一、ETL介绍
ETL流程是数据仓库建设的核心环节,它涉及从各种数据源中抽取数据,经过清洗、转换和整合,最终加载到数据仓库中以供分析和决策。在数据仓库国产化的背景下,ETL流程扮演着重要的角色,今天我们就来讲讲ETL流程的概念和设计方式。

1.数据抽取(Extract)
数据抽取是ETL流程的第一步,它涉及从各种数据源中提取数据,将数据从源系统中抽取出来,为后续的处理做准备。数据源可以是各种类型,总共分为结构化数据、半结构化数据以及非结构化数据,包括关系数据库、文件(如CSV、Excel、JSON等)、API、日志文件等。数据抽取在不同数据源结构的情况下可以分为以下几种方式:
- 结构化数据:从关系数据库、表格、CSV文件等结构化数据源中,以SQL查询或API调用的方式,抽取数据记录;利用增量抽取或CDC技术,仅抽取已变更或新增的数据,以提高效率和实时性。
(2)非结构化或半结构化数据:从文本文件、日志、图像、音频、视频等非结构化数据源中,以适当的解析技术,抽取有价值的信息;使用文本挖掘、图像处理、语音识别等技术,将非结构化数据转化为结构化或半结构化形式。
在数据抽取方式上,一般可以采用以下几种方式:
(1)全量抽取(Full Extraction): 将源系统中的所有数据一次性抽取出来,适用于数据量不大且变化较少的情况,比如数据初始化装载。
(2)增量抽取(Incremental Extraction): 只抽取源系统中发生变化的数据,通常使用时间戳或增量标记来识别新增或修改的数据,一般用于数据更新。
(3)增量抽取+日志追踪(Change Data Capture,CDC): 在数据库中使用日志追踪技术,实时监测数据库中的变化,并将变化的数据抽取出来,以保证数据的实时性。
2.数据转换(Transform)
数据转换是ETL流程的核心环节,涉及对抽取的数据进行清洗、整合和转换,使其适应目标存储和分析的需求。不同结构的数据转换方式也不一样:
(1)结构化数据:转换方式主要是进行数据清洗,去除重复值、处理缺失数据,并确保数据一致性和准确性,执行关系型数据的连接、合并、筛选等操作,以整合来自不同源的数据等;
(2)非结构化数据:转换方式主要是对文本数据进行自然语言处理,如分词、实体识别、情感分析等,以提取文本内容的关键信息,将非结构化数据转换为适合存储和分析的结构化格式,如将文本转换为表格形式等。
数据转换包括以下主要步骤:
(1)数据清洗: 清洗数据是为了处理数据中的异常、缺失或错误,确保数据的准确性和一致性。这可能涉及去除重复值、填充缺失值、纠正格式问题等。
(2)数据整合: 如果数据来自多个源系统,可能需要进行数据整合,合并不同源的数据,消除重复项,以获得更全面的视图。
(3)数据转换和计算: 在这一步中,数据可以进行数学计算、逻辑运算、日期处理等操作,以生成新的衍生数据或指标。例如,计算销售额、计算增长率等。
(4)数据格式化: 将数据转换为目标存储的格式,可能涉及重新组织数据结构、调整数据类型等。
(5)数据规范化: 统一数据值的表示方式,确保数据的一致性和可比性。例如,将地区名称转换为标准的地区代码。
3.数据加载(Load)
数据加载是ETL流程的最后一步,它将经过抽取和转换的数据加载到目标存储中,通常是数据仓库或数据湖。数据加载可以分为以下几种方式:
(1)全量加载(Full Load): 将所有经过处理的数据一次性加载到目标存储中,适用于初始加载或数据量较小的情况。
(2)增量加载(Incremental Load): 只加载抽取和转换后发生变化的数据,以保证数据的实时性和效率。
(3)事务性加载: 使用数据库的事务机制,确保数据加载的完整性,即要么全部加载成功,要么回滚至加载前的状态。
(4)批处理加载和流式加载: 批处理加载适用于大规模数据处理,而流式加载适用于需要实时数据分析的场景。
无论是处理结构化数据还是非结构化数据,ETL流程的核心目标都是将原始数据变换成可用于分析、报告和决策的有价值数据。不同数据类型需要针对其特性进行不同的抽取、转换和加载操作,以确保数据质量和可用性。
二、可免费使用的ETL工具推荐
根据数据源不同,数据仓库ETL工具可分为结构化数据ETL工具和非结构化/半结构化数据ETL工具,以下是经过试用后值得推荐的几款免费ETL工具。
1. Kettle
Kettle是一款免费的国外开源ETL工具,使用广泛,是一款目前来看市面上功能最强大的开源ETL工具,通过Kettle可用于数据抽取、转换和加载实现数据快速入仓和分析。下面简单说一下Kettle的优缺点:
优点:
(1)提供了直观的图形化用户界面,用户可以通过拖放和连接转换步骤来构建数据集成流程,这种可视化的开发方式使得非技术人员也能够轻松上手,并加快了开发效率。
(2)Kettle提供了丰富的转换步骤和功能,使用户能够对数据进行清洗、过滤、转换和合并等操作,它支持各种数据处理技术,包括字符串操作、日期处理、聚合计算、条件判断等,以满足复杂的数据转换需求。
缺点:
- 学习上手存在一定难度,对于新手来说,Kettle可能需要一些时间来理解其概念和操作方式。尤其是在处理复杂的数据转换逻辑时,需要具备一定的数据处理和编程知识。
- 文档支持有限,相比其他一些国产的ETL工具,Kettle在国内的用户数量虽然很多,但是中文文档和技术支持相对有限。这可能导致在遇到问题时需要更多的自学和研究。
(3)不支持CDC实时数据采集功能,只能依赖加快任务的调度频率如1分钟来实现实时数据传输,如果数据量比较庞大的话,对于生产系统的话会造成很大的压力。
使用界面图:
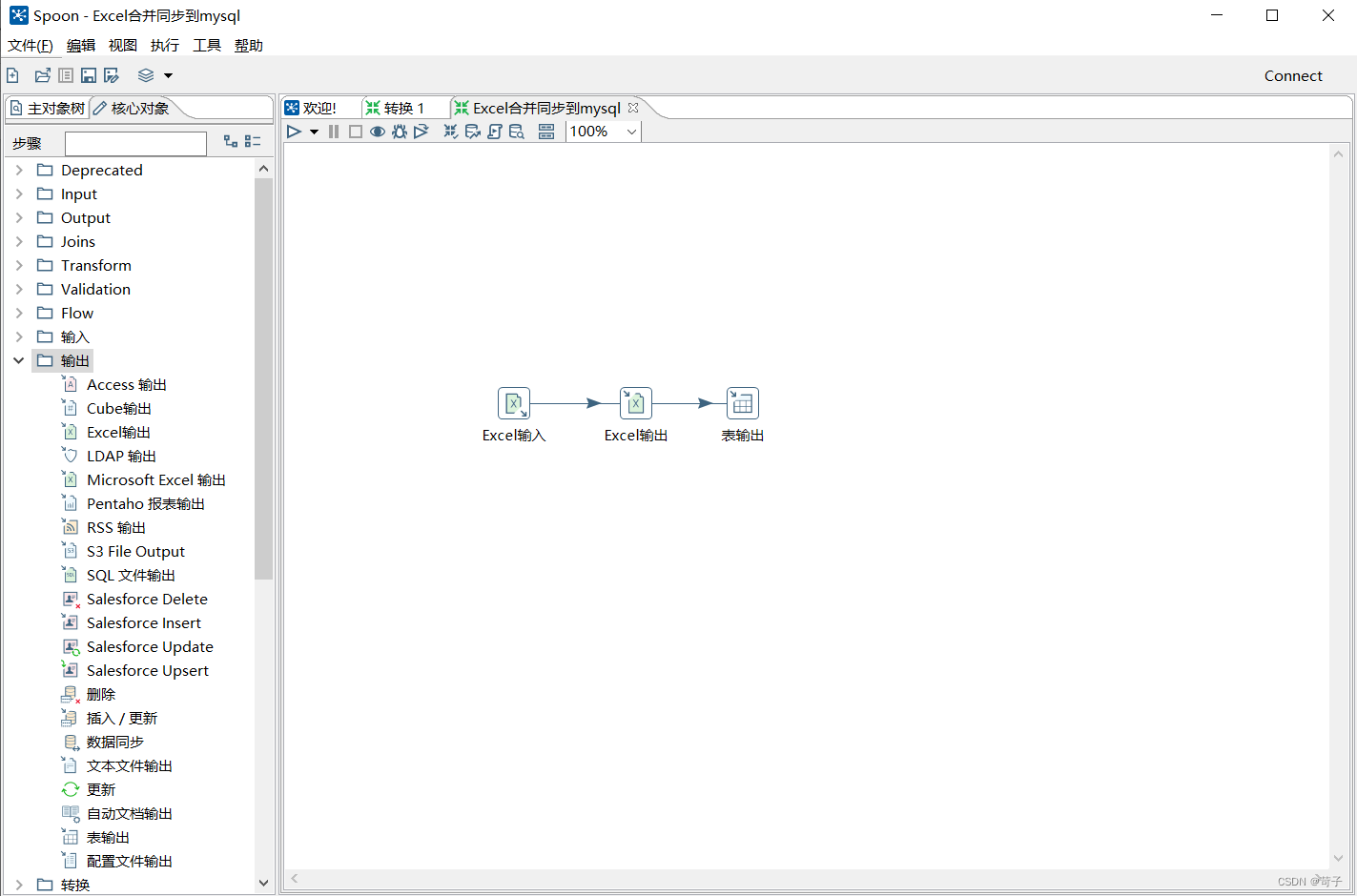
(作为开源软件,可以直接从官方网站下载Kettle)
2. AirByte:
airbyte是一款最新开源的数据集成软件,它将应用程序、API和数据库中的数据同步到数据仓库、数据湖和其他目的地,支持200个Source类型连接器,100 个Destination类型的连接器。
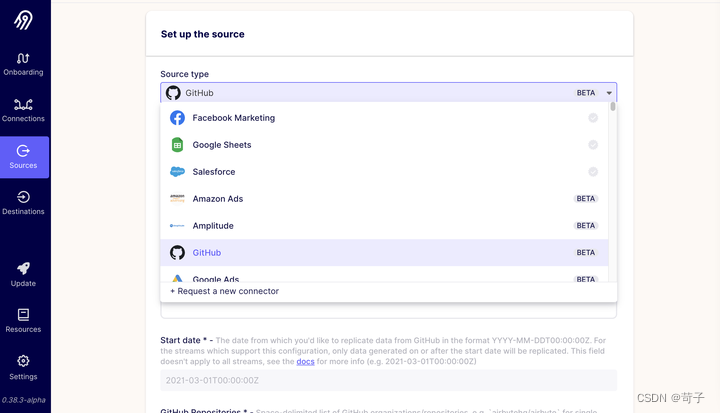
(AirByte的链接器界面)
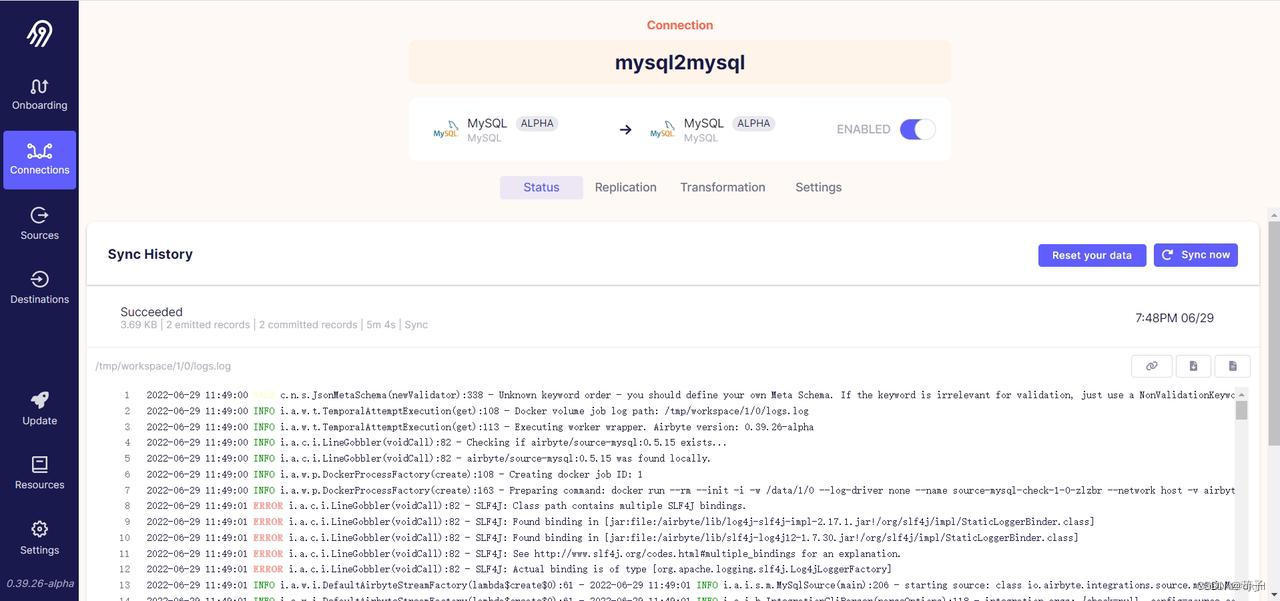
(数据同步监控界面)
- ETLCloud
可以实现实时数据同步、离线数据处理、流程全面监控于一体的国产数据集成平台,相比其他国外ETL工具有着更易上手的特点,ETLCloud分为社区版和商业收费版,其中社区版是免费使用的。下面我们来简单说一下它的优缺点:
优点:
(1)强大的数据支持功能:可对接数据库、上层通用协议、消息队列、文件、平台系统、应用等类型的数据源,为企业提供一套完整的数据集成和分析解决方案。
(2)支持CDC实时数据采集能力,同步效率高,数据同步过程中有详细的监测报告。
(3)提供WEB直观的可视化配置界面,有统一的运维平台,是一款本土化自研数据集成产品。
(4)社区免费版本,有大量的用户群体,技术文档全面,具有丰富的组件市场快速实现与SASS应用的打通。
缺点:
- 社区免费版本有部分功能不支持,需要企业版本才可以使用。
使用界面图:
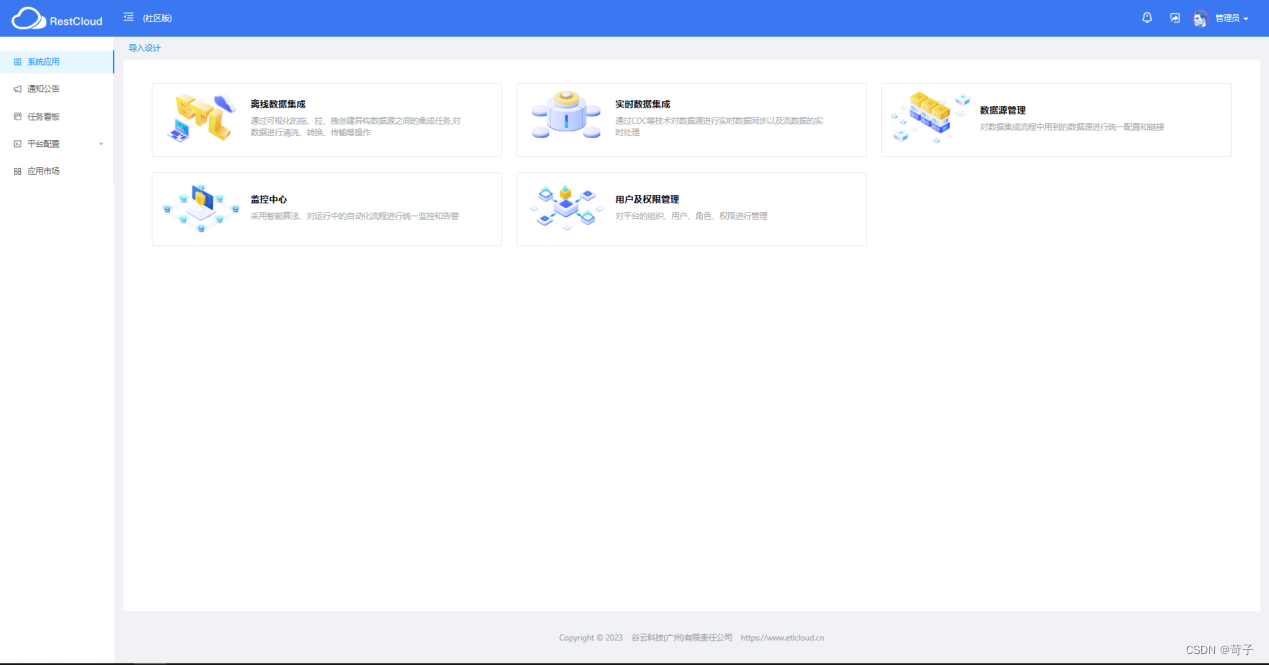
流程设计:
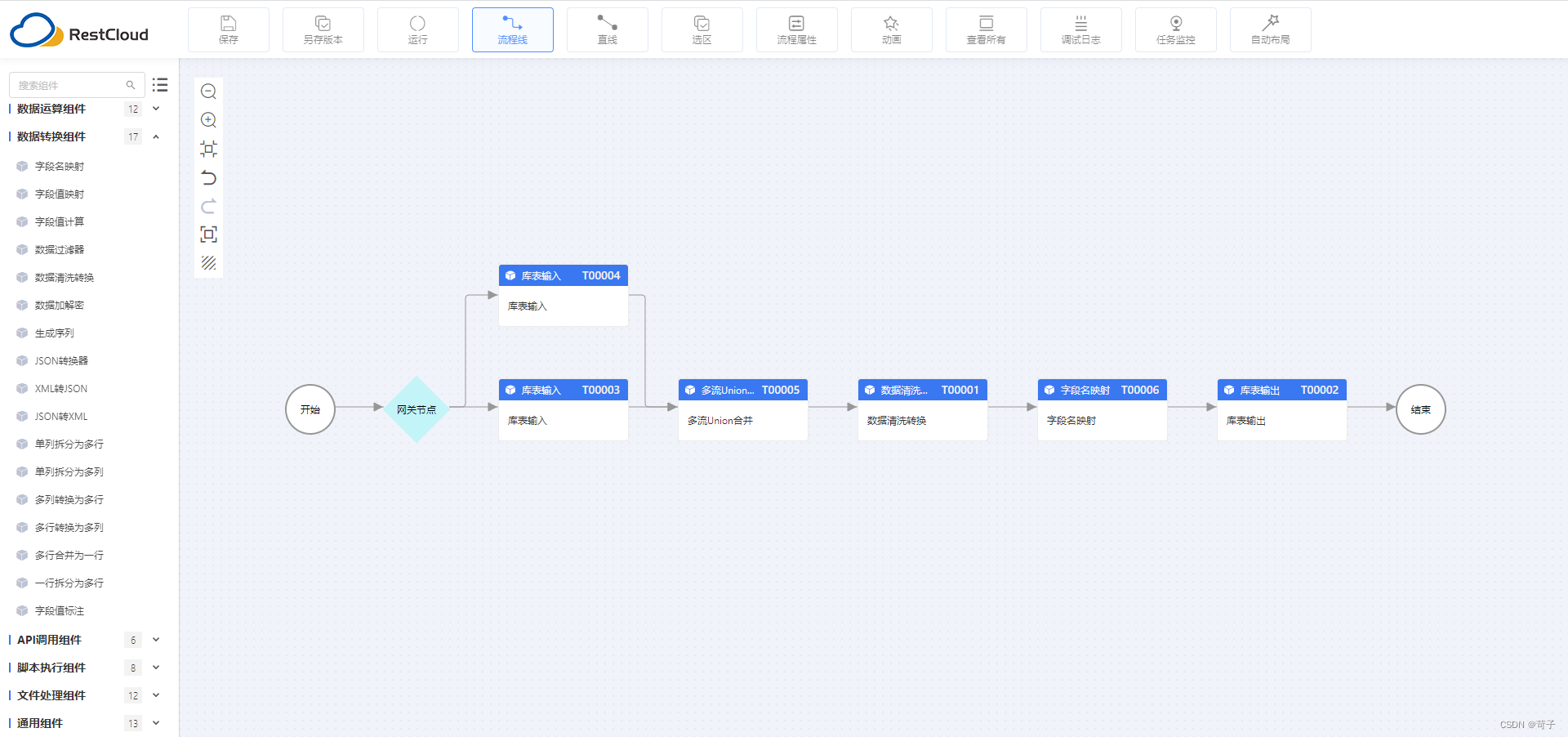
(流程设计界面)
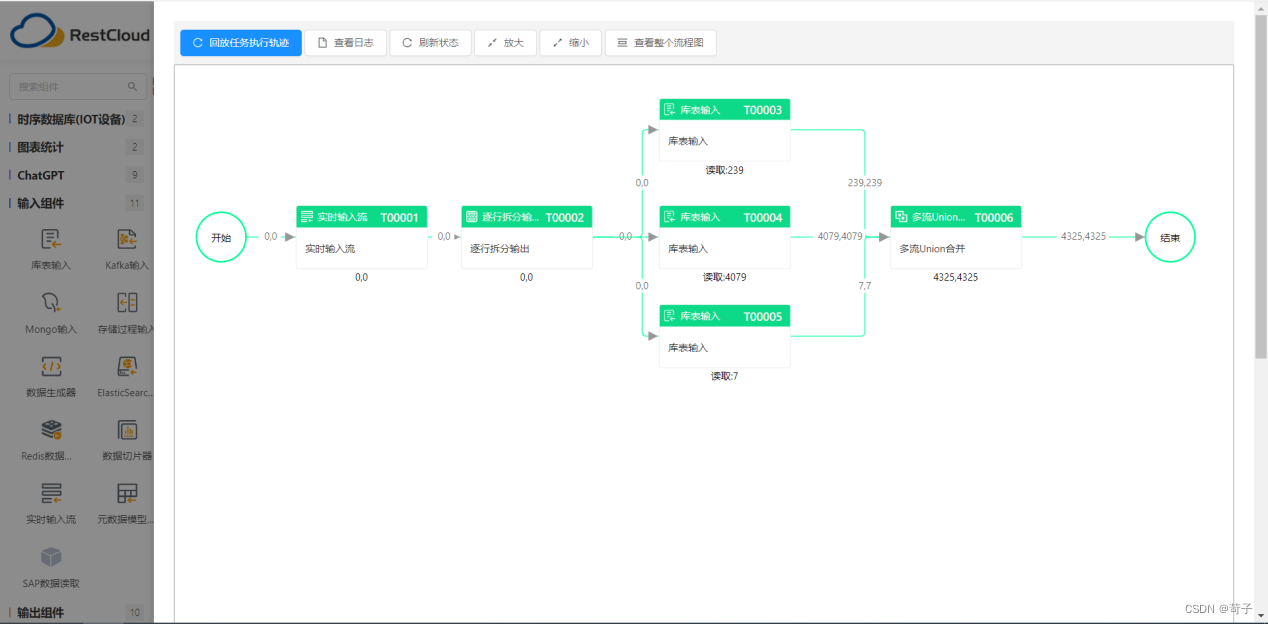
(任务监控运行界面)
4.DataX
DataX是阿里开源的一个异构数据源离线同步工具。作为一个服务于大数据的ETL工具(其实可以算作是ELT工具),除了提供数据快照搬迁功能之外,还提供了丰富数据转换的功能,能提供稳定高效的数据同步功能,下面也来简单说说它的优缺点。
优点:
(1)支持多个数据源和数据目标,且接入方便。
(2)支持高速数据传输,适用于大规模数据处理场景。
(3)定制化程度高,支持用户自定义开发。
缺点:
- DataX但DataX是以脚本的方式执行任务的,需要完全吃透源码才可以调用,学习成本高。
- 缺少用户友好的界面,需要编写脚本进行配置 ,可视化监控和数据追踪能力不够完善。运维成本相对高。
使用界面图:
三、总结
本文介绍了什么是ETL,分析了ETL在大数据处理中的作用和重要性,并分享了ETL的应用场景以及适用性。需要注意的是,以上几款ETL工具优缺点仅供参考,具体的评价还需要根据实际需求和使用情况来综合考虑。建议在选择ETL工具时,结合自身的业务需求,进行全面的评估和比较,选择最适合的工具。