IO流
IO(输入/输出),主要是指数据之间的传送。狭义上是指数据从别的地方输入到当前程序,或当前程序将数据输送到别的地方。当然别的地方不仅仅是硬盘,而且还有内存中的一些事物,比如说别的程序或者是别的流。
File类
File类是与文件和目录相关而且平台无关的类,File能够新建、删除、重命名文件但是不能够访问文件的内容(这个需要IO)。
访问文件和目录
1. 文件名相关
得到文件的路径、名称,重命名等。
2. 文件检测相关
是否为一个文件、目录,是否为绝对路径。
3. 文件信息相关
获取最后修改时间,文件长度。
4. 文件操作相关
创建删除文件,临时文件。
5. 目录相关
列出所有子文件和路径名,所有根路径等,创建多级目录。
以下为示例代码:
package file;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
public class FileTest {
public static void main(String[] args) throws IOException {
File file = new File("src/file/zhuliu7.txt");//File可以是一个文件
System.out.println(file.getName());
System.out.println(file.getAbsolutePath());
System.out.println(file.getParent());
File file1 = new File("src/file");//File对象也可以是一个目录
File tempFile = File.createTempFile("zhuliu7",".properties",file1);
tempFile.deleteOnExit();//在退出的时候删除文件夹
System.out.println("当前路径下的所有文件");
String[] strs = file1.list();//当前路径下的所有目录或文件
for(String s : strs) {
System.out.println(s);
}
System.out.println("end");
File[] roots = File.listRoots();//返回计算机下面的所有跟目录
for(File f : roots) {
System.out.println(f);
}
File file3 = new File("src/666","777");
System.out.println(file3.getAbsolutePath());
System.out.println(file3.mkdirs());//false当我们已经创建了对应的目录的时候那么再次创建就会返回false
}
}
递归身处文件夹可以参考以下代码:
package file.test;
import java.io.File;
public class DeleteFileTest {
public static void main(String[] args) {
File f = new File("removeio");
RecursionDelete(f);
}
public static void RecursionDelete(File f) {
System.out.println(f);
if(f.isFile()||f.listFiles().length==0) {
f.delete();
return;
}
for(File file : f.listFiles()) {
System.out.println(file);
RecursionDelete(file);
f.delete();
}
}
}
文件过滤器
File类的list()方法中会接收FilenameFilter(函数式接口)参数,可以列出符合条件的文件。其中FilenameFilter中有一个accept的如果该方法返回true就会显示否则不会显示。FileFilter这个类原本可以做FilenameFilter的实现类但是sun公司没有这样实现,这算是一个小遗漏。以下代码列出后缀名为.java的文件来。
package file;
import java.io.File;
import java.io.FileFilter;
public class FileNameFilter {
public static void main(String[] args) {
File file = new File("src/file");
File[] files =file.listFiles((fl)->fl.getName().endsWith(".java"));//满足这个条件的返回true
for(File f : files) {
System.out.println(f.getName());
}
}
}
Java的IO流
流的分类
根据不同的流向可以把流分为不同的种类。
根据流向:输入流,输出流。
根据操作单元:字节流、字符流。
根据角色:直接怼在数据源上的为节点流,包装节点流的对象为处理流。
流的概念模型
对于输入流而言:
把输入设备当做是一个水管,输入流使用隐式的指针来读取这个水管中的水滴,当读取一个或多个水滴后记录指针自动向后移动。
对于输出流而言:
把输出设备当做是一个水管,当执行输出时程序相当于依次把“水滴”放到水管中。当放入水滴之后指针向后移动。
对于处理流而言:
① 以缓冲的方式来增加输入和输出的效率。
② 一次输出输出大批量的内容而非单个“水滴”的读取。
③ 它可以嫁接在任何的已存在流的基础上。
④ 在关闭流的时候只需要关闭处理流就ok了,节点流自动关闭。
字节流与字符流
InputStream和Reader
InputStream与Reader并不能创建流的实例但是他们是所有输入输出流的基类,为其它的输入流提供了模板,所以他们的方法是所有输入流都可以使用的方法。
其中InputStream为字节流它的操作单位是字节,Reader是字符它的操作单位是字符。当然他们除了一个一个的字节(字符)读取他们还可以一次性度满一个字节(字符)数组然后将数据放入目的地。示例代码如下:
package file;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.io.Reader;
public class FileInputStreamTest {
public static void main(String[] args) throws IOException {
Reader reader = new FileReader("src/file/FileInputStreamTest.java");
char[] b = new char[1024];
int hasReader = 0;
while((hasReader = reader.read(b))>0) {//读到返回读到的长度,读不到就返回0
System.out.println(new String(b,0,hasReader));
}
reader.close();
}
}
特别说明:
这个程序是按照1k字符的来读取文件的。最后需要将流关闭,因为IO资源不能被垃圾回收机制回收掉,所以需要显式的关闭。
除此之外
还有一些关于指针的一些操作,比如说mark()在当前指针处记录一个指针。reset()清空指针。skip(long n)将指针向前移动n个单位。
OutputStream和Writer
OutputStream与Writer极其相似。它们的功能与输出流对称。
两个流都提供了如下的三个方法:
void write(int c)将指定的字节输出到输出流,c可以是字节也可以是字符。
void write(byte[]/char[]buf),将指定数组中的内容输入到输出流中。
void write(byte[]/char[],int off,intlen) 将指定数组中的内容输入到输出流中。而且是从off开始输出len个单位长度的数据。
void write(String s),将字符串输出到输出流中。
void write(String s,int off,int len) 将字符串输出到输出流中。而且是从off开始输出len个单位长度的数据。
输入输出体系
输入输流出体系
输入输出流体系虽然庞大但是是非常规律的,通常来说字节流的功能比字符流的功能强大。因为计算机里面所有的文件都是由字节构成。字符只是由两个字节(数据项)构成的数据元素。所以计算机中所有的文件都是二进制文件文本文件只是二进制文件的一个特例。当二进制文件恰好被解释成一个个的字符是它也就成了字符文件。这就需要编码解码来实现。
以下示例代码介绍了以字符串作为物理节点的输入输出流:
package stringnodetest;
import java.io.IOException;
import java.io.StringReader;
import java.io.StringWriter;
import java.util.HashMap;
import java.util.Map;
public class StringNodeTest {//以字符串作为节点的输入输出流
public static void main(String[] args) {
String str = "有实力无所惧,\n"
+ "我倒要看看达内的题有多难?";
char[] buffer = new char[32];
int hasread = 0;
StringReader sr = new StringReader(str);
try {
while((hasread = sr.read(buffer))>0) {
System.out.println(new String(buffer,0,hasread));
}
} catch (IOException e) {
e.printStackTrace();
}
//可以以一个字符串作为输出节点
StringWriter sw = new StringWriter();
sw.write("对面的美眉");
sw.write("哎呦不错噢!: - )");
System.out.println(sw.toString());
}
}
附加说明:如果使用了缓冲流则需要flush()之后才能够将缓冲区中的数据写入到物理节点。
转换流
首先说转换流就是把字节流转换成字符流的一种流,马士兵老师说它用到了适配器模式。为什么没有把字符流转换成字节流的转换流?因为字节流的使用范围比较广泛但是字符流操作比较方便,在这里我们为的是方便。以下示例代码展示的是将标准的输入流(一个字节流)改写成一个字节的输出流。
package transformstream;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
public class KeyinTest {
public static void main(String[] args) {
InputStreamReader isr = new InputStreamReader(System.in);
BufferedReader br = new BufferedReader(isr);
String line = null;
try {
while((line = br.readLine())!=null) {
if(line.equals("exit")) {
System.exit(1);
}
System.out.println(line);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
推回输入流
推回输入流与其他流最大的不同之处在于它能够将已经读取的数据退回到自己的缓冲区中以便再次读取(事实上我用这个流用的很少)。当推回之后再次读取时会先读取推回缓冲区内的数据只有当推回缓冲区读取完毕才会读取正常的流中的数据。以下的示例代码展示了试图找出程序中的“new PushbackReader”字符串之后,只打印他们前面的内容。
package pushbackreader;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.PushbackReader;
public class PushbackReaderTest {
public static void main(String[] args) {
//创建一个PushbackReader指定的退回缓冲区为64 字节或者是字符
try {
PushbackReader pr = new PushbackReader(new FileReader("src/pushbackreader/PushbackReaderTest.java"),1024);
char[] buf = new char[64];
//用以保存上次读取字符串内容
String lastContent = "";
int hasRead = 0;
//循环读取文件内容
while((hasRead = pr.read(buf))>0) {
//当前的字符串
String content = new String(buf,0,hasRead);
int targetIndex = 0;
//将上次读取的字符串与本次读取的字符串拼接起来看看有没有目标字符串 它出现的位置
targetIndex = (lastContent + content).indexOf("new PushbackReader");
boolean flag = targetIndex>0?true:false;
if(flag) {
pr.unread((lastContent + content).toCharArray());//如果发现目标字符串将读取到的内容退回
//如果前面的字符串太多的话我们要重新构建一个退回字符数组
if(targetIndex>64) {
buf = new char[targetIndex];
}
//倒回之后再次读取目标串之前的内容 这个内容就在退回缓冲区中
pr.read(buf,0,targetIndex);
System.out.println(new String(buf,0,targetIndex));
System.exit(0);
}else {
System.out.println(lastContent);
lastContent = content;//虽然拿到了本次的字符串但是并没有打印
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
重定向标准输入/输出
这个是是个小的知识点,我觉得主要是让我们更加明白System.in和System.out这两个流。当然他的内部也封装了两个方法用来重定向标准的输入输出。
以下代码是重定向输入流:
package standardio;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.util.Scanner;
public class RedirectIn {
public static void main(String[] args) {
try {
FileInputStream fis = new FileInputStream("zhuliu7.txt");
System.setIn(fis);
Scanner in = new Scanner(System.in);
while(in.hasNext()) {
System.out.println(in.next());
}
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
}
以下代码是重定向输出流:
package standardio;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.PrintStream;
public class RedirectOut {
public static void main(String[] args) {
//这个过程整体上就是替换一个流的故事
try {
PrintStream ps = new PrintStream(new FileOutputStream("zhuliu7.txt"));
System.setOut(ps);
System.out.println("hello future!");
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
}
Java虚拟机读写其它进程的数据
在这里最容易混淆的就是一个流是输入流还是输出流。在这里我们永远站在当前Java程序的角度来考虑问题。也就是当一个流对子进程的输入流对当前Java程序是输出流我们就叫他为输出流。所以当有代码p.getOutputStream()的时候(p为子进程),事实上就是在说对于本程序是输出流,对于子进程输入流。以下代码展示了读取其它进程的输出信息:
package processio;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
//从子进程中输出数据到Java程序中
public class ReadFromProcess {
public static void main(String[] args) throws IOException {
Process p = Runtime.getRuntime().exec("javac"); //从p这个进程读取出来
BufferedReader br = new BufferedReader(new InputStreamReader(p.getErrorStream()));
String buff = null;
while((buff = br.readLine())!=null) {
System.out.println(buff);
}
}
}
RandomAccessFile
RandomAccessFile随机访问文件,其实这个名字不是那么标准。它想要表达的意思就是程序可以跳到文件的任何地方进行访问数据。而它本身含有读和写的双重功能。他有一个很大的局限就是不能够像其他的流一样进行流与流之间的数据交互,它只能够访问文件。在创建RandomAccessFile时也需要指定文件的访问模式。
以下代码展示访问文件中间部分数据:
package randomaccessfile;
import java.io.FileNotFoundException;
import java.io.RandomAccessFile;
public class RandomAccessFileTest {//它既是输入流也是输出流
public static void main(String[] args) {
//读取指定位置之后的内容
try {
RandomAccessFile raf = new RandomAccessFile("src/randomaccessfile/RandomAccessFileTest.java","r");
System.out.println(raf.getFilePointer());
raf.seek(50);
int hasRead = 0;
byte[] b = new byte[64];
while((hasRead = raf.read(b))>0) {
System.out.println(new String(b,0,hasRead));
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
以下代码展示了在文件末尾追加数据:
package randomaccessfile;
import java.io.RandomAccessFile;
public class AppendContent {
public static void main(String[] args) {
try {
RandomAccessFile raf = new RandomAccessFile("zhuliu7.txt","rw");
raf.seek(raf.length());
raf.write("我不是不想去达内而是我需要把一首歌难唱的地方唱下来这样才能够把这首歌唱好".getBytes());
}catch(Exception e) {
e.printStackTrace();
}
}
}
虽然RandomAccessFile功能强大但是还是无法完成数据的插入,我们需要使用临时文件来保存当前的数据,然后在指定位置插入数据之后再从临时文件中把剩下的数据读取出来。事实上这也是断点下载技术的核心所在,当我们下载一个文件时会生成两个文件,一个文件代表我们下载数据另一个文件记录当前的指针位置。以下代码展现了在文件中插入数据:
package randomaccessfile;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.RandomAccessFile;
public class InsertContent {
public static void main(String[] args) {
try {
File tmp = File.createTempFile("src/zhuliu7tmp", ".txt");
// tmp.deleteOnExit();
RandomAccessFile file = new RandomAccessFile("zhuliu7.txt","rw");
file.seek(10);
FileOutputStream fos = new FileOutputStream(tmp);
FileInputStream fis = new FileInputStream(tmp);
byte[] b = new byte[64];
int hasRead = 0;
//将断点后面的内容统统方到零时文件中
while((hasRead = file.read(b))>0) {//这里有乱码问题
fos.write(b,0,hasRead);
}
fos.close();
file.seek(10);
file.write("zhuliu7".getBytes());
while((hasRead = fis.read(b))>0) {
file.write(b,0,hasRead);
}
file.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
对象序列化
对象序列化就是把一个对象以二进制流的形式存储在磁盘上,反序列化就是拿到一个对象的二进制编码进而还原成为一个对象。打个比方就是我们平常所说的游戏存盘。而且序列化技术平台无关,常用于JavaEE技术。而JavaEE通常都跨平台跨网络,所以通常建议JavaBean需要实现对象序列化。一个对象实现Serializable接口就能够实现序列化。
使用对象流实现序列化
在Java中与对象序列化相关的流就是两个对象流。ObjectInputStream和ObjectOutputStream。他们可以将对象变成二进制的字节存入磁盘也可以将磁盘中的二进制文件还原成对象。
以下为示例代码:
package serializable;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.io.Serializable;
public class WriteObject {
public static void main(String[] args) {
try {
ObjectOutputStream oop = new ObjectOutputStream(new FileOutputStream("zhuliu7.txt"));
Person p = new Person("hyl",23);
oop.writeObject(p);
oop.close();
ObjectInputStream oip = new ObjectInputStream(new FileInputStream("zhuliu7.txt"));
Person p1 = (Person) oip.readObject();
System.out.println(p1.equals(p));//这里是false 对象的反序列化无需使用构造器
}catch (Exception e) {
e.printStackTrace();
}
}
}
class Person implements Serializable{
private String name;
private int age;
public Person(String name,int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
注意事项,反序列化读取的仅仅是Java对象的数据所以在读取的一方必须有要读取对象所对应的类否则会抛出ClassNotFoundException。与此同时在反序列化的过程中无需使用构造器。当多个对象写入文件时在读取时也必须按照顺序来读取。
父类与对象序列化
当父类实现了对象序列化的时候也会将父类的成员变量保存到磁盘中。当没有实现序列化接口的时候父类是不会被序列化到磁盘中的。当父类①没有无参构造器②没有实现序列化接口这个时候就会抛出java.io.InvalidClassException。
对象引用的序列化
当一个要序列化对象的成员变量是一个引用类型的变量的时候,如果想要序列化这个类的对象的时候那么就得让这个引用类型实现Serializable接口。否则这个类的对象也是无法序列化的。
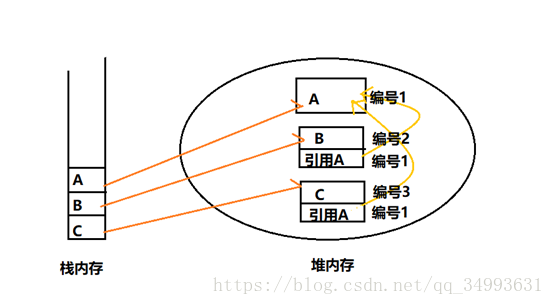
当对象A被多个对象(B、C)引用时在序列化这几个对象的时候,A只会被序列化一次。这就涉及到了一个Java对象序列化的算法。
① 所有保存到磁盘中的对象都有一个编号。
② 当程序序列化一个对象时先检查这个对象是否被序列化过。如果没有被序列化过的话才会将当前对象序列化到磁盘。
③ 如果某个对象被序列化过,程序将输出一个序列化编号而非再次序列化该对象。
上述的场景如下图:
自定义序列化
一个对象序列化了在网上跑,其中的一些敏感信息有可能被被黑客拦截进而破解。所以有时候我们需要对序列化的内容做一些手脚(比如说一些加密)这就涉及到了自定义序列化了。
① 不去序列化某个变量
关键词transient瞬态实例变量,在序列化的时候它不会被序列化。使用该关键词修饰的变量在反序列化的时候就不会得到相应的值。
② 使用自定义序列化的方式
Java的自定义序列化机制可以让程序去控制对各个变量的序列化过程,甚至不用去序列化。比如我想给Person类中的name成员变量加密我们就在Person中写入writeObject(ObjectOutputStream out)方法这个方法在序列化之前调用。由于在反序列化的时候需要解密所以就需要在Person中再加上一个readObject(ObjectInputStream in)方法它在反序列化之后执行。Person的代码如下:
package customserializable;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.io.Serializable;
public class Person implements Serializable{
private String name;
// private transient int age;//用这个修饰的变量不会被序列化
private transient int age;
public Person(String name,int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
private void writeObject(ObjectOutputStream out) throws IOException {//这样的方法能够保证即使在网上传输的数据如果被黑客拦截住了也不会泄露信息
out.writeObject(new StringBuffer(name).reverse());
out.writeObject(age);
}
private void readObject(ObjectInputStream in) throws ClassNotFoundException, IOException {
this.name = ((StringBuffer)in.readObject()).reverse().toString();
this.age = (int) in.readObject();
}
//Exteralnalizeable接口和Serializable一样只是强制的加上了自定义的读写方式
}
① 一种更为彻底的对象序列化
现在我不仅仅是想要加密,我甚至想要替换序列化的对象。比如我想把Person对象的值装入到一个List中然后在序列化这个操作简直是厉害。Object writeReplace()这个方法也是在对象序列化之前执行。代码如下:
Student类
package customserializable;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.io.ObjectStreamException;
import java.io.Serializable;
import java.util.ArrayList;
public class Student implements Serializable{
private String name;
// private transient int age;//用这个修饰的变量不会被序列化
private transient int age;
public Student(String name,int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
//将序列化的数据再次进行封装,比上次的反转更为致命 又是一个默认调用的方法
private Object writeReplace() throws ObjectStreamException{
ArrayList<Object> list = new ArrayList<Object>();
list.add(name);
list.add(age);
return list;
}
}
测试类
package customserializable;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.util.ArrayList;
public class ReplaceTest {
public static void main(String[] args) {
try {
ObjectOutputStream oop = new ObjectOutputStream(new FileOutputStream("zhuliu7.txt"));
Student s = new Student("hyl",23);
oop.writeObject(s);
oop.close();
ObjectInputStream oip = new ObjectInputStream(new FileInputStream("zhuliu7.txt"));
ArrayList list = (ArrayList) oip.readObject();
System.out.println(list);
}catch (Exception e) {
e.printStackTrace();
}
}
}
Object writeReplace()方法的注意事项,这个方法会返回一个Object如果这个Object也有ObjectwriteReplace()这个方法的话那么就会一直递归的调用下去。
① 对象恢复功能Object readResolve()
② 我们知道在反序列化之后返回的对象与我们序列化时候的对象是不一样的(从这一点来说反序列化可以克隆一个对象)。如果我们想要还原成和以前的值一样(比如说一个枚举值或者是单例模式就会有这样的需求)这时我们就需要Object readResolve()方法来重塑一个对象。这个方法在readObject()方法之后调用。这个方法有一个需要注意的地方就是当子类继承父类时父类有此方法,所以我们在返回时会得到父类的返回对象,这显然不是我们所想要的。所以这个方法private的修饰符修饰。示例代码如下:
Car类
package customserializable;
import java.io.ObjectStreamException;
import java.io.Serializable;
public class Car implements Serializable{
private static Car car = new Car("特斯拉");
private String name;
private Car(String name) {
this.name = name;
}
public static Car getCar() {
return car;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Object readResolve() throws ObjectStreamException{
return car;
}
}
测试类
package customserializable;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.util.ArrayList;
public class ReadResolveTest {
public static void main(String[] args) {
try {
ObjectOutputStream oop = new ObjectOutputStream(new FileOutputStream("zhuliu7.txt"));
Car c = Car.getCar();
oop.writeObject(c);
oop.close();
ObjectInputStream oip = new ObjectInputStream(new FileInputStream("zhuliu7.txt"));
Car c1 = (Car) oip.readObject();
System.out.println(c1==c);//这样的话就能够返回和原来一样的对象了这个厉害
}catch (Exception e) {
e.printStackTrace();
}
}
}
小节
四个自定义序列化的方法执行顺序为:
writeReplace()
write Object()
readObject()
readResolve()
另一个自定义序列化
这是一种强制的自定义序列化,强制要求程序员自己来操控序列化。想要实现这个目标Java类必须实现Externalizable接口。实现接口的类会强制实现void readExternal(ObjectInputStream in)与voidwriteExternal(ObjectOutputStream out)这两个方法,用法与writeObject() 和readObject()相似这里就不在赘述了。
对于对象序列化还有几点需要注意:
① 对象的类名,实例变量(包括基本类型还有数组、对其它对象的引用)都会被序列化。方法,类变量,transient修饰的变量都不会被序列化。虽然static修饰的变量也不会被序列化,但是不推荐。
② 序列化一个变量时要保证它的引用变量也是可序列化的(要么用transient修饰)否则该对象无法序列化。
③ 反序列化时必须要有序列化对象的class。
④ 读取序列化对象时必须要按照顺序来读取。
版本
我们知道在反序列化的时候必须要有序列化对象的class,如果一方的class文件进行升级而在文件里的序列化对象还保留着原始的版本这样就出现了兼容性的问题。Java序列化机制里提供了一个private static final serialVersionUID用来标识Java类的序列化版本,也就是说这要两个类的serialVersionUID保持不变,序列化机制就会认为他们是同一个序列化版本。
通常我们要显式的指定serialVersionUID。不指定(由JVM来计算)的坏处:
① JVM会根据class的信息去计算,这样修改后的类显然和修改前的类结果不同。从而造成序列化版本不兼容而失败。
② 不同平台下的JVM计算策略不同,就算是同一个class在不同的平台下也会有不同的结果。
如果由于类的修改导致了序列化失败,此时应该更新serialVersionUID。什么情况会导致序列化失败呢下面来讨论:
① 修改了方法,静态变量,瞬态实例变量反序列化不受影响。无需修改实例变量。
② 如果修改了非瞬态(静态)实例变量时则可能版本不兼容。如果类两边的的变量数目不相等但是其它的变量类型都一样则不会出现版本不兼容。但是只要出现变量名相同但是变量类型不同这时候就会导致版本不兼容,这时候也就需要修改serialVersionUID的值。
NIO
传统IO流的特点
传统的IO是阻塞式的流,如果没有读取到有效数据程序就会阻塞线程的执行。不仅如此传统的输入流底层都是由字节的移动来实现的(也就是一次只能够处理一个字节),即使是字符流的处理底层也是依靠字节流。这样的话就比较效率低。
新IO概述
新的IO与传统的IO有相同的目的。但是采用了不同的方式来处理输入和输出。新IO将一个文件或者是一个文件的一段区域都映射到内存里,这样就可以像访问内存一样来访问文件了(这种方式模拟了操作系统上虚拟内存的概念)。这种方式十分的高效。
其中nio中有两个核心的类Channel(通道)与Buffer(缓冲)。
Channel是对传统的流的模拟,但是它多出了一个map方法,这个方法可以把“一块区域”映射到内存里。如果说传统的流是面向流的处理那么这里的NIO则是面向块的处理。
Buffer的本质是一个数组,它既可以像原始的“水桶”一桶一桶地取水,也可以由Channel直接将数据映射到Buffer中。
使用Buffer
Buffer的三个重要概念:
容量(capacity):Buffer的最大容量
界限(limit):第一个不能被读到的缓冲区位置索引。
位置(position):下一个可以被操作的(读或写)的缓冲区位置索引。
标记:这个可选,一个标签便于后来的操作。
他们有如下的关系:
0<=mark<=position<=limit<=capacity
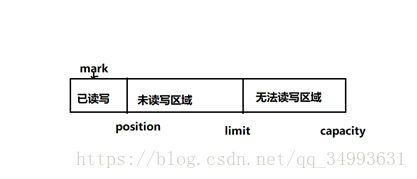
Bufferde的两个核心方法,flip()与clear()。
执行filp()之后Buffer处于准备读取状态,此时的limit定位到了当前的position处。postion定位到了0处。
执行了clear()之后Buffer处于准备写入状态。此时的limit定位到capacity处,position定位到0处。特别强调的就是此时Buffer中还拥有数据。
Buffer的两种操作方式:
① 相对操作,从当前position处开始操作。
② 绝对操作,直接使用下标来操作。
最后强调capacity所指的缓冲区位置索引不存放任何数据。
示例代码如下:
package nio.buffer;
import java.nio.CharBuffer;
public class BufferTest {
public static void main(String[] args) {
CharBuffer buff = CharBuffer.allocate(8);
System.out.println("capacity:" + buff.capacity());//总容量
System.out.println("limit"+buff.limit());//允许读取的大小
System.out.println("position"+buff.position());//下一个指针是谁
buff.put('a');
buff.put('b');
buff.put('c');
System.out.println("limit"+buff.limit());//允许读取的大小
System.out.println("position"+buff.position());//下一个指针是谁
buff.flip();//准备开始读取
System.out.println("filp之后");
System.out.println("limit"+buff.limit());//允许读取的大小
System.out.println("position"+buff.position());//下一个指针是谁
System.out.println(buff.get());
System.out.println("position"+buff.position());//下一个指针是谁
buff.clear();
System.out.println("clear之后");
System.out.println("limit"+buff.limit());//允许读取的大小
System.out.println("position"+buff.position());//下一个指针是谁
}
}
直接Buffer与普通Buffer
除了上述介绍的创建Buffer的方法,Java还提供了allocateDirect()来直接创建Buffer。直接创建的Buffer它的创建成本高但是它的读取效率高。所以直接Buffer适合一次创建长期使用的场景。
使用Channel
Channel是传统流的延伸但是有两个主要的区别。
① 他可以直接将文件中的数据部分或者全部映射成Buffer。
② 程序不能够直接读写Channel中的数据必须依赖于Buffer从Channel中取得一些数据程序才能够从Buffer中取得数据。
所有的Channel创建不是依靠构造器而是通过传统的流的getChannel()方法来得到对应的Channel,当然不同的流会有不同的Channel。
Map方法的签名为:MappedByteBuffermap(FileChannel.MapMode mode ,long position ,long size),第一个参数分别有只读、读写模式。剩余的两个参数则是控制将Channel的那些数据映射成ByteBuffer的。以下为FileChannel的示例代码:
package nio.channel;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.nio.CharBuffer;
import java.nio.MappedByteBuffer;
import java.nio.channels.FileChannel;
import java.nio.charset.Charset;
import java.nio.charset.CharsetDecoder;
public class FileChannelTest {
public static void main(String[] args) {
File f = new File("src/nio/channel/FileChannelTest.java");
try {
FileInputStream fis = new FileInputStream(f);
FileOutputStream fos = new FileOutputStream("zhuliu7.txt");
FileChannel inChannel = fis.getChannel();//Channel已经把数据从流中读取到手了
FileChannel outChannel = fos.getChannel();
//将FileChannel中的数据全部映射成ByteBuffer 他是一个二进制的map
MappedByteBuffer buffer = inChannel.map(FileChannel.MapMode.READ_ONLY,0,f.length());
//outChannel读取buffer中的数据全部输出到对应的流的文件中
outChannel.write(buffer);//我所好奇的是直接将字节输入到文件中竟然没事
buffer.clear();
Charset charset = Charset.forName("GBK");
CharsetDecoder decoder = charset.newDecoder();//创建解码器
CharBuffer charbuffer = decoder.decode(buffer);
System.out.println(charbuffer);
} catch (Exception e) {
e.printStackTrace();
}
}
}
不仅InputStream和OutputStream有getChannel()方法,RandomAccessFile也有自己的getChannel()方法,当然返回的FileChannel是只读的还是读写的则取决于RandomAccessFile的读写模式。下面代码是复制文件中的内容然后追加到文件末尾。
package nio.channel;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.RandomAccessFile;
import java.nio.ByteBuffer;
import java.nio.channels.FileChannel;
import java.nio.channels.FileChannel.MapMode;
public class RandomFileChannelTest {
public static void main(String[] args) {
File file = new File("zhuliu7.txt");
try {
RandomAccessFile raf = new RandomAccessFile(file, "rw");
FileChannel channel = raf.getChannel();//当得到一个channel的时候也就拿到了文件中的所有内容
ByteBuffer buffer = channel.map(FileChannel.MapMode.READ_ONLY,0,file.length());
channel.position(file.length());//就像在操作文件一样
channel.write(buffer);
} catch (Exception e) {
e.printStackTrace();
}
}
}
Buffer也可以当做是传统意义上的容器,来在Channel中多次取水。示例代码如下:
package nio.channel;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.nio.ByteBuffer;
import java.nio.CharBuffer;
import java.nio.channels.FileChannel;
import java.nio.charset.Charset;
public class ReadFile {
public static void main(String[] args) throws Exception {
File f = new File("src/nio/channel/ReadFile.java");
FileInputStream fis = new FileInputStream(f);
ByteBuffer bbuffer = ByteBuffer.allocate(256);
FileChannel channel = fis.getChannel();
while((channel.read(bbuffer))>0) {//此时此刻channel就像一个普通的流一样
bbuffer.flip();
//接下来的操作就是将字节数组中的内容解码到字符数组中
Charset cs = Charset.forName("GBK");
CharBuffer cbuffer = cs.decode(bbuffer);
System.out.println(cbuffer);
bbuffer.clear();
}
}
}
字符集和Charset
计算机中的文件数据都是一种表面现象,他们的底层都是二进制序列。将明文转换成二进制数据为编码,将二进制数据转换成明文就是解码。只有编码和解码使用的字符集相同才能够正确的显示字符。下面代码展示了:字符数组à字节数组à字符数组。的编码解码过程。
package nio.charset;
import java.nio.ByteBuffer;
import java.nio.CharBuffer;
import java.nio.charset.CharacterCodingException;
import java.nio.charset.Charset;
import java.nio.charset.CharsetDecoder;
import java.nio.charset.CharsetEncoder;
public class CharsetTranform {
public static void main(String[] args) throws Exception {
//字符数组-->字节数组-->字符数组
Charset charset = Charset.forName("GBK");
CharsetEncoder encoder = charset.newEncoder();
CharsetDecoder decoder = charset.newDecoder();
CharBuffer cbuffer = CharBuffer.allocate(8);
cbuffer.put('a');
cbuffer.put('b');
cbuffer.put('c');
cbuffer.flip();
ByteBuffer bbuffer = encoder.encode(cbuffer);
for(int i = 0;i<bbuffer.limit();i++) {
System.out.print(bbuffer.get(i)+" ");//打印出来的是对应的unicode码
}
System.out.println(decoder.decode(bbuffer));
}
}
当然String中也有一个getBytes()将指定的字符串转换为字节序列。
文件锁
在多个运行的程序并发修改同一个文件的时候,程序之间要通过某种机制来实现通信,使用文件锁可以有效的阻止多个程序并发修改一个文件。JDK1.4的NIO就提供了文件锁的功能FileLock。在FileChannel中提供的lock()/tryLock()的方法可以获得文件锁FileLock对象从而锁定文件。当然lock()与tryLock()存在区别,lock()试图锁定某个文件时不断的询问某个文件,如果无法得到文件锁,程序将一直阻塞。而tryLock()是尝试锁定文件,它将直接返回而不是阻塞,如果得不到就返回null。
在两个文件锁方法的参数中有position与size它表示锁定从position到position+size区域内的数据。还有一个shared,当它为true时表示它是一个共享锁它允许其他程序访问该文件。当shared为false的时候表明该锁为一个排他锁,他将锁住该文件的读写。
最后release可以释放锁。
以下示例代码展示了在15秒之内zhuliu7.txt无法被其他程序修改。
package nio.filelock;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.nio.channels.FileChannel;
import java.nio.channels.FileLock;
public class FileLockTest {
public static void main(String[] args) {
try {
FileChannel channel = new FileOutputStream("zhuliu7.txt").getChannel();
FileLock lock = channel.tryLock();
Thread.sleep(15000);
lock.release();
} catch (Exception e) {
e.printStackTrace();
}
}
}
文件锁的注意事项:
① 文件锁是建议性的而非强制性的,所以一个程序在不能获得文件锁的时候也能读写文件。
② 文件锁是Java虚拟机所拥有的而不是Java程序所拥有的。也就是如果两个Java虚拟机使用同一个Java虚拟机运行,则他们不能够同时对同一个文件加锁。
③ 在某些平台上当关闭一个文件上的channel时会释放该文件上的所有锁,因此应该避免一个被锁定的文件同时打开多个channel。
NIO.2
主要介绍一批工具类的使用。
Path、Paths与Files
早期的Java提供了File类来访问文件系统,但是File类比较有限,性能底下,与多种文件系统不兼容。所以提供了平台无关的路径方法Path。当然还提供了一些相关的工具类比如说Paths与Files。以下示例代码展示了Path以及Paths的用法:
package nio2;
import java.nio.file.Path;
import java.nio.file.Paths;
public class PathTest {
public static void main(String[] args) {
//根据一个路径来创建一个Paths对象
Path path = Paths.get("src");
System.out.println("Paths里包含的路径数量:"+path.getNameCount());
System.out.println("当前路径的根路径:"+path.getRoot());
Path absolutePath = path.toAbsolutePath();
System.out.println("绝对路径:"+absolutePath);
System.out.println("根据目录的级别去寻找路径:"+absolutePath.getName(2));
System.out.println("绝对路径的根路径:"+absolutePath.getRoot());
//用多个目录创建Path对象
Path path2 = Paths.get("D:","zhuliu7","zhuliu7");
System.out.println(path2);
}
}
Files是一个文件操作的工具类,下面程序示范了Files类的用法:
package nio2;
import java.io.FileOutputStream;
import java.io.IOException;
import java.nio.charset.Charset;
import java.nio.file.FileStore;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.ArrayList;
import java.util.List;
public class FilesTest {
public static void main(String[] args) {
try {
//文件复制
Files.copy(Paths.get("zhuliu7.txt"),new FileOutputStream("src/hyl.txt"));
//判断文件是否为隐藏文件
System.out.println("隐藏文件么?"+Files.isHidden(Paths.get("zhuliu7.txt")));
//将每一行String放到List集合中
List<String> lines = Files.readAllLines(Paths.get("src/nio2/FilesTest.java"), Charset.forName("GBK"));
System.out.println(lines);
//得到文件的大小
System.out.println(Files.size(Paths.get("zhuliu7.txt"))+"字节");
//直接将多个字符串写入文件中
List<String> list = new ArrayList<String>();
list.add("会当凌绝顶");
list.add("一览众山小");
Files.write(Paths.get("zhuliu7.txt"),list, Charset.forName("GBK"));
//Files与Stream编程
//列出当前文件夹下所有的文件和子目录
Files.list(Paths.get(".")).forEach(ele->System.out.println(ele));
//Stream读取文件
Files.lines(Paths.get("zhuliu7.txt"), Charset.forName("GBK")).forEach(ele->System.out.println(ele));;
//判断磁盘的空间
FileStore store = Files.getFileStore(Paths.get("C:"));
System.out.println("C盘的总大小"+store.getTotalSpace());
System.out.println("C盘的可用空间"+store.getUsableSpace());
} catch (Exception e) {
e.printStackTrace();
}
}
}
使用FileVisitor来遍历文件和目录
Files类中有walkFileTree(Pathstart,FileVisitor<?super Path> visitor)方法来遍历指定目录下的所有文件和子目录。FileVisitor代表一个文件访问器他是一个接口,walkFileTree()会自动遍历start下面的所有文件和目录。而且也会触发相应的访问目录(文件)时(后)的方法。以下为示例代码:
package nio2;
import java.io.IOException;
import java.nio.file.FileVisitResult;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.nio.file.SimpleFileVisitor;
import java.nio.file.attribute.BasicFileAttributes;
public class FileVisitorTest {
public static void main(String[] args) throws IOException {
Files.walkFileTree(Paths.get("src"),new SimpleFileVisitor<Path>() {
@Override //访问文件时触发的方法
public FileVisitResult visitFile(Path file, BasicFileAttributes attrs) throws IOException {
System.out.println("正在访问"+file+"文件");
if(file.endsWith("FileVisitorTest.java")) {
System.out.println("已经找到了目标文件");
return FileVisitResult.TERMINATE;//如果找到该文件则停止遍历
}
return FileVisitResult.CONTINUE;
}
@Override//访问子目录之后触发的方法
public FileVisitResult postVisitDirectory(Path dir, IOException exc) throws IOException {
System.out.println("正在访问"+dir+"路径");
return FileVisitResult.CONTINUE;
}
});
}
}
使用WatchService监控文件变化
在以前的Java中,若要监控文件的变化。则考虑在后台启动一条线程每隔一段时间去遍历一次指定的目录文件。如果发现不同那么就认为文件发生了变化。性能不好,十分繁琐。NIO2中的Path类提供了register(WatchService watcher,WatchEvent.Kind<?> event):用watch来监听path下的事件变化。event来指定要监听的事件类型。WatchKey有如下的三个方法来获取被监听目录的文件变化事件。
WatchKey poll():获取下一个WatchKey,如果没有就立即返回null。
WatchKey poll(long timeout):尝试等待timeout时间去获取下一个WatchKey。
WatchKey take():获取下一个WatchKey,如果没有获取到那么一直等待。
如果程序向一直监控,则要选择take方法,如果想要指定监控的时间那么就用poll方法。
下面代码是WatchService监控D盘下的文件变化:
package nio2;
import java.io.IOException;
import java.nio.file.FileSystems;
import java.nio.file.Paths;
import java.nio.file.StandardWatchEventKinds;
import java.nio.file.WatchEvent;
import java.nio.file.WatchKey;
import java.nio.file.WatchService;
public class WacthServiceTest {//监控文件变化
public static void main(String[] args) throws Exception {
//获取文件系统的变化 //获取了一个默认的文件系统对象
WatchService watchService = FileSystems.getDefault().newWatchService();
//为D盘根路径注册监听 三个增删改
Paths.get("D:/").register(watchService,StandardWatchEventKinds.ENTRY_CREATE,
StandardWatchEventKinds.ENTRY_MODIFY,
StandardWatchEventKinds.ENTRY_DELETE);
while(true) {
WatchKey key = watchService.take();
for(WatchEvent<?> event : key.pollEvents()) {
System.out.println(event.context()+"文件发生了"+event.kind()+"事件");
}
boolean valid = key.reset();
if(!valid) {
break;
}
}
}
//是监控到了在直属文件夹下面正确生效 在其它子文件下不一定生效
}
访问文件属性
以前的File类也可以访问文件属性,但是想要访问更多的属性则需要平台特定的代码来实现。
Java7下NIO.2在java.nio.file.attribute中提供了大量的工具类。在这里FileAttributeView是其它XxxAttribute的父接口。具体的用法如下所示:
package nio2;
import java.io.IOException;
import java.nio.ByteBuffer;
import java.nio.charset.Charset;
import java.nio.file.FileSystems;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.nio.file.attribute.BasicFileAttributeView;
import java.nio.file.attribute.BasicFileAttributes;
import java.nio.file.attribute.DosFileAttributeView;
import java.nio.file.attribute.FileOwnerAttributeView;
import java.nio.file.attribute.UserDefinedFileAttributeView;
import java.nio.file.attribute.UserPrincipal;
import java.util.List;
public class AttributeViewTest {
public static void main(String[] args) throws IOException {
//获取要操作的文件
Path testPath = Paths.get("src/nio2/AttributeViewTest.java");
//获取基本属性的视图
BasicFileAttributeView basicView = Files.getFileAttributeView(testPath, BasicFileAttributeView.class);
BasicFileAttributes basicAttrs = basicView.readAttributes();
System.out.println("创建时间"+basicAttrs.creationTime());
System.out.println("最后访问时间"+basicAttrs.lastAccessTime());
System.out.println("最后修改时间"+basicAttrs.lastModifiedTime());
System.out.println("文件大小"+basicAttrs.size());
//访问文件属主信息
FileOwnerAttributeView ownerAttri = Files.getFileAttributeView(testPath,FileOwnerAttributeView.class);
//获取该文件所属的用户
System.out.println(ownerAttri.getOwner());
//获取系统中guest中所对应的用户
UserPrincipal user = FileSystems.getDefault().getUserPrincipalLookupService().lookupPrincipalByName("guest");
//获取自定义属性
UserDefinedFileAttributeView userView = Files.getFileAttributeView(testPath,UserDefinedFileAttributeView.class);
//获得所有自定义属性(对于我而言就没有什么自定义属性)
List<String> attrs = userView.list();
for(String name : attrs) {
ByteBuffer bbuf = ByteBuffer.allocate(userView.size(name));
bbuf.flip();
String value = Charset.defaultCharset().decode(bbuf).toString();
System.out.println(value);
}
//添加一个自定义属性
userView.write("所有人",Charset.defaultCharset().encode("Robert•Hu"));
DosFileAttributeView dosView = Files.getFileAttributeView(testPath, DosFileAttributeView.class);
dosView.setHidden(false);
dosView.setReadOnly(false);
}
}
好累。