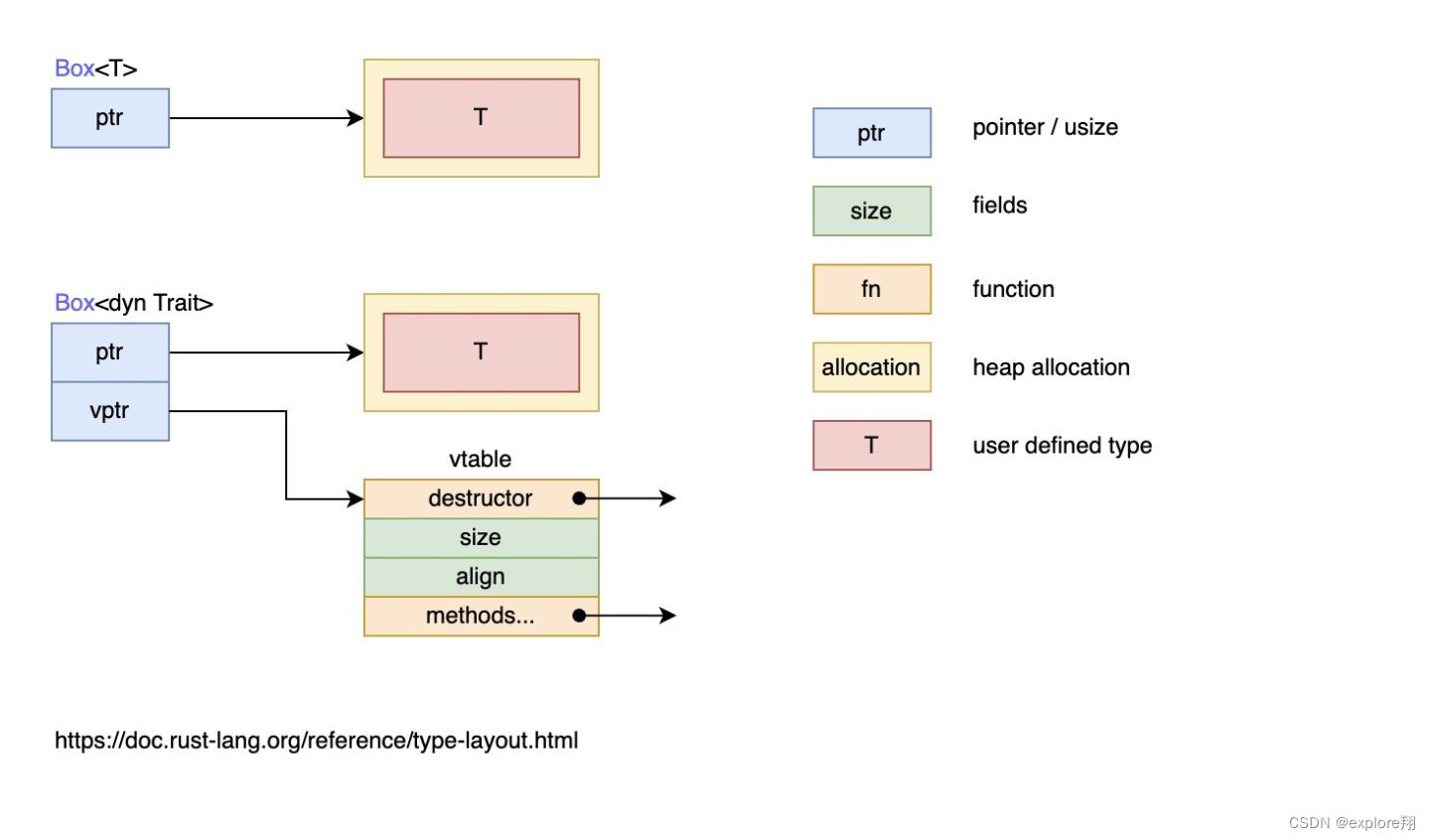
特征对象大小不固定:这是因为,对于特征 Draw,类型 Button 可以实现特征 Draw,类型 SelectBox 也可以实现特征 Draw,因此特征没有固定大小
几乎总是使用特征对象的引用方式,如 &dyn Draw、Box(虽然特征对象没有固定大小,但它的引用类型的大小是固定的,它由两个指针组成(ptr 和 vptr),因此占用两个指针大小)
一个指针 ptr 指向实现了特征 Draw 的具体类型的实例,也就是当作特征 Draw 来用的类型的实例,比如类型 Button 的实例、类型 SelectBox 的实例;另一个指针 vptr 指向一个虚表 vtable,vtable 中保存了类型 Button 或类型 SelectBox 的实例对于可以调用的实现于特征 Draw 的方法.
一些常用的trait
接下来我们还会学习几类比较重要的trait:
和内存分配释放相关的 trait
用于区别不同类型协助编译器做类型安全检查的标记 trait
进行类型转换的 trait、操作符相关的 trait
Debug/Display/Default。
今天我们先学习内存相关的3个trait
内存相关:Clone / Copy / Drop
Clone trait有两个方法:
clone()
clone_from() 有缺省实现。
pub trait Clone {
fn clone(&self) -> Self;
fn clone_from(&mut self, source: &Self) {
*self = source.clone()
}
}
所有的trait都定义了一个隐式的类型Self,它指当前实现此接口的类型。” ——Rust官方文档
填坑:self Self ,&self,&Self
self
当self用作函数的第一个参数时,它等价于self: Self。&self参数等价于self: &Self
Self(相当于一种泛型)
方法参数中的Self是一种语法糖,是方法的接收类型(例如,本方法所在的impl的类型)。
它可能出现在trait或impl中。但经常出现在trait中,它是任何最终实现trait的类型代替(在定义trait时未知该类型)。
impl Clone for MyType {
//我可以使用具体类型(当前已知的,例如MyType)
fn clone(&self) -> MyType;
//或者再次使用Self,毕竟Self更简短
fn clone(&self) -> Self
}
为什么用&self,因为这是一种借用,不会转移所有权。不然类型进了函数后出来,就不能再用了。
在Rust中,没有隐式传递this参数给某个类型的方法。你得显式将“当前对象”传递给方法参数,所以要加self。
那么self作为第一个参数和Self作为第一个参数区别在于。self是方法,Self是关联函数。
调用方式不一样了。
impl MyType{
fn doit(&self, a: u32){
//...
}
fn another(this: &Self, a: u32){
//...
}
}
fn main() {
let m = Type;
//都可以用作关联函数
MyType::doit(&m, 1);
MyType::another(&m, 2)
//但只有”doit”可用作方法
m.doit(3) // m自动被借用
m.another(4) //错误:没有命名为`another`的方法
}
那这2个有什么区别呢?
// 如果a已经存在
a = b.clone(); // clone过程会分配内存。
a.clone_from(&b); // 避免内存分配,提高效率。
这2句,如果如果 a 已经存在,在 clone 过程中会分配内存,使用新内存,释放旧的内存.那么用 a.clone_from(&b) 可以避免内存分配,提高效率。
Clone trait 可以通过派生宏直接实现,这样能简化不少代码。如果是struct 数据结构里,每一个字段都已经实现了 Clone trait,那么可以用 #[derive(Clone)]。
Clone 是深度拷贝,栈内存和堆内存一起拷贝。
Copy trait
Copy trait没有额外的方法,它是一个标记trait(marker trait)
代码定义如下:
pub trait Copy: Clone {}
要实现Copy就必须实现Clone trait,这样没有任何方法的trait有什么用呢?
这样的 trait 虽然没有任何行为,但它可以用作 trait bound 来进行类型安全检查,所以我们管它叫标记 trait。
Copy对Clone进行了细化。一个克隆(clone)操作可能很慢并且开销很大,但是拷贝(copy)操作保证是快速且开销较小的,所以拷贝是一种更快的克隆操作。如果一个类型实现了Copy,Clone实现就无关紧要了:
// 标注#[derive(Copy, Clone)]后 编译器自动生成的代码
impl<T: Copy> Clone for T {
//clone 方法仅仅只是简单的按位拷贝
fn clone(&self) -> Self {
*self
}
}
Drop trait
代码定义如下:
pub trait Drop {
fn drop(&mut self);
}
大部分场景无需为数据结构提供 Drop trait,系统默认会依次对数据结构的每个域做 drop。但有两种情况你可能需要手工实现 Drop。
希望在数据结束生命周期的时候做一些事情,比如记日志。(有点类似 装饰模式)
需要对资源回收的场景。编译器并不知道你额外使用了哪些资源,也就无法帮助你 drop 它们。比如说锁资源的释放,在 MutexGuard 中实现了 Drop 来释放锁资源:
impl<T: ?Sized> Drop for MutexGuard<'_, T> {
#[inline]
fn drop(&mut self) {
unsafe {
self.lock.poison.done(&self.poison);
self.lock.inner.raw_unlock();
}
}
}
标记trait
标记trait
昨天的学习Copy trait也是一种标记trait。Rust还支持一些常用的标记trait Size/Send/Sync/Unpin。
标记 trait 是不含 trait 项的 trait。它们的工作把实现类型“标记(mark)”为具有某种属性,否则就没有办法在类型系统中去表示。
Size trait用于标记有具体大小的类型。在使用泛型参数时,Rust 编译器会自动为泛型参数加上 Sized 约束。比如以下这两坨代码作用是一样的。
但是,在一些情况下,上述代码中的T是可变类型,这时候类型大小就不一致了。Rust提供 ?Size 来解决这个问题。
Send / Sync 往往一起实现
我们来看先Send和Sync的代码定义:
pub unsafe auto trait Send {}
pub unsafe auto trait Sync {}
这两个 trait 都是 unsafe auto trait。auto:是指编译器会在合适的场合,自动为数据结构添加它们的实现。unsafe: 代表实现的这个 trait 可能会违背 Rust 的内存安全准则。
Send/Sync 是 Rust 并发安全的基础:
如果一个类型 T 实现了 Send trait,意味着 T 可以安全地从一个线程移动到另一个线程,也就是说所有权可以在线程间移动。
如果一个类型 T 实现了 Sync trait,则意味着 &T 可以安全地在多个线程中共享。一个类型 T 满足 Sync trait,当且仅当 &T 满足 Send trait。
标准库中不支持Send/Sync的数据结构主要有:
裸指针 *const T / *mut T。它们是不安全的,所以既不是 Send 也不是 Sync。
UnsafeCell 不支持 Sync。也就是说,任何使用了 Cell 或者 RefCell 的数据结构不支持 Sync。
引用计数 Rc 不支持 Send 也不支持 Sync。所以 Rc 无法跨线程。
(填坑:关于cell,rc, arc的特点)
操作符转换trait
在开发中,我们经常需要把一个类型转换成另一种类型。
我们先来看下,这几种方式的比较。
// 第一种方法,为每一种转换提供一个方法
// 把字符串 s 转换成 Path
let v = s.to_path();
// 把字符串 s 转换成 u64
let v = s.to_u64();
// 第二种方法,为 s 和要转换的类型之间实现一个 Into<T> trait
// v 的类型根据上下文得出
let v = s.into();
// 或者也可以显式地标注 v 的类型
let v: u64 = s.into();
这还用比吗?显然第二种,对于我们这种码农来说更友好,只需要记一种格式就行了。不同类型的转换都实现一个数据转换trait,这样可以用同一个方法实现不同类型的转换,(有点像泛型?)这样也符号开闭原则,对扩展开放,对修改关闭。底层可以扩展更多的数据类型,原来的不用修改,只需要新增实现即可。
按照这个思路,Rust按照值类型和引用类型提供两套不同的trait。
值类型: From / Into / TryFrom / TryInto
引用类型: AsRef / AsMut
pub trait From {
fn from(T) -> Self;
}
pub trait Into {
fn into(self) -> T;
}
// 实现 From 会自动实现 Into
impl<T, U> Into for T where U: From {
fn into(self) -> U {
U::from(self)
}
}
从代码中可以看到,在实现From的时候会自动实现Into。
一般情况,只用实现From,这2种方式都可以做类型做转换。
比如这样:
let s = String::from(“Hello world!”);
let s: String = “Hello world!”.into();
如果你的数据类型在转换过程中有可能出现错误,可以使用 TryFrom 和 TryInto ,它们的用法和 From / Into 一样,只是 trait 内多了一个关联类型 Error,且返回的结果是 Result<T, Self::Error>。
AsRef 和 AsMut 用于从引用到引用的转换。还是先看它们的代码定义:
pub trait AsRef where T: ?Sized {
fn as_ref(&self) -> &T;
}
pub trait AsMut where T: ?Sized {
fn as_mut(&mut self) -> &mut T;
}
从这2个的定义可以看出,允许T的大小可变类型,如:str、[u8]之类的。
另外AsMut除了是可变引用之外,其他的都和AsRef一样,所以我们主要看AsRef
操作符相关trait
deref trait
let mut x = 5;
{
let y = &mut x;
*y += 1
}
assert_eq!(6, x);
我们使用 *y 来访问可变引用 y 所指向的数据,而不是可变引用本身。接着可以修改它的数据,在这里是对其加一。
引用并不是智能指针,他们只是引用指向的一个值,所以这个解引用操作是很直接的。智能指针还会储存指针或数据的元数据。当解引用一个智能指针时,我们只想要数据,而不需要元数据,因为解引用一个常规的引用只能给我们数据而不是元数据。我们希望能在使用常规引用的地方也能使用智能指针。为此,可以通过实现 Deref trait 来重载 * 运算符的行为。
pub trait Deref {
// 解引用出来的结果类型
type Target: ?Sized;
fn deref(&self) -> &Self::Target;
}
use std::ops::Deref;
struct Mp3 {
audio: Vec<u8>,
artist: Option<String>,
title: Option<String>,
}
impl Deref for Mp3 {
type Target = Vec<u8>;
fn deref(&self) -> &Vec<u8> {
&self.audio
}
}
fn main() {
let my_favorite_song = Mp3 {
// we would read the actual audio data from an mp3 file
audio: vec![1, 2, 3],
artist: Some(String::from("Nirvana")),
title: Some(String::from("Smells Like Teen Spirit")),
};
assert_eq!(vec![1, 2, 3], *my_favorite_song);
}
这里,音频数据才是想要的,歌名和作者名是元数据,不需要的。所以需要实现 Deref trait 来返回音频数据。
关于trait的更多知识可以参考
https://juejin.cn/post/6957216834772795422